pytorch+CRNN实现
最近接触了一个仪表盘识别的项目,简单调研以后发现可以用CRNN来做。但是手边缺少仪表盘数据集,就先用ICDAR2013试了一下。
结果遇到了一系列坑。为了不使读者和自己在以后的日子继续遭罪。我把正确的代码发到下面了。
1)超参数请不要调整!!!!CRNN前期训练极其离谱,需要良好的调参,loss才会慢慢下降。
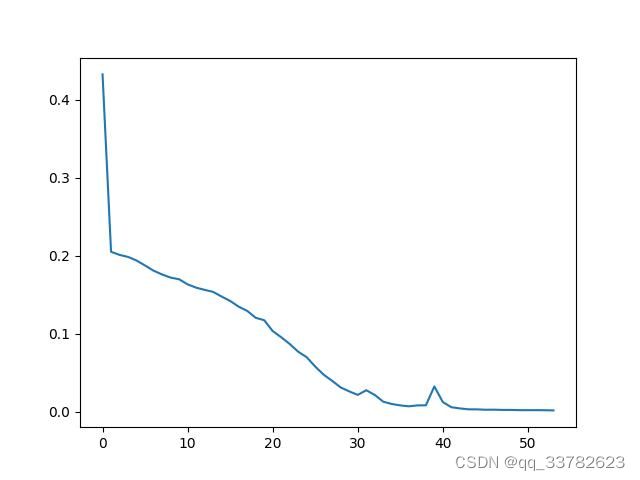
我给出了一个训练曲线,可以看到确实贼几把怪,七拐八拐的。
2)千万不要用百度开源的那个ctc!!!
网络代码:
#crnn.py
import torch.nn as nn
import torch.nn.functional as F
class BidirectionalLSTM(nn.Module):
# Inputs hidden units Out
def __init__(self, nIn, nHidden, nOut):
super(BidirectionalLSTM, self).__init__()
self.rnn = nn.LSTM(nIn, nHidden, bidirectional=True)
self.embedding = nn.Linear(nHidden * 2, nOut)
def forward(self, input):
recurrent, _ = self.rnn(input)
T, b, h = recurrent.size()
t_rec = recurrent.view(T * b, h)
output = self.embedding(t_rec) # [T * b, nOut]
output = output.view(T, b, -1)
return output
class CRNN(nn.Module):
# 32 1 37 256
def __init__(self, imgH, nc, nclass, nh, n_rnn=2, leakyRelu=False):
super(CRNN, self).__init__()
assert imgH % 16 == 0, 'imgH has to be a multiple of 16'
ks = [3, 3, 3, 3, 3, 3, 2]
ps = [1, 1, 1, 1, 1, 1, 0]
ss = [1, 1, 1, 1, 1, 1, 1]
nm = [64, 128, 256, 256, 512, 512, 512]
cnn = nn.Sequential()
def convRelu(i, batchNormalization=False):
nIn = nc if i == 0 else nm[i - 1]
nOut = nm[i]
cnn.add_module('conv{0}'.format(i),
nn.Conv2d(nIn, nOut, ks[i], ss[i], ps[i]))
if batchNormalization:
cnn.add_module('batchnorm{0}'.format(i), nn.BatchNorm2d(nOut))
if leakyRelu:
cnn.add_module('relu{0}'.format(i),
nn.LeakyReLU(0.2, inplace=True))
else:
cnn.add_module('relu{0}'.format(i), nn.ReLU(True))
convRelu(0)
cnn.add_module('pooling{0}'.format(0), nn.MaxPool2d(2, 2)) # 64x16x64
convRelu(1)
cnn.add_module('pooling{0}'.format(1), nn.MaxPool2d(2, 2)) # 128x8x32
convRelu(2, True)
convRelu(3)
cnn.add_module('pooling{0}'.format(2),
nn.MaxPool2d((2, 2), (2, 1), (0, 1))) # 256x4x16
convRelu(4, True)
convRelu(5)
cnn.add_module('pooling{0}'.format(3),
nn.MaxPool2d((2, 2), (2, 1), (0, 1))) # 512x2x16
convRelu(6, True) # 512x1x16
self.cnn = cnn
self.rnn = nn.Sequential(
BidirectionalLSTM(512, nh, nh),
BidirectionalLSTM(nh, nh, nclass))
def forward(self, input):
# conv features
#print('---forward propagation---')
conv = self.cnn(input)
b, c, h, w = conv.size()
assert h == 1, "the height of conv must be 1"
conv = conv.squeeze(2) # b *512 * width
conv = conv.permute(2, 0, 1) # [w, b, c]
output = F.log_softmax(self.rnn(conv), dim=2)
return output
训练:
#train.py
import os
import torch
import cv2
import numpy as np
from torchvision import transforms
from torch.utils.data import Dataset, DataLoader
from torch.nn.utils.rnn import pad_sequence
import crnn
import time
import re
import matplotlib.pyplot as plt
dic={" ":0,"a":1,"b":2,"c":3,"d":4,"e":5,"f":6,"g":7,"h":8,"i":9,"j":10,"k":11,"l":12,"m":13,"n":14,"o":15,"p":16,"q":17,"r":18,"s":19,"t":20,"u":21,"v":22,"w":23,"x":24,"y":25,"z":26,
"A":27,"B":28,"C":29,"D":30,"E":31,"F":32,"G":33,"H":34,"I":35,"J":36,"K":37,"L":38,"M":39,"N":40,"O":41,"P":42,"Q":43,"R":44,"S":45,"T":46,"U":47,"V":48,"W":49,"X":50,"Y":51,"Z":52}
STR=" abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"
n_class=53
label_sources=r"E:\machine_learning\instrument\icdar_2013\Challenge2_Test_Task1_GT"
image_sources=r"E:\machine_learning\instrument\icdar_2013\Challenge2_Test_Task12_Images"
use_gpu = True
learning_rate = 0.0001
max_epoch = 100
batch_size = 20
# 调整图像大小和归一化操作
class resizeAndNormalize():
def __init__(self, size, interpolation=cv2.INTER_LINEAR):
# 注意对于opencv,size的格式是(w,h)
self.size = size
self.interpolation = interpolation
# ToTensor属于类 """Convert a ``PIL Image`` or ``numpy.ndarray`` to tensor.
self.toTensor = transforms.ToTensor()
def __call__(self, image):
# (x,y) 对于opencv来说,图像宽对应x轴,高对应y轴
image = cv2.resize(image, self.size, interpolation=self.interpolation)
# 转为tensor的数据结构
image = self.toTensor(image)
# 对图像进行归一化操作
#image = image.sub_(0.5).div_(0.5)
return image
def load_data(label_folder,image_folder,label_suffix_name=".txt",image_suffix_name=".jpg"):
image_file,label_file,num_file=[],[],[]
for parent_folder, _, file_names in os.walk(label_folder):
# 遍历当前子文件夹中的所有文件
for file_name in file_names:
# 只处理图片文件
# if file_name.endswith(('jpg', 'jpeg', 'png', 'gif')):#提取jpg、jpeg等格式的文件到指定目录
if file_name.endswith((label_suffix_name)): # 提取json格式的文件到指定目录
# 构造源文件路径和目标文件路径
a,b=file_name.split("gt_")
c,d=b.split(label_suffix_name)
image_name=image_folder + "\\" + c + image_suffix_name
if os.path.exists(image_name):
label_name = label_folder + "\\" + file_name
txt=open(label_name,'rb')
txtl=txt.readlines()
for line in range(len(txtl)):
image_file.append(image_name)
label_file.append(label_name)
num_file.append(line)
return image_file,label_file,num_file
def zl2lable(zl):
label_list=[]
for str in zl:
label_list.append(dic[str])
return label_list
class NewDataSet(Dataset):
def __init__(self, label_source,image_source,train=True):
super(NewDataSet, self).__init__()
self.image_file,self.label_file,self.num_file= load_data(label_source,image_source)
def __len__(self):
return len(self.image_file)
def __getitem__(self, index):
txt = open(self.label_file[index], 'rb')
img=cv2.imread(self.image_file[index],cv2.IMREAD_GRAYSCALE)
wordL = txt.readlines()
word=str(wordL[self.num_file[index]])
pl = re.findall(r'\d+',word)
zl = re.findall(r"[a-zA-Z]+", word)[1] #1
#img tensor
x1, y1, x2, y2 = pl[:4]
img= img[int(y1):int(y2),int(x1):int(x2), ]
(height, width)=img.shape
# 由于crnn网络输入图像的高为32,故需要resize原始图像的height
size_height = 32
# ratio = 32 / float(height)
size_width =100
transform = resizeAndNormalize((size_width, size_height))
# 图像预处理
imageTensor = transform(img)
#label tensor
l = zl2lable(zl)
labelTensor = torch.IntTensor(l)
return imageTensor,labelTensor
class CRNNDataSet(Dataset):
def __init__(self, imageRoot, labelRoot):
self.image_root = imageRoot
self.image_dict = self.readfile(labelRoot)
self.image_name = [fileName for fileName, _ in self.image_dict.items()]
def __getitem__(self, index):
image_path = os.path.join(self.image_root, self.image_name[index])
keys = self.image_dict.get(self.image_name[index])
label = [int(x) for x in keys]
image = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
# if image is None:
# return None,None
(height, width) = image.shape
# 由于crnn网络输入图像的高为32,故需要resize原始图像的height
size_height = 32
ratio = 32 / float(height)
size_width = int(ratio * width)
transform = resizeAndNormalize((size_width, size_height))
# 图像预处理
image = transform(image)
# 标签格式转换为IntTensor
label = torch.IntTensor(label)
return image, label
def __len__(self):
return len(self.image_name)
def readfile(self, fileName):
res = []
with open(fileName, 'r') as f:
lines = f.readlines()
for line in lines:
res.append(line.strip())
dic = {}
total = 0
for line in res:
part = line.split(' ')
# 由于会存在训练过程中取图像的时候图像不存在导致异常,所以在初始化的时候就判断图像是否存在
if not os.path.exists(os.path.join(self.image_root, part[0])):
print(os.path.join(self.image_root, part[0]))
total += 1
else:
dic[part[0]] = part[1:]
print(total)
return dic
trainData =NewDataSet(label_sources,image_sources)
trainLoader = DataLoader(dataset=trainData, batch_size=1, shuffle=True, num_workers=0)
# valData = CRNNDataSet(imageRoot="D:\BaiduNetdiskDownload\Synthetic_Chinese_String_Dataset\images\\",
# labelRoot="D:\BaiduNetdiskDownload\Synthetic_Chinese_String_Dataset\lables\data_t.txt")
#
# valLoader = DataLoader(dataset=valData, batch_size=1, shuffle=True, num_workers=1)
#
# def decode(preds):
# pred = []
# for i in range(len(preds)):
# if preds[i] != 5989 and ((i == 5989) or (i != 5989 and preds[i] != preds[i - 1])):
# pred.append(int(preds[i]))
# return pred
#
#
def toSTR(l):
str_l=[]
if isinstance(l, int):
l=[l]
for i in range(len(l)):
str_l.append(STR[l[i]])
return str_l
def toRES(l):
new_l=[]
new_str=' '
for i in range(len(l)):
if(l[i]==' '):
new_str = ' '
continue
elif new_str!=l[i]:
new_l.append(l[i])
new_str=l[i]
return new_l
def val(model=torch.load("pytorch-crnn.pth")):
# 将模式切换为验证评估模式
loss_func = torch.nn.CTCLoss(blank=0, reduction='mean')
model.eval()
test_n=10
for i, (data, label) in enumerate(trainLoader):
if(i>test_n):
break;
output = model(data.cuda())
pred_label=output.max(2)[1]
input_lengths = torch.IntTensor([output.size(0)] * int(output.size(1)))
target_lengths = torch.IntTensor([label.size(1)] * int(label.size(0)))
# forward(self, log_probs, targets, input_lengths, target_lengths)
#log_probs = output.log_softmax(2).requires_grad_()
targets = label.cuda()
loss = loss_func(output.cpu(), targets.cpu(), input_lengths, target_lengths)
pred_l=np.array(pred_label.cpu().squeeze()).tolist()
label_l=np.array(targets.cpu().squeeze()).tolist()
print(i,":",loss,"pred:",toRES(toSTR(pred_l)),"label_l",toSTR(label_l))
def train():
model = crnn.CRNN(32, 1, n_class, 256)
if torch.cuda.is_available() and use_gpu:
model.cuda()
loss_func = torch.nn.CTCLoss(blank=0,reduction='mean')
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate,betas=(0.9, 0.999))
lossTotal = 0.0
k = 0
printInterval = 100
start_time = time.time()
loss_list=[]
total_list=[]
for epoch in range(max_epoch):
n=0
data_list = []
label_list = []
label_len=[]
for i, (data, label) in enumerate(trainLoader):
#
data_list.append(data)
label_list.append(label)
label_len.append(label.size(1))
n=n+1
if n%batch_size!=0:
continue
k=k+1
data=torch.cat(data_list, dim=0)
data_list.clear()
label = torch.cat(label_list, dim=1).squeeze(0)
label_list.clear()
target_lengths=torch.tensor(np.array(label_len))
label_len.clear()
# 开启训练模式
model.train()
if torch.cuda.is_available and use_gpu:
data = data.cuda()
loss_func = loss_func.cuda()
label = label.cuda()
output = model(data)
log_probs = output
# example 建议使用这样,貌似直接把output送进去loss fun也没发现什么问题
#log_probs = output.log_softmax(2).requires_grad_()
targets = label.cuda()
input_lengths = torch.IntTensor([output.size(0)] * int(output.size(1)))
# forward(self, log_probs, targets, input_lengths, target_lengths)
#targets =torch.zeros(targets.shape)
loss = loss_func(log_probs.cpu(), targets, input_lengths, target_lengths)/batch_size
lossTotal += float(loss)
print("epoch:",epoch,"num:",i,"loss:",float(loss))
loss_list.append(float(loss))
if k % printInterval == 0:
print("[%d/%d] [%d/%d] loss:%f" % (
epoch, max_epoch, i + 1, len(trainLoader), lossTotal / printInterval))
total_list.append( lossTotal / printInterval)
lossTotal = 0.0
torch.save(model, 'pytorch-crnn.pth')
optimizer.zero_grad()
loss.backward()
optimizer.step()
plt.figure()
plt.plot(loss_list)
plt.savefig("loss.jpg")
plt.clf()
plt.figure()
plt.plot(total_list)
plt.savefig("total.jpg")
end_time = time.time()
print("takes {}s".format((end_time - start_time)))
return model
if __name__ == '__main__':
train()
测试结果如下:

最后给一些参考文献:
https://www.cnblogs.com/azheng333/p/7449515.html
https://blog.csdn.net/wzw12315/article/details/106643182
另外给出数据集和我训练好的模型:
链接:https://pan.baidu.com/s/1-jTA22bLKv2ut_1EJ1WMKA?pwd=jvk8
提取码:jvk8