【半监督医学图像分割 2022 TMI】ASE-Net
文章目录
- 【半监督医学图像分割 2022 TMI】ASE-Net
-
- 摘要
- 1. 介绍
- 2. 相关工作
- 3. 方法
-
- 3.1 对抗性一致性学习
- 3.2 基于动态卷积的双向注意组件
- 4. 实验
- 5. 讨论
- 6. 结论
【半监督医学图像分割 2022 TMI】ASE-Net
论文题目:Semi-supervised medical image segmentation using adversarial consistency learning and dynamic convolution network
中文题目:基于对抗一致性学习和动态卷积网络的半监督医学图像分割
论文链接:https://ieeexplore.ieee.org/document/9966841/
论文代码:https://github.com/SUST-reynole/ASE-Net
发表时间:2022年9月
论文团队:陕西科技大学&同济大学
引用:Lei T, Zhang D, Du X, et al. Semi-supervised medical image segmentation using adversarial consistency learning and dynamic convolution network[J]. IEEE Transactions on Medical Imaging, 2022.
引用数:1(截止时间:2023年2月14号)
摘要
- 目前流行的半监督医学图像分割网络由于在
不同的数据扰动下使用一致性学习来正则化模型训练,经常受到未标记数据的错误监督。这些网络忽略了标记和未标记数据之间的关系,只计算单个像素级的一致性,导致预测结果不确定。- 此外,由于骨干网的设计依赖于有监督的图像分割任务,这些网络往往需要大量的参数。此外,由于半监督图像分割通常采用少量的训练样本,
这些网络往往面临较高的过拟合风险。
针对上述问题,本文提出了一种基于动态卷积(ASE-Net)的对抗自拟网络,用于半监督医学图像分割。
-
首先,我们采用对抗性一致性训练策略(ACTS),该策略采用基于一致性学习的两个鉴别器来获得标记数据和未标记数据之间的先验关系。该算法可以同时计算不同数据扰动下未标记数据的像素级和图像级的一致性,从而提高标签的预测质量。
-
其次,我们设计了一种基于动态卷积的双向注意组件(bidirectional attention component, DyBAC),该组件可以嵌入到任何分割网络中,目的是基于输入样本的结构信息自适应调整ASE-Net的权值。
该组件有效地提高了ASE-Net的特征表示能力,降低了网络的过拟合风险。
提出的ASE-Net已经在三个公开可用的数据集上进行了广泛的测试,实验表明ASE-Net优于最先进的网络,并减少了计算成本和内存开销。
1. 介绍
医学图像分割可以在异常图像中提取重要器官或病变,在计算机辅助诊断和治疗研究中具有重要作用。近年来,许多基于监督学习的医学图像分割编码器-解码器网络取得了显著的效果,如U-Net[1]、UNet++[2]、H-DenseUNet[3]等。然而,这些技术的成功在很大程度上依赖于大量的像素级标记数据,但在实践中,注释医学图像通常非常昂贵。其中一个原因是医学图像由于低对比度和噪声干扰,视觉效果很差。此外,医学图像标注比自然图像需要更多的专业知识。因此,要构建大量具有高精度标签的医学图像数据集几乎是不可能的。与监督学习相比,半监督学习是解决弱监督学习[4]中数据监督不完全问题的一种新的学习范式。它主要使用少量的标注数据和大量的未标注数据来实现联合训练。显然,在医学图像分割中,半监督学习比监督学习更符合实际临床场景的要求。
目前主要的半监督医学图像分割方法大致可分为一致性学习、对抗学习、自训练、对比学习和协同训练。
在本文中,我们关注一致性学习和对抗性学习。一致性学习通常采用不同扰动下的一致性正则化方法来训练网络。其中最具代表性的方法是自ensemble Mean Teacher (MT)[5],它利用了自ensemble教师模型和学生模型在无标签数据上基于扰动的一致性损失,以及在有标签数据上的监督损失。基于MT,随后改进的方法侧重于选择不同的数据扰动和特征扰动,以获得性能增益。准确地说,分割网络生成一致伪标签的质量决定了网络对无标签数据的知识挖掘能力。
对于对抗学习,用于医学图像分割的生成式对抗网络(generative adversarial networks, GAN)[11][12][13]主要包括两个子网络,即一个鉴别器和一个生成器。
鉴别器的目的是识别输入样本是来自地面真值还是来自发生器。该生成器的目标是使鉴别器不能区分地面真实和分割网络的输出。一旦鉴别器不能确定输入来自哪里,生成样本就被认为足够接近地面真相。这两个网络交替更新,互相促进。
虽然上述方法取得了很大的成功,但它们仍然面临以下挑战。
首先,在一致性学习中,典型的Mean Teacher方法仅依靠不同的数据扰动获得一致性损失,不能有效利用无标记和有标记数据之间的先验关系,导致对无标记数据进行特征学习缓慢,模型泛化能力较弱。
其次,在对抗学习中,常用的方法只是利用单一的分割网络和单一的鉴别网络从未标记的数据中挖掘潜在的知识。
不幸的是,这两个网络经常会互相误导,导致训练过程中错误积累的问题。
第三,半监督方法通常不适合直接使用监督学习中具有固定参数的分割网络。一方面,参数固定的分割网络对有标记数据的拟合效果较好,但对无标记数据的特征表示效果较差;另一方面,在参数固定的网络中,不同的样本具有相同的模型权值,这容易导致对较小的标记数据集进行网络过拟合,导致对未标记数据生成伪标记的质量较差。
为了解决上述问题,本文提出了一种基于动态卷积的对抗自集成网络(ASE-Net)用于半监督医学图像分割。
ASE-Net通过一致性学习和在MT框架中添加两个鉴别器网络,有效地利用了未标记和标记数据之间的先验关系以及像素级和图像级的一致性。此外,我们提出了一种基于动态卷积的双向注意组件,该组件可以很容易地嵌入到分割网络中,以避免过拟合问题。本文的主要贡献如下:
(1)提出了一种基于双鉴别器的对抗一致性训练策略(ACTS)。第一鉴别器学习标记和未标记数据之间的先验关系,第二鉴别器学习同一数据在不同数据扰动下分割网络的图像级一致性。两种识别器都旨在提高分割网络从有标记数据到无标记数据的知识转移能力。
(2)设计了一种基于动态卷积的双向注意组件(bidirectional attention component, DyBAC),该组件能够充分挖掘样本的先验知识,并根据不同的输入样本动态调整卷积核的参数。DyBAC能有效地提高网络的特征表示能力,避免网络过拟合。
(3)在三个具有挑战性的医学图像分割任务中,我们广泛地验证了该方法的性能,实验表明,与最先进的方法相比,所提出的网络是非常有竞争力的。值得一提的是,我们提出的网络是一个轻量级的网络,需要更少的参数,具有比比较网络更快的推理速度。
2. 相关工作
半监督医学图像分割:为了解决缺乏大量标注数据的问题,研究者提出了许多用于医学图像分割的半监督学习方法。传统的半监督医学图像分割方法通常采用人工设计的浅层特征,表示能力有限,对对比度低、噪声干扰严重的医学图像分割效果不佳。与上述方法相比,基于深度学习的半监督方法具有强大的特征表示和建模能力[22],能够提供良好的分割结果。目前流行的半监督医学图像分割方法通常使用常规的编码器-解码器分割网络作为骨干网。为了更好地利用无标记数据,更多的方法关注于学习策略的改进。在本文中,我们重点研究如何利用一致性学习[27]和对抗学习[28]来提高网络性能。
在一致性学习方面,目前最先进的技术是Mean Teacher (MT),它通过对学生模型的权值进行累积,在不同的数据扰动下进行一致性学习。具体来说,机器翻译首先是在标注数据上以监督学习的方式进行的。然后,利用MT中的教师模型为未标注数据提供伪标注,并通过不同的正则化方法保持教师和学生模型对未标注数据的预测一致性。最后,通过监督反馈和一致性损失来更新学生模型。其中,教师模型是学生模型权重的指数移动平均(EMA)。该操作使教师模型能够连续累积未标注数据的历史预测信息。后续改进采用不同的一致性正则化策略,提高了未标记数据的预测质量,避免了网络过拟合
例如Li et al.[6]通过引入数据转换一致性的正则化策略,提出了一种转换一致性自集成模型(TCSM v2)来有效利用无标记数据。Chen等人[8]提出了一种基于网络扰动的交叉伪监督(CPS)方法,以鼓励两个扰动网络的预测结果保持高度一致性。然而,计算未标记数据的两个预测之间的一致性可能会导致一些不可靠的指导,从而使训练不稳定。为了解决这一问题,Yu et al.[9]提出了一种基于平均教师结构(Mean Teacher structure, UA-MT)的不确定性感知框架,该框架使学生模型经过多次前向传播后,根据不确定性估计逐渐学习到更可靠的目标。为了减少时间和内存开销,Wu et al.[31]提出了一种相互一致性网络(MC-Net)。该网络包括两个解码器,将两种预测的差异表示为模型不确定性信息,正则化模型训练,从而提高伪标签的质量。Liu等人[32]提出了一种扰动严格均值教师(and strict mean teacher, PS-MT)框架,通过添加辅助教师模型、设计不同的丢失函数、使用不同的数据扰动方法来提高分割精度。此外,Luo et al.[33]通过联合预测目标像素级分割地图和几何感知级别集表示,构建了一种双任务一致性(DTC)正则化方法。DTC关注的是任务级别的一致性而不是数据级别的一致性。
对抗学习是一种通过有效挖掘未标记数据中的潜在知识来提高模型鲁棒性的常用策略。例如,Zhang et al.[12]提出了一种深度对抗网络(deep arial network, DAN)来提高未标记数据的预测质量。然而,目前流行的半监督对抗学习方法[11][12][28]只包含单个生成器和单个鉴别器,这可能会由于过度依赖单个网络的结果而导致分割精度较低。因此,从分割精度较低的模型中获得的知识在学习未标记数据时可能会产生误导。进一步的改进方法[34][35][36][37]兼顾了一致性学习和对抗学习,提高了模型的学习能力。
动态神经网络:传统的深度学习网络以静态的方式进行推理,即训练后的网络参数是固定的。对于不同的输入样本,这些静态网络使用相同的参数与不同的输入组合,输出不同的预测结果,这导致一些复杂的输入样本由于特征表示能力较弱,预测效果较差。与静态网络相反,动态神经网络[38]是指网络结构[39]、参数[40]、特征映射[41][42]在推理阶段根据不同的输入发生变化。例如,在基于注意机制的动态特征网络方面,Gu等人[42]详细展示了注意机制的有效性,并在医学图像分割中取得了较好的效果。因此,动态神经网络与人类视觉系统更加兼容。本文主要研究具有动态参数的卷积神经网络。
Yang et al.[41]提出的条件参数化卷积和Chen et al.[40]提出的动态卷积神经网络(CNN)主要是根据输入图像对不同卷积核的多组权值进行动态聚合,实现动态卷积。但是,这两种方法都导致了参数数量的急剧增加,并且只使用通道的先验知识,而没有考虑特征图的空间信息。为了解决这一问题,对合[43]和解耦动态滤波网络(DDF)[44]提出了空间特异性的思想,使卷积核参数的值随特征图中空间位置的变化而变化。对合和DDF巧妙地利用样本的空间先验知识提取图像的空间结构信息,取得了良好的效果。与上述方法相比,Li等人[45]通过并行策略引入了全维度动态卷积,学习更加灵活的注意力,从而提高网络性能。通常,动态卷积通过根据不同的输入调整网络参数值,对卷积核进行软关注。因此,动态cnn可以有效地利用样本的先验知识来改进特征表示。
与上述方法不同的是,首先,考虑到机器翻译框架,我们将对抗一致性训练策略扩展到半监督学习框架(ACTS),该框架能更好地利用无标记和标记数据之间的本质关系。其次,我们提出了一种基于动态卷积的双向注意组件(bidirectional attention component, DyBAC),旨在降低网络的过拟合风险,并在保持分割精度的同时减少内存开销。
3. 方法
在本文中,我们提出了一个对抗自集成网络(ASE-Net)用于半监督医学图像分割。如图1所示,我们的ASE-Net由分割网络和鉴别网络组成。细分网络由学生模型和教师模型组成。学生模型与教师模型具有相同的结构,两者都是基于编解码结构的;不同的是前者是由损失函数训练的,而后者是学生模型权重的指数移动平均(EMA)。鉴别器网络由卷积层、提出的DyBAC和全局平均池组成,我们的ASE-Net的具体结构如图1所示。
在我们的ASE-Net中,我们提出了一种基于MT框架的对抗一致性训练策略(ACTS)来从未标记数据中挖掘先验知识。为了不同的目的,我们使用两个相同结构的鉴别器。第一鉴别器学习分割网络对未标记数据和标记数据的预测质量一致性。第二鉴别器使用相同的输入,但在不同的扰动下学习教师和学生网络的预测一致性。值得一提的是,我们的鉴别器网络的输入是softmax之后的分割结果与原始图像的拼接,而不仅仅是分割结果。这样,可以进一步评价分割结果的质量,以原始图像为基准,区分分割结果与基准的匹配关系。在网络结构方面,在分割网络和鉴别器网络中,我们采用DyBAC替代除第一层以外的所有卷积层。DyBAC可以提高网络的特征表示能力,降低过拟合的风险。此外,分割网络和鉴别器是交替训练的,在推理阶段不需要鉴别器,避免了额外的计算成本。
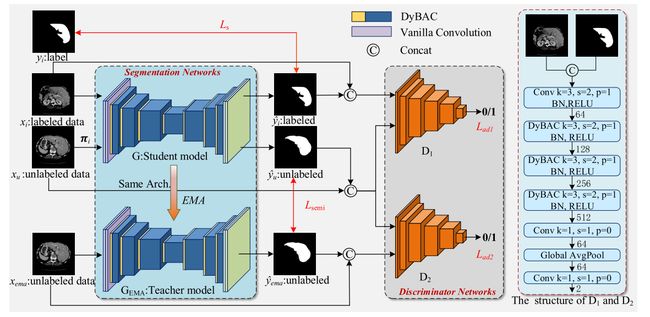
拟议的ASE-Net框架。ase网络由两个主要部分组成:分割网络(左)和鉴别网络(右)。分割网络是基于编码器-解码器的体系结构。右图为判别网络的详细结构,其中k、s、p分别代表卷积核的大小、stride、padding。在推理阶段,鉴别器是不必要的。
3.1 对抗性一致性学习
虽然一致性学习和对抗学习在半监督图像分割任务中是有用的,但它们也有一定的局限性。首先,规则半监督图像分割网络通常采用不同扰动下的一致性策略对模型进行正则化训练。这些网络经常忽略标记和未标记数据之间的先验关系。此外,对于可能导致预测结果不确定的未标记数据,他们只计算像素级的一致性。第二,基于对抗学习的方法过分依赖单一的分割网络和单一的判别网络,容易造成误导问题。
为了解决这些问题,我们提出了一种新的训练策略。如图1所示,我们添加了两个鉴别器,这两个鉴别器结构相同但功能不同。鉴别器 D 1 D_1 D1学习标记数据和未标记数据输出质量之间的差异。鉴别器D2在未标记数据中学习扰动数据和未扰动数据的区别。最后,通过监督损失Ls、一致性损失Lsemi和对抗损失(Lad1, Lad2),鼓励学生网络对未标记数据产生高质量的分割结果。实际上,D2和Lsemi的作用是互补的。一致性损失Lsemi是个体样本间像素级的一致性,更注重特征映射细节。我们的D2主要用于扰动数据与未扰动数据的图像级一致性,更关注特征地图的全局信息。
具体来说,我们通过交替训练实现对抗性一致性学习。首先,将医学图像输入到分割网络中,得到分割预测图;然后,我们将输出的特征映射和相应的原始图像连接到鉴别器网络中。鉴别器主要评价分割结果的质量,0表示分割结果质量差,1表示分割结果质量好。在分割网络G的训练过程中,我们鼓励分割网络对未标记数据xu产生高质量的分割结果,目的是保证结果尽可能接近1。在歧视网络的培训过程中,我们鼓励歧视网络尽可能地歧视不同的输入。因此,学生网络G和两个判别网络D1、D2的优化目标函数定义为:
min G max D 1 , D 2 ( L G ( θ ) + L D 1 ( θ ) + L D 2 ( θ ) ) \min _{G} \max _{D_{1}, D_{2}}\left(L_{G}(\theta)+L_{D_{1}}(\theta)+L_{D_{2}}(\theta)\right) GminD1,D2max(LG(θ)+LD1(θ)+LD2(θ))
其中θ表示待优化参数。对分割网络和鉴别器网络进行了交替训练。分割网络的目标函数LG(θ)定义为:
L G ( θ ) = L s ( y i ^ , y i ) + λ ( L s e m i ( y ^ u , y ^ e m a ) + L a d 1 ( D 1 ( x u , y ^ u ) + L a d 2 ( D 2 ( x u , y ^ u ) ) ) L_G(\theta)=L_s(\hat{y_i},y_i)+\lambda (L_{semi} (\hat{y}_u,\hat{y}_{ema})+L_{ad1}(D_1(x_u,\hat{y}_u)+L_{ad2}(D_2(x_u,\hat{y}_u))) LG(θ)=Ls(yi^,yi)+λ(Lsemi(y^u,y^ema)+Lad1(D1(xu,y^u)+Lad2(D2(xu,y^u)))
式中,Ls(·)表示监督损失,Ls(·)= Lce(·)+ lice(·),Lce(·)为交叉熵损失,lice为Dice损失。Lsemi(·)为MSEloss, Lad1(·)和Lad2(·)均为二元类交叉熵损失。Yi是输入xi对应的标号,xu是无标号的输入数据,通过πi对数据进行扰动。πi为随机高斯噪声。ˆyi和ˆyu分别是标记数据和未标记数据的分割结果。 y ^ e m a \hat{y}_{ema} y^ema为教师网的预测结果, λ \lambda λ为加权系数。根据[6],λ是一条高斯递增曲线,λ = δe(−5(1−I)2), I表示纪元数。
在训练网络的早期,λ的值很小,网络的更新主要依赖于监督损失。因此,在训练网络的早期阶段,主要依靠标注好的数据进行训练。随着训练的进行,λ的值不断增加,网络可以获得可靠的分割结果,并对未标记数据生成目标。这是因为其他损失函数在起作用。然后,鉴别器网络尽力区分分割网络的输出。判别器D1和D2的目标函数定义为:
L D 1 ( θ ) = L a d 1 ( D 1 ( x i , y ^ i ) , 1 ) + L a d 1 ( D 1 ( x u , y ^ u ) , 0 ) L D 2 ( θ ) = L a d 2 ( D 2 ( x e m a , y ^ e m a ) , 1 ) + L a d 2 ( D 2 ( x u , y ^ u ) , 0 ) \begin{array}{c} L_{D_{1}}(\theta)=L_{a d 1}\left(D_{1}\left(x_{i}, \hat{y}_{i}\right), 1\right)+L_{a d 1}\left(D_{1}\left(x_{u}, \hat{y}_{u}\right), 0\right) \\ L_{D_{2}}(\theta)=L_{a d 2}\left(D_{2}\left(x_{e m a}, \hat{y}_{e m a}\right), 1\right)+L_{a d 2}\left(D_{2}\left(x_{u}, \hat{y}_{u}\right), 0\right) \end{array} LD1(θ)=Lad1(D1(xi,y^i),1)+Lad1(D1(xu,y^u),0)LD2(θ)=Lad2(D2(xema,y^ema),1)+Lad2(D2(xu,y^u),0)
其中xi和xema分别表示有标记的数据和无标记的输入。
教师模型的参数是学生模型参数的EMA累积。教师模型保留了学生模型的历史信息,可以为未标记的数据生成更高质量的目标。在[5]和[6]中验证了其有效性,将现有教师模型的参数θt定义为:
θ t ′ = α θ t − 1 ′ + ( 1 − α ) θ t \theta^\prime_t=\alpha \theta^\prime_{t-1}+(1-\alpha)\theta_t θt′=αθt−1′+(1−α)θt
其中参数θt−1是教师模式的历史积累。θt为学生模型的权值。α是平滑系数的超参数,α决定了教师模型与学生模型之间的依赖关系。根据[5][6][9]和实验经验,α值为0.999时,网络的性能最好。
综上所述,细分网络和鉴别网络之间存在着博弈。当鉴别器网络不能区分分割结果和ground truth时,分割网络对标记数据、未标记数据和不同扰动下的数据具有较高的分割质量。这种对抗学习方法可以有效地利用未标记数据来提高预测伪标记的质量。
3.2 基于动态卷积的双向注意组件
过拟合是分割任务中常见的问题。为了克服这一问题,许多基于半监督学习的分割网络采用了不同的一致性正则化策略,如数据摄动,网络参数摄动,特征摄动。然而,这些针对扰动的方法只对特定的任务有效,通常很难为不同的任务有效地选择一致的扰动类型,导致分割效果不理想。此外,由于这些半监督方法仍然使用固定卷积核的分割网络,其自身结构存在潜在的过拟合风险。固定参数值的分割网络只有在任务中有大量像素标记数据的前提下才有效,但在实践中,半监督学习只涉及少量标记数据和大量未标记数据。因此,基于标准卷积的半监督分割网络容易出现过拟合问题,特征表示能力较差。
为了解决上述问题,我们从数据本身出发,对无标签数据按照其结构构造监理信息。具体来说,我们利用动态卷积对每个样本自适应调整一组参数,这样可以更好地利用先验知识,同时降低过拟合风险,提高网络的特征表示能力。此外,为了克服医学图像中对比度低和边缘模糊的问题,我们在使用动态卷积之前增加了空间注意。因此,卷积核的最终值是由空间注意力和动态卷积的结合决定的。因此,将该策略命名为基于动态卷积的双向注意组件(dynamic convolutional bidirectional attention component, DyBAC)。
具体来说,DyBAC的结构如图2所示,对于给定的输入 x i n ∈ R C × H × W x_{in}\in\mathbb{R}^{C\times H\times W} xin∈RC×H×W,其中C表示输入通道数,H和W表示输入特征图的高度和宽度。为了增强重要空间位置的重要性,首先通过空间注意模块对输入特征图进行处理。具体操作如图2 (a)所示。首先,对输入特征图进行 1 × 1 1 × 1 1×1的卷积降维。第二,输出张量被sigmoid激活函数归一化。最后,将得到的空间注意权值乘以输入的特征图像素,得到特征图 x 1 ∈ R C × H × W x_{1}\in\mathbb{R}^{C\times H\times W} x1∈RC×H×W。
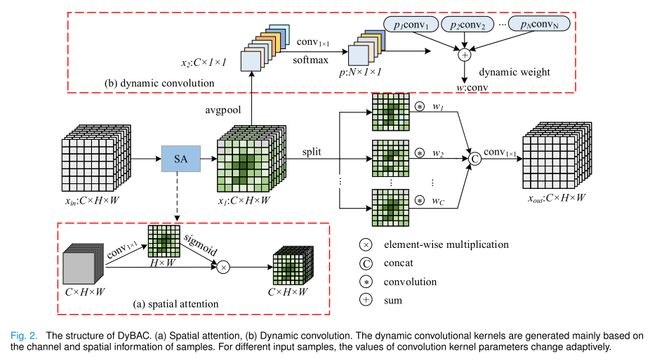
接下来,我们主要介绍动态卷积的生成过程。与SE-Net[47]中的注意机制不同,我们将权值分配给卷积核而不是特征映射。首先,通过全局平均池化层,将feature map x1转化为 x 2 ∈ R C × 1 × 1 x_{2}\in\mathbb{R}^{C\times1\times1} x2∈RC×1×1,然后使用1×1卷积降维,在softmax激活函数后得到 p ∈ R N × 1 × 1 p\in\mathbb{R}^{N\times1\times1} p∈RN×1×1,其中N为卷积核的个数,预先定义为超参数。N可根据具体任务进行设置。在本文中,我们经验地设定N = 4。将得到的系数分别乘以p到N个卷积核,然后将N个卷积核的权值相加,得到一个动态卷积核。这样,我们可以通过动态聚合从N个卷积核中得到最具代表性的卷积核。卷积核的权值w定义为:
w = ∑ i = 1 N ( p i ⋅ c o n v i ) w=\sum_{i=1}^N{(p_i\cdot conv_i)} w=i=1∑N(pi⋅convi)
其中pi是p的第i个系数, 0 ≤ p i ≤ 1 , ∑ i = 1 N p i = 1 0\leq p_{i}\leq1,\sum_{i=1}^{N}p_{i}=1 0≤pi≤1,∑i=1Npi=1, c o n v i conv_{i} convi是第i个卷积核的权。 用 Q s Q_s Qs表示的标准动态卷积的参数数定义为:
Q s = C i n × N + N × C i n × C o u t × k × k , Q_s=C_{in}\times N+N\times C_{in}\times C_{out}\times k\times k, Qs=Cin×N+N×Cin×Cout×k×k,
其中 k × k k\times k k×k是卷积核的大小, C i n C_{in} Cin和 C o u t C_{out} Cout分别表示输入和输出特征映射的通道数。 显然,参数数比香草卷积多N倍。
为了减少参数的数目,我们充分解耦空间和信道的相关性。 具体来说,我们定义了N个深度卷积来提取每个通道的特征,然后利用点卷积来获取不同通道之间的信息。 我们将得到的关注系数乘以相应的卷积核,动态选择一个卷积核进行最终的卷积运算。 我们提出的动态卷积的参数数,用 Q o Q_o Qo表示,定义为:
Q o = C i n × N + N × C i n × k × k + C i n × C o u t . Q_{o}=C_{in}\times N+N\times C_{in}\times k\times k+C_{in}\times C_{out}. Qo=Cin×N+N×Cin×k×k+Cin×Cout.
我们提出的动态卷积的参数个数与标准卷积的比值r为:
r = C in × N + N × C in × k × k + C in × C out C out × C in × k × k = N + N × k × k + C out C out × k × k ≈ 40 + C out 9 × C out ≪ 1. \begin{aligned} r= & \frac{C_{\text {in }} \times N+N \times C_{\text {in }} \times k \times k+C_{\text {in }} \times C_{\text {out }}}{C_{\text {out }} \times C_{\text {in }} \times k \times k} \\ & =\frac{N+N \times k \times k+C_{\text {out }}}{C_{\text {out }} \times k \times k} \approx \frac{40+C_{\text {out }}}{9 \times C_{\text {out }}} \ll 1 . \end{aligned} r=Cout ×Cin ×k×kCin ×N+N×Cin ×k×k+Cin ×Cout =Cout ×k×kN+N×k×k+Cout ≈9×Cout 40+Cout ≪1.
在实际应用中,卷积核大小通常为k=3,cout值大于16,预定卷积数n通常为4。 显然,与Vanilla卷积和标准动态卷积相比,我们的DYBAC大大减少了参数数量。 具体来说,我们的操作是根据每个样本的结构信息自适应地调整卷积核的参数,这与所有样本共享静态参数的Vanilla卷积不同。
4. 实验
5. 讨论
6. 结论
实验设置和评价指标在本工作中,我们提出了一种用于半视觉医学图像分割的ASE-NET。 首先,提出的ACTS有效地结合了对抗性学习和一致性学习,利用对抗性训练最大限度地提高一致性学习。 这使得网络能够快速地学习未标记数据和已标记数据之间的先验关系,并进一步挖掘未标记数据中存在的潜在知识。 然后,我们提出的DYBAC根据输入样本自适应地调整卷积核的参数值,不仅有效地避免了网络过拟合,提高了网络的特征表示能力,而且减少了内存开销。 在三个公开的基准数据集上的实验表明,我们提出的ASE-NET优于现有的方法,为半监督医学图像分割提供了一个有效的解决方案,显著降低了网络过拟合风险和一致性学习中的不确定性预测。