golang学习之二:切片slice
golang切片slice
- 为什么会有切片?
- 切片的创建和初始化
-
- 切片与数组的区别
- 切片的创建
-
- 1、自动推导类型
- 2、借助make函数
- 切片属性(起始下标、长度、容量)
- 切片的操作
-
- 切片截取
- 切片和底层数组关系
- 内建函数
-
- 1、append
-
- 添加数据
- 自动扩容
- 2、copy
- 切片做函数参数
-
- 值传递 还是 引用传递?
- 切片做函数参数的好处
- 切片扩容
- 尽量使用 cap 参数创建 slice
为什么会有切片?
golang中数组的特点(缺点)
1、数组的长度在定义之后无法再次修改;
2、数组是值类型,每次传递都将产生一份副本。显然这种数据结构无法完全满足开发者的真实需求。Go语言提供了数组切片(slice)来弥补数组的不足。
为了解决这两个缺点,所以才有了切片
切片并不是数组或数组指针,它只是一个数据结构,它通过内部指针和相关属性引用数组片段,以实现变⻓方案。 slice 并不是真正意义上的动态数组,而是一个引用类型。slice 总是指向一个底层 array,slice
的声明也可以像 array 一样,只是不需要长度。
golang的切片实现是在包runtime/slice.go,切片结构体包含array指向数组的指针,是一块连续的内存空间,len代表切片的长度,cap代表切片的容量,cap总是大于等于len。
我们来看一下切片的源码:
type slice struct {
array unsafe.Pointer
len int
cap int
}

切片的创建和初始化
切片与数组的区别
slice和数组的区别:声明数组时,方括号内写明了数组的长度,而声明slice时,方括号内没有任何字符或者…。
// 数组的定义,数组里面的长度是固定的一个常量,数组不能修改长度,len和cap永远都是7
a := [7]int{1, 2, 3, 4, 5, 6, 7}
fmt.Println("slice=", a,"\nlen=", len(a), "\ncap=", cap(a))
// 切片的定义:[]里面为空,或者为...切片的长度或容量可以不固定
b := [] int {}
fmt.Println("b=", b,"\nb=", len(b), "\ncap=", cap(b))// [],0,0
// 给切片末尾追加一个成员,再次打印发现长度和容量均发生了变化
b = append(b, 11)// [11],1,1
// 创建切片并初始化
c := []int{1, 2, 3}
// 总之一句话,声明slice时,方括号内没有任何数字,或者为...
切片的创建
1、自动推导类型
// 自动推导类型
s1 := []int{1, 2, 3, 4}
fmt.Println("s1= ", s1)
控制台
s1= [1 2 3 4]
2、借助make函数
借助make函数,格式 make(切片类型,长度,容量)
s2 := make([]int, 5, 10)
fmt.Printf("len = %d, cap = %d\n", len(s2), cap(s2))
控制台
len = 5, cap = 10
如果没有指定容量,那么容量和长度一样
s3 := make([]int, 5)
fmt.Printf("len = %d, cap = %d\n", len(s3), cap(s3))
控制台
len = 5, cap = 5
切片属性(起始下标、长度、容量)
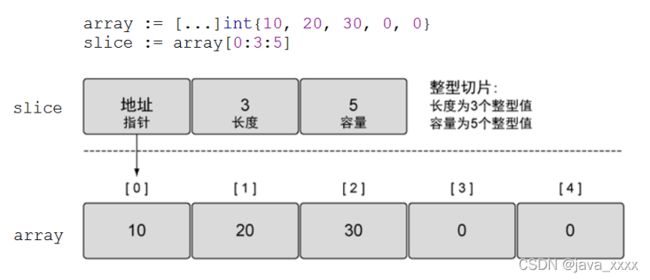
下面我们来从数组里截取一个切片
array := []int{10, 20, 30, 0, 0}
// array[low,high,max]
slice := array[0:3:5]
fmt.Println("slice=", slice,"\nlen=", len(slice), "\ncap=", cap(slice))
// 控制台打印
slice= [10 20 30]
len= 3
cap= 5
上述代码:0,3代表:从数组中的第一个元素开始截取,到索引为3的元素为止(不包括索引为3的元素,即10、20、30),然后切片当前的元素共有10、20、30这三个元素,所以该切片的长度为3。最后一个5表示该切片的容量为5,也就是当前切片在不扩容的情况下最多能放的元素的个数为5个元素,当然了如果再多,切片会自动扩容,新容量为之前容量的2倍。
所以新切片的信息为
// 控制台打印
slice= [10 20 30]
len= 3
cap= 5
我们来详细的看看这个array[0:3:5]可以把它看成array[low:high:max]
low:下标起点(切片中第一个元素在原数组中的索引下标)
high:下标的终点(不包括此下标),[a[low], a[high])左闭右开
len = high - low,(长度:切片当前所存放的元素的个数)
cap = max - low, (容量: 切片在不扩容的情况下最多能放的元素的个数)
cap:绝对不会错的cap计算方式,其实切片的容量就是在原数组中从切片的第一个元素开始,到原数组最后一个元素的元素的个数(包括切片的第一个和原数组最后一个元素)。
如下代码,cap就是5 -1 = 4。即切片第一个元素为20,20在原素组中开始数到最后一个元素0为止,即20、30、0、0,一共有4个元素,所以cap为4。此时切片的长度为4-1=3,即当前切片中所存有的元素个数,20、30、0,一共是3个。
array := []int{10, 20, 30, 0, 0}
slice := array[1:4:5]
可以把切片看成一个杯子,长度就是杯子里当前的水量,容量就是杯子体积在不发生变化时最多能盛的水量(这里不太恰当,切片会自动扩容)。
切片的结构有三部分:
- 1、地址指针
- 2、长度(切片当前所存放的元素的个数)
- 3、容量(切片里最多能放的元素的个数)
切片的操作
切片截取
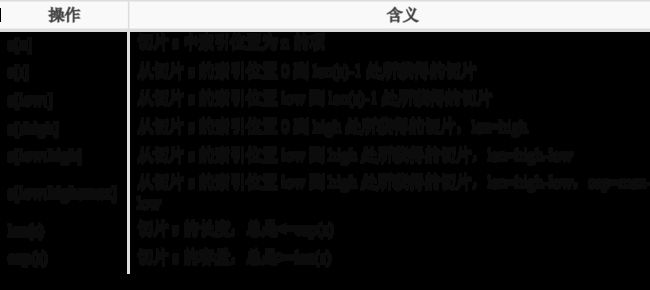
示例说明
array := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
// [low:high:max] 取下标从low开始的元素,len=high-low, cap=max-low
s1 := array[:] // [0:len(array):len(array)] 不指定容量,容量和长度一样

注:切片的容量:切片的容量就是在原数组中从切片的第一个元素开始,到原数组最后一个元素的元素的个数(包括切片的第一个和原数组最后一个元素)。
切片和底层数组关系
修改切片中某个元素的值,对应的原数组中的值也会被改变,所以切片依旧指向原底层数组。
如下代码,注释很详细,这里不再解释
a := []int{1, 2, 3, 4, 5, 6, 7, 8, 9}
// 新切片
s1 := a[2:5]
// s1: [3 4 5] len: 3 cap: 7
fmt.Println("s1:", s1, "len:", len(s1), "cap:", cap(s1))
// 修改切片的第一个元素的值
s1[0] = 666
// 打印s1: [666 4 5] len: 3 cap: 7
fmt.Println("s1:", s1, "len:", len(s1), "cap:", cap(s1))
// 原数组对应的元素也发生了改变
// a: [1 2 666 4 5 6 7 8 9]
fmt.Println("a:", a)
// 创建一个新的切片,该切片是从s1:[3,4,5]的下标索引为2的元素对应原数组的元素5开始至下标为6结束,即5678
// 故,新切片长度为4,容量为5
s2:= s1[2:7]
// 打印:s2: [5 6 7 8 9] len: 5 cap: 5
fmt.Println("s2:", s2, "len:", len(s2), "cap:", cap(s2))
// 修改切片s2的元素
s2[0] = 777
// 打印 s2: [777 6 7 8 9]
fmt.Println("s2:", s2)
// 打印 a: [1 2 666 4 777 6 7 8 9]
fmt.Println("a:", a)
内建函数
1、append
append函数向 slice 尾部添加数据,返回新的 slice 对象,而且如果切片的容量不够,它还会自动帮切片扩容。
添加数据
var s1 []int //创建nil切换
//s1 := make([]int, 0)
// 在原切片的末尾添加元素
s1 = append(s1, 1) //追加1个元素
s1 = append(s1, 2, 3) //追加2个元素
s1 = append(s1, 4, 5, 6) //追加3个元素
fmt.Println(s1) //[1 2 3 4 5 6]
s2 := make([]int, 5)
s2 = append(s2, 6)
fmt.Println(s2) //[0 0 0 0 0 6]
s3 := []int{1, 2, 3}
s3 = append(s3, 4, 5)
fmt.Println(s3)//[1 2 3 4 5]
自动扩容
append函数会智能地底层数组的容量增长,一旦超过原底层数组容量,通常以2倍容量重新分配底层数组,并复制原来的数据:
由一下代码可以看出,当添加的元素超过了切片的容量时,append会将切片的容量变为原先的2倍。
s := make([]int, 0, 1)
for i := 0; i < 50; i++ {
s = append(s, i)
fmt.Println("切片中存放的元素个数:", len(s), ", cap:", cap(s))
}
/*
切片中存放的元素个数: 1 , cap: 1
切片中存放的元素个数: 2 , cap: 2
切片中存放的元素个数: 3 , cap: 4
切片中存放的元素个数: 4 , cap: 4
切片中存放的元素个数: 5 , cap: 8
切片中存放的元素个数: 6 , cap: 8
切片中存放的元素个数: 7 , cap: 8
切片中存放的元素个数: 8 , cap: 8
切片中存放的元素个数: 9 , cap: 16
切片中存放的元素个数: 10 , cap: 16
切片中存放的元素个数: 11 , cap: 16
切片中存放的元素个数: 12 , cap: 16
切片中存放的元素个数: 13 , cap: 16
切片中存放的元素个数: 14 , cap: 16
切片中存放的元素个数: 15 , cap: 16
切片中存放的元素个数: 16 , cap: 16
切片中存放的元素个数: 17 , cap: 32
切片中存放的元素个数: 18 , cap: 32
切片中存放的元素个数: 19 , cap: 32
切片中存放的元素个数: 20 , cap: 32
切片中存放的元素个数: 21 , cap: 32
切片中存放的元素个数: 22 , cap: 32
切片中存放的元素个数: 23 , cap: 32
切片中存放的元素个数: 24 , cap: 32
切片中存放的元素个数: 25 , cap: 32
切片中存放的元素个数: 26 , cap: 32
切片中存放的元素个数: 27 , cap: 32
切片中存放的元素个数: 28 , cap: 32
切片中存放的元素个数: 29 , cap: 32
切片中存放的元素个数: 30 , cap: 32
切片中存放的元素个数: 31 , cap: 32
切片中存放的元素个数: 32 , cap: 32
切片中存放的元素个数: 33 , cap: 64
切片中存放的元素个数: 34 , cap: 64
切片中存放的元素个数: 35 , cap: 64
切片中存放的元素个数: 36 , cap: 64
切片中存放的元素个数: 37 , cap: 64
切片中存放的元素个数: 38 , cap: 64
切片中存放的元素个数: 39 , cap: 64
切片中存放的元素个数: 40 , cap: 64
切片中存放的元素个数: 41 , cap: 64
切片中存放的元素个数: 42 , cap: 64
切片中存放的元素个数: 43 , cap: 64
切片中存放的元素个数: 44 , cap: 64
切片中存放的元素个数: 45 , cap: 64
切片中存放的元素个数: 46 , cap: 64
切片中存放的元素个数: 47 , cap: 64
切片中存放的元素个数: 48 , cap: 64
切片中存放的元素个数: 49 , cap: 64
切片中存放的元素个数: 50 , cap: 64
*/
2、copy
函数 copy 在两个 slice 间复制数据,复制⻓度以 len 小的为准,两个 slice 可指向同⼀底层数组。
就是将短的切片的元素替换掉长的切片的部分元素
如下代码
srcSlice := []int{1, 2}
dstSlice := []int{6, 6, 6, 6, 6}
// 将srcSlice复制到dstSlice里
copy(dstSlice, srcSlice)
// dst= [1 2 6 6 6]
fmt.Println("dst= ", dstSlice)
// dst= [1 2]
fmt.Println("dst= ", srcSlice)
切片做函数参数
值传递 还是 引用传递?
Go语言中的函数传参方式全部都是值传递,不存在引用传递。
切片在当成参数传递的时候也是值传递,那为啥在函数里修改了切片的数据,且未将切片返回,但是函数外的切片取到的值也会修改呢?
原理:
Go语言中的切片事实上就是是一个结构体,其运行时结构如下:
type slice struct {
array unsafe.Pointer
len int
cap int
}
这一点非常重要,这也就意味着,将切片作为函数参数时,其传递机制与结构体传递机制一样,都是值传递,也即传递的是原切片的拷贝。
另外一个非常重要的点就是,切片结构体中的array是一个指针,意味着array的值是底层数组的地址,通过函数传参后,这个值依然没有改变。
因此可以看到,当把切片作为函数参数传递时,在函数中对切片进行某些修改操作,会影响到函数外的原始切片。
切片做函数参数的好处
1、当切片作为函数参数传递给函数是,实际传递的是切片的内部表述,也就是runtime.slice结构体实例,因此无论有切片描述的底层数组有多大,切片最为参数传递带来的性能损耗都是很小且恒定的,甚至小到可以忽略不计,这就是函数在参数中多使用切片而不用数组指针的原因之一。
2、切片可以提供比指针更为强大的功能,比如下标访问、边界益出校验、动态扩容等等。
切片扩容
切片扩容大致过程:append会根据切片的需要,在当前底层数组容量无法满足的情况下,动态分配新的数组,新数组长度会按一定算法扩展(可参见$GOROOT/src/runtime/slice.go中的growslice函数)。新数组建立后,append会把旧数组中的数据复制到新数组中,之后新数组便成为切片的底层数组,旧数组后续会被垃圾回收掉。这样的append操作有时会给大家带来一些困惑,比如通过语法u[low:high]形式进行数组切片化而创建的切片,一旦切片cap触碰到数组的上界,再对切片进行append操作,切片就会和原数组解除绑定。
上面是理论,下面来段代码实战一下,下面这段代码先不看答案,你能写对吗?
package main
import "fmt"
func main() {
u := [...]int{11, 12, 13, 14, 15}
fmt.Println("array:", u) // [11, 12, 13, 14, 15]
s := u[1:3]
fmt.Printf("slice(len=%d, cap=%d): %v\n", len(s), cap(s), s) // [12, 13]
s = append(s, 24)
fmt.Println("after append 24, array:", u)
fmt.Printf("after append 24, slice(len=%d, cap=%d): %v\n", len(s), cap(s), s)
s = append(s, 25)
fmt.Println("after append 25, array:", u)
fmt.Printf("after append 25, slice(len=%d, cap=%d): %v\n", len(s), cap(s), s)
s = append(s, 26)
fmt.Println("after append 26, array:", u)
fmt.Printf("after append 26, slice(len=%d, cap=%d): %v\n", len(s), cap(s), s)
s[0] = 22
fmt.Println("after reassign 1st elem of slice, array:", u)
fmt.Printf("after reassign 1st elem of slice, slice(len=%d, cap=%d): %v\n", len(s), cap(s), s)
}
控制台打印:
array: [11 12 13 14 15]
slice(len=2, cap=4): [12 13]
after append 24, array: [11 12 13 24 15]
after append 24, slice(len=3, cap=4): [12 13 24]
after append 25, array: [11 12 13 24 25]
after append 25, slice(len=4, cap=4): [12 13 24 25]
after append 26, array: [11 12 13 24 25]
after append 26, slice(len=5, cap=8): [12 13 24 25 26]
after reassign 1st elem of slice, array: [11 12 13 24 25]
after reassign 1st elem of slice, slice(len=5, cap=8): [22 13 24 25 26]
我们看到当 append 25 之后,切片的元素已经触碰到了底层数组 u 的边界;此后再 append 26 后,append 发现底层数组已经无法满足 append 的要求,于是新创建了一个底层数组(数组长度为 cap(s)的 2 倍,即 8),并将 slice 的元素拷贝到新数组中了。这之后,我们即便再修改 slice 的第一个元素值,原数组 u 的元素也没有发生任何改变了,因为此时切片 s 与数组 u 已经解除了“绑定关系”,s 已经不再是数组 u 的“描述符”了,s是扩容后的新数组的描述符。
这就好比有一个容量为1的切片叫丁原(u),然后吕布(s)认他做了义父,但是董卓向该切片里放了一匹赤兔马(append操作),但是切片放不下,不过董卓财大气粗啊,就对吕布说:奉先吾儿,跟咱家保准你吃香的喝辣的,于是吕布就认了董卓当义父(s指向了新数组),所以以后再骂吕布的义父就是在骂董卓了,和丁原无关了(通过s改变切片的元素的值,原切片u的值不会发生变化)。忍不住感叹,好一个贼吕布,好一个三姓家奴。
尽量使用 cap 参数创建 slice
我们看到 append 操作是一并利器,它让 slice 类型部分满足了“零值可用”的理念。但从 append 的原理中我们也能看到重新分配底层数组并拷贝元素的操作代价还是蛮大的,尤其是当元素较多的情况下。那么如何减少或避免为过多内存分配和拷贝付出的代价呢?一种有效的方法就是根据 slice 的使用场景在为新创建的 slice 赋初值时使用 cap 参数。
s := make([]T, 0, cap)
个人学习笔记,不喜勿喷