【Python】第七课 文件存储
7.1 初识文件的读写
在Python中,使用open()这个 函数来打开文件并返回文件对象:
open(file,mode="r",buffering=-1,encoding=None,errors=None,newline=None,closefd=True,opener=None)
第一个参数是传入文件名,如果只有文件名不带路径,那么Python会在当前文件夹中去找到该文件并打开。称为相对路径。
第二个参数是设置打开文件的访问模式
| 打开模式 | 执行操作 |
|---|---|
| “r” | 以只读方式打开文件(默认) |
| “w” | 以写入方式的方式打开文件,会覆盖已存在的文件 |
| "x" | 如果文件已存在,使用此模式打开将引发异常 |
| "a" | 以写入模式打开,如果文件存在,则在末尾追加写入 |
| "b" | 以二进制模式打开文件 |
| "t" | 以文本模式打开(默认) |
| "+" | 可读写模式(可添加到其他模式中使用) |
| "U" | 通用换行符支持 |
通过open()方法根据指定的路径打开文件,并获得该文件对象,需要通过以下方法读取或者写入数据到文件中。
| 文件对象的方法 | 执行操作 |
|---|---|
| close() | 关闭文件 |
| read(size=1) | 从文件读取size个字符,当未给定size或给定负值的时候,读取剩余的所有字符,然后作为字符串返回 |
| readline() | 从文件中读取一整行字符串 |
| write(str) | 将字符串str写入文件 |
| writelines(seq) | 向文件写入字符串序列seq,seq应该是一个返回字符串的可迭代对象 |
| seek(offset,from) | 在文件中移动文件指针,从from(0代表文件起始位置,1代表当前位置,2代表文件末尾)偏移offest个字节 |
| tell() | 返回当前在文件中的位置 |
# 先将txt文件放置项目的根路径下,作为相对路径读取文件
def read1():
f = open("file/book.txt", mode="r", encoding="UTF-8")
info = f.read()
print(info)
f.close()
def write1(t):
f = open("file/book.txt", mode="w", encoding="UTF-8")
f.write(t)
f.close()
def write2(t):
f = open("file/book.txt", mode="a", encoding="UTF-8")
f.write(t)
f.close()close()方法用于关闭文件。文件在每次读取或者写入之后需要进行文件关闭操作。而Python拥有垃圾收集机制,会在文件对象的引用计数降至零的时候自动关闭文件,所以在Python编程中,如果忘记关闭文件并不会造成内存泄露那么危险的结果。但并不是说就可以不要关闭文件,如果你对文件进行了写入操作,那么应该在完成写入之后关闭文件。因为Python可能会缓存你写入的数据,如果中途发生类似断点之类的事故,那么缓存的数据根本就不会写入到文件中,所以,为了安全起见,要养成使用完文件后立刻关闭的好习惯。
def read2():
f = open("file/book.txt", mode="r", encoding="UTF-8")
info = f.read()
print(info)
print("读取到当前字符所在的位置:",f.tell())
#第一个参数是起始位置,第二个参数表示以起始位置往后的偏移量
print("改变当前读取的位置:",f.seek(0,0))
#读取改变后位置之后的字符个数
info1=f.read(3)
print(info1)
#打印读取之后,当前所在的位置
print("读取之后当前所在的位置:",f.tell())
f.close()#循环读取每一行数据,也可以使用readline方法进行按行读取
def read3():
f = open("file/book.txt", mode="r", encoding="UTF-8")
#将当前指针移动至开始位置
f.seek(0,0)
for txt in f:
print(txt,end="")课后练习:建立一个txt文本,文本中编写一些模拟数据,模拟客服和顾客之间的三段对话,每段对话之间用----------------------------分割线隔开。
问题:将每段对话的客服的话以及顾客的对话分离开,存储在user1.txt和worker1.txt文件中,三段对话的数据分别存储在user1.txt,user2.txt,user3.txt,worker1.txt,worker2.txt,worker3.txt中。
def save(user,worker,count):
file_name_user="user"+str(count)+".txt"
file_name_worker="worker"+str(count)+".txt"
#给新建的指定文件中写入数据
user_file=open(file_name_user,"w")
worker_file=open(file_name_worker,"w")
# 按行写入
user_file.writelines(user)
worker_file.writelines(worker)
#写入完毕后,关闭对象
user_file.close()
worker_file.close()
# 读取指定文件中的数据,进行按分隔符进行分割
def split_file(file_name):
#定义变量,用于定位当前是第几段话
count=1
#定义列表,用于临时存储每一段话,用户的对话
user=[]
#定义列表,用于临时存储每一段话,客服的对话
worker=[]
#读取指定的文件
f=open(file_name)
#循环遍历每一行文本信息
for line in f:
#匹配去除掉客服名字或者顾客的名字
if line[:4] !="-------------------------":
#如果不是分隔符,说明是数据,将每一行数据临时存储在列表中
#将每一行数据按冒号分割成元组,返回索引值为1的第二个部分
(role,line_spoken)=line.split(":",1)
if role=="顾客":
# 如果是顾客则存储至顾客的列表中
user.append(line)
if role=="客服":
# 如果是顾客则存储至客服的列表中
worker.append(line)
else:
#如果是匹配到分隔符,则表示一段已经读取完一段,将这一段分开读取的数据存储到txt文本中
save(user,worker,count)
user=[]
worker=[]
count+=1
save(user,worker,count)
f.close()
split_file("info.txt")7.2 基于OS模块的文件读写
| 函数名 | 使用方法 |
|---|---|
| getcwd() | 返回当前工作目录 |
| chdir(path) | 改变工作目录 |
| listdir(path=".") | 列举指定目录中的文件名("."表示当期那目录,".."表示上一级目录) |
| mkdir(path) | 创建单层目录,如该目录已存在抛出异常 |
| makedirs(path) | 递归创建多层目录,如果该目录已存在则抛出异常,注意:"E:\\a\\b"和“E:\\a\\c”并不冲突 |
| remove(path) | 删除文件 |
| rmdir(path) | 删除单层目录,如果该目录非空则抛出异常 |
| removedirs(path) | 递归删除目录,从子目录到父目录逐层尝试删除,遇到目录非空则抛出异常 |
| rename(old,new) | 将文件名old重命名为new |
| system(command) | 运行系统的shell命令 |
| os.curdir | 指当前目录 |
| os.pardir | 指上一级目录 |
| os.sep | 输出操作系统特定的路径分隔符(在window下为“\\”) |
| os.linesep | 当前平台使用的行终止符(在window下为\r\t) |
| os.name | 指当前使用的操作系统(包括posix,nt,mac,os2,ce,java) |
1.getcwd()
用于获得当前项目的工作目录,那么可以使用该方法获得
# os模块的使用
# 获得当前项目的目录
import os
print(os.getcwd())
#运行结果:D:\wd\pythonfile\2022PythonBase2.chdir(path)
该方法可以改变当前工作目录,比如可以切换到C盘:
# 切换工作目录
os.chdir("C:\\")
print(os.getcwd())3.listdir(path)
该方法用于获得某指定文件夹路径下的所有子文件夹以及文件的名称
# 获得子文件夹及文件名称
print(os.listdir())
#['.idea', 'file', 'Test1.py', 'Test2.py', 'Test3.py', 'Test4.py', 'Test5.py', 'Test6.py', 'venv']
print(os.listdir("D:\\wd\\eclipse_work_2022"))
#['.metadata', '.recommenders', 'BPSJNet', 'FoodFilter', 'RemoteSystemsTempFiles', 'Servers']通过运行结果发现得到的数据是存储在列表中的
4.mkdir(path)
该方法用于创建文件夹,如果该文件夹存在,则不会再创建,抛出FileExistsError异常
# 在当前项目中,创建文件夹
os.mkdir("newDir")
5.makedirs(path)
该函数用于创建多层目录
# 在当前项目中,创建多级文件夹
os.makedirs(r"newDirs\a\b\c") 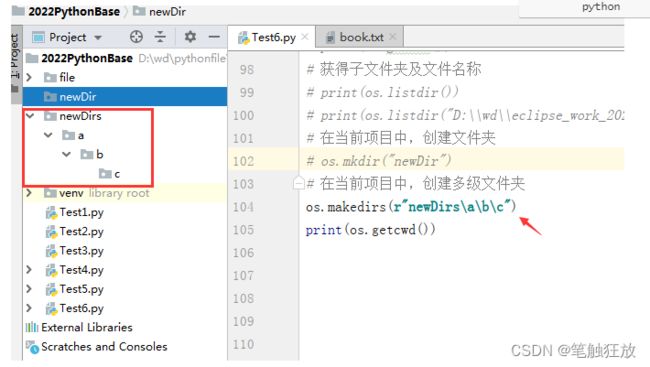
6.remove(path),rmdir(path),removedirs(path)
remove(path)用于删除指定的文件,当不会删除文件夹
rmdir(path)用于删除指定的文件夹
removedirs(path)用于删除指定的多层文件夹
# 删除newDir文件夹中的文件
os.remove(r"newDir\aaa.txt")
# 删除指定的文件夹
os.rmdir("newDir")
#删除指定的多层文件夹
os.removedirs(r"newDirs\a\b\c")7.rename(old,new)
该方法用于重命名文件或者文件夹
# 重命名
os.rename("file","newfile")
os.renames("newfile","newFile111")8.system(command)
启动window系统自带的小应用
#打开计算器
os.system("calc")可点击电脑中查看各个小应用的名称,python都能打开。
9.walk(top)
该函数的作用是遍历top参数指定路径下的所有子目录,并将结果返回一个三元组(路径,包含目录,包含文件)
#遍历某个文件夹下的所有子文件
for file in os.walk(r"D:\wd\pythonfile\2022PythonBase"):
print(file)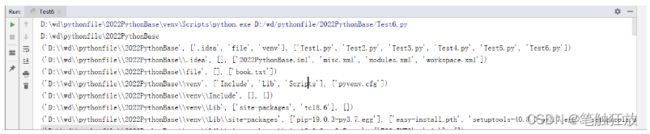
os模块中还提供了一个很强大的模块,有一下常用方法
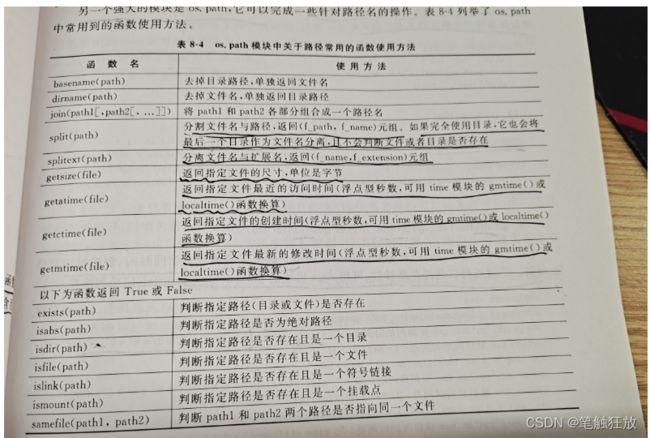
10.basename(path),dirname(path)
用于将一个文件路径的路径和文件名进行分开获取
#分离文件名称
print(os.path.basename(r"file\book.txt"))
#分离文件路径
print(os.path.dirname(r"file\book.txt"))11.join(path1,path2,……)
将多个文件路径进行组合起来
print(os.path.join(r"c:\\project\test","book.txt"))12.split(path)和splittext(path)
两个函数都用于分割路径,前者用于分割路径和文件名,不会判断路径是否存在,后者将文件的后缀和文件路径分割开。
print(os.path.split(r"a\b\test.txt"))
#("a\\b","test.txt")
print(os.path.splittext(r"a\b\test.txt"))
#("a\\b\\test",".txt")13.getsize(file)
该方法用于获得指定文件路径的文件夹或者文件所占磁盘的内存大小,以字节为单位
print(os.path.getsize(r"D:\wd\pythonfile\2022PythonBase"))
运行结果:409614.getatime(file),getctime(file),getmtime(file)
第一个方法用于获得文件的最近访问时间,第二个方法用于获得文件的创建时间,第三个方法用于获得文件的最近修改时间,只不过返回的是浮点型的秒数,需要转换格式。这里可以使用time模块的方法来转换时间格式
import time
temp=time.localtime(os.path.getatime("file"))
print("最近访问时间:",time.strftime("%Y{0}%m{1}%d{2} %H:%M:%S",temp).format("年","月","日"))
temp=time.localtime(os.path.getctime("file"))
print("创建的时间:",time.strftime("%Y{0}%m{1}%d{2} %H:%M:%S",temp).format("年","月","日"))
temp=time.localtime(os.path.getmtime("file"))
print("最近修改时间:",time.strftime("%Y{0}%m{1}%d{2} %H:%M:%S",temp).format("年","月","日"))运行结果:
最近访问时间: 2022年08月01日 10:42:13 创建的时间: 2022年08月01日 10:06:08 最近修改时间: 2022年08月01日 10:42:13
7.3 基于pickle模块的复杂数据类型的读写
import pickle
# 将列表数据以二进制的格式存储在文件中
list1=[3.14,"哈哈","abc",True]
path=open(r"D:\wd\pythonfile\2022PythonBase\file\my_list.pkl","wb")
pickle.dump(list1,path)
path.close()
# 读取存储的二进制格式的列表数据
path=open(r"D:\wd\pythonfile\2022PythonBase\file\my_list.pkl","rb")
info=pickle.load(path)
print(info)