第三节 Hadoop学习案例——MapReduce课程设计 好友推荐功能
提示:文章内容主要以案例为主
目录
前言
项目说明
一,程序需求
1.需求
2.数据
二,编码操作
1.项目建包目录
2.FriendsRecommend.java
3.FriendsRecommendMapper.java
4.FriendsRecommendReduce.java
三,Xshell运行的步骤
1.创建目录
2.上传程序
3.分布式文件系统上传测试数据
4.执行程序
5. 查看结果
总结
前言
项目说明
- 互为推荐关系
- 非好友的两个人之间存在相同好友则互为推荐关系
- 朋友圈两个非好友的人,存在共同好友人数越多,越值得推荐
- 存在一个共同好友,值为1;存在多个值累加
提示:以下是本篇文章正文内容,下面案例可供参考
一,程序需求
1.需求
- 程序要求,给每个人推荐可能认识的人
- 互为推荐关系值越高,越值得推荐
- 每个用户,推荐值越高的可能认识的人排在前面
2.数据
- 数据使用空格分割
- 每行是一个用户以及其对应的好友
- 每行的第一列名字是用户的名字,后面的是其对应的好友
- 数据准备:friend.txt
xiaoming laowang renhua linzhiling
laowang xiaoming fengjie
renhua xiaoming ligang fengjie
linzhiling xiaoming ligang fengjie guomeimei
ligang renhua fengjie linzhiling
guomeimei fengjie linzhiling
fengjie renhua laowang linzhiling guomeimei二,编码操作
1.项目建包目录
2.FriendsRecommend.java
package org.hadoop.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class FriendsRecommend {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(FriendsRecommend.class);
Path input = new Path(args[0]);
FileInputFormat.addInputPath(job, input);
Path output = new Path(args[1]);
//如果文件存在,,删除文件,方便后续调试代码
if (output.getFileSystem(conf).exists(output)) {
output.getFileSystem(conf).delete(output,true);
}
FileOutputFormat.setOutputPath(job, output);
job.setMapperClass(FriendsRecommendMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setReducerClass(FriendsRecommendReduce.class);
job.waitForCompletion(true);
}
}3.FriendsRecommendMapper.java
package org.hadoop.mr;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.util.StringUtils;
import java.io.IOException;
public class FriendsRecommendMapper extends Mapper {
Text mkey = new Text();
IntWritable mval = new IntWritable();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//不能用双引号,要用单引号 将传递过来的值进行分割
String[] strs = StringUtils.split(value.toString(), ' ');
// 直接好友的 key为直接好友列表 value为0
for (int i = 1; i < strs.length; i++) {
//直接好友关系
mkey.set(fof(strs[0], strs[i]));
mval.set(0);
context.write(mkey, mval);
//间接好友关系 设置value为1
for (int j = i + 1; j < strs.length; j++) {
mkey.set(fof(strs[i], strs[j]));
mval.set(1);
context.write(mkey, mval);
}
}
}
//两个共同好友的间接好友之间,可能存在 B C 和C B 的情况,但是比对累加时,计算机不识别,所以需要字典排序
private static String fof(String str1, String str2) {
//compareTo比较的 正数说明大
if (str1.compareTo(str2) > 0) {
return str2 + ":" + str1;
}
return str1 + ":" + str2;
}
} 4.FriendsRecommendReduce.java
package org.hadoop.mr;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class FriendsRecommendReduce extends Reducer {
private IntWritable mValue = new IntWritable();
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
//
int flg = 0;
int sum = 0;
for (IntWritable value : values) {
if (value.get() == 0) {// 直接关系
flg = 1;
}
sum += value.get(); // 添加间接权重
}
if (flg == 0) {
mValue.set(sum);
context.write(key, mValue);
}
}
}
三,Xshell运行的步骤
1.创建目录
- 创建程序以及数据存放目录
cd /opt/
ls # 如果目录下没有testData目录的话自己手动创建一下即可
cd testData/
mkdir friend
cd friend/
2.上传程序
- 把程序先上传到虚拟机node01里面
cd /opt/testData/friend/
rz

3.分布式文件系统上传测试数据
- 首先上传本地测试文件hello.txt到虚拟机
cd /opt/testData/friend/
rz
![]()
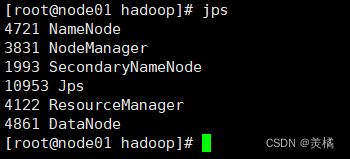
- 确认Hadoop集群已经开启
- 此处必须开启yarn集群
start-dfs.sh
start-yarn.sh
- 分布式文件系统创建input目录并且input目录上传测试文件friend.txt
-
hdfs dfs -mkdir /input
-
hdfs dfs -put friend.txt /input
-
hdfs dfs -ls /input

4.执行程序
hadoop jar FriendsRecommend-1.0-SNAPSHOT.jar /input /output

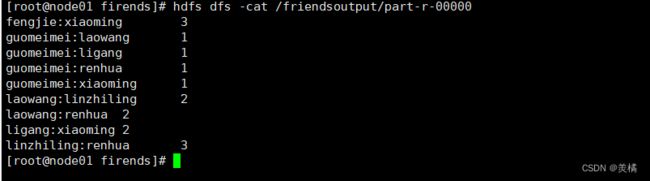
5. 查看结果
hdfs dfs -cat /output/part-r-00000
总结
本文主要介绍了Hadoop学习案例——MapReduce课程设计 好友推荐功能,过程中要注意jar包的打包。