Hive的函数
提示:文章内容仅供参考
目录
前言
一.内置函数
二.处理json数据
三.窗口函数
1.窗口聚合
2.窗口分片
3.窗口排序
4.上下移动
5.首尾值
四.自定义函数
1.自定义UDF
五. Hive的Shell操作
总结
前言
本文就主要介绍hive函数了。
提示:以下是本篇文章正文内容,下面案例可供参考
一.内置函数
类型转换
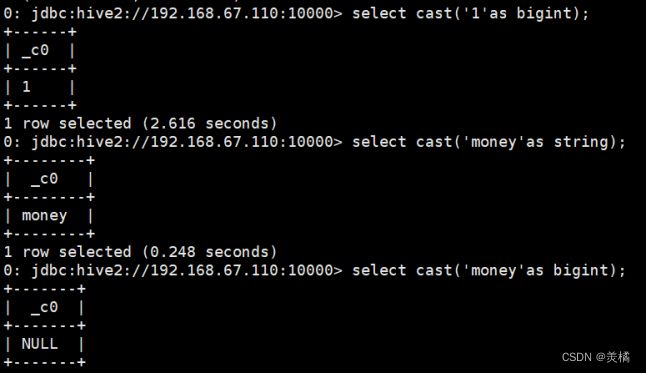
cast(expr as
例:select cast(‘1’ as bignit)
select cast(‘money’ as bignit)
切割
split(string str, string pat)
例:select split('hi|hello|morning','\\|')

正则表达式截取字符串
select regexp_extract(字段名,正则表达式,索引)
regexp_extract(string subject, string pattern, int index)
例:select regexp_extract('helloworldhaha','(.*)',1)

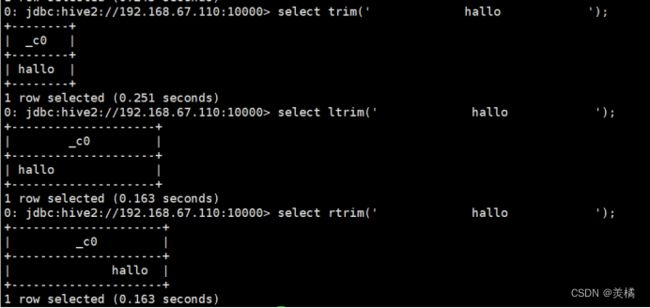
将字符串前后出现的空格去掉
- 去掉首尾空格 : trim(atring A)
- 去掉字段的前置空格 : ltrim(atring A)
- 去掉字段的后置空格 : rtrim(atring A)
例:select trim(‘ hallo ’)
select ltrim(‘ hallo ’)
select rtrim(‘ hallo ’)
求指定列的聚合函数
指定列元素求和:sum(col)
指定列元素平均值:avg(col)
指定列元素最小值:min(col)
指定列元素最大值:max(col)
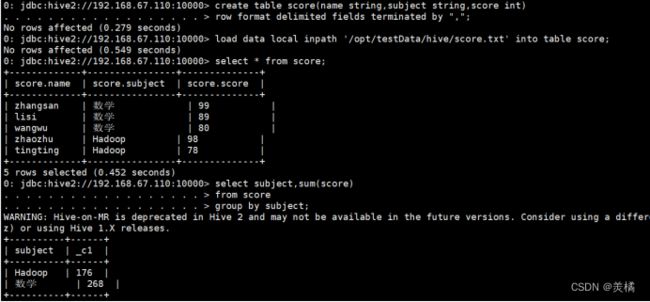
例:数据准备:
name subject score
zhangsan,数学,99
lisi,数学,89
wangwu,数学,80
zhaozhu,Hadoop,98
tingting,Hadoop,78
1.求和:
代码:0: jdbc:hive2://192.168.67.110:10000> select subject,sum(score)
. . . . . . . . . . . . . . . . . . > from score
. . . . . . . . . . . . . . . . . . > group by subject;
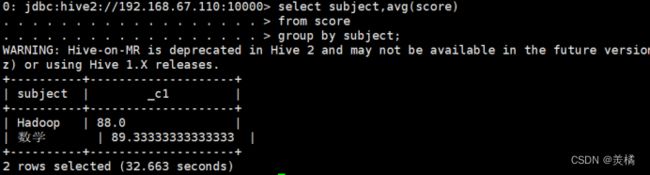
2.平均值:
代码:0: jdbc:hive2://192.168.67.110:10000> select subject,avg(score)
. . . . . . . . . . . . . . . . . . > from score
. . . . . . . . . . . . . . . . . . > group by subject;
3.最小值:
代码:0: jdbc:hive2://192.168.67.110:10000> select subject,min(score)
. . . . . . . . . . . . . . . . . . > from score
. . . . . . . . . . . . . . . . . . > group by subject;
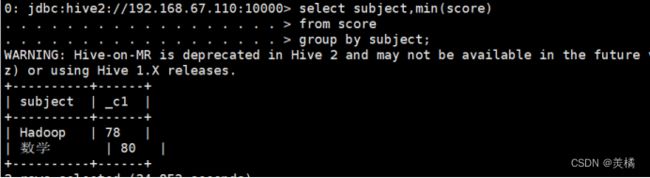
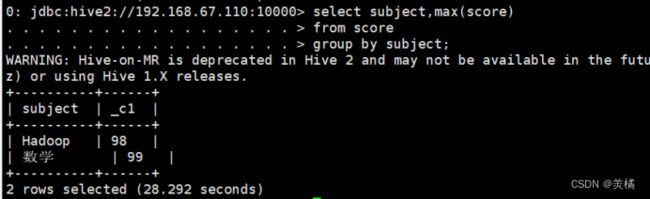
4.最大值:
0: jdbc:hive2://192.168.67.110:10000> select subject,max(score)
. . . . . . . . . . . . . . . . . . > from score
. . . . . . . . . . . . . . . . . . > group by subject;
拼接字符串
代码:concat(string A, string B...)

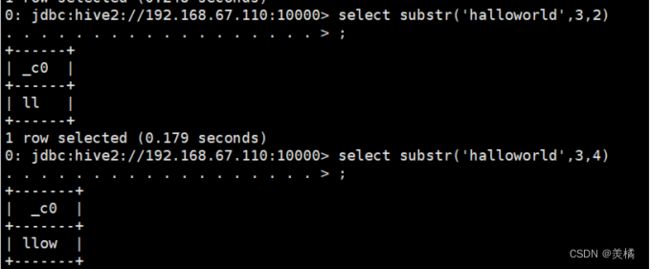
字符串的截取
代码:select substr('halloworld',3,2)
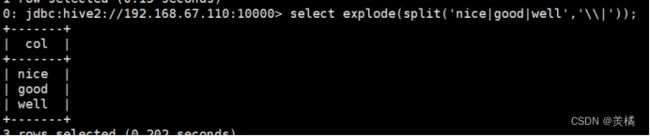
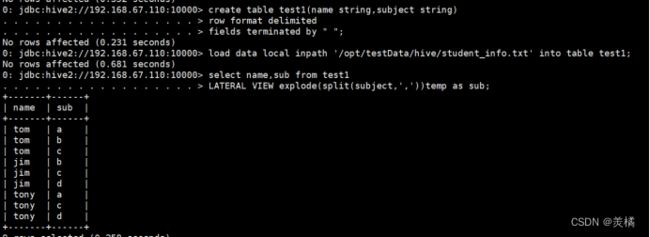
炸裂函数
代码:select explode(split("nice|good|well","\\|"));
例:
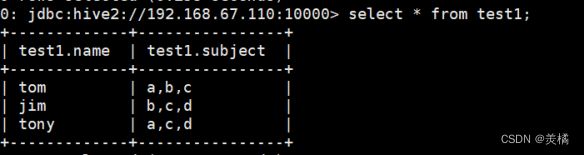
数据准备:
tom a,b,c
jim b,c,d
tony a,c,d
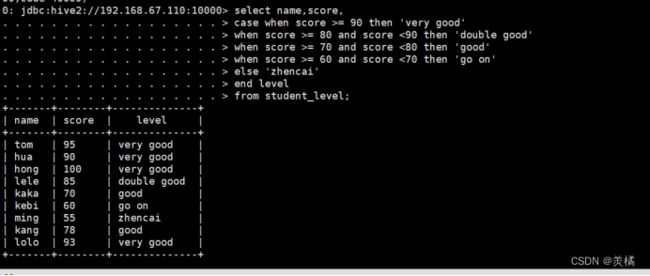
case when
数据准备:
tom,95
hua,90
hong,100
lele,85
kaka,70
kebi,60
ming,55
kang,78
lolo,93

日期处理函数
1.date_format函数(根据格式整理日期)
代码:select date_format('2020-03-05','yyyy-MM');

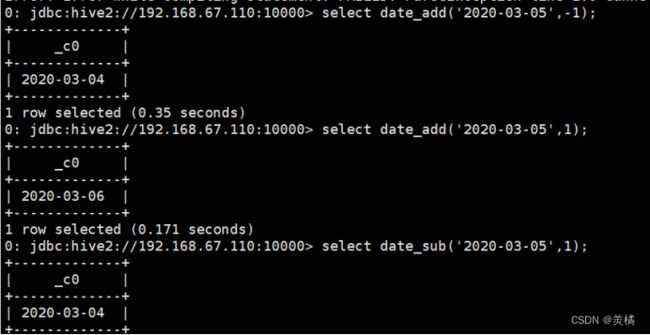
2.date_add函数(加减日期)
代码:select date_add('2020-03-05',-1);
代码:select date_add('2020-03-05',1);
代码:select date_sub('2020-03-05',1);
3.next_day函数
·取当前天的下一个周一
代码:select next_day('2020-03-05','MO');

取当前周的周一
代码:select date_add(next_day('2020-03-05','MO'),-7);

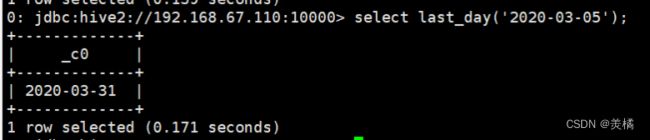
4.list_day函数(求当月最后一天的日期)
代码:select last_day('2020-03-05');
二.处理json数据
现有json数据:
{"movie":"1193","rate":"5","timeStamp":"978300760","uid":"1"}
{"movie":"661","rate":"3","timeStamp":"978302109","uid":"1"}
{"movie":"914","rate":"3","timeStamp":"978301968","uid":"1"}
{"movie":"3408","rate":"4","timeStamp":"978300275","uid":"1"}
{"movie":"2355","rate":"5","timeStamp":"978824291","uid":"1"}
{"movie":"1197","rate":"3","timeStamp":"978302268","uid":"1"}
{"movie":"1287","rate":"5","timeStamp":"978302039","uid":"1"}
{"movie":"2804","rate":"5","timeStamp":"978300719","uid":"1"}
{"movie":"594","rate":"4","timeStamp":"978302268","uid":"1"}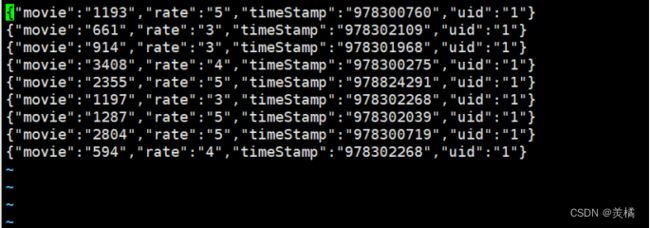
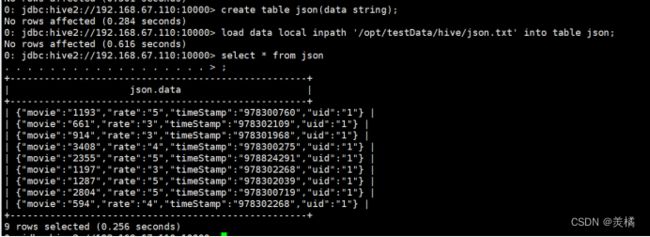
创建表,并load数据。
代码:create table json(data string);
代码:load data local inpath '/opt/testData/hive/json.txt' into table json;
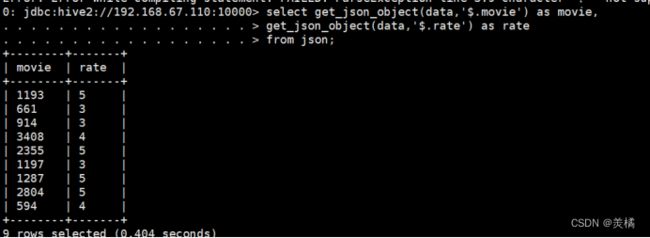
查询json数据。
代码:select get_json_object(data,'$.movie') as movie,
get_json_object(data,'$.rate') as rate
from json;
三.窗口函数
1.窗口聚合
准备数据
cookie1,2015-04-10,1
cookie1,2015-04-13,3
cookie1,2015-04-11,5
cookie1,2015-04-12,2
cookie1,2015-04-15,4
cookie1,2015-04-16,4
cookie1,2015-04-14,4
cookie2,2015-04-14,3
cookie2,2015-04-15,9
cookie2,2015-04-16,7
cookie2,2015-04-10,2
cookie2,2015-04-11,3
cookie2,2015-04-12,5
cookie2,2015-04-13,6创建表。
create table cookie1(cookieid string, createtime string, pv int) row format delimited fields terminated by ',';
加载数据。
load data local inpath "/usr/datadir/cookie1.txt" into table cookie1;
sum(pv) over()
我们通过cookieid分组,createtime排序,求pv的和。
求之前行到当前行的pv和。不加范围限定,默认也是这种。
sum(pv) over(partition by cookieid order by createtime rows between unbounded preceding and current row) as pv1,
sum(pv) over (partition by cookieid order by createtime) as pv2,
如果只进行了分组,没有排序,会将分组内的所有数据进行求和。
sum(pv) over (partition by cookieid) as pv3,
求当前行与前3行的pv和。
sum(pv) over (partition by cookieid order by createtime rows between 3 preceding and current row) as pv4,
当前行的前3行到后2行。
sum(pv) over(partition by cookid order by createtime rows between 3 preceding and 2 following) as pv5,
当前行到最后行。
sum(pv) over (partition by cookieid order by createtime rows between current row and unbounded following) as pv6,
代码
select cookieid,createtime,
pv,
sum(pv) over (partition by cookieid order by createtime rows between unbounded preceding and current row) as pv1,
sum(pv) over (partition by cookieid order by createtime) as pv2,
sum(pv) over (partition by cookieid) as pv3,
sum(pv) over (partition by cookieid order by createtime rows between 3 preceding and current row) as pv4,
sum(pv) over (partition by cookieid order by createtime rows between 3 preceding and 2 following) as pv5,
sum(pv) over (partition by cookieid order by createtime rows between current row and unbounded following) as pv6
from cookie1;avg(pv) over()
min(pv) over()
max(pv) over()
2.窗口分片
数据准备
cookie1,2015-04-10,1
cookie1,2015-04-11,5
cookie1,2015-04-12,7
cookie1,2015-04-13,3
cookie1,2015-04-14,2
cookie1,2015-04-15,4
cookie1,2015-04-16,4
cookie2,2015-04-10,2
cookie2,2015-04-11,3
cookie2,2015-04-12,5
cookie2,2015-04-13,6
cookie2,2015-04-14,3
cookie2,2015-04-15,9
cookie2,2015-04-16,7创建表
create table cookie2(cookieid string, createtime string, pv int)
row format delimited
fields terminated by ',';
加载数据
load data local inpath "/usr/datadir/cookie2.txt" into table cookie2;
查看数据
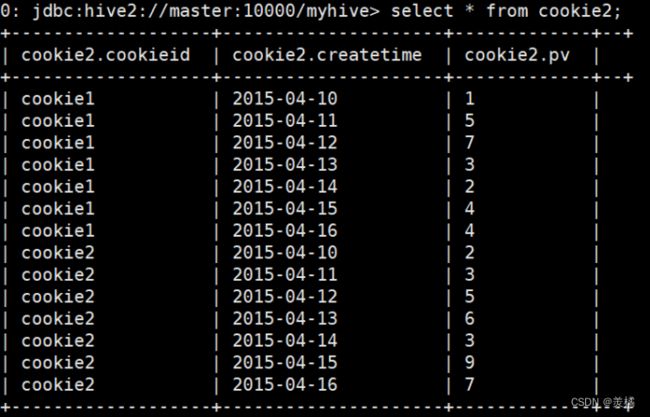
以下不支持rows between
ntile(n) over()
按顺序将组内的数据分为几片,一般用来求前几分之几的数据。
ntile(2) over (partition by cookieid order by createtime) as rn1
ntile(3) over (partition by cookieid order by createtime) as rn2,
如果不加分区,会将所有数据分成多片。
ntile(4) over (order by createtime) as rn3
代码
select cookieid,createtime,
pv,
ntile(2) over (partition by cookieid order by createtime) as rn1,
ntile(3) over (partition by cookieid order by createtime) as rn2,
ntile(4) over (order by createtime) as rn3
from cookie1
order by cookieid,createtime;结果
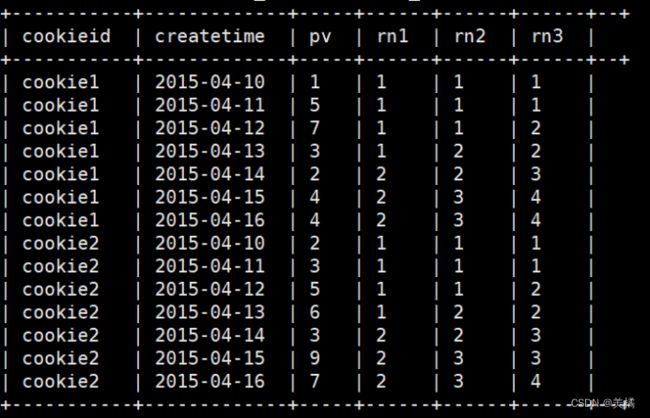
例:比如,统计一个cookie,pv数最多的前1/3的天。
create table cookie_temp
as
select
cookieid,
createtime,
pv,
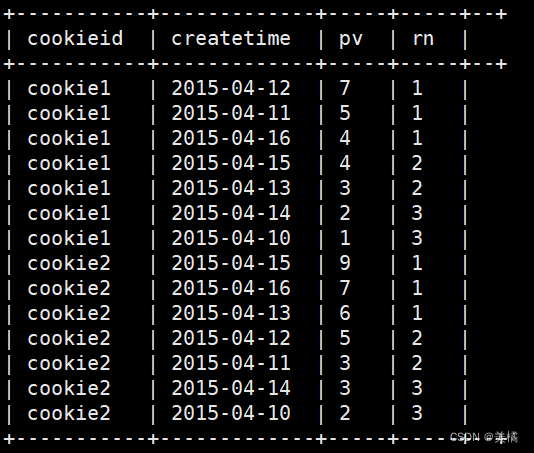
ntile(3) over (partition by cookieid order by pv desc) as rn
from cookie2;结果
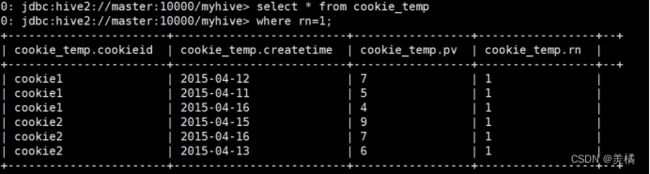
例:我们取rn=1的就是pv最多的前三分之一
3.窗口排序
row_number() over()
分组排序,并记录名次,一般用来取前n名
row_number() over (partition by cookieid order by pv desc) as rn1
100 99 98 98 97 96
1,2,3,4,5,6
rank() over()
rank() over(partition by cookieid order by pv desc) as rn2
100 99 98 98 97 96
1,2,3,3,5,6
dense_rank() over()
dense_rank() over(partition by cookieid order by pv desc) as rn3
100 99 98 98 97 96
1,2,3,3,4,5
代码
select
cookieid,
createtime,
pv,
rank() over (partition by cookieid order by pv desc) as rn1,
dense_rank() over (partition by cookieid order by pv desc) as rn2,
row_number() over (partition by cookieid order by pv desc) as rn3
from cookie2
where cookieid='cookie1';结果
4.上下移动
首先,新建一个node01窗口
然后进入编写文档的文件夹
[root@node01 ~]# cd /opt/testData/hive/
然后新建文件,编辑数据
[root@node01 hive]# vi cookie3.txt
数据准备
cookie1,2015-04-10 10:00:02,url2
cookie1,2015-04-10 10:00:00,url1
cookie1,2015-04-10 10:03:04,url3
cookie1,2015-04-10 10:50:05,url6
cookie1,2015-04-10 11:00:00,url7
cookie1,2015-04-10 10:10:00,url4
cookie1,2015-04-10 10:50:01,url5
cookie2,2015-04-10 10:00:02,url22
cookie2,2015-04-10 10:00:00,url11
cookie2,2015-04-10 10:03:04,url33
cookie2,2015-04-10 10:50:05,url66
cookie2,2015-04-10 11:00:00,url77
cookie2,2015-04-10 10:10:00,url44
cookie2,2015-04-10 10:50:01,url55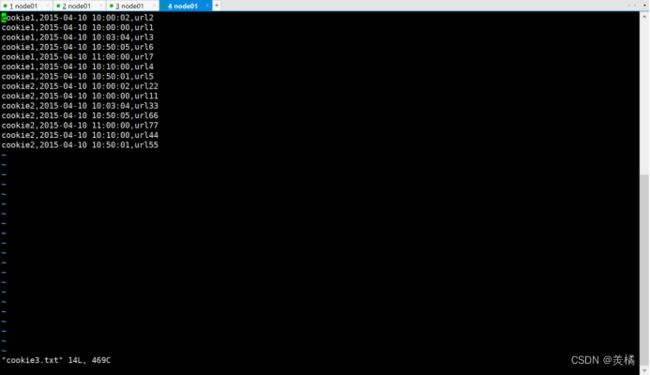
进入hive里
创建表
0: jdbc:hive2://192.168.67.110:10000> create table cookie3(cookieid string, createtime string, url string)
. . . . . . . . . . . . . . . . . . > row format delimited fields terminated by ',';
No rows affected (0.631 seconds)
加载数据
0: jdbc:hive2://192.168.67.110:10000> load data local inpath "/opt/testData/hive/cookie3.txt" into table cookie3;
No rows affected (1.095 seconds)![]()
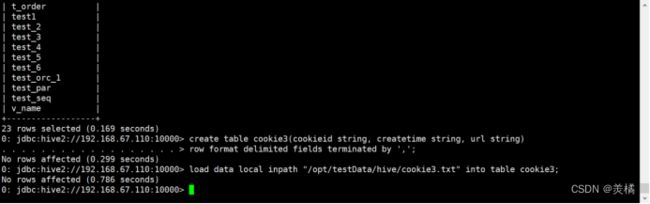
查看数据
0: jdbc:hive2://192.168.67.110:10000> create table cookie3(cookieid string, createtime string, url string)
. . . . . . . . . . . . . . . . . . > row format delimited fields terminated by ',';
No rows affected (0.299 seconds)
0: jdbc:hive2://192.168.67.110:10000> load data local inpath "/opt/testData/hive/cookie3.txt" into table cookie3;
No rows affected (0.786 seconds)
0: jdbc:hive2://192.168.67.110:10000> select * from cookie3;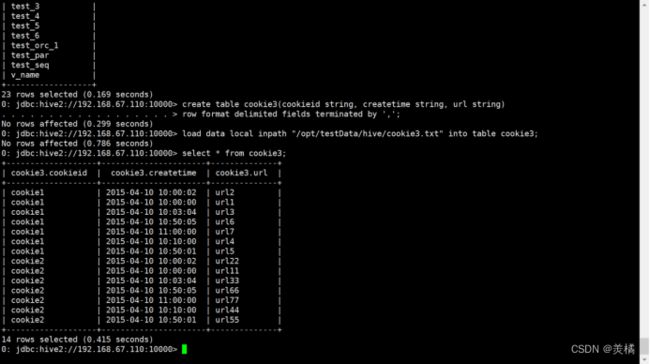
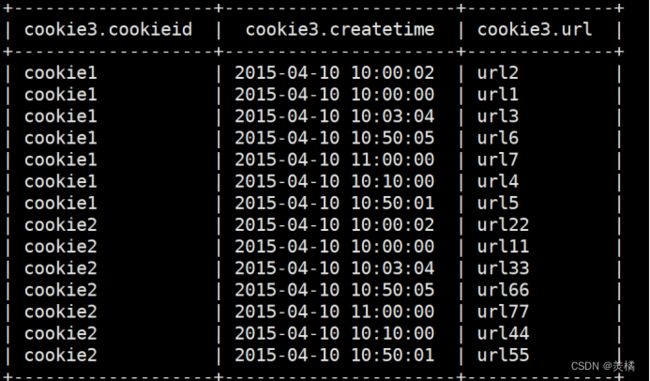
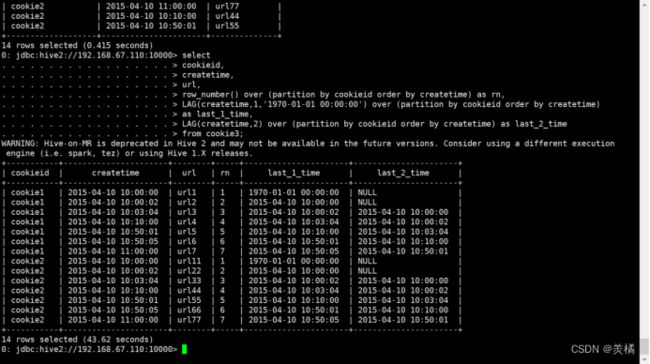
LAG(col,n,DEFAULT)
用于将当前列往上移n行
第一个参数为列名。
第二个参数为往上第n行(可选,默认为1)。
第三个参数为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL)。
LAG(createtime,1,'1970-01-01 00:00:00') over (partition by cookieid order by createtime) as last_1_time
LAG(createtime,2) over (partition by cookieid order by createtime) as last_2_time
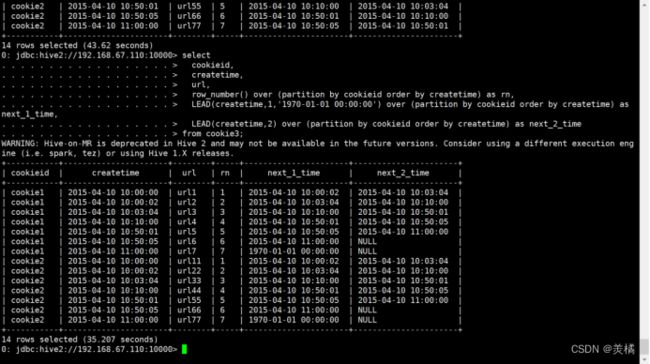
LEAD(col,n,DEFAULT)
与上面的相似,用于将当前列往下移n行。

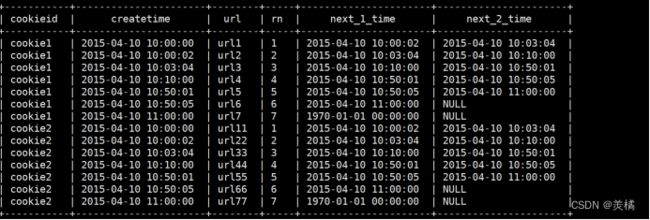
5.首尾值
FIRST_VALUE(url) over ()
分组排序后截至到当前行的第一个值。
FIRST_VALUE(url) over (partition by cookieid order by createtime desc) as last1
LAST_VALUE(url) over ()
分组排序后截至到当前行的最后一个值。
FIRST_VALUE(url) over (partition by cookieid order by createtime desc) as last2
代码
select cookieid,createtime,url,
row_number() over (partition by cookieid order by createtime) as rn,
FIRST_VALUE(url) over (partition by cookieid order by createtime desc) as last1,
LAST_VALUE(url) over (partition by cookieid order by createtime desc) as last2
from cookie3;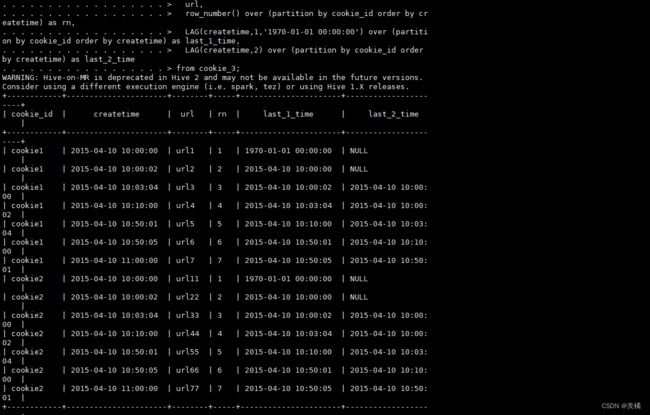
四.自定义函数
当 Hive 提供的内置函数无法满足业务处理需要时,此时就可以考虑使用用户自定义函数。
UDF(user-defined function)作用于单个数据行,产生一个数据行作为输出。
UDAF(用户定义聚集函数 User- Defined Aggregation Funcation):接收多个输入数据行,并产生一个输出数据行。类似于max、min。
UDTF(表格生成函数 User-Defined Table Functions):接收一行输入,输出多行。类似于explode。
1.自定义UDF
- 创建Maven项目,并导入依赖(eclipse中也可将hive-exec的jar包复制进来然后build path)。
org.apache.hive hive-exec 2.3.3 jdk.tools jdk.tools - 自定义一个java类继承UDF,重载 evaluate 方法。
import org.apache.hadoop.hive.ql.exec.UDF; public class ToLower extends UDF { public String evaluate(String field) { String result = field.toLowerCase(); return result; } } - 打成jar包上传到服务器。
4.添加jar包到hive中。

5.创建临时函数与开发好的 class 关联起来。
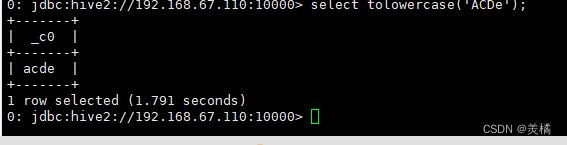
代码:create temporary function tolowercase as 'com.udf.toLower';

6.在HQL种使用
注意:这种方式创建的临时函数只在一次hive会话中有效,重启会话后就无效
7.永久生效。
如果需要经常使用该自定义函数,可以考虑创建永久函数:
拷贝jar包到hive的lib目录下。
创建永久关联函数。
代码:create function tolowercase as 'cn.jixiang.udf.ToLower';
8.删除函数。
删除临时函数
代码:drop temporary function tolowercase;
删除永久函数
代码:drop function tolowercase;
五. Hive的Shell操作
hive -e 从命令行执行指定的HQL
例:hive -e "select * from student"
hive -f 执行 HQL 脚本
例:echo "select * from student" > hive.sql
hive -f hive.sql
总结
提示:这里对文章进行总结:
以上就是今天要讲的内容,本文仅仅简单介绍了hive的函数。