【CS231n assignment 2022】Assignment 3 - Part 5,Self Supervised Learning
前言
- 博客主页:睡晚不猿序程
- ⌚首发时间:2022.8.20
- ⏰最近更新时间:2022.8.20
- 本文由 睡晚不猿序程 原创,首发于 CSDN
- 作者是蒻蒟本蒟,如果文章里有任何错误或者表述不清,请 tt 我,万分感谢!orz
相关文章目录 :
- 【CS231n assignment 2022】Assignment 2 - Part 1,全连接网络的初始化以及正反向传播
- 【CS231n assignment 2022】Assignment 2 - Part 2,优化器,批归一化以及层归一化
- 【CS231n assignment 2022】Assignment 3 - Part 1,RNN
- 【CS231n assignment 2022】Assignment 3 - Part 2,LSTM
- 【CS231n assignment 2022】Assignment 3 - Part 3,Transformer
文章目录
- 前言
- 1. 内容简介
- 2. Self-Supervised Learning
-
- 2.1 什么是自监督学习?
- 2.2 Contrastive Learning: SimCLR
- 2.3 Pretrained Weights
- 2.4 Data Augmentation
- 2.5 Base Encoder and Projection Head
- 2.6 SimCLR: Contrastive Loss
- 2.7 Implement the train function
- 3. 总结、预告
1. 内容简介
上一次作业我们完成了 GAN,这次作业将会是 CS231n 的最后一项作业了,我们在这项作业中将会完成自监督学习
2. Self-Supervised Learning
2.1 什么是自监督学习?
目前现代机器学习需要许多标注数据,但是通常来说,这样的数据的收集很耗费时间且昂贵。
所以自监督学习就出现了,他通过使用未标注的数据自己学习模式
通过自监督学习的方式,模型可以学到一组“好的表达”(Good representation)
2.2 Contrastive Learning: SimCLR
SimCLR 引入了一种新的结构,其使用对比学习来学习好的视觉表达
对比学习致力于学习相似图像的相似表达和不同图像的不同表达
对于数据集的每一个图像,SimCLR会生成两张不一样的增强视图,称为positive pair,接着模型鼓励生成和这两张图相似的表达向量。
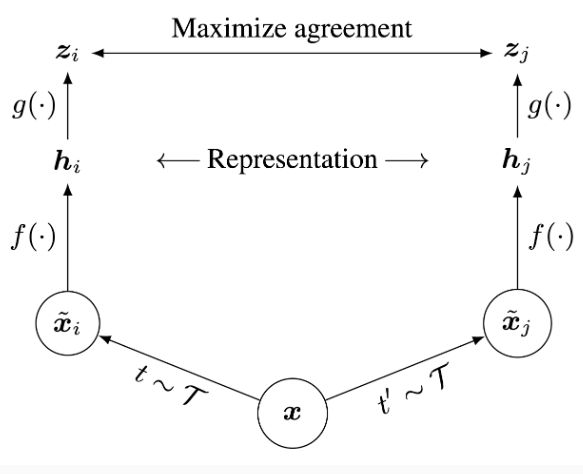
首先给出图片 x,SimCLR 会使用两个不同的数据增强模式 t 和 t’ 来生成 positive pair,f 是一个基本的 encoder 网络,用来抽取表达向量,这将会产生 h i h_i hi 和 h j h_j hj
最后一个小的神经网络g 把向量投影到 contrastive loss 使用的空间当中去
优化的目标为:最大化 z i z_i zi和 z j z_j zj的 agreement
训练完成之后,我们直接丢弃 g,使用 f 和表达 h 来执行下游任务(比如图像分类),我们会在训练好的 SimCLR 上 finetune 一个层来进行分类任务。接着我们会拿一个没有经过自监督学习的模型来作为 baseline 进行对比
2.3 Pretrained Weights
因为我们是在本地运行的,所以接下来的代码块我们无法运行,我们采取手动下载的方式,直接复制他的下载链接下载预训练模型然后复制进去
文件结构如下
2.4 Data Augmentation
第一步是实现 data augmentation,我们要完成cs231n/simclr/data_utils.py中的compute_train_transform()函数
我们对其执行以下随机变换:
- 随机裁切为 32x32
- 水平翻转,机率为 0.5
- 色彩抖动,机率为 0.8
- 转化为灰度图像,机率为 0.2
在做之前,建议先看一下 torchvision 的文档再开始。我们直接来看代码
transform
def compute_train_transform(seed=123456):
"""
This function returns a composition of data augmentations to a single training image.
Complete the following lines. Hint: look at available functions in torchvision.transforms
"""
random.seed(seed)
torch.random.manual_seed(seed)
# Transformation that applies color jitter with brightness=0.4, contrast=0.4, saturation=0.4, and hue=0.1
color_jitter = transforms.ColorJitter(0.4, 0.4, 0.4, 0.1)
train_transform = transforms.Compose([
##############################################################################
# TODO: Start of your code. #
# #
# Hint: Check out transformation functions defined in torchvision.transforms #
# The first operation is filled out for you as an example.
##############################################################################
# Step 1: Randomly resize and crop to 32x32.
# Step 2: Horizontally flip the image with probability 0.5
# Step 3: With a probability of 0.8, apply color jitter (you can use "color_jitter" defined above.
# Step 4: With a probability of 0.2, convert the image to grayscale
transforms.RandomResizedCrop(32),
transforms.RandomHorizontalFlip(0.5),
transforms.RandomApply([color_jitter], 0.8),
transforms.RandomGrayscale(0.2),
##############################################################################
# END OF YOUR CODE #
##############################################################################
transforms.ToTensor(),
transforms.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010])])
return train_transform
__getitem__
class CIFAR10Pair(CIFAR10):
"""CIFAR10 Dataset.
"""
def __getitem__(self, index):
img, target = self.data[index], self.targets[index]
img = Image.fromarray(img)
x_i = None
x_j = None
if self.transform is not None:
##############################################################################
# TODO: Start of your code. #
# #
# Apply self.transform to the image to produce x_i and x_j in the paper #
##############################################################################
x_i = self.transform(img)
x_j = self.transform(img)
##############################################################################
# END OF YOUR CODE #
##############################################################################
if self.target_transform is not None:
target = self.target_transform(target)
return x_i, x_j, target
2.5 Base Encoder and Projection Head
我们接着对增强后的图片执行基本的 Encoder 和映射头
SimCLR 发现使用更深更大的模型表现更好,所以使用了 ResNet 来作为 encoder
映射头 g 使用非线性变换,在这里我们使用了一个单隐层的 MLP 作为 g
作业已经完成了这两部分内容,位于文件cs231n/simclr/model.py,去快速浏览一下确保你理解了
2.6 SimCLR: Contrastive Loss
包含 N 张图片的 minibatch,会生成 2N 张增强样本,接着我们按照如下公式来进行损失的计算
l ( i , j ) = − log exp ( sim ( z i , z j ) / τ ) ∑ k = 1 2 N 1 k ≠ i exp ( sim ( z i , z k ) / τ ) l \; (i, j) = -\log \frac{\exp (\;\text{sim}(z_i, z_j)\; / \;\tau) }{\sum_{k=1}^{2N} \mathbb{1}_{k \neq i} \exp (\;\text{sim} (z_i, z_k) \;/ \;\tau) } l(i,j)=−log∑k=12N1k=iexp(sim(zi,zk)/τ)exp(sim(zi,zj)/τ)
L = 1 2 N ∑ k = 1 N [ l ( k , k + N ) + l ( k + N , k ) ] L = \frac{1}{2N} \sum_{k=1}^N [ \; l(k, \;k+N) + l(k+N, \;k)\;] L=2N1k=1∑N[l(k,k+N)+l(k+N,k)]
我们需要完成sim函数以及loss函数,来看代码
sim
def sim(z_i, z_j):
"""Normalized dot product between two vectors.
Inputs:
- z_i: 1xD tensor.
- z_j: 1xD tensor.
Returns:
- A scalar value that is the normalized dot product between z_i and z_j.
"""
norm_dot_product = None
##############################################################################
# TODO: Start of your code. #
# #
# HINT: torch.linalg.norm might be helpful. #
##############################################################################
norm_dot_product = np.dot(
z_i, z_j)/(torch.linalg.norm(z_i)*torch.linalg.norm(z_j))
##############################################################################
# END OF YOUR CODE #
##############################################################################
return norm_dot_product
similr_loss_naive
def simclr_loss_naive(out_left, out_right, tau):
"""Compute the contrastive loss L over a batch (naive loop version).
Input:
- out_left: NxD tensor; output of the projection head g(), left branch in SimCLR model.
- out_right: NxD tensor; output of the projection head g(), right branch in SimCLR model.
Each row is a z-vector for an augmented sample in the batch. The same row in out_left and out_right form a positive pair.
In other words, (out_left[k], out_right[k]) form a positive pair for all k=0...N-1.
- tau: scalar value, temperature parameter that determines how fast the exponential increases.
Returns:
- A scalar value; the total loss across all positive pairs in the batch. See notebook for definition.
"""
N = out_left.shape[0] # total number of training examples
# Concatenate out_left and out_right into a 2*N x D tensor.
out = torch.cat([out_left, out_right], dim=0) # [2*N, D]
total_loss = 0
for k in range(N): # loop through each positive pair (k, k+N)
z_k, z_k_N = out[k], out[k+N]
##############################################################################
# TODO: Start of your code. #
# #
# Hint: Compute l(k, k+N) and l(k+N, k). #
##############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
sum_k, sum_k_N = 0, 0
for i in range(2*N):
z_i = out[i]
if i != k:
sum_k += torch.exp(sim(z_k, z_i)/tau)
if i != k+N:
sum_k_N += torch.exp(sim(z_k_N, z_i)/tau)
loss1 = -torch.log(torch.exp(sim(z_k, z_k_N)/tau)/sum_k)
loss2 = -torch.log(torch.exp(sim(z_k_N, z_k)/tau)/sum_k_N)
total_loss += loss1+loss2
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
##############################################################################
# END OF YOUR CODE #
##############################################################################
# In the end, we need to divide the total loss by 2N, the number of samples in the batch.
total_loss = total_loss / (2*N)
return total_loss
代码详解
- 我们使用了简单的 for 循环来进行损失计算
接下来我们要使用矩阵运算来完成上面的步骤,完成sim_positive_pairs、compute_sim_matrix和simclr_loss_vectorized函数
def sim_positive_pairs(out_left, out_right):
"""Normalized dot product between positive pairs.
Inputs:
- out_left: NxD tensor; output of the projection head g(), left branch in SimCLR model.
- out_right: NxD tensor; output of the projection head g(), right branch in SimCLR model.
Each row is a z-vector for an augmented sample in the batch.
The same row in out_left and out_right form a positive pair.
Returns:
- A Nx1 tensor; each row k is the normalized dot product between out_left[k] and out_right[k].
"""
pos_pairs = None
##############################################################################
# TODO: Start of your code. #
# #
# HINT: torch.linalg.norm might be helpful. #
##############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
left_norm = out_left / torch.linalg.norm(out_left, dim=1, keepdim=True)
right_norm = out_right / torch.linalg.norm(out_right, dim=1, keepdim=True)
mul = torch.mm(left_norm, right_norm.T)
pos_pairs = torch.diag(mul).view(-1, 1)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
##############################################################################
# END OF YOUR CODE #
##############################################################################
return pos_pairs
def compute_sim_matrix(out):
"""Compute a 2N x 2N matrix of normalized dot products between all pairs of augmented examples in a batch.
Inputs:
- out: 2N x D tensor; each row is the z-vector (output of projection head) of a single augmented example.
There are a total of 2N augmented examples in the batch.
Returns:
- sim_matrix: 2N x 2N tensor; each element i, j in the matrix is the normalized dot product between out[i] and out[j].
"""
sim_matrix = None
##############################################################################
# TODO: Start of your code. #
##############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
out_norm = out / torch.linalg.norm(out, dim=1, keepdim=True)
sim_matrix = torch.mm(out_norm, out_norm.T)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
##############################################################################
# END OF YOUR CODE #
##############################################################################
return sim_matrix
def simclr_loss_vectorized(out_left, out_right, tau, device='cuda'):
"""Compute the contrastive loss L over a batch (vectorized version). No loops are allowed.
Inputs and output are the same as in simclr_loss_naive.
"""
N = out_left.shape[0]
# Concatenate out_left and out_right into a 2*N x D tensor.
out = torch.cat([out_left, out_right], dim=0) # [2*N, D]
# Compute similarity matrix between all pairs of augmented examples in the batch.
sim_matrix = compute_sim_matrix(out) # [2*N, 2*N]
##############################################################################
# TODO: Start of your code. Follow the hints. #
##############################################################################
# Step 1: Use sim_matrix to compute the denominator value for all augmented samples.
# Hint: Compute e^{sim / tau} and store into exponential, which should have shape 2N x 2N.
exponential = torch.exp(sim_matrix / tau)
# This binary mask zeros out terms where k=i.
mask = (torch.ones_like(exponential, device=device) -
torch.eye(2 * N, device=device)).to(device).bool()
# We apply the binary mask.
exponential = exponential.masked_select(
mask).view(2 * N, -1) # [2*N, 2*N-1]
# Hint: Compute the denominator values for all augmented samples. This should be a 2N x 1 vector.
denom = torch.sum(exponential, dim=1, keepdim=True)
# Step 2: Compute similarity between positive pairs.
# You can do this in two ways:
# Option 1: Extract the corresponding indices from sim_matrix.
# Option 2: Use sim_positive_pairs().
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
sim_pairs = sim_positive_pairs(out_left, out_right)
sim_pairs = torch.cat([sim_pairs, sim_pairs], dim=0)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# Step 3: Compute the numerator value for all augmented samples.
numerator = None
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
numerator = torch.exp(sim_pairs / tau)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# Step 4: Now that you have the numerator and denominator for all augmented samples, compute the total loss.
loss = None
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
loss = torch.mean(-torch.log(numerator / denom))
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
##############################################################################
# END OF YOUR CODE #
##############################################################################
return loss
2.7 Implement the train function
接下来我们要完成训练函数
def train(model, data_loader, train_optimizer, epoch, epochs, batch_size=32, temperature=0.5, device='cuda'):
"""Trains the model defined in ./model.py with one epoch.
Inputs:
- model: Model class object as defined in ./model.py.
- data_loader: torch.utils.data.DataLoader object; loads in training data. You can assume the loaded data has been augmented.
- train_optimizer: torch.optim.Optimizer object; applies an optimizer to training.
- epoch: integer; current epoch number.
- epochs: integer; total number of epochs.
- batch_size: Number of training samples per batch.
- temperature: float; temperature (tau) parameter used in simclr_loss_vectorized.
- device: the device name to define torch tensors.
Returns:
- The average loss.
"""
model.train()
total_loss, total_num, train_bar = 0.0, 0, tqdm(data_loader)
for data_pair in train_bar:
x_i, x_j, target = data_pair
x_i, x_j = x_i.to(device), x_j.to(device)
out_left, out_right, loss = None, None, None
##############################################################################
# TODO: Start of your code. #
# #
# Take a look at the model.py file to understand the model's input and output.
# Run x_i and x_j through the model to get out_left, out_right. #
# Then compute the loss using simclr_loss_vectorized. #
##############################################################################
_, out_left = model.forward(x_i)
_, out_right = model.forward(x_j)
loss = simclr_loss_vectorized(out_left, out_right, temperature)
##############################################################################
# END OF YOUR CODE #
##############################################################################
train_optimizer.zero_grad()
loss.backward()
train_optimizer.step()
total_num += batch_size
total_loss += loss.item() * batch_size
train_bar.set_description(
'Train Epoch: [{}/{}] Loss: {:.4f}'.format(epoch, epochs, total_loss / total_num))
return total_loss / total_num
两行代码即可完成
接下来是训练了,但是我的本地主机显卡为 1050 Ti,显存不够,所以训练的过程就没有了iai

总之我们可以知道,经过自监督训练过的模型肯定性能更为优秀!
3. 总结、预告
终于,cs231n作业在暑假结束前更新完成了(是不是作业二少了一半没有更新)
好哒博主会补齐的啦!
因为作业一的内容个人感觉重要性一般所以没有做,如果大家有需要看作业一的解答,请留言博主,博主也会找时间更新的啦!!