大模型的数据供血系统-向量数据库常识科普
1. 数据库行业有了新动向
对于传统数据库研发运维来说,数据库行业上次有概念创新,还是十几年前的NoSQL……
在AI大行业发展的推进下,向量数据库成为了最新兴的数据库技术趋势,业内多家开源向量数据库都拿到了高额融资,腾讯云等多家云厂商,也在将自用的向量数据库包装云化推广给客户。
附录:这个行业的大新闻时间轴
去年8月,Zilliz(Milvus)B轮融资 $103M
今年3月,NVIDIA和OpenAI 同时强调向量数据库的重要性。
今年4月,Chroma: 种子轮融资 $18M
今年4月,Qdrant: 种子轮融资 $7.5M
今年4月,Weaviate: B轮融资 $50M
今年4月,Pinecone: B轮融资 $100M
大部分研发和运维工程师从未接触过向量数据,也更未了解过向量数据库;但是各种大模型和生成式AI技术,都会用到向量数据库。笔者趁着腾讯云发布向量数据库产品的机会,向相关领域技术大牛进行了多次讨教学习,给不了解向量数据库的读者们做一次公益科普。

2. 什么是向量数据
科普的开篇,读者首先弄清楚一个问题,什么是向量数据,向量数据和大模型有什么关系。
“向量-Vector”虽然高中课本就学过,但是计算机领域、大模型领域使用的向量还是和数学向量有点区别。所以本文先举3个向量数据的例子,再举1个向量计算的例子。
举例1:简单向量数据。这个例子就是各种一维数组,类似于各种xy轴、xyz轴的数组。
a=[0.5, 0.3] b=[0.33, -0.59, 0.6] c=[25, 105, -60]
## 常规向量并不限制数值的范围,但是各种AI词嵌入产生的向量一般都是负1到正1之间的偏移量。
举例2:多维矩阵向量数据,无论是描述一堆复杂的东西还是渲染图像,都可以用这个矩阵向量来描述。

举例3:词向量数据,通过向量数值的距离,说明了两者的关联性。这个例子图省事我随便写了3个参数,生产环境中用词嵌入(Embedding)的方式生成带几百个到几十万个维度的词向量。
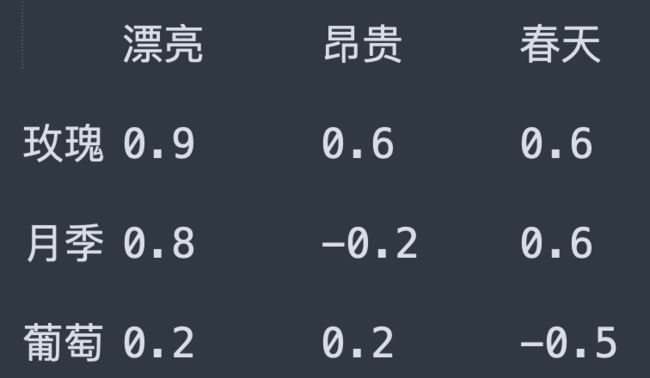
举例4:基于上文的向量数据样例,对下列三句话做相似性运算,找到语义最相近的两句话。
例句A:因为玫瑰花,她很开心。
例句B:因为漂亮的花,她很开心。
例句C:因为东西不贵,她很开心。
标准答案:例句A和例句B相似度最高。
从这四个例子就能看出来,面向AIGC和大模型的向量数据并不是结构化数据,这些数据也需要新的检索和运算方法。向量化的数据,可以完成图片、语音、文本的相似性的搜索,并据此完成推荐系统和问答系统。
3. 向量数据是大模型的供血系统
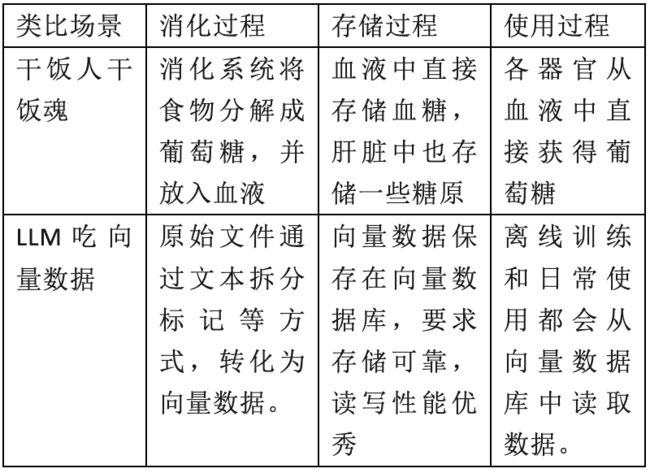
虽然很多科普文章将向量数据库当做大模型的记忆体,但我更愿意称呼向量数据库是大模型的供血系统。大脑管理记忆的运作机制太难解释了,用食物营养和血液的关系打比方,会更通俗易懂。
人类吃食物的过程,需要经历消化、存储和使用的过程,食物首先会被消化系统分解成葡萄糖,葡萄糖既要通过血液循环系统送到肝脏储存,也要通过血液循环系统传递给各种急需葡萄糖的人体器官。

大模型要做模型训练,也不是硬解原始文字或者原始图片,而是和人类吃饭类似,也有个消化、存储和使用的操作逻辑。向量数据库在整个大流程中,发挥的就是血液循环系统的作用。
1.消化数据:大模型应用需要通过数据标注、文本分段、词嵌入等方法,将原始文件分解成向量数据。这一段数据消化工作和本文关注的数据库工作无关,我们只要知道,在此环节开始产生了向量数据。
2.存储数据:向量数据比原始数据更“精粹”,在大部分情况下也比原始数据更重要,这些向量数据应该存储在一个专用的数据库里,这个数据库需要提供稳妥的存储保障,也需要保障数据读取写入时的高性能。
3.使用数据:大模型做脱机训练时,需要大批量读取数据库内大部分向量信息;大模型做业务推演时,可能需要快速补充新闻、知识库、热点信息,此时就需要快速检索定位到具体向量信息;其他应用程序(比如知识图谱)需要依赖向量数据库的数据分析能力,完成向量对比等工作。
4. 向量数据库的需求预估
做数据库选型和预估时,无论是向量数据库还是传统数据库,都要从研发和运维两个方向评估:

笔者了解了多款开源向量数据库和腾讯云向量数据库的功能特性,大致能给出如下选型建议:
第一.预估本业务产生的数据量级,即数据库支持要存储多少条、多大体积的向量数据,以及配套的索引、日志等文件的体积。
第二.预估本业务需要并发读写性能,即数据库(及配套硬件)要支持多大的并发读写,这个需求描述越详细,压测脚本越好写。
第三.根据本项目中数据的存储和更新规则,描述出检索定位数据的思路,然后根据维护索引的成本和索引的检索效率,找到适合的向量索引类型,比如FLAT(扁平扫描)、IVF_FLAT(基于倒排文件的FLAT)、IVF_SQ8、IVF_PQ等等。
第四.根据本项目的数据内容和业务需求,总结出需要哪些向量数据的计算方法。最常见的向量计算方法就是计算多个向量的相似度,在做相似度度量时,可以使用欧几里得距离、余弦相似度、曼哈顿距离等等算法。除了相似度计算,向量还能要做加权平均、内积外积、池化归一化等等计算。
上述内容看似又虚又乱又难,但大家照着中文版官方文档和样例教程实操过几次,就会发现向量数据库和普通数据库没太大区别,都是增删改查而已。

5. 推荐腾讯云向量数据库
如果大家只是测试环境玩一玩,想摸一摸向量数据库的常规操作方法,笔者会推荐在PostgreSQL上安装pgvector扩展。是的,这个陌生的向量世界里,依旧有我们熟悉靠谱的PostgreSQL。
前文提到的融资名单里,都是新兴独立的开源数据库,这些数据库既有英文官方文档,也有容器镜像,动手能力强的朋友,都可以下载测试。
这些开源种子选手都是近两年入局的新秀,大部分都选择由传统数据库负责数据持久化,自己专注于做向量索引和计算方法。这种工作方式在解决向量数据库0到1的阶段很有效,但总感觉有点太粗糙,换你上你也行……
当然了,如果这些种子选手们自行完成了数据持久化工作,我们又该担心他们的存储引擎并未“酒精考验”、年头不久味道不深了。
经过腾讯云朋友的介绍,我更推荐大家使用腾讯云的向量数据库,原因如下:
1.腾讯云的向量数据库并不是跟风现造的热乎项目,而是内部使用多年的老项目ElasticFaiss(新名为OLAMA)的云化改造,软件已经内部自用了五年以上了。他们开数据库发布会时,还特地请OLAMA的技术人员一并讲解了很多技术问题。
2.该向量数据库支撑着整个腾讯集团的所有向量访问请求,我就不列那些规模数字了,毕竟大部分用户的业务规模也到不了腾讯的1%。我是想说,腾讯云有能力组个这么大的资源池,云用户很难把资源池用尽玩崩。
3.腾讯云这次不仅能做数据库,而且一并提供了付费的Embedding+检索的集成方案。笔者仔细咨询,这套方案不是做“使用向量数据库本软件的培训”,而是“使整个大模型项目完成接入向量数据库改造”的经验传递,能够让客户更快速度完成AI业务。
客户找几个精悍的工程师,自学向量数据库的维护和对接并不难。但是说明书上只有使用经验,没有最佳实践,客户自学的技术,无论是做技术决策还是推动其他部门配合时,心里没底气,工作干完了也缺乏解读和验证方法。
腾讯云通过集成方案的方式,能把AI接入的最佳实践脱敏分享给客户,并参与客户的业务接入和业务验收,这种经验复用是难能可贵的。
采用了腾讯云的一体化方案后,客户能将接入向量数据库的工期从30天缩短到3天,客户技术决策层很快能看到引入腾讯云向量数据库,是否能提高AI群集的运算效率,或者降低AI群集的运算成本。
4.腾讯云向量数据库现在就正式公布,但要等到8月份才会正式发布,并不是说这30天里要赶紧编代码或者扩资源,而是他们在认真编写用户使用文档和各种测试用例文档,力求让各位老资格DBA们,能够拿到足够简单、清晰又权威可信的用户使用文档。
