Linux--基础IO
目录
-
- 1. 打开文件
-
- 1.1 系统调用与库函数
- 1.2 系统调用接口
-
- 1.2.1 open
- 1.2.2 write
- 2. 默认打开的三个流
-
- 2.1 内存文件与磁盘文件
- 3. 文件描述符的本质
-
- 3.1 原理
-
- 3.1.1 用接口函数举例
- 3.2 分配规则
- 3.2 FILE是什么
- 3.3 重定向
-
- 3.3.1 dup2函数
1. 打开文件
文件是由进程打开读写的,也是由进程关闭的;那么平时在使用printf等函数的时候,为什么不需要先打开文件?
因为任何进程在运行的时候都会默认打开三个输入输出流:stdin标准输入(键盘),stdout标注输出(显示器),stderr标准错误(显示器)。
执行man stdin查看手册:
#include 可以看到它们其实就相当于我们打开的文件,类型是FILE*。
1.1 系统调用与库函数
系统调用接口:指的是系统提供的接口,如open,close,read,write等;
库函数:指的是C标准库中的函数,如fopen,fclose,fread,fwrite等。
对于系统调用接口来说,是通过用户操作接口来调用的,而用户操作接口里有fopen等库函数,所以f*系列就是对系统调用接口的封装。
也就是说f*会去调用系统调用接口open等。原因有两个:分别是可读性(linux调用比较难理解)和跨平台性。
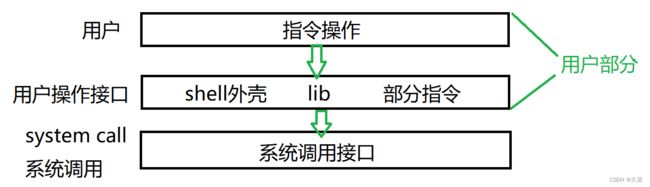
1.2 系统调用接口
1.2.1 open
输入手册指令:
man 2 open;//2表示系统调用
#include - 参数介绍
pathname表示需要打开文件的路径,mode表示设置的权限,flags表示标志位,对于这个标志位,它的实现思路为:
一个整形有32个bit位,那么可以表示32种标志,但是这样不方便,因为要传递该标志位对应的整数,比如要表示(……0000 1000)就要传递8,这样其实不太方便,所以采用位操作的方法;
这种方法就是在函数内定义宏,通过位运算来查找到对应的指令操作是什么(例如read,write等);
在系统内会有默认的标志位,用来表示只读,只写等,这里用XYZ做例子:
//假如O_X等是系统设置的标志位,用来表示只读、只写等
//每个宏代表每个位上置1
#define O_X 0x1;//只读
#define O_Y 0x2;//只写
#define O_Z 0x8;//追加
然后传递参数的时候:
open(path,O_X);//这是只读
open(path,O_X|O_Y);//这是读写
而函数接收参数时:
int open(const char *pathname, int flags);
那么在函数内部,只要通过flags&O_X和flags&O_Y即可知道哪个位被置1,就能找到对应的指令;否则就需要这样传参:
open(path,write,read);//过于麻烦
所以,open函数的调用方式:
//只读只写
int fd = open("test.txt",O_WRONLY|O_CREAT,0666);
若需要查看对应的宏,可输入指令:
grep -E 'O_CREAT|O_RDONLY|O_WRONLY' /usr/include/ -R;
然后跳出很多头文件,复制粘贴下列第一个或者其他:

/usr/include/asm-generic/fcntl.h
再进入到头文件里:
vim /usr/include/asm-generic/fcntl.h
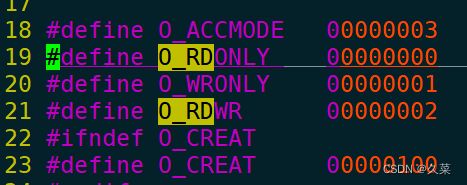
就可以看到它们都是每个位只有一个比特位为1的宏。
而对于权限的设置,由于umask的存在,使得刚才调用出来的文件权限并不是我们所设计的0666,所以要改变这种情况,就需要对umask进行处理:
mode_t umask(mode_t mask);
只要把mask设置为0即可不受其影响(default=default&(~umask))。
这里就可以看出,open对比fopen的区别,其中一个就是权限的设置,fopen调用的时候并不需要自己设置文件权限,因为OS默认会帮我们设置好。
- 返回值
open的返回值:fd代表打开的文件的文件描述符,>=0是代表打开成功,<0代表失败
- 运行
若只打开一次:
int main()
{
umask(0);
int fd1 = open("log.txt",O_WRONLY|O_CREAT,0666);
printf("fd1:%d\n",fd1);
return 0;
}
本次fd1输出3
若打开多次:
int main()
{
umask(0);
int fd1 = open("log.txt",O_WRONLY|O_CREAT,0666);
printf("fd1:%d\n",fd1);
int fd2 = open("log.txt",O_WRONLY|O_CREAT,0666);
printf("fd2:%d\n",fd2);
int fd3 = open("log.txt",O_WRONLY|O_CREAT,0666);
printf("fd3:%d\n",fd3);
int fd4 = open("log.txt",O_WRONLY|O_CREAT,0666);
printf("fd4:%d\n",fd4);
int fd5 = open("log.txt",O_WRONLY|O_CREAT,0666);
printf("fd5:%d\n",fd5);
return 0;
}
本次多个fd输出为:
[zcb@VM-8-7-centos test]$ ./test
fd1:3
fd2:4
fd3:5
fd4:6
fd5:7
他们都有一个共同的特点:从3开始。那么012哪里去了?
后面会说到系统的默认打开的三个流。
1.2.2 write
查看man手册:
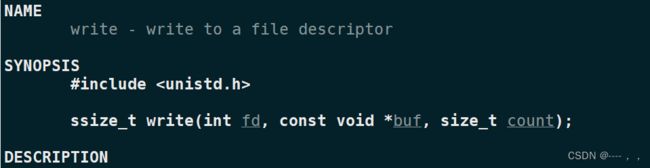
ssize_t的意思是实际写入了多少个字节,而count意思是期望写入多少个字节;buf是文件的写入缓冲区,也就是要从这里拿数据到指定地点;fd是要写入的文件的文件描述符。
创建bite文件并写入内容:
int main()
{
int fd = open("./bite",O_WRONLY | O_CREAT,0644);
if(fd < 0){
printf("open error!\n");
}
const char* msg = "linux so easy!\n";
write(fd,msg,strlen(msg));
close(fd);
}
值得注意的是,write函数传递第三个参数的时候,其大小不需要计算字符串的’\0’,因为对于linux来说字符串没有’\0’为结束标志的概念。
查看bite输出结果:
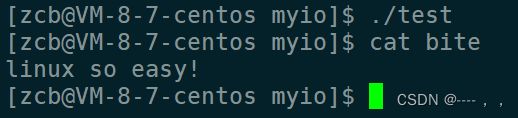
类似的还有fwrite函数:
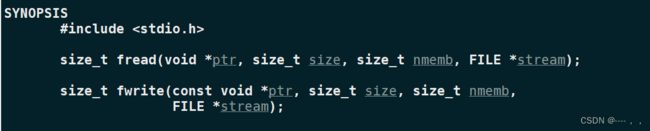
2. 默认打开的三个流
2.1 内存文件与磁盘文件
看到如此顺序排列的fd012345,很难不想到数组下标;是否fd和数组也有某些关系?
- 内存文件
对于一个进程来说,它可以打开多个文件;而对于多个进程来说,系统就可能存在大量打开的文件。
那必定少不了操作系统的文件管理:先描述,再组织;同进程一样,描述文件的结构体为struct file,将多个文件链接起来后就达成了进程和文件的联系。
对于内存文件来说。打开的只是文件的属性信息,若需要操作文件就会延后式地慢慢加载数据。
- 磁盘文件
磁盘文件存在磁盘中,不仅仅存了内容,还存了元信息(属性,名称,描述等)。
3. 文件描述符的本质
3.1 原理
Linux进程默认情况下会有3个缺省打开的文件描述符,分别是标准输入0, 标准输出1, 标准错误2。
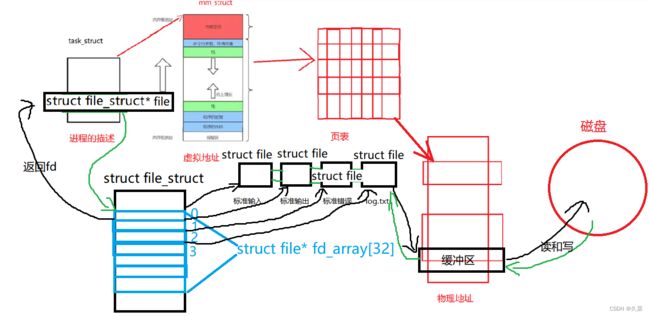
创建程序的时候默认会打开这三个流,OS创建一个结构体struct file,利用双链表的形式统一管理。
0,1,2对应的物理设备一般是:键盘,显示器,显示器
-
struct file:每打开一个文件,OS都会分配一个file对象给到对应文件,里面保存了文件相关的属性信息。
-
struct file_struct:该结构体包含一个指针数组,该数组类型为struct file* fd_array[32];这个指针数组的作用就是将对应文件描述符的地址写到该数组对应下标中(这个过程相当于分配下标),例如默认打开的标准输入、标准输出、标准错误分别对应下标0、1、2;
-
struct file_struct* file:这是一个指针,指向上述的指针数组,其作用是让进程拿到上述操作后,对应文件的描述符fd。
这三个结构,建立了进程与打开的文件之间的联系,通过数据结构实现各个进程对各个文件进行各种操作。
而现在知道,文件描述符就是从0开始的小整数,它其实就是一个数组指针对应的下标。当我们打开文件时,操作系统在内存中要创建相应的数据结构来描述目标文件。
于是就有了file结构体,表示一个已经打开的文件对象,里面包含文件的各种属性。
再详细地说:
进程执行open系统调用,所以必须让进程和文件关联起来。
每个进程都有一个指针struct file_struct* file, 指向一张表file_struct,该表最重要的部分就是包涵一个指针数组,每个元素都是一个指向打开文件的指针! 所以,本质上,文件描述符就是该数组的下标。所以,只要拿着文件描述符,就可以找到对应的文件。
所以说为什么前面的多个fd打印出来的值都是从3开始的,就是默认打开了012,所以再次打开文件时就从下标3开始。
通过上面的分析,也可以了解到为什么write、read等系统调用函数都需要文件描述符fd,因为拿到了fd,才能找到并对对应文件进行操作。
3.1.1 用接口函数举例
0,1,2对应的物理设备一般是:键盘,显示器,显示器
那么,write函数直接往显示器写入是没问题的:
const char* msg = "i like linux!\n";
write(1,msg,strlen(msg));//1和2对应显示器
write(2,msg,strlen(msg));
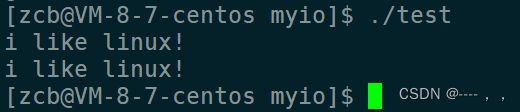
1、2代表的都是显示器,那么上述两个写入操作,有什么不同?
//待补充
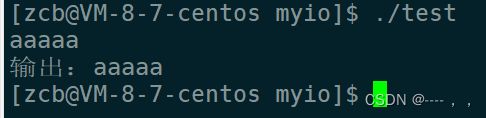
也可以从键盘中读数据:
char buf[100];
ssize_t s = read(0,buf,sizeof(buf));//0对应显示器
buf[s-1] = 0;//消除\n
printf("输出:%s\n",buf);
3.2 分配规则
文件描述符的分配规则:在fd_array数组当中,找到当前没有被使用的
最小的一个下标,作为新的文件描述符。
也即是说,如果那这些操作之前把0关掉,那么下一个打开的文件的文件描述符就会被自动赋值为0,其他下标也同理。
也可以理解为系统是采用了一个线性遍历的方式,找到未使用的文件描述符。
如果在打开文件之前就关闭了默认的文件描述符:
//关闭描述符0
close(0);
int id = open("./bite.txt",O_WRONLY | O_CREAT);
printf("fd:%d\n",id);
运行后得到的结果是fd : 0;也就是说此时该文件的文件描述符被赋值成了0;
//关闭描述符1
close(1);
int id = open("./bite.txt",O_WRONLY | O_CREAT);
printf("fd:%d\n",id);

如果关闭的是1,会发现./test运行可执行程序的时候并没有输出任何结果,但是cat查看该文件内容的时候,发现fd:1打印在了文件内。这个过程就是分配规则的体现,其中原来指向描述符1的显示器文件就被关闭了。
文件描述符和打开的文件并不是一一对应的关系,多个文件描述符可以指向同一个打开文件,这些文件描述符可以在相同或不同的进程中打开。
3.2 FILE是什么
FILE是语言层面的一个结构体。fprintf,prinft等库函数(语言层)其实是向下调用open,write等(系统层)系统调用接口,相当于上层是用户层、语言层,而下层是系统层,所以本质还是系统调用。
对于fopen等函数,其实是语言层面调用接口后进到系统层面调用open,然后open打开文件拿到文件描述符fd返回给FILE结构体。然后更新里面的struct_file里的fd,这样也就拿到了新打开的文件的信息。
这就是为什么fopen的返回值是FILE*,因为这是一个指向FILE结构体的指针,这个结构体里包含了新文件的信息。 在每次打开新文件的过程中,FILE会随之更新文件的数据,那么FILE*指针对应也会更新,每次作为返回值实现更新。
因为IO相关函数与系统调用接口对应,并且库函数封装系统调用,所以本质上,访问文件都是通过fd访问的;
所以C库当中的FILE结构体内部,必定封装了fd,每次打开文件的过程中,都会有更新fd的过程。
3.3 重定向
- 重定向
形成重定向:本来应该打印到某一个文件的内容,通过修改文件描述符后可以输出到指定文件。
所以一句话:重定向的本质就是修改文件描述符fd下标对应的struct file*的内容(也就是struct file的元素)。
例如重定向的过程也可以这样:打开文件使用printf打印的时候先把标准输出流关闭close(1),这时候打印的地方不是屏幕而是该文件内部;因为printf默认往stdout的文件输出(原本是stdout显示器文件),这个规则是不会变的,但是此时的stdout结构体内的fd=1已经默认分配给了文件地址。
那么认死理的printf等函数就会将内容打印到文件内而不是屏幕上。
3.3.1 dup2函数
也可以使用dup2完成输出重定向:
除了前面提到的close方法,还有一种方法可以不用关闭默认的描述符012,这个方法就是dup2函数:
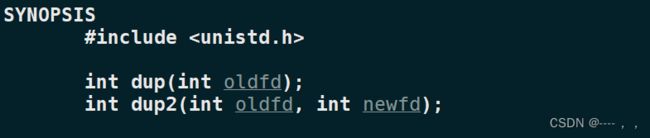
newfd是指现在将要被改变输出方向的文件的文件描述符。就比如标准输出stdout对应描述符是1,我们如果要将一个内容输出到某个文件中而不是stdout,那么stdout就是将要被修改的文件;oldfd指的就是上述“某个文件”的fd;
举例:要将本来输出到显示器的内容输出到bite.txt中,那么newfd对应就是1(stdout),因为它将被修改;而oldfd对应bite.txt的fd,因为它的文件地址将要去覆盖原stdout地址占据的下标1:
int fd = open("./bite.txt",O_WRONLY | O_TRUNC);//只读 | 清空原有数据
if(fd < 0){
perror("open failed\n");
}
dup2(fd,1);//将输出到标准输出的内容输出到fd的对应文件中
printf("aaaaaaaa\n");
结果输出到了bite.txt中:

换成输入重定向也同理:
本来是从键盘读取,现在换成从文件bite.txt中读取:
int fd = open("./bite.txt",O_RDONLY);
if(fd < 0){
perror("open failed\n");
}
dup2(fd,0);//从键盘读取变成从文件读取
char buf[100];
scanf("%s",buf);
printf("%s\n",buf);
在bite.txt中随意输入值:
运行./test,本来是要从显示器读,现在直接就从文件里读了出来:
- 如何理解一切皆文件
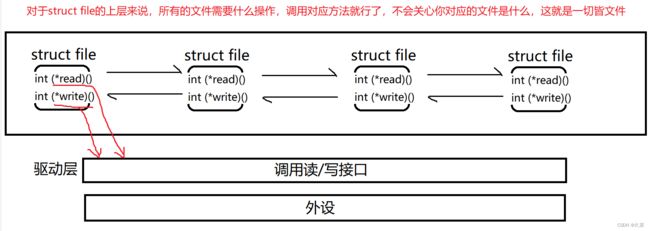
这也是上面说到的:一切皆文件,上层不会知道下层做了什么事情,只需要按照下层给出的接口之间调用就行了。