文件IO_复制文件描述符(附Linux-5.15.10内核源码分析)
目录
1.文件描述符复制简介
2.dup函数原型
2.1 dup函数
2.2 dup函数工作原理
2.3 dup函数内核源码分析
2.4 dup函数示例代码
3.dup2函数原型
3.1 dup2函数
3.2 dup2函数工作原理
3.3 dup2函数内核源码分析
3.4 dup2函数示例代码
4.dup3函数原型
4.1 dup3函数
4.2 dup3函数工作原理
4.3 dup3函数内核源码分析
4.4 dup3函数示例代码
1.文件描述符复制简介
Linux文件描述符复制是指在进程中复制一个文件描述符(file descriptor)的操作。文件描述符是一个用于标识打开文件或其他输入/输出资源的整数值。
在Linux中,每个进程都有一个进程表项,其中保存了一张文件描述符表。该表中的每个条目都指向一个打开的文件或其他资源。当我们在进程中打开一个文件时,系统会为该文件分配一个文件描述符,并将其添加到进程的文件描述符表中。
通过复制文件描述符,我们可以在进程中创建多个对同一文件的引用。这些引用可以同时对文件进行读取、写入等操作,而不会相互干扰。
2.dup函数原型
2.1 dup函数
#include
int dup(int oldfd);
函数简介:dup函数作用是复制文件描述符,将oldfd指向的文件描述符复制到一个新的文件描述符中,并返回新的文件描述符。新的文件描述符是进程中当前可用的最小非负整数文件描述符。
函数参数:
oldfd:需要复制的文件描述符。
函数返回值:
成功:返回新的文件描述符。
失败:返回-1,并设置errno。
2.2 dup函数工作原理
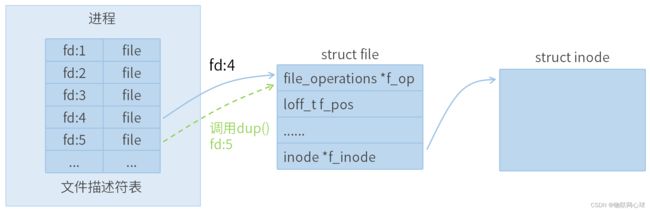
图 2-1 dup函数工作原理
背景知识:
每个进程都有一个文件描述符表,单个进程默认最大打开文件描述符为1024,每打开一个文件,会创建一个struct file对象,并申请一个未使用的fd,进程会记录fd和struct file的对应关系至文件描述符表。
struct inode对象代表一个实际的文件,struct inode对象是唯一的,struct file对象可以是多个,比如多次打开同一个文件,会创建多个struct file对象,但实际对应的struct inode只有一个。
原理分析:
打开一个文件时,申请一个fd(4)以及创建一个struct file对象指向一个struct inode对象,我们把这个fd称为旧的fd。
调用dup函数进行文件描述符复制时,会申请一个新的fd(5),新的文件描述符是进程中当前可用的最小非负整数文件描述符,dup函数会将新的fd也绑定到旧的fd对应的struct file对象,这样新的fd和旧的fd都可以对这个struct file对象进行操作,这个就是文件描述符复制。
2.3 dup函数内核源码分析

图 2-2 dup函数内核源码调用流程
dup内核源码非常简单,首先通过旧的fd找到struct file对象,然后申请一个新的fd,再将新的fd绑定旧的fd对应的struct file对象,旧完成了文件描述符复制。
2.4 dup函数示例代码
int dup_test() {
int fd = open(TEST_FILE, O_RDWR | O_CREAT | O_TRUNC, 0644);
if (fd == -1) {
perror("perror open");
return -1;
}
int newfd = dup(fd);
if (newfd == -1) {
perror("dup error");
close(fd);
return -1;
}
write_len_data(fd, 10, 'a');
print_pos(fd);
write_len_data(newfd, 10, 'b');
print_pos(fd);
close(fd);
close(newfd);
return 0;
}
3.dup2函数原型
3.1 dup2函数
#include
int dup2(int oldfd, int newfd); 函数简介:dup2函数的主要功能是将一个已有的文件描述符复制到另一个文件描述符上。通过调用dup2函数,可以实现以下几个功能:
- 文件描述符的复制:通过将一个已有的文件描述符复制到另一个文件描述符,可以实现对同一个文件或设备的多个操作。
- 文件描述符的重定向:通过将一个文件描述符复制到标准输入、标准输出或标准错误输出,可以实现输入输出的重定向。
函数参数:
oldfd:需要复制的文件描述符。
newfd:目标文件描述符。如果newfd已经打开,将会先关闭newfd再进行复制。
函数返回值:
成功:返回新的文件描述符。
失败:返回-1,并设置errno。
3.2 dup2函数工作原理
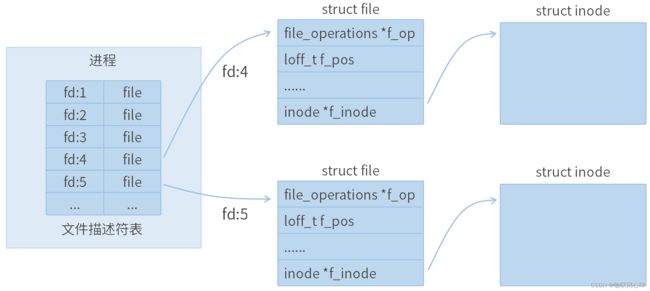
图 3-1 dup2函数工作原理1

图 3-2 dup2函数工作原理2
如图 3-1,未调用dup2函数之前,已经有打开了两个文件,第一个文件fd(4)对应一个struct file对象,第一个文件fd(5)对应另一个struct file对象,此时fd(4)和fd(5)是隔离的。
如图 3-2,调用dup2函数之后,fd(5)对应的struct file对象会被关闭和释放,且fd(5)会重新绑定fd(4)对应的struct file对象,完成文件描述符复制。
注意:新的fd可以是未打开文件的文件描述符(未使用的文件描述符),这种情况和dup函数调用过程类似。
3.3 dup2函数内核源码分析
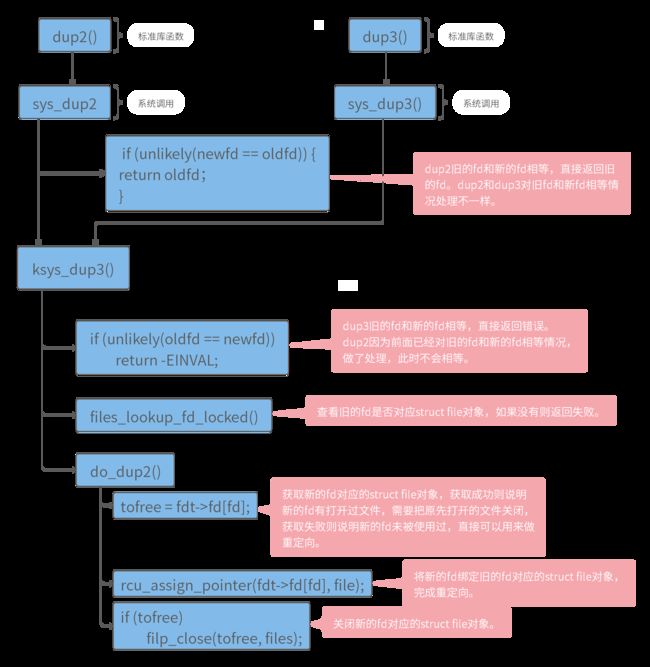
图 3-3 dup2函数内核源码调用流程
如图3-3,该图把dup2和dup3内核源码流程并在一起,这样能够直观的了解dup2和dup3调用流程,且能直观的了解二者之间的差异。
dup2和dup3函数会调用一个共用的函数ksys_dup3函数,也就是ksys_dup3函数之后的流程,dup2和dup3函数是一样的。
调用ksys_dup3函数之前,dup2函数会判断新的fd和旧的fd是否相等,如果相等,dup2函数直接返回旧的fd。
调用ksys_dup3函数之后,dup2和dup3的流程是一样的,这里有一个特殊的地方是ksys_dup3函数也会判断新的fd和旧的fd是否相等,对于dup2函数来说,这个没有什么意义,因为调用ksys_dup3函数之前,dup2已经做了处理,此时不做任何处理。dup3函数如果判断新的fd和旧的fd相等则会返回错误,这个是dup2和dup3的一个差异点,可以通过测试代码验证。
后续的流程则是先找到旧的fd对应的struct file对象,然后将新的fd绑定到该struct file对象,如果新的fd已经打开过文件,则关系新的fd原先对应的struct file对象。
3.4 dup2函数示例代码
int dup2_test() {
int fd = open(TEST_FILE, O_RDWR | O_CREAT | O_TRUNC, 0644);
if (fd == -1) {
perror("perror open");
return -1;
}
int fd1 = open(TEST_FILE1, O_RDWR | O_CREAT | O_TRUNC, 0644);
if (fd1 == -1) {
perror("perror open");
return -1;
}
int newfd = dup2(fd, fd1);
if (newfd == -1) {
perror("dup error");
close(fd);
return -1;
}
printf("fd:%d, fd1:%d, newfd:%d\n", fd, fd1, newfd);
write_len_data(fd, 10, 'a');
print_pos(fd);
write_len_data(newfd, 10, 'b');
print_pos(fd);
close(fd);
close(fd1);
close(newfd);
return 0;
}4.dup3函数原型
4.1 dup3函数
#define _GNU_SOURCE
#include
#include
int dup3(int oldfd, int newfd, int flags);
函数简介:dup3函数会将oldfd所指向的文件描述符复制到newfd上,并返回新的文件描述符。 如果newfd已经打开,则dup3会复制oldfd和先关闭newfd。 如果newfd和oldfd相等,则dup3不进行任何操作,直接返回错误。
函数参数:
oldfd:需要复制的文件描述符。
newfd:新的文件描述符。
flags:选项,可以是以下值的按位或运算结果:
- O_CLOEXEC:在执行exec时关闭新文件描述符。
- O_NONBLOCK:将新文件描述符设置为非阻塞模式。
函数返回值:
成功:返回新的文件描述符。
失败:返回-1,并设置errno。
4.2 dup3函数工作原理
请参考dup2函数工作原理。
4.3 dup3函数内核源码分析
请参考dup2函数内核源码分析。
4.4 dup3函数示例代码
int dup3_test() {
int fd = open(TEST_FILE, O_RDWR | O_CREAT | O_TRUNC, 0644);
if (fd == -1) {
perror("perror open");
return -1;
}
int fd1 = open(TEST_FILE1, O_RDWR | O_CREAT | O_TRUNC, 0644);
if (fd1 == -1) {
perror("perror open");
return -1;
}
int newfd = dup3(fd, fd1, O_CLOEXEC);
if (newfd == -1) {
perror("dup3 error");
close(fd);
close(fd1);
return -1;
}
printf("fd:%d, fd1:%d, newfd:%d\n", fd, fd1, newfd);
write_len_data(fd, 10, 'a');
print_pos(fd);
write_len_data(newfd, 10, 'b');
print_pos(fd);
close(newfd);
close(fd1);
close(fd);
return 0;
}