MIT 6.829 -- Lecture 1: Packet Switching
MIT 6.829 -- Lecture 1: Packet Switching
- 引言
- Interconnections
- Circuit Switching
- Packet Switching
-
- Datagram routing
- Source routing
- Virtual circuits
- An example:LAN Switching
-
- Learning bridges
- The Solution:Spanning Trees
- Virtual LANs
- Summary
本课程为MIT 6.829 计网课程,课程对应官网链接: Computer Networks Lecture Notes
本节对应课程文档链接: Lecture 1: Packet Switching
引言
这节课程会讨论使用不同的方式,将相同类型的网络链路互联在一起,构成一个简单的网络。这里,我们会使用一个叫做交换机(Switch)的设备,并讨论几种不同的交换方式来将数据在不同的网络之间移动。我们会关注在“packet switching”,并研究它是如何工作的。
在你继续阅读之前,你需要熟悉L0中的内容。
Interconnections
单条链路网络的能力受物理距离,连接的主机数,可承载的流量所限制。所以人们会考虑将多个单链路媒介互联在一起,以构成更大的计算机网络。在这一节课,我们将会看到几种互联技术,它们可以将同质化的网络链路连接起来。
这里互联的关键组件是Switch,这是一个特殊的计算机,它上面运行了软件使得它可以接收并处理来自链路的frame(或者packet),然后再将这些frame转发到一个或者多个其他链路上。多条链路物理连接在交换机的attachment port或者switch port上(当上下文是清晰的时候,这里通常简称为端口/port)。通过这种方式构建的网络通常被称为“receive-and-forward”网络。
有些人会称之为“store-and-forward”网络,但是这里我们使用一种更精确的词语。我们会称呼其他网络,例如电子邮件网络,为“store-and-forward”网络。
一个特定的物理链路通常会被不同计算机之间多个并发的网络会话共享,所以交换机的基本功能就是将不同计算机之间多个会话(以及涉及到的数据frame)在物理链路上进行多路复用。有两类非常不同的技术被开发来实现这个功能。第一种被电话网络所使用,被称为电路交换(Circuit Switching)。第二种,被例如互联网的网络使用,被称为分组交换(Packet Switching)。它们之间的关键区别在于,在Circuit Switching网络中,frame不必带有任何特殊的信息来告诉交换机如何转发数据,而在Packet Switching则需要。
Circuit Switching
Circuit Switching网络中传输信息通常需要两个阶段:
- 首先是设置阶段,这个阶段会在源和目的之间路径上的每一个交换机上配置好特定的状态;
- 其次是传输阶段,这个阶段会实际传输frame。因为frame里面并不会包含转发信息,所以在设置阶段需要配置好frame的转发设置。
一种常见的实现了Circuit Switching的方法是时分复用(time-division multiplexing,TDM)。这里,连接到交换机的一个链路从逻辑上分成了N个虚拟的通道,假设链路的物理容量是C(bits/s),这样每个通道分到的容量C/N(bits/s)足够用来为每个会话传输数据(例如两个终端之间的电话通话)。这里将每个独立传输会话的带宽称为R。现在假设我们限制每个frame为固定的大小—s bit。那么交换机通过这种方式实现时分复用:可以先将链路的容量分成若干个长度为s/C的时间单元,再将第i个时间单元分配给第i个传输会话。
严格来说,是分配给第(i mod N)个会话。
这种方法可以为每个会话提供所需要的带宽R(bits/s)。因为每个会话可以经过Ns/C秒发送s bits(虽然发送s bit只需要s/C的时间,但是要经过N个s/C时间才能轮到一个s/C时间片,所以整体看来对于一个会话需要经过Ns/C秒才能发送s bit),用数据量除以时间等于s/(Ns/C) = C/N = R bits/s。
每一个数据frame可以简单的使用它到达交换机的时间片来进行传输。因此,在Circuit Switching的设置阶段,需要为即将到来的数据传输关联一个通道,通过将第i个时间片分配给第i个传输通道。发送端计算机只会在它们在设置阶段被分配到的时间片中发送数据frame。
其他实现Circuit Switching的方式还包括了:波分复用(wavelength division multiplexing,WDM);频分复用(frequency division multiplexing,FDM)和码分复用(code division multiplexing, CDM),后两者在一些蜂窝无线网络中有应用。
Circuit Switching在一个负载一致的网络中是有意义的。负载一致是指:所有的信息传递会话使用相同的容量,每一次传输都使用一样(或者近乎一样)的比特率。负载一致最有说服力的例子就是电话,并且现在大部分电话网络也是这样设计的(电话网络使用Circuit Switching的另一个原因是历史原因,因为Circuit Switching比Packet Switching要发明的早得多)。
但是,如果负载不一致(不同传输会话使用不同的比特率),Circuit Switching就会浪费链路带宽(因为被逻辑划分出来的N个虚拟通道的带宽是一致的,为了保证传输,每个虚拟通道的带宽必然要小于最大的传输比特率,对应的小的负载的通道就会造成浪费)。现实中大量的数据传输应用程序具有负载不一致的特征,我们应该使用其他链路复用策略。Packet Switching就是一种通用的提升这种场景性能的方法。
Packet Switching
最好的克服上面低效率的方法是在链路复用的前提下,允许任意的发送者在任意时间发送数据(这样高负载的应用程序可以占用链路更多时间)。Packet Switching就是这样一种方法,它使用了一种非常简单的思想:为每个frame增加一些特定的额外信息来告诉交换机如何转发frame。frame中包含这些额外信息的地方通常被称为header。
Packet Switching有几种不同的形式,区别在于header中包含的信息以及交换机需要什么样的信息来执行转发:
- 最“直接”的Packet Switching形式是datagram routing。它会在header中包含目的地址。header中的目的地址唯一的标识了数据的目的地,每个Switch可以用这个目的地址完成datagram的转发。
- 第二种Packet Switching的形式是源路由(source routing),它会在header中包含转发路径上所有Switch的信息,或者将datagram送达目的地所需要的完整路径信息。相比datagram routing,现在每个Switch的转发决策更加简单,但是这种方法假设datagram的发送端提供了正确的信息。
- 第三种Packet Switching的形式结合了Circuit Switching和Packet Switching,并且使用了一种叫做Virtual Circuit的思想。尽管这种方式包含了Circuit Switching中的设置阶段,但是因为它使用了header,我们还是将它归类为Packet Switching技术。
Datagram routing
在Datagram routing中,发送端传输的datagram会将目的地的地址包含在header中,datagram中通常也会包含发送端的地址,这样接收端可以将对应的信息返回给发送端。Switch的工作就是使用目的地址作为key,在一个叫做routing table的数据结构(或者是forwarding table,这两者之间的区别有的时候还挺重要,在后面的课程会看到他们的区别)中进行查找,查找得到的结果是Switch的一个输出端口,之后Switch会将datagram从这个端口送出,以用来向目的地转发packet(这里的frame,datagram,packet都有相同的含义)。
虽然转发就是在一个数据结构中进行相对简单的查找,但是这里的难点在于如何获取routing table中的条目。通常是通过一个实现了路由协议的后台程序完成,这个程序通常以分布式的方式在所有Switch中实现。理论上和实际中有几种类型的路由协议(某些路由协议只存在于理论中),我们在后面的课程中会学习其中几种。但是目前为止,知道运行路由协议就是为了获取网络中每一个目的地址的路由(路径)就足够了。
在datagram routing中实现了这一小节描述功能的switch通常被称为router。使用Internet Protocol(IP)来在互联网上转发和路由packet就是datagram routing的一个例子。
Source routing
在前面的方式中,Switch实现了路由协议将它们的路由表在”纯“datagram网络中转发出去。其实在发送端也可以实现相同的功能以确定包转发的路径,这就是source routing,也就是发送端会将转发路径上交换机的完整顺序(或者是交换机和关联端口的完整顺序)附加在每个packet中。现在每个switch的任务非常简单,因为连查表都不需要了。然而,source routing却需要每个发送端都加入到路由协议中以学习网络的拓扑(这样发送端才能确定转发路径)。
基于上面的原因,人们倾向于不会构建只使用source routing的网络,但是很多网络(例如互联网)允许source routing与datagram routing共存。
Virtual circuits
Virtual circuit是一个结合了circuit switching和packet switching的有趣的转发方式,它既有circuit switching的设置阶段,又有packet switching的特定的header。在设置阶段,发送端会发送一个特定的singaling message到目的地,这个message会经过一系列的switch最终到达目的地。沿途的每个交换机会为每个端口关联一个本地的tag(或者label),并将这个tag设置到singaling message中再发给下个switch。具体过程是,当一个switch在其某个输入端口上收到了singaling message,它首先会决定哪个输出端口可以将这个message送到目的地,之后会将输入端口和输入的tag作为key加入到一个本地的table中,key对应的value就是输出端口和对应于输出端口的tag。
在数据传输时,并不会使用packet header中的目的地址,而是会使用tag。现在每个switch的转发任务包含了:
- tag查找,以获取输出端口和用来替换的tag;
- tag交换,替换packet header中的tag。
之所以要替换tag,是为了避免混淆。因为如果不替换tag,那么每个源都必须确保任何它使用的tag现在并没有在网络中被其他人使用。
有很多网络技术都使用了Virtual circuit switching,例如Frame Relay和Asynchronous Transfer Mode(ATM)。这些网络中tag的格式和语义各不相同,并且tag的计算方式也不相同。Muti-Protocol Label Switching(MPLS)是一种不依赖链路层的技术(MPLS是2.5层技术,在L2和L3之间加tag),switch可以它用来实现tag switching。尽管有很多不同,所有这些系统的基本工作方式都在上面都介绍了。
Virtual circuit switching的支持者们认为它比datagram routing存在以下优势:
- 它可以确保源和目的之间的路径是固定的,这使得网络管理员可以根据不同的流量模型编排网络。
- 基于tag的查找比基于datagram header中不同字段查找更有效,目前我们还没有足够的背景理解这一点,但是随着这门课的学习,这一点会更加清晰。
- 因为有一个独立的设置步骤,对于需要保留网络资源(例如带宽,switch buffer等)的应用程序,可以使用这个signaling message来预留所需的资源。
但是上面的观点其实是有争议的:Virtual circuit switching相比datagram routing更加复杂,并且默认情况下不能处理链路或者路由失败。资源预留的原理和机制也存在争议,并且已经在社区中激烈的讨论了很久,看情况还会持续很多年!
Virtual circuit技术在互联网基础设施中很常见,并且通常会用来在一个传输网络中连接两个IP router。传输网络可以被看成是链路层,两个router之间的IP packet会在之间传输,例如基于ATM的链路技术。(这里的传输网络就是ISP的骨干网,IP router对应的就是Provider Edge router)
接下来我们来看一个switching的具体例子,这个例子使用了广泛部署的LAN(local-area network)switching技术。
An example:LAN Switching
单个共享媒介的network segment,例如单个Ethernet,受限于它可以支持的终端数量,以及受限于可以在其之上共享的流量。要扩展单个LAN segment,需要以某种方式将多个LAN网络连接在一起。或许最简单的扩展LAN的方式是通过”LAN Switching“,有时也会被称为”bridging“。Bridges(也就是LAN switches)可以用来扩展单个共享物理媒介。它会查看从一个network segment来的数据帧,捕获这些数据帧,并转发到一个或者多个其他的网络分区中。我们接下来会在datagram routing的背景下学习这一部分。另一个学习bridges的原因是,它们是一个自我配置(plug-and-play)的很好的例子。
Bridges具备以下特征:
-
在多个端口上混杂的接收并转发数据。每个bridge端口都有个关联的LAN,这个LAN上可能又包含了其他的bridge。在这样一个网络中,总的带宽不会超过其中最弱部分的network segment的带宽,因为在任何一个LAN传输的任何一个packet,都会出现在其他所有的LAN中,包括了最慢的那个LAN(这里提到的LAN就是一个独立的network segment,可以理解为一根链路,bridge的端口连接到这些链路上)。
-
学习。它们可以学习哪个终端在哪个LAN segment,并更高效的转发packet。
-
可以实现生成树(Spanning tree)结构,这样带有环路的网络拓扑可以避免网络风暴。
Bridge是透明的设备—它们完全保留了它们所处理包的完整性,并且不会以任何形式改变它们。当然,因为它们的store-and-forward特性,它们可能会为packet增加一些延时并且偶尔丢包,但是从功能上来说它们是透明的。

Learning bridges
Learning bridges的基本思想是,bridge学习终端位于自己哪个端口,并构建一个cache来记录这个信息。之后当一个发往特定目的地址(例如MAC地址)的packet到达bridge时,它就知道该往哪个端口转发。那bridge是如何构建cache的呢?它是通过查看它接收到的packet的源地址(也就是记录接收端口和源地址的关系)。
如果bridge的cache中没有某个目的地址的记录,它会简单的将packet发送给除了接收端口之外的其他所有端口。因此,learning bridge维护的状态类似于一个cache,这个cache可以优化转发,并且cache的一致性对于正确性来说不是必须的(因为没有cache也可以通过flood完成转发)。
如果在网络拓扑中不存在环路,这里的方法可以正确的工作。实际上,在没有环路时,这里的方法不仅可以处理包转发,也可以更新在网络拓扑中移动的节点。如果一个节点移动到网络的另一个位置,它第一次发送出数据时,从它到数据的目的地沿途的bridge都会将cache更新到node的新位置。实际上,这种方法的一个变种再加上一些优化被用在各种无线局域网中用来实现链路层的移动性。
但是当交换网络中存在环路时,会有明显的问题。可以查看下图中的例子:
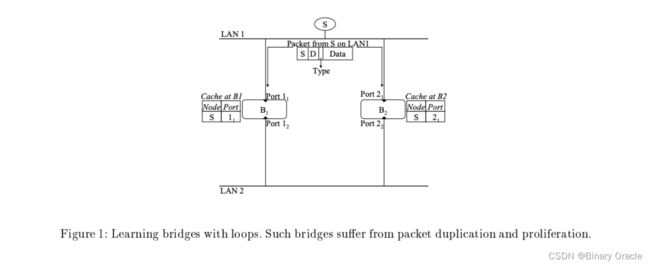
Bridge B1和B2同时连接LAN1和LAN2(这么做的一个原因是为拓扑增加冗余以提高可靠性)。假设一个packet从S发出,发往了LAN1。因为B1和B2都能看到这个packet,它们都能学到S位于LAN1,并且向它们的cache中添加合适的信息。之后B1和B2都会将packet发送给LAN2,但是它们会根据CSMA/CD来竞争LAN2上的通信权利,假设是B1竞争获胜,会将packet发送给LAN2。当然,这个packet也会被B2看见。现在B2看见了重复的packet,但是它又没办法发现这是一个重复的packet,因为如果每个包都逐bit比较的话,转发效率会非常低。因为learning bridge透明特性,bridge不会修改packet的任何字段(不像router会更新header中的hop limit或者TTL),所以重复的包会永远循环下去。
但这还不是最糟糕的部分,实际上packet在某些场景下还可以不断的复制。如果我们在两个LAN之间加上第三个bridge B3。现在,每当一个bridge向一个LAN发送一个packet,剩下的两个bridge都会收到相同的packet,并且各自向另一个LAN发送这个packet(packet数量加倍了)。不难看出这种状态会一直持续,最终使得整个网络不可使用。
对于这个问题有几个解决方法,包括:构造网络时避免形成环路;自动探测环路;和让网络能在有环路的情况下也能工作。明显最后一种方法是更好的方法,它的诀窍在于从一个bridge网络拓扑中找到一条无环路的路径。这是通过一个分布式的spanning tree算法来实现的。
The Solution:Spanning Trees
现实中存在很多分布式spanning tree算法。Bridge使用一种基于Dijkstra最短路径的spanning tree算法。这里的想法很简单:所有bridge选举一个根节点,然后每个bridge形成到根节点的最短路径。这些最短路径的集合构成的spanning tree就是最终的树。
更具体的来说:对于网络中的每一个bridge,确定它的哪个port应该参与到数据转发中,哪个应该保持不活跃的状态,这样最终每个LAN segment在到达root的路径上都有且只有一个bridge与其直接相连(spanning tree算法就是将网络中的冗余去除,以避免环路。去除冗余的方法就是关闭某些bridge的某些端口)。
首先需要将LAN segment和Bridge构成的网络看成一个图,之后才能在这个图上构建spanning tree,但是构建这么一个图比较麻烦。可以这么来构建,将LAN segment和bridge看成图中的点,图中的边连接了bridge和LAN segment。spanning tree的目标是找出所有边的子集以构成树,这些边还需要覆盖(span)图中的所有节点(这里需要注意的是,部分bridge可能不会被覆盖,但是这没问题,因为这些bridge是冗余的)。
Spanning tree算法存在一些挑战,其中第一个是使用一个分布式的异步的算法,而不是一个中心控制器来完成计算。这里的目标是每个bridge独立的发现自己的哪些端口属于spanning tree,因为它最终需要向这些端口发送packet。最终结果是一个无环的转发拓扑。第二个挑战是处理故障的bridge(例如人工移除bridge或者出bug了)和新增的bridge和LAN segment,而又不中断整个网络。
为了解决第一个问题,每个bridge会定期的向LAN上其他所有的bridge发送configuration message。message包含下列信息:
![]()
- 每个bridge都有一个属于自己的unique ID,它除了标识bridge,最小unique ID的bridge会被选做spanning tree的根节点。
- bridge’s idea of root 包含了当前bridge所知道的根节点的unique ID。最初的时候,每个bridge都会将自己作为根节点,因为在最初的时候它们自己的unique ID就是它们知道的最小ID。
- distance to root 是当前bridge到其所知道的根节点的距离。这个距离可以用在Dijkstra算法中。根节点到自己的距离为0。
configuration message不会被转发到所有的LAN,而是只会发送到bridge连接的每个LAN segment,并且只被这个LAN segment上的其他bridge接收并处理。它的目的地址通常对应了一个约定好的链路层地址—ALL-BRIDGES。
在任何时间,一个bridge会根据它接收到的最小unique ID和对应的到根节点的距离来构建自己的信息。到根节点的距离通常对应了到达根节点需要经过的bridge端口的数量。
- bridge会存储收到了最小unique ID消息的端口作为自己的”root port“(也就是通过这个端口可以到达root)。
- 构建自己的configuration message,其中到根节点的距离等于收到消息中的到根节点距离+1。
- 将自己的configuration message发送给其他端口。
- 如果bridge在一个LAN segment上收到了一个更优的到根节点的信息,那么它不会向这个LAN segment发出任何消息。这一步很有必要,因为这可以确保每个LAN segment只有一个bridge为其转发流量(因为只有一个bridge宣告了最优路径)。而这个bridge,被称为这个LAN segment的designated bridge,并且也是这个LAN segment在spanning tree中离根节点最近的bridge。如果有多个bridge到根节点距离相同且都是最近,那么拥有最小unique ID的bridge会被选中。
如果不存在网络拓扑的变更,不难看出这里的方法可以形成一个带有根节点的spanning tree。每个bridge只会向位于spanning tree中的端口转发packet。每个bridge需要知道它的”root port“以及连接其他bridge的port,这些port会连接到其他bridge的root port。
最终,这里形成了一个无环的网络拓扑,这个拓扑以拥有最小ID的bridge作为根节点,其他bridge到根节点都有最短路径。定期发送的configuration message可以处理加入到网络的新bridge和LAN segment。重新生成spanning tree在大多数情况下不会使得整个网络陷入完全的停顿。
以上是基本的算法,但是它没有处理bridge出故障的状态。故障是由定时发送的configuration message中的时间信息来处理(定时发送本身就包含了时间信息)。Bridge会将定时发送的configuration message作为一个”soft state“。如果缺失了从designated bridge或者root发来的configuration message,则会触发spanning tree的重新计算。这里”soft state“的概念是一个非常重要的概念,我们在这门课程中会反复看到。定期的宣告configuration message来更新网络中的”soft state“可以为一个基于上面算法生成的无环spanning tree拓扑提供最终一致性(eventual consistency)。
Virtual LANs
截止到目前为止,交换网络并具备较好的扩展性。这里的原因包括了spanning tree算法的线性扩展特性(网络规模越大,需要计算的节点越多,收敛时间越长);以及所有的广播packet都需要送达网络中的所有LAN segment的所有节点。Virtual LANs通过将一个交换网络分区成多个独立的虚拟LAN网络来提升扩展性。每个虚拟LAN都被分配了一个”颜色“,packet只有在”颜色“匹配时,才会从一个LAN switch转发到另一个LAN switch。因此,上面提到的算法分别在每种颜色的LAN网络中独立的实现,并且LAN switch的每个端口都被配置成整个系统所有颜色的子集(注,这里的颜色就对应了VLAN ID)。
Summary
Switch是一种特殊的计算机,它用来互联单个通讯媒介以形成更大的网络。switching有两种主要的形式:circuit switching和packet switching。packet switching又有多种形式。我们学习了其中一种,switched LAN。
尽管LAN switch可以很好的工作,它们不足以构建一个全球的网络基础设施。这里包含了两个原因:
- 缺乏扩展性。首先,每个LAN switch都需要在它的forwarding table中维护基于每个主机的信息。其次,偶尔但是必须的flood不能在大规模网络中很好的工作。
- 不能在多种异构链路技术之间工作。一个全球的网络基础设施的一个目标是在各种链路层技术上工作,而不仅仅是以太网。
解决上面提到的挑战并且提供一个全球网络基础设施的问题被称为网络互联的问题(internetworking problem)。我们从下节课开始将学习如何解决这个问题。