RocketMQ面试题八股文 【2023】
本文仅用作个人学习复习使用!
RocketMQ是一个纯Java、分布式队列模型的消息中间件,是阿里巴巴在2012年开源的分布式消息中间件,目前已经捐赠给 Apache 软件基金会,并于2017年9月25日成为 Apache 的顶级项目。作为经历过多次阿里巴巴双十一这种“超级工程”的洗礼并有稳定出色表现的国产中间件,具有高性能、低延时和高可靠等特性。主要用来解耦、削峰、消息分发等。
基础篇
1 消息队列的用途
消息队列三大用途 : 解耦 异步 削峰;
第一方面 : 解耦: 系统耦合度降低,没有强依赖关系;
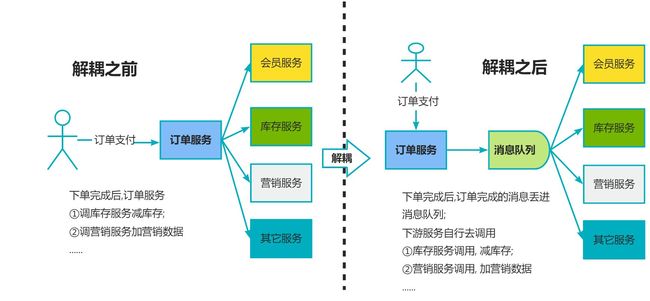
第二方面 : 异步, 不需要同步执行的远程调用可有效提高响应时间
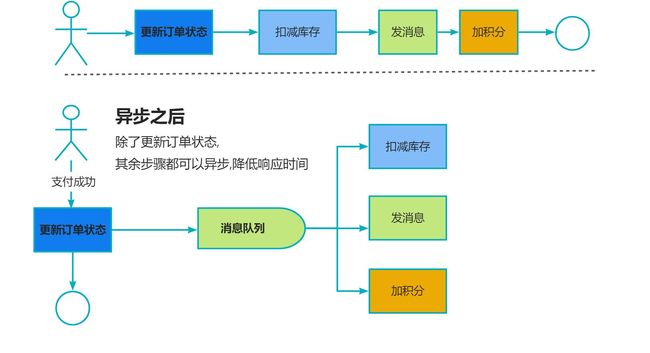
第三方面 : 削峰 , 请求达到峰值后,后端Service还可以保持固定消费速率消费,不会被压垮
消息队列合一用来削峰;
比如秒杀系统, 秒杀时候流量陡增,服务器,Redis,MySQL承受能力不一样,有可能直接挂了;
这时候把请求丢到队列里面,只放出服务能处理的流量,就能抗住短时间大流量;
2 RocketMQ的优缺点
| 类别 | RabbitMQ | ActiveMQ | RocketMQ | Kafka |
|---|---|---|---|---|
| 公司 | Rabbit | Apache | Alibaba | Apache |
| 语言 | Erlang | Java | Java | Scala |
| 协议支持 | AMQP | REST AMQP… | 自定义 | 自定义协议 |
| 单机吞吐量 | 万级别③2.6w/s | 万级别 | 十万级别①11w/s | 十万级别②17w/s |
| 消息延迟 | 微秒 | 毫秒 | 毫秒 | 毫秒以内 |
| 消息可靠性 | - | 较低概率丢数据 | 参数优化配置,可做到0丢失 | 经过参数配置,可做到0丢失 |
| 优势 | 语言,性能极好,延时很低,吞吐量万级,MQ功能完备 | 接口简单易用,吞吐量大,分布式扩展,社区活跃,支持大规模Topic,支持复杂业务场景 | 超高吞吐量,ms级别延时 | |
| 劣势 | 吞吐量较低 | |||
| 语言不容易定制开发 | 接口不是按照标准JMS规范走,有系统迁移要修改大量代码 | 可能进行消息重复消费 | ||
| 应用 | 都有使用 | 主用于解耦和异步 | 用于大规模吞吐,复杂业务中 | 大数据实时计算和日志采集中大规模使用 |
综上所述 :
RocketMQ 的优点 :
-
单机吞吐量:十万级别
-
可用性: 非常高,分布式结构
-
消息可靠性 : 经过参数优化配置,消息可以做到 0 丢失
-
功能支持 : MQ功能较为完善,分布式,扩展性好
-
支持10 亿级别消息堆积,不会因为堆积导致性能下降
-
源码Java,方便二次开发
:::info
系统 面向用户的C端系统,有一定并发量,对性能也有较高要求,所以选择低延迟,吞吐量比较高,可用性比较好的RocketMQ;
:::
缺点 : -
支持的客户端语言不多, 目前是Java和C++(其中C++不成熟)
-
没有在MQ核心中去实现 JMS 等接口,有些系统要迁移需要修改大量代码;
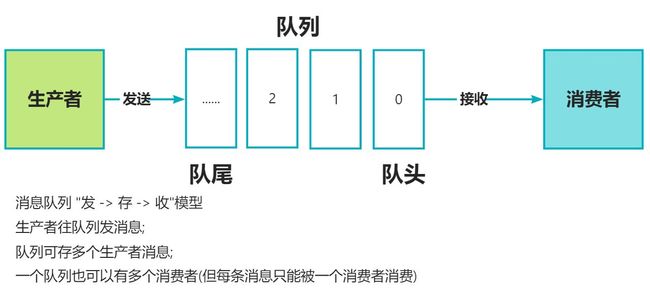
3 消息队列的消息模型
队列模型和发布/订阅模型;
队列模型:
发布订阅模型:
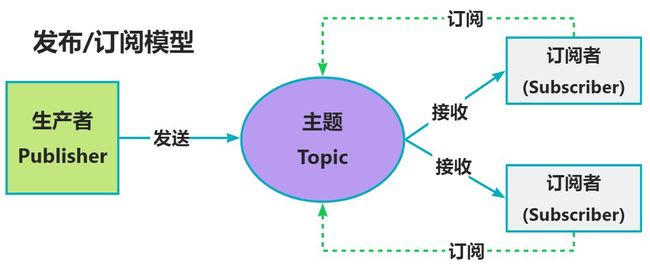
发布者将消息发送到主题中,订阅者在接收消息之前需要先 “订阅主题”.
"订阅"在这里既是一个动作,也可以理解是主题在消费时的一个逻辑副本,每份订阅中,订阅者都可接收到主题的所有消息;
生产者就是发布者, 队列就是主题, 消费者就是订阅者, 无本质区别.
唯一的不同就是 : 一份消息数据能否被多次消费;
4 RocketMQ的消息模型
标准的发布/订阅模型,
- RocketMQ本身消息由下面几个部分组成:
- Message 消息 必须有一个主题,也可以拥有一个可选标签Tag;
- Topic 主题,看作消息归类, 主题和生产者多对多的关系,主题也可以被0个,1个,多个消费者订阅;
- Tag 标签看成子主题;
- Group 订阅者概念通过消费组体现,每个消费者都消费主题中一份完整的消息,消费组之间可重复消费,消费组内部是竞争关系
- Message Queue 消息队列 一个主题下可设置多个消息队列,
- Offset 为每个消费者在每个队列维护一个消费位置(Consumer Offset)
5 消息消费模式
- 默认情况是集群消费 (Clustering) 这种模式下 一个消费者组共同消费一个主题的多个队列,一个队列只会被一个消费者消费; 如果某个消费者挂掉,分组内其它消费者会接替挂掉的消费者继续消费;
1.一条消息只会被同Group中的一个Consumer消费
2.多个Group同时消费一个Topic时,每个Group都会有一个Consumer消费到数据
- 广播消费消息会发给消费者组的每一个消费者进行消费;
广播消费消息将对一 个Consumer Group 下的各个 Consumer 实例都消费一遍。即即使这些 Consumer 属于同一个Consumer Group ,消息也会被 Consumer Group 中的每个 Consumer 都消费一次。
6 RocketMQ基本架构
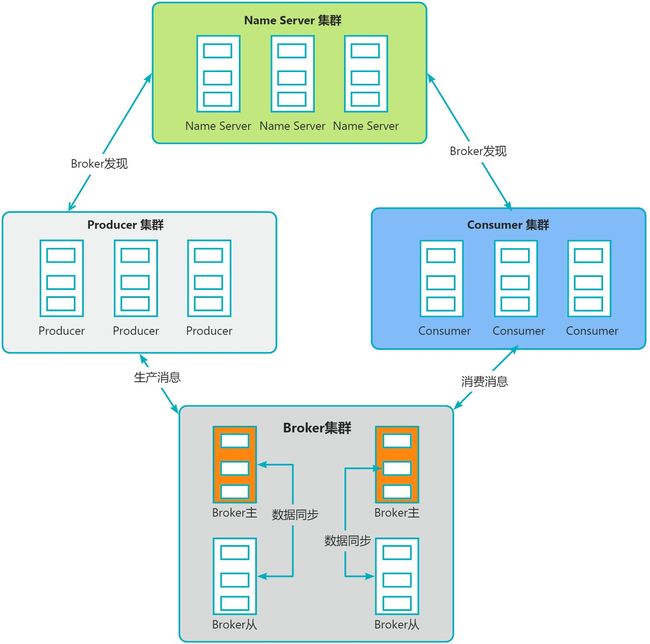
NameServer
动态列表,无状态服务器,. 好比ZK(但是ZK有状态);
特点 :
- 每个NS结点间相互独立,彼此没有任何信息交互;
- 功能一:和Broker结点保持长连接; 功能二:维护Topic的路由信息;
Broker
消息存储和中转角色,负责存储和转发消息; 就是MQ本身,收发消息/持久化消息等;

- Broker内部维护 Consumer Queue 用来存储消息索引,真正存储消息的地方是 CommitLog(日志文件);
- 单个Broker和所有NS保持长连接和心跳,定时将 Topic 信息同步到NS,和NS通信底层是通过Netty实现;
Producer
消息生产者,业务端负责发送消息,用户自行实现和分布式部署
- Producer用户进行分布式部署,消息通过多种负载均衡模式发送到Broker集群,发送低延时,支持快速失败;
- RocketMQ提供三种方式发送消息
- 同步发送: 收到响应再发下一个数据包,用于重要通知消息,邮件和营销短信;
- 异步发送:不等回应,直接发下一个数据包,比如用户视频上传后通知启动转码服务;
- 单向发送:只负责发,不等服务器回应且没有回调函数触发,比如日志收集;
Consumer
消息消费者, 一般是后台系统负责异步消费
- Consumer由用户部署,支持 PUSH 和 PULL 两种消费模式,支持集群消费和广播消费,提供实时消息订阅机制;
- PULL 拉取型消费者,主动从消息服务器拉取信息,只要批量拉取到消息,用户应用就会启动消费过程,主动消费型
- PUSH 推送型消费者,封装消息拉取,消费进度和其它内部维护工作,将消息到达时执行的回调接口留给用户应用程序实现,被动消费类型. 其实从实现看还是从消息服务器拉取消息,只不过PUSH首先要注册消费监听器,当监听器处触发后才开始消费消息;
进阶篇
7 保证消息不丢失/可用/可靠
生产阶段
主要通过请求确认机制,保证消息可靠传递.
- 1、同步发送的时候,要注意处理响应结果和异常。如果返回响应OK,表示消息成功发送到了Broker,如果响应失败,或者发生其它异常,都应该重试。
- 2、异步发送的时候,应该在回调方法里检查,如果发送失败或者异常,都应该进行重试。
- 3、如果发生超时的情况,也可以通过查询日志的API,来检查是否在Broker存储成功。
存储阶段
可以通过配置可靠性优先的 Broker 参数来避免因为宕机丢消息,简单说就是可靠性优先的场景都应该使用同步。
- 1、消息只要持久化到CommitLog(日志文件)中,即使Broker宕机,未消费的消息也能重新恢复再消费。
- 2、Broker的刷盘机制:同步刷盘和异步刷盘,不管哪种刷盘都可以保证消息一定存储在pagecache中(内存中),但是同步刷盘更可靠,它是Producer发送消息后等数据持久化到磁盘之后再返回响应给Producer。
- 3、Broker通过主从模式来保证高可用,Broker支持Master和Slave同步复制、Master和Slave异步复制模式,生产者的消息都是发送给Master,但是消费既可以从Master消费,也可以从Slave消费。同步复制模式可以保证即使Master宕机,消息肯定在Slave中有备份,保证了消息不会丢失。
消费
从Consumer角度分析,如何保证消息被成功消费?
- Consumer保证消息成功消费的关键在于确认的时机,不要在收到消息后就立即发送消费确认,而是应该在执行完所有消费业务逻辑之后,再发送消费确认。因为消息队列维护了消费的位置,逻辑执行失败了,没有确认,再去队列拉取消息,就还是之前的一条。
8 解决消息重复的问题
分布式消息队列,"有且仅有一次"就是确保一定投递和不重复投递比较难,RocketMQ选择了确保一定投递,保证消息不丢失,但可能造成消息重复.
就需要业务端自己保证,主要方式有两种: 业务幂等和消息去重;
业务幂等:第一种是保证消费逻辑的幂等性,也就是多次调用和一次调用的效果是一样的。这样一来,不管消息消费多少次,对业务都没有影响。
消息去重:第二种是业务端,对重复的消息就不再消费了。这种方法,需要保证每条消息都有一个惟一的编号,通常是业务相关的,比如订单号,消费的记录需要落库,而且需要保证和消息确认这一步的原子性。
具体做法是可以建立一个消费记录表,拿到这个消息做数据库的insert操作。给这个消息做一个唯一主键(primary key)或者唯一约束,那么就算出现重复消费的情况,就会导致主键冲突,那么就不再处理这条消息。
9 处理消息挤压
- 消费者扩容:如果当前Topic的Message Queue的数量大于消费者数量,就可以对消费者进行扩容,增加消费者,来提高消费能力,尽快把积压的消息消费玩。
- 消息迁移Queue扩容:如果当前Topic的Message Queue的数量小于或者等于消费者数量,这种情况,再扩容消费者就没什么用,就得考虑扩容Message Queue。可以新建一个临时的Topic,临时的Topic多设置一些Message Queue,然后先用一些消费者把消费的数据丢到临时的Topic,因为不用业务处理,只是转发一下消息,还是很快的。接下来用扩容的消费者去消费新的Topic里的数据,消费完了之后,恢复原状
10 顺序消息如何实现
顺序消息是指消息的消费顺序和产生顺序相同,在有些业务逻辑下,必须保证顺序,比如订单的生成、付款、发货,这个消息必须按顺序处理才行
顺序消息分为全局顺序消息和部分顺序消息,全局顺序消息指某个 Topic 下的所有消息都要保证顺序;
部分顺序消息只要保证每一组消息被顺序消费即可,比如订单消息,只要保证同一个订单 ID 个消息能按顺序消费即可。
#部分顺序消息
部分顺序消息相对比较好实现,生产端需要做到把同 ID 的消息发送到同一个 Message Queue ;在消费过程中,要做到从同一个Message Queue读取的消息顺序处理——消费端不能并发处理顺序消息,这样才能达到部分有序。
全局顺序消息
RocketMQ 默认情况下不保证顺序,比如创建一个 Topic ,默认八个写队列,八个读队列,这时候一条消息可能被写入任意一个队列里;在数据的读取过程中,可能有多个 Consumer ,每个 Consumer 也可能启动多个线程并行处理,所以消息被哪个 Consumer 消费,被消费的顺序和写人的顺序是否一致是不确定的。
要保证全局顺序消息, 需要先把 Topic 的读写队列数设置为 一,然后Producer Consumer 的并发设置,也要是一。简单来说,为了保证整个 Topic全局消息有序,只能消除所有的并发处理,各部分都设置成单线程处理 ,这时候就完全牺牲RocketMQ的高并发、高吞吐的特性了。
11 实现消息过滤
两种方案:
- 一种是在 Broker 端按照 Consumer 的去重逻辑进行过滤,这样做的好处是避免了无用的消息传输到 Consumer 端,缺点是加重了 Broker 的负担,实现起来相对复杂。
- 另一种是在 Consumer 端过滤,比如按照消息设置的 tag 去重,这样的好处是实现起来简单,缺点是有大量无用的消息到达了 Consumer 端只能丢弃不处理。
一般采用Cosumer端过滤,如果希望提高吞吐量,可以采用Broker过滤。
对消息的过滤有三种方式:
// 根据Tag过滤:这是最常见的一种,用起来高效简单
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("CID_EXAMPLE");
consumer.subscribe("TOPIC", "TAGA || TAGB || TAGC");
// SQL 表达式过滤:SQL表达式过滤更加灵活
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("please_rename_unique_group_name_4");
// 只有订阅的消息有这个属性a, a >=0 and a <= 3
consumer.subscribe("TopicTest", MessageSelector.bySql("a between 0 and 3");
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
consumer.start();
- Filter Server 方式:最灵活,也是最复杂的一种方式,允许用户自定义函数进行过滤
12 延时消息
//RocketMQ是支持延时消息的,只需要在生产消息的时候设置消息的延时级别:
// 实例化一个生产者来产生延时消息
DefaultMQProducer producer = new DefaultMQProducer("ExampleProducerGroup");
// 启动生产者
producer.start();
int totalMessagesToSend = 100;
for (int i = 0; i < totalMessagesToSend; i++) {
Message message = new Message("TestTopic", ("Hello scheduled message " + i).getBytes());
// 设置延时等级3,这个消息将在10s之后发送(现在只支持固定的几个时间,详看delayTimeLevel)
message.setDelayTimeLevel(3);
// 发送消息
producer.send(message);
}
//但是目前RocketMQ支持的延时级别是有限的:
private String messageDelayLevel = "1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h";
// 临时存储+定时任务
// Broker收到延时消息了,会先发送到主题(SCHEDULE_TOPIC_XXXX)的相应时间段的Message Queue中,
//然后通过一个定时任务轮询这些队列,到期后,把消息投递到目标Topic的队列中,
//然后消费者就可以正常消费这些消息。
13 死信队列
死信队列用于处理无法被正常消费的消息,即死信消息。
当一条消息初次消费失败,消息队列 RocketMQ 会自动进行消息重试;达到最大重试次数后,若消费依然失败,则表明消费者在正常情况下无法正确地消费该消息,此时,消息队列 RocketMQ 不会立刻将消息丢弃,而是将其发送到该消费者对应的特殊队列中,该特殊队列称为死信队列。
死信消息的特点:
- 不会再被消费者正常消费。
- 有效期与正常消息相同,均为 3 天,3 天后会被自动删除。因此,需要在死信消息产生后的 3 天内及时处理。
死信队列的特点:
- 一个死信队列对应一个 Group ID, 而不是对应单个消费者实例。
- 如果一个 Group ID 未产生死信消息,消息队列 RocketMQ 不会为其创建相应的死信队列。
- 一个死信队列包含了对应 Group ID 产生的所有死信消息,不论该消息属于哪个 Topic。
RocketMQ 控制台提供对死信消息的查询、导出和重发的功能。
原理篇
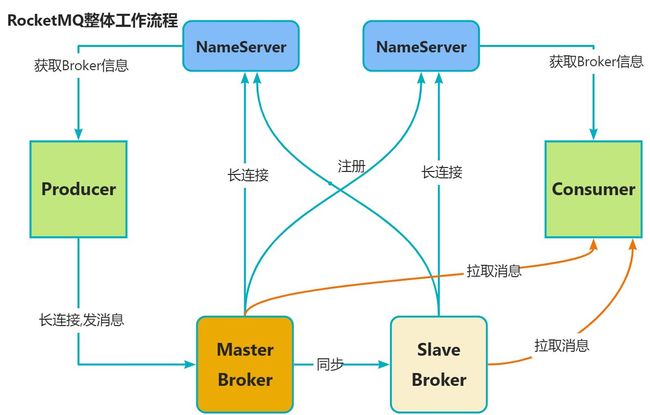
14 RocketMQ 整体工作流程
简单来说,RocketMQ是一个分布式消息队列,也就是消息队列+分布式系统。
作为消息队列,它是发-存-收的一个模型,对应的就是Producer、Broker、Cosumer;作为分布式系统,它要有服务端、客户端、注册中心,对应的就是Broker、Producer/Consumer、NameServer
所以我们看一下它主要的工作流程:RocketMQ由NameServer注册中心集群、Producer生产者集群、Consumer消费者集群和若干Broker(RocketMQ进程)组成:
- Broker在启动的时候去向所有的NameServer注册,并保持长连接,每30s发送一次心跳
- Producer在发送消息的时候从NameServer获取Broker服务器地址,根据负载均衡算法选择一台服务器来发送消息
- Conusmer消费消息的时候同样从NameServer获取Broker地址,然后主动拉取消息来消费
15 RocketMQ怎么对文件进行读写的?
RocketMQ对文件的读写巧妙地利用了操作系统的一些高效文件读写方式——PageCache、顺序读写、零拷贝。
- PageCache、顺序读取
在RocketMQ中,ConsumeQueue逻辑消费队列存储的数据较少,并且是顺序读取,在page cache机制的预读取作用下,Consume Queue文件的读性能几乎接近读内存,即使在有消息堆积情况下也不会影响性能。而对于CommitLog消息存储的日志数据文件来说,读取消息内容时候会产生较多的随机访问读取,严重影响性能。如果选择合适的系统IO调度算法,比如设置调度算法为“Deadline”(此时块存储采用SSD的话),随机读的性能也会有所提升。
页缓存(PageCache)是OS对文件的缓存,用于加速对文件的读写。一般来说,程序对文件进行顺序读写的速度几乎接近于内存的读写速度,主要原因就是由于OS使用PageCache机制对读写访问操作进行了性能优化,将一部分的内存用作PageCache。对于数据的写入,OS会先写入至Cache内,随后通过异步的方式由pdflush内核线程将Cache内的数据刷盘至物理磁盘上。对于数据的读取,如果一次读取文件时出现未命中PageCache的情况,OS从物理磁盘上访问读取文件的同时,会顺序对其他相邻块的数据文件进行预读取。
- 零拷贝
另外,RocketMQ主要通过MappedByteBuffer对文件进行读写操作。其中,利用了NIO中的FileChannel模型将磁盘上的物理文件直接映射到用户态的内存地址中(这种Mmap的方式减少了传统IO,将磁盘文件数据在操作系统内核地址空间的缓冲区,和用户应用程序地址空间的缓冲区之间来回进行拷贝的性能开销),将对文件的操作转化为直接对内存地址进行操作,从而极大地提高了文件的读写效率(正因为需要使用内存映射机制,故RocketMQ的文件存储都使用定长结构来存储,方便一次将整个文件映射至内存)。
#说说什么是零拷贝?
在操作系统中,使用传统的方式,数据需要经历几次拷贝,还要经历用户态/内核态切换。

图片来源 <图解操作系统>
- 从磁盘复制数据到内核态内存;
- 从内核态内存复制到用户态内存;
- 然后从用户态内存复制到网络驱动的内核态内存;
- 最后是从网络驱动的内核态内存复制到网卡中进行传输。
所以,可以通过零拷贝的方式,减少用户态与内核态的上下文切换和内存拷贝的次数,用来提升I/O的性能。零拷贝比较常见的实现方式是mmap,这种机制在Java中是通过MappedByteBuffer实现的。
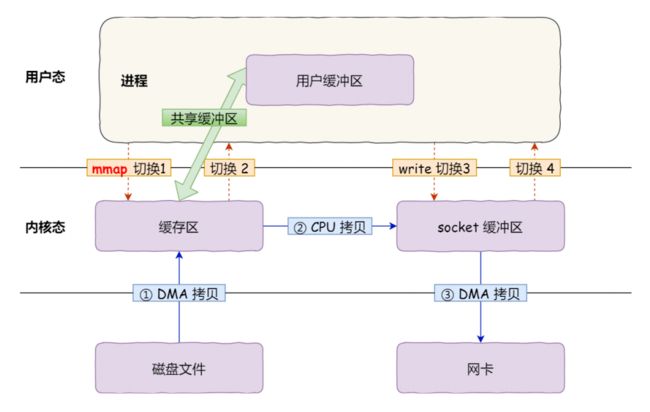
图片来源 <图解操作系统>
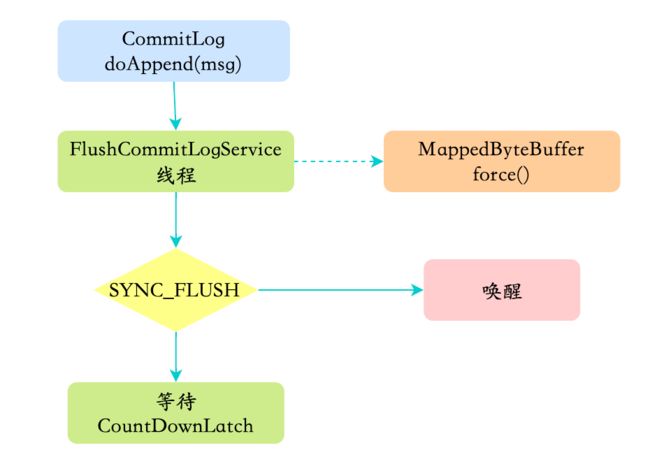
16 消息刷盘
RocketMQ提供了两种刷盘策略:同步刷盘和异步刷盘
- 同步刷盘:在消息达到Broker的内存之后,必须刷到commitLog日志文件中才算成功,然后返回Producer数据已经发送成功。
- 异步刷盘:异步刷盘是指消息达到Broker内存后就返回Producer数据已经发送成功,会唤醒一个线程去将数据持久化到CommitLog日志文件中。
Broker 在消息的存取时直接操作的是内存(内存映射文件),这可以提供系统的吞吐量,但是无法避免机器掉电时数据丢失,所以需要持久化到磁盘中。
刷盘的最终实现都是使用NIO中的 MappedByteBuffer.force() 将映射区的数据写入到磁盘,如果是同步刷盘的话,在Broker把消息写到CommitLog映射区后,就会等待写入完成。
异步而言,只是唤醒对应的线程,不保证执行的时机,流程如下图所示。
17 RocketMQ 的负载均衡如何实现
RocketMQ中的负载均衡都在Client端完成,具体来说的话,主要可以分为Producer端发送消息时候的负载均衡和Consumer端订阅消息的负载均衡。
Producer的负载均衡
Producer端在发送消息的时候,会先根据Topic找到指定的TopicPublishInfo,在获取了TopicPublishInfo路由信息后,RocketMQ的客户端在默认方式下selectOneMessageQueue()方法会从TopicPublishInfo中的messageQueueList中选择一个队列(MessageQueue)进行发送消息。具这里有一个sendLatencyFaultEnable开关变量,如果开启,在随机递增取模的基础上,再过滤掉not available的Broker代理。
// 选择一个消息队列
public MessageQueue test(){
// 索引递增
int index = this.sendWhichQueue.incrementAndGet();
// 利用索引取随机数,取余
int pos = Math.abs(index) % this.messageQueueList.size();
if (pos <0 )
pos = 0;
return this.messageQueueList.get(pos);
}
“latencyFaultTolerance”,是指对之前失败的,按一定的时间做退避。例如,如果上次请求的latency超过550Lms,就退避3000Lms;超过1000L,就退避60000L;如果关闭,采用随机递增取模的方式选择一个队列(MessageQueue)来发送消息,latencyFaultTolerance机制是实现消息发送高可用的核心关键所在。
默认策略随机选择:
- producer维护一个index
- 每次取节点会自增
- index向所有broker个数取余
- 自带容错策略
#Consumer的负载均衡
在RocketMQ中,Consumer端的两种消费模式(Push/Pull)都是基于拉模式来获取消息的,而在Push模式只是对pull模式的一种封装,其本质实现为消息拉取线程在从服务器拉取到一批消息后,然后提交到消息消费线程池后,又“马不停蹄”的继续向服务器再次尝试拉取消息。如果未拉取到消息,则延迟一下又继续拉取。在两种基于拉模式的消费方式(Push/Pull)中,均需要Consumer端知道从Broker端的哪一个消息队列中去获取消息。因此,有必要在Consumer端来做负载均衡,即Broker端中多个MessageQueue分配给同一个ConsumerGroup中的哪些Consumer消费。
- Consumer端的心跳包发送
在Consumer启动后,它就会通过定时任务不断地向RocketMQ集群中的所有Broker实例发送心跳包(其中包含了,消息消费分组名称、订阅关系集合、消息通信模式和客户端id的值等信息)。Broker端在收到Consumer的心跳消息后,会将它维护在ConsumerManager的本地缓存变量—consumerTable,同时并将封装后的客户端网络通道信息保存在本地缓存变量—channelInfoTable中,为之后做Consumer端的负载均衡提供可以依据的元数据信息。
- Consumer端实现负载均衡的核心类—RebalanceImpl
在Consumer实例的启动流程中的启动MQClientInstance实例部分,会完成负载均衡服务线程—RebalanceService的启动(每隔20s执行一次)。
通过查看源码可以发现,RebalanceService线程的run()方法最终调用的是RebalanceImpl类的rebalanceByTopic()方法,这个方法是实现Consumer端负载均衡的核心。
采用平均分配算法
18 RocketMQ 消息长轮询
长轮询,就是Consumer 拉取消息,如果对应的 Queue 如果没有数据,Broker 不会立即返回,而是把 PullReuqest hold起来,等待 queue 有了消息后,或者长轮询阻塞时间到了,再重新处理该 queue 上的所有 PullRequest。
//如果没有拉到数据
case ResponseCode.PULL_NOT_FOUND:
// broker 和 consumer 都允许 suspend,默认开启
if (brokerAllowSuspend && hasSuspendFlag) {
long pollingTimeMills = suspendTimeoutMillisLong;
if (!this.brokerController.getBrokerConfig().isLongPollingEnable()) {
pollingTimeMills = this.brokerController.getBrokerConfig().getShortPollingTimeMills();
}
String topic = requestHeader.getTopic();
long offset = requestHeader.getQueueOffset();
int queueId = requestHeader.getQueueId();
//封装一个PullRequest
PullRequest pullRequest = new PullRequest(request, channel, pollingTimeMills,
this.brokerController.getMessageStore().now(), offset, subscriptionData, messageFilter);
//把PullRequest挂起来
this.brokerController.getPullRequestHoldService().suspendPullRequest(topic, queueId, pullRequest);
response = null;
break;
}
// 挂起的请求,有一个服务线程会不停地检查,看queue中是否有数据,或者超时
@Override
public void run() {
log.info("{} service started", this.getServiceName());
while (!this.isStopped()) {
try {
if (this.brokerController.getBrokerConfig().isLongPollingEnable()) {
this.waitForRunning(5 * 1000);
} else {
this.waitForRunning(this.brokerController.getBrokerConfig().getShortPollingTimeMills());
}
long beginLockTimestamp = this.systemClock.now();
//检查hold住的请求
this.checkHoldRequest();
long costTime = this.systemClock.now() - beginLockTimestamp;
if (costTime > 5 * 1000) {
log.info("[NOTIFYME] check hold request cost {} ms.", costTime);
}
} catch (Throwable e) {
log.warn(this.getServiceName() + " service has exception. ", e);
}
}
log.info("{} service end", this.getServiceName());
}
写在最后, 如果觉得对你有帮助,麻烦点赞加关注,谢谢!
周日愉快!⭐⭐⭐