XML简介与解析
文章目录
-
- 了解XML(可扩展标记语言)
- XML的作用(简要)
- XML 语法
-
- 1.定义xml
- 2.文档声明
- 3.XML元素(标签)
- XML 解析( 常见的解析方式——面试题)
-
- ①.解析方式
- ②.针对这些解析方式的API
-
- Dom4j的基本用法
- Dom4J结合XPath解析XML
了解XML(可扩展标记语言)
XML(EXtensible Markup Language) 是 W3C 的推荐标准(结构标准语言),XML最初设计的目的是弥补HTML的不足,以强大的扩展性满足网络信息发布的需要,后来逐渐用于网络数据的转换和描述。XML 被设计为传输和存储数据,其焦点是数据的内容(当然安卓开发是用来做界面布局的)。HTML 被设计用来显示数据,其焦点是数据的外观。
XML的作用(简要)
- 可以用来保存数据
如安卓中的数据存储使用SharedPreferences专门存储一些单一的小数据,数据就是以xml保存的
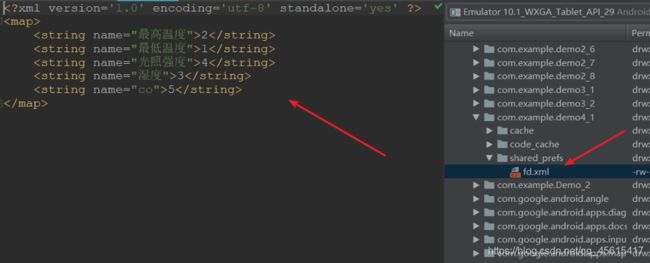
- 可以用来做配置文件
这个是最为普遍的,如Tomcat中conf的web.xml与server.xml - 数据传输载体
xml是一种数据交换格式,但是xml解析数据较复杂,现在客户端与服务器数据交换格式一般使用JSON
XML 语法
1.定义xml
xml其实就是一个文件,我们只要建一个文本按一定的语法编写后,把文件的后缀为 .xml即可。
2.文档声明
<?xml version="1.0" encoding="gbk" standalone="no" ?>
version:解析这个xml的时候,使用那个版本的解析器解析
encoding:解析xml中的文字的时候,使用什么编码来解析
standalone:no——该文档会依赖关联其他文档 yes——这是一个独立的文档
关于encoding:
①.如果文件是以GBK的编码保存的,那么要是xml正常显示,则encoding应该是GBK或gb2312。(以什么编码方式保存,则encoding就是什么编码方式)
GB2312编码适用于汉字处理、汉字通信等系统之间的信息交换。GBK与GB 2312—1980国家标准所对应的内码标准兼容。对于人名、古汉语等方面出现的罕用字,GB 2312不能处理,这导致了后来GBK及GB 18030汉字字符集的出现。这里可以看出gbk是对gb2132的扩展,但是一些对于一些罕见字,如果使用gbk编码保存,以gb2312来解码,可能会出现乱码
②.通常PC端保存文件时见到的ANSI其实就是本地编码GBK;

③.一般为了通用性建议使用UTF-8编码保存,即encoding也应为UTF-8.
3.XML元素(标签)
①.<> 括起来的都叫元素,且是成对出现的,可以称为开始标签和结束标签。
> >
②.文档声明下来的第一个元素叫做根元素 (根标签)
③.属性的定义:XML元素可以在开始标签中包含属性
<元素名称 属性名称="属性的值">> > >
④.关于空标签:空标签“<”标识开始,以“/>”标识结束,一般配合属性来用。
语法格式:
<空标签的名称 属性列表/> 如: >
或
<空标签的名称/> 如: >
⑤.元素里面可以嵌套其他的元素,元素里面也可以是普通的文字
>
>
>张三 >
>
>
>王五 >
>
>
⑥.标签可以自定义。
更多规则可参考:
XML 教程
XML 解析( 常见的解析方式——面试题)
获取元素里面的字符数据或属性数据。
①.解析方式
解析方式有很多种,常用的有两种。
1.DOM:文档对象模型(Document Obiect Model),官方推荐
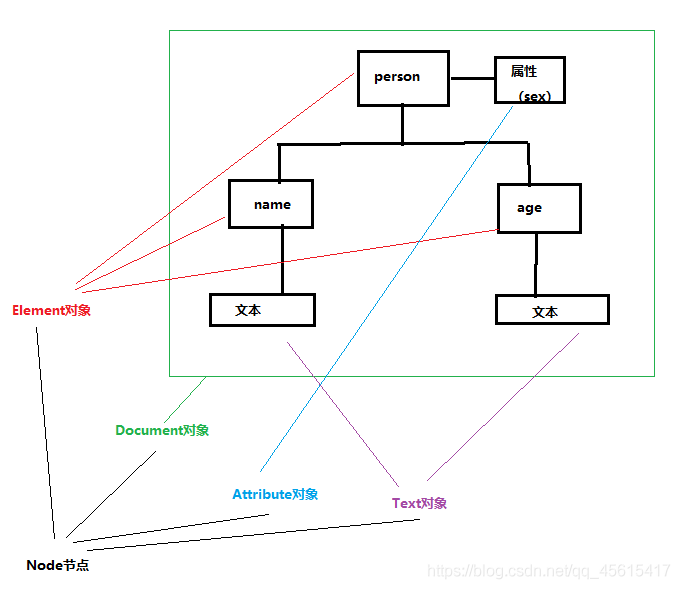
dom原理:把整个xml全部加载到内存中,形成树状结构。整个文档对应Document对象,属性对应Attribute对象,所有元素节点对应Element对象,文本对应Text对象,而以上所有对象都可称为Node对象
优点:可以对文档进行增删改查操作
缺点:当xml很大时,由于是把整个文档加载到内存,将会造成内存溢出。
DOM解析时XML文档形成所树结构的理解
<?xml version="1.0" encoding="UTF-8"?>
>
>李华 >
>18 >
>
2.SAX:简单应用程序接口(Simple Api For Xml)
特点:基于事件驱动,读取一行,解析一行。
优点:不会造成内存溢出
缺点:不能进行增删改,只能查询
②.针对这些解析方式的API
DOM与SAX是一种解析思想,并没有提供相应的api实现,一些组织或者公司, 针对这些解析方式, 给出了一些解决方案。
常见的解析工具:
- Dom4j:DOM4J组织提供的工具包,使用广泛。
- JDom:JDOM组织提供的工具包,使用较少
- JAXP:sun公司提供的,使用比较繁琐,使用少。
- Jsoup:jsoup 是一款Java 的HTML解析器。也能够解析XML,但是通常用于解析HTML,适用于网络爬虫。使用Java+Jsoup实现网络爬虫
Dom4j的基本用法
使用核心类SaxReader加载xml文档获得Document,通过Document对象获得文档的根元素,就可以针对性的进行解析操作了。
dom4j下载地址
常用方法:
SaxReader对象
| 方法 | 作用 |
|---|---|
| new SaxReader() | 构造器 |
| Document read(String url) | 加载执行xml文档 |
| Document对象 | |
| 方法 | 作用 |
| – | – |
| Element getRootElement() | 得到根元素 |
Element对象
| 方法 | 作用 |
|---|---|
| Element element([String ele]) | 获得指定名称第一个子元素。可以不指定名称 |
| List elements([String ele] ) | 获得指定名称的所有子元素。可以不指定名称(获取根元素下的所有子元素) |
| String getText() | 获得当前元素的文本内容 |
| String attributeValue(String attrName) | 获得指定属性名的属性值 |
| String elementText(Sting ele) | 获得指定名称子元素的文本值 |
| String getName() | 获得当前元素的元素名 |
使用示例:
1.导包
![]()
2.创建xml

<?xml version="1.0" encoding="UTF-8"?>
<students>
<student>
<name>李华</name>
<age>18</age>
</student>
<student>
<name>小明</name>
<age>28</age>
</student>
</students>
2.测试基本用法
![]()
package xmlparser;
import java.io.File;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class XmlParser {
public static void main(String[] args){
try {
//1. 创建一个解析器对象
SAXReader reader=new SAXReader();
//2.指定解析的xml源,得到的 Document 对象就带表了整个 XML
Document document = reader.read(new File("src/xml/student.xml"));
//3.得到元素
//得到根元素
Element rootElement = document.getRootElement();
//获取根元素下的子元素 name
String name1 = rootElement.element("student").element("name").getText();
System.out.println(name1);
// Element element = rootElement.element("student");
// System.out.println(element);//org.dom4j.tree.DefaultElement@31befd9f [Element: 运行结果:

Dom4J结合XPath解析XML
jaxen下载地址
- XPath 是一门在 XML 文档中查找信息的语言。使用Xpath提供的api,结合xpaht的语法(路径表达式)完成选取XML文档元素节点进行解析操作。
- DOM4j 对 XPath 有良好的支持,如访问一个节点,可直接用 XPath 选择,支持我们在解析xml的时候,能够快速的定位到具体的某一个元素。
XPath语法(使用XPath表达式直接定位到XML里的节点):
- 绝对路径表达式方式:
/a/b/c找根标签a下边的b,b下边的c - 全文搜索路径表达式方式:
//a全文搜索a标签 - 定位属性的方式:
//@id全文搜索id属性 - 条件筛选方式:
①通过序号定位://a[3]全文搜索a元素,但是要第3个
②通过属性筛选://a[@id="1"]全文搜索id属性值为1的a元素
使用示例:
1.导包
2.测试基本使用:
package xmlparser;
import java.io.File;
import java.util.List;
import org.dom4j.DocumentException;
public class XmlParserXpath {
public static void main(String[] args){
try {
//1. 创建一个解析器对象
org.dom4j.io.SAXReader reader=new org.dom4j.io.SAXReader();
//2.指定解析的xml源
org.dom4j.Document document = reader.read(new File("src/xml/student.xml"));
//3.得到元素
//得到根元素
org.dom4j.Element rootElement = document.getRootElement();
//返回一个元素,获取的是第一个name
org.dom4j.Element nameElement = (org.dom4j.Element) rootElement.selectSingleNode("//name");
System.out.println(nameElement.getText());
System.out.println("===================");
//获取文档里面的所有name元素
List<org.dom4j.Element> selectNodes = rootElement.selectNodes("//name");
for(org.dom4j.Element nameElementBianli:selectNodes){
System.out.println(nameElementBianli.getText());
}
} catch (DocumentException e) {
e.printStackTrace();
}
}
}
运行结果:

一般的使用,在查找指定节点的时候,根据XPath语法规则来查找,更多XPath语法规则可参考:
XPath 教程