你知道零复制以及netty的零复制是怎么回事吗?
在开始介绍零复制之前,我们先来明确几个概念:
(1) 上下文切换: 当用户程序向内核发起系统调用时 ,cpu将用户进程从用户态切换到内核态, 当系统调用返回时,cpu将用户进程从内核态切换回用户态.
(2) cpu拷贝:由CPU直接处理数据的传送,数据拷贝时会一直占用cpu的资源
(3) DMA拷贝: 由CPU向DMA磁盘控制器下达命令,让DMA控制器来处理数据的传送,数据传送完毕再把信息反馈给CPU,从而减轻了CPU资源的占有率.
(4))PIO模式: 是一种通过CPU执行I/O端口指令来进行数据的读写的数据交互模式.
PIO模式向DMA模式的发展历程
以Read()为例PIO模式的IO操作的基本流程如下:

从上图可看出,PIO模式存在拖慢了CPU速度的问题,在读取磁盘文件到内存中,数据要经过CPU存储转发,这种方式是十分不合理,需要占用大量的CPU时间来读取文件,造成文件访问时系统几乎停止响应.
为了解决PIO模式拖慢CPU速度的问题,就出现了DMA技术. DMA的全称叫直接内存存取(Direct Memory Access),是一种允许外围设备(硬件子系统)直接访问系统主内存的机制,也就是,基于DMA访问方式,系统主内存与硬盘或网卡之间的数据传输可以绕开CPU的全程调度.目前大多数的硬件设备,包括磁盘控制器,网卡,显卡以及声卡等支持DMA技术.
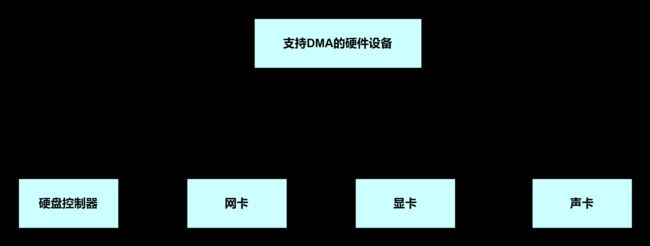
整个数据传输操作在一个DMA控制器下进行的.CPU 除了在数据传输开始和结束时做一点处理外(开始和结束时要做中断处理),在传输过程中CPU可以继续进行其他的工作.
这样大部分时间里,cpu计算和I/0操作都处于并行操作,使整个计算机系统的效率大大提升.DMA传输的优势:给CPU 带来了解脱
DMA 传输则在I/O中断的基础上引入了DMA磁盘控制器,由DMA磁盘控制器负责数据的慢传输,降低了I/O中断作为cpu资源的大量消耗,CPU从繁重的I/O操作中解脱,数据读取操作的流程如下:
(1) 用户进程向cpu发起read 系统调用读取数据,由用户态切换为内核态,然后一直阻塞等待数据的返回.
(2)cpu在接收到指令以后对DMA磁盘控制器发起调度指令.
(3)DMA 磁盘控制器对磁盘发起I/O 请求,将磁盘数据先放入磁盘控制器缓冲区,cpu全程不参与此过程.
(4)数据读取完成后,DMA磁盘控制器会接受到磁盘的通知,将数据从磁盘控制器缓冲区拷贝到内核缓冲区.
(5)DMA 磁盘控制器向cpu发出数据读完的信号,由CPU负责将数据从内核缓冲区拷贝到用户缓冲区.
(6)用户进程由内核态切换回用户态,解除阻塞状态,然后等待cpu的下一个执行时间钟.
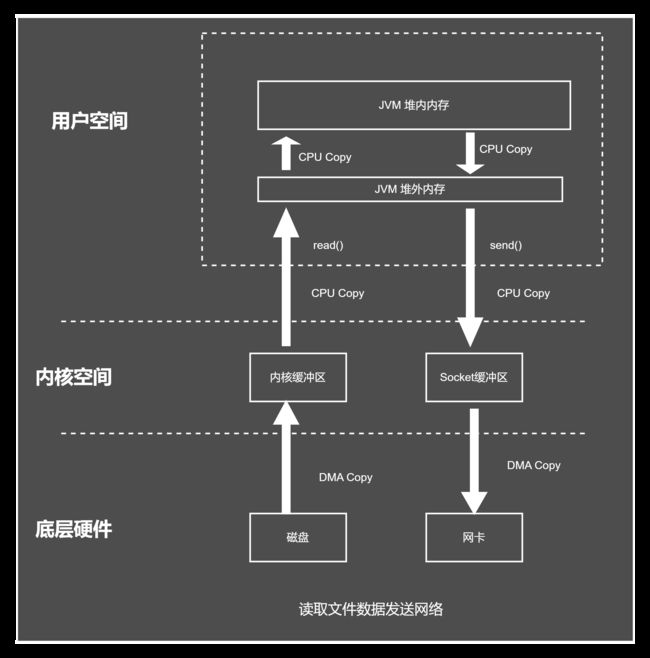
基于DMA技术的IO基础流程如下:

传统I/O操作的数据读写流程,
触发4次上下文切换,2次DMA拷贝和4次CPU拷贝
IO 传输过程,零拷贝优化方案
减少用户空间和内核空间的拷贝
mmap+write 零拷贝
使用mmap 的目的是将内核中读缓冲区(read buffer)的地址与用户空间的缓冲区(user buffer) 进行映射.
省去了将数据从内核缓冲区(read buffer )拷贝到用户缓冲区(user buffer)的过程.
mmap+write 实现零拷贝的基本流程如下:

(1) 用户进程向内核发起系统mmap调用
(2)将用户进程的内核空间的读缓冲区与用户空间的缓冲区进行内存地址映射
(3)内核基于DMA Copy 将文件数据从磁盘复制到内核缓冲区
(4)用户进程mmap系统调用完成并返回.
(5)用户进程向内核发起write系统调用
(6)内核基于CPU Copy 将数据从内核缓冲区拷贝到Socket缓冲区
(7)内核基于DMA Copy 将数据从Socket缓冲区拷贝到网卡
(8)用户进程write 系统调用完成并返回.
mmap+write零拷贝方式优点是mmap+write 系统调用的零拷贝方式,整个拷贝过程会发生4次上下文切换,1次CPU Copy拷贝和2次DMA Copy
mmap+write零拷贝方式主要用于提高I/O性能,特别是针对大文件,对于小文件,内存映射文件反而会导致碎片空间的浪费.
mmap +write 零拷贝应用在java的MappedByteBuffer中. 即将文件的内核缓冲区直接映射到用户空间的内存地址,这样对文件的操作不再是write/read,而是直接对内存地址的操作.获取MappedByteBuffer对象的方法如下:
MappedByteBuffer mapBuffer = filechannel.map(FileChannel.MapMode.READ_WRITE, 0, 1000);
减少内核空间的内存复制
sendfile + DMA Gather Copy 零复制
通过sendFile 系统调用,数据可以直接在内存空间内部进行I/O传输,从而省去了数据在用户空间和内核空间之间的来回拷贝.
sendFile系统调用在linux内核版本2.1中被引入,目的是简化通过网络在两个通道之间进行的数据传输过程.Sendfile调用中I/O 数据对用户空间是完全不可见的.也就是说,这一次完全意义上的数据传输过程.
sendfile + DMA Gather Copy 零复制 基本流程如下:

(1)用户进程发起sendfile 系统调用,
(2)内核基于DMA Copy 将文件数据从磁盘拷贝到内核缓冲区
(3)内核将内核缓冲区中的文件描述信息(文件描述符,数据长度)拷贝到Socket缓冲区
(4)内核基于Socket缓冲区的文件描述信息和DMA硬件提供的Gather Copy功能将内核缓冲区数据复制到网卡
(5)用户进程sendfile系统调用完成并返回.
sendfile + DMA Gather Copy 零复制的优点是基于Sendfile 系统调用的零拷贝方式,整个拷贝过程会发生2次上下文切换,0次CPU拷贝和2次DMA拷贝.
sendfile + DMA Gather Copy 零复制的缺点是 Sendfile+DMA gather copy 拷贝方式存在用户程序不能对数据进行修改的问题.
java中的文件通道FileChannelImpl的transferTo()和transferFrom()方法通过Sendfile系统调用实现零拷贝,
RocketMQ选择了mmap+write 零拷贝方式,适用于业务级消息这种小块文件的数据持久化和传输.
kafka 采用了SendFile 零拷贝方式,适用于系统日志消息这种高吞吐量的大块文件的数据持久化和传输.但是kafka 的索引文件使用的是mmap+write方式,仅仅数据文件使用的是SendFile方式.
Splice 系统调用(使用得少)
splice 系统调用可以在内核空间的读缓冲区(read buffer) 和网络缓冲区(socket buffer)之间建立管道(pipeline),从而避免了两者之间的CPU拷贝操作.
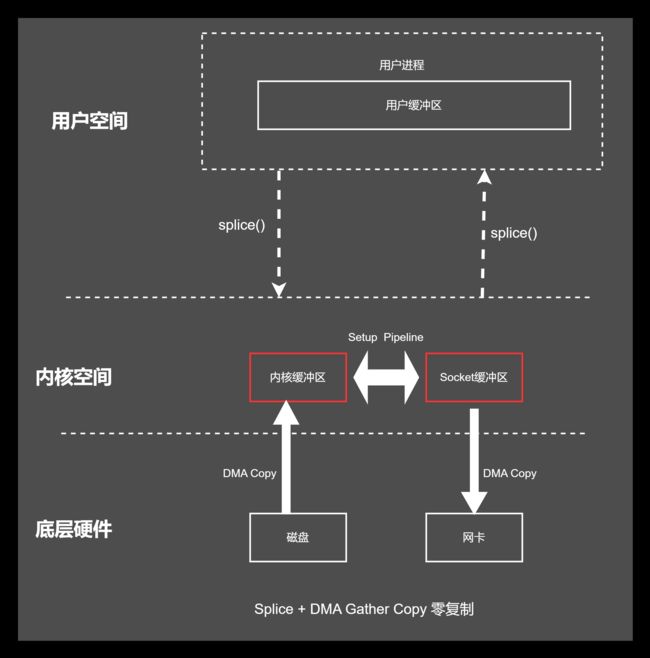
linux 在2.6.17版本引入Splice 系统调用,不仅不需要硬件支持,并实现了两个文件描述符之间的数据零拷贝.
其优点是 基于Splice 系统调用的零拷贝方式,整个拷贝过程会发生2次上下文切换,0次CPU拷贝以及2次DMA拷贝.
其缺点 是两个文件描述符参数中有一个必须是管道设备.
减少jvm堆内存的内存复制
如果是JVM 堆内存的Send操作需要3次内存复制,如下图示:

java 堆内存的一次网络IO 操作,需要6次复制,如下图所示:
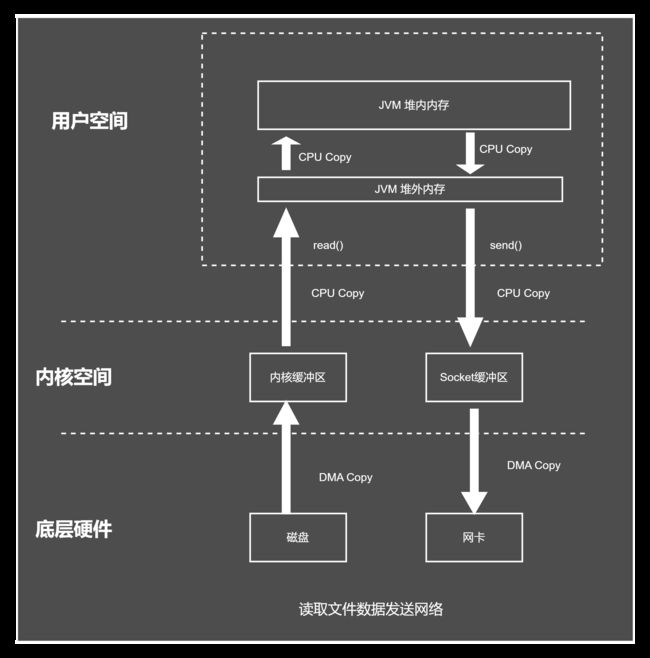
如果使用直接内存的一次传统网络send操作,则需要2次内存复制,如下图所示:

使用java的堆内存地址值,与JNI堆外内存的地址值不一致的原因是由于JVM 的有自己的内存模型,JVM缓冲区起始地址和长度,与JNI堆外内存的值不一致,所以,不能直接传递给JNI函数去调用底层的C语言内存操作函数.
以NIO SocketChannel为例,在SocketChannelImpl在写数据的时候,会调用write()方法并调用IOUtil.write()方法,其核心源码如下:
@Override
public int write(ByteBuffer buf) throws IOException {
...
try {
...
do {
n = IOUtil.write(fd, buf, -1, nd);
} while (n == IOStatus.INTERRUPTED && isOpen());
...
} finally {
...
}
...
} finally {
...
}
}
static int write(FileDescriptor fd, ByteBuffer src, long position,
boolean directIO, int alignment, NativeDispatcher nd)
throws IOException
{
//有两种情况,
//情况1:如果缓冲ByteBuffer是直接缓冲区,就把数据写到内核缓冲区
if (src instanceof DirectBuffer) {
return writeFromNativeBuffer(fd, src, position, directIO, alignment, nd);
}
//情况2:如果ByteBuffer不是直接缓冲,是堆内存,
// Substitute a native buffer
int pos = src.position();
int lim = src.limit();
assert (pos <= lim);
int rem = (pos <= lim ? lim - pos : 0);
ByteBuffer bb;
if (directIO) {
Util.checkRemainingBufferSizeAligned(rem, alignment);
bb = Util.getTemporaryAlignedDirectBuffer(rem, alignment);
} else {
//step1:申请一个临时直接内存
bb = Util.getTemporaryDirectBuffer(rem);
}
try {
//step:把数据复制到临时直接内存
bb.put(src);
bb.flip();
// Do not update src until we see how many bytes were written
src.position(pos);
//step3:再把临时的直接内存写入到内核缓存区,此处有2次的复制
int n = writeFromNativeBuffer(fd, bb, position, directIO, alignment, nd);
if (n > 0) {
// now update src
src.position(pos + n);
}
return n;
} finally {
Util.offerFirstTemporaryDirectBuffer(bb);
}
}
写入内核空间的源码如下:
private static int writeFromNativeBuffer(FileDescriptor fd, ByteBuffer bb,
long position, boolean directIO,
int alignment, NativeDispatcher nd)
throws IOException
{
....
//核心代码:使用C语言的函数pwrite和write对Socket缓冲区和内核缓冲区的写入
if (position != -1) {
written = nd.pwrite(fd,
((DirectBuffer)bb).address() + pos,
rem, position);
} else {
written = nd.write(fd, ((DirectBuffer)bb).address() + pos, rem);
}
...
}
NIO 使用directbuffer 的优势是不必将数据在堆外和堆内拷贝了,减少了一次内存拷贝,降低了堆内存的占用,减轻了gc的压力.
Netty 的零拷贝实现方式
Netty提供CompositeByteBuf类实现零复制
此种方式属于进程内部的数据操作优化;可以将多个ByteBuf合并为一个逻辑上的ByteBuf,避免了各种ByteBuf之间的拷贝.
使用方式:
CompositeByteBuf compositeByteBuf = Unpooled.compositeBuffer(3);
compositeByteBuf.addComponents(true,ByteBuf1,ByteBuf1);
需要注意的是addComponents第一个参数必须为true, 那么writeIndex 才不为0,才能从compositeByteBuf中读到数据.

通过wrap 操作实现零复制
此种方式属于进程内部的数据操作优化;我们可以将byte[]数组,ByteBuf,ByteBuffer 等包装成一个Netty ByteBuf对象,进而避免拷贝操作.
使用方式:
byte[] bytes = data.getBytes();
ByteBuf byteBuf = Unpooled.wrappedBuffer(bytes);
Unpooled.wrappedBuffer(bytes)就是进行了byte[]数组的包装工作,过程中不存在内存拷贝.即包装出来的byteBuf和byte[]数组指向了同一个存储空间.但是,因为值引用,所以byte修改也会影响byteBuf的值.
ByteBuf支持slice操作实现零复制
此种方式属于进程内部的数据操作优化;可以将ByteBuf分解为多个共享同一个存储区域的ByteBuf,避免内存的拷贝.
使用方式:
ByteBuf buffer = ByteBufAllocator.DEFAULT.directBuffer(1024);
ByteBuf header = buffer.slice(0,50);
ByteBuf body = buffer.slice(51,1024);
Netty使用直接内存,
消息在发送过程中少了一次缓冲区的内存拷贝,此种方式属于进程内部的数据操作优化;这种方式使用得较少,就不在论述.
通过FileRegion实现零复制
此种属于操作系统层面的零复制.Netty的文件传输调用FileRegion 包装的transferTo方法,可以直接将文件缓冲区的数据发送到目标Channel,是属于sendFile+ DMA Gather Copy 相结合方式的零复制. 避免通过循环write方式导致的内存拷贝问题.
示例如下:
public class FileRegionDemo extends ChannelInboundHandlerAdapter {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
RandomAccessFile raf = null;
long length = -1;
try {
// 1. 通过 RandomAccessFile 打开一个文件.
raf = new RandomAccessFile(msg.toString(), "r");
length = raf.length();
ctx.write(new DefaultFileRegion(raf.getChannel(), 0, length));
} catch (Exception e) {
e.printStackTrace();
return;
} finally {
if (length < 0 && raf != null) {
raf.close();
}
}
super.channelRead(ctx, msg);
}
}
DefaultFileRegion 的使用:
首先通过RandomAccessFile 打开一个文件,然后Netty使用了DefaultFileRegion来封装一个FileChannel,即new DefaultFileRegion(raf.getChannel(), 0, length),当有了FileRegion后,我们就可以直接通过它将文件的内容直接写入Channel中,而不需要像传统的做法:拷贝文件内容到临时buffer,然后再将buffer 写入channel,通过这样的零拷贝操作,无疑对传输大文件很有帮助.