OpenCL编程指南-7缓冲区和子缓冲区
内存对象、缓冲区、子缓冲概述
OpenCL内存对象的分配对应于一个上下文,这个上下文可能有一个或多个相关联的设备。内存对象对这个上下文中的所有设备都是全局可见的。不过,由于OpenCL定义了一个宽松的内存模型,所以对一个内存对象的所有写操作并非对同一个缓冲区的后续读操作都可见。
通过观察可以明确这一点,与其他设备命令类似,读、写内存对象时将把一个与特定设备相关的命令入队。可以将内存对象的读/写标记为阻塞,这会阻塞宿主机线程,直到排队的命令完成为止,这样写至一个特定设备的内存对与特定上下文相关的所有设备都可见,或者所读的内存已经完全读回宿主机内存。如果读/写命令未阻塞,宿主机线程可能会在排队的命令完成之前返回,则应用程序不能假设所读/写的内存已经准备就绪可以使用。
在这种情况下,宿主机应用程序必须使用以下OpenCL同步原语之一来确保命令已经完成:
1)cl_int clFinish(cl_command_queue queue),这里的queue是特定的命令队列,读/写命令会在这个命令队列中排队。clFinish会阻塞,直到 queue中所有未结束的命令都已经完成。
2)cl_int clwaitForEvents(cl_uint num_events, const cl _event *event_list),这里的event_list至少包含与特定读/写相关联的入队命令所返回的事件。clwaitForEvents 会阻塞,直到与event_list中相应事件相关联的所有命令都已经完成。
对于与不同上下文关联的OpenCL内存对象,只能与同一个上下文中创建的其他对象一同使用。例如,不能用不同上下文创建的命令队列完成读/写操作。由于上下文的创建特别针对一个特定的平台,所以不可能创建不同平台设备之间共享的内存对象。如果一个应用程序要使用系统中的所有OpenCL设备,那么在这种情况下,当管理数据时,需要通过宿主机内存空间向给定上下文以及在上下文之间复制数据。
创建缓冲区和子缓冲区
缓冲区(buffer):1维字节数组。缓冲区对象是1维的内存资源,可以包含标量、矢量或用户定义的数据类型。缓冲区对象使用以下函数创建:
cl_mem clCreateBuffer(cl_context context,
cl_mem_flags flags,
size_t size,
void *host_ptr,
cl_int *errcode_ref)
context 一个合法的上下文对象,要为这个上下文分配缓冲区
flags 这是一个位域,用于指定关于缓冲区创建的分配和使用信息。flags可取的合法值由枚举cl_mem_flags定义
size 所分配的缓冲区大小(字节数)
host_ptr 这是一个数据指针,由应该程序分配; 这个指针在clCreateBuffer调用中如何使用由flags参数确定, host_ptr指向的数据大小至少为请求分配的大小, 也就是说, >=size字节
errode_ret 如果是非NULL, 函数返回的错误码将由这个参数返回
cl_mem_flags支持的合法值
CL_MEM_READ_WRITE 指定内存对象将由内核读写。
如果没有给定任何其他修饰符,则认为这个模式是默认模式
CL_MEM_WRITE_ONLY 指定内存对象将由内核写,但不能读。
对于使用CL_MEM_WRITE_ONLY创建的缓冲区或其他内存对象(如图像),
在内核中读取这些内存对象的行为是未定义的
CL_MEM_USE_HOST_PTR 只有当host_ptr为非 NULL时,这个标志才合法。
如果指定了这个标志,表示就用程序看望OpenCL实现使用host_ptr引用的内存作为内存对象的存储位
CL_MEM_ALLOC_HOST_PTR 指定缓冲区应当在宿主机可访问的内存中分配。
不能同时使用CL_MEM_ALLOC_HOST_PTR 和CL_MEM_USEHOST_PTR
CL_MEM_COPY_HOST_PTR 如果指定了这个标志,表示应用程序希望OpenCL实现分配内存对象的内存,并从host_ptr引用的内存复制数据。
不能同时使用CL_MEM_CoPY_HOST_PTR和CL_MEM_USE_HOST_PTR
对于使用宿主机可访间的(例如,PCIe)内存分配的内存对象,可以结合使用CL_MEM_COPY_HOST_PTR和CL_MEM_ALLOC_HOST_PTR初始化这些内存对象的内容。
只有当host_ptr为非NULL时, 这个标志才合法
与其他内核参数类似,也使用函数clSetKernelArg将缓冲区作为参数传递到内核,在内核中定义为全局地址空间中一个期望数据类型的指针。下面的代码给出了一些简单的例子,展示如何创建缓冲区,以及如何用它来设置内核参数:
#define NUM_BUFFER_ELEMENTS 100
cl_int errNum;
cl_context;
cl_kernel kernel;
cl_command_queue queue;
float inputOutput[NUM_BUFFER_ELEMENTS];
cl_mem buffer;
//place code to create context, kernel, and command-queue here
//initialize inputOutput
buffer = clCreateBuffer(context,
CL_MEM_READ_WRITE | CL_MEM_COPY_HOST_PTR,
sizeof(float) * NUM_BUFFER_ELEMENTS,
&errNum);
//check for errors
errNum = setKernelArg(kernel, 0, sizeof(buffer), &buffer);
下面的内核定义给出一个简单例子,指出如何指定内核的缓冲区参数:
__kernel void square(__global float *buffer)
{
size_t id = get_global_id(0);
buffer[id] = buffer[id] * buffer[id];
}
进一步推广,将内核square完成的工作划分到与一个特定上下文关联的所有设备,clEnqueueNDRangeKernel的偏移量参数可以用来计算缓冲区中的偏移量。下面的代码展示了如何完成这个工作:
#define NUM_BUFFER_ELEMENTS 100
cl_int errNum;
cl_uint numDevices;
cl_device_id *deviceIDs;
cl_context;
cl_kernel kernel;
std::vector<cl_command_queue> queues;
float *inputOutput;
cl_mem buffer;
//place code to create context, kernel, and command-queue here
//initialize inputOutput
buffer = clCreateBuffer(context,
CL_MEM_READ_WRITE | CL_MEM_COPY_HOST_PTR,
sizeof(float) *NUM_BUFFER_ELEMENTS,
inputOutput,
&errNum);
//check for errors
errNum = setKernelArg(kernel, 0, sizeof(buffer), &buffer);
//Create a command-queue for each device
for(int i = 0; i < numDevices; i++)
{
cl_command_queue queue = clCreateCommandQueue(context,
deviceIDs[i],
0,
&errNum);
queues.push_back(queue);
}
//Submit kernel enqueue to each queue
for(int i = 0; i < queues.size(); i++)
{
cl_command_queue = clCreateCommandQueue(context,
deviceIDs[i],
0,
&errNum);
queues.push_back(queue);
}
//Submit kernel enqueue to each queue
for(int i = 0; i < queues.size(); i++)
{
cl_event event;
size_t gWI = NUM_BUFFER_ELEMENTS;
size_t offset = i * NUM_BUFFER_ELEMENTS * sizeof(int);
errNum = clEnqueueNDRangeKernel(queues[i],
kernel,
1,
(const size_t*)&offset,
(const size_t*)&gWI,
(const size_t*)NULL,
0,
0,
&event);
events.push_back(event);
}
//wait for commands to complete
clWaitForEvents(events.size(), events.data());
还可以采用一种更一般的方法,将缓冲区上完成的工作进一步划分,使用子缓冲区来完成。子缓冲区为一个特定缓冲区提供一个视图,例如,允许开发人员将一个缓冲区划分为可以独立处理的小块。子缓冲区纯粹是一个软件抽象,可以用子缓冲区完成的工作都可以利用缓冲区并明确指定偏移量来完成。子缓冲区增加了一层模块性,如果只使用缓冲区则很难表述这一层抽象。与前面介绍的方法相比,子缓冲区的优点在于:子缓冲区使用的接口只需要缓冲区,而无需额外了解偏移值等信息。例如,考虑一个库接口,它设计为需要一个OpenCL缓冲区对象,不过总假设第一个元素偏移量为0。在这种情况下,如果不修改库的源代码,就无法使用前面介绍的方法。子缓冲区则为这个问题提供了一个解决方案。
子缓冲区不能从其他子缓冲区构建3。子缓冲区使用以下函数创建:
cl_mem clCreateSubBuffer(cl_mem buffer,
cl_mem_flags flags,
cl_buffer_create_type buffer_create_type,
const void *buffer_create_info,
cl_int *errcode_ref)
buffer 一个合法的缓冲区对象,不能是之前分配的一个子缓冲区
flags 这是一个位域,用于指定关于缓冲区创建的分配和使用信息。
flags可取的合法值由枚举cl_mem_flags定义。
buffer_create_type 与buffer_create_info结合共同描述所要创建的缓冲区对象的类型
buffer_create_type可取的合法值由枚举cl_buffer_create_type定义
buffer_create_info 与buffer_create_info结合共同描述所要创建的缓冲区对象的类型
errcode_ret 如果为非NULL,函数返回的错误码将由这个参数返回
clCreateSubBuffer支持的名和值
cl_buffer_create_type
CL_BUFFER_CREATE_TYPE_REGION 创建一个缓冲区对象,表示buffer中一个特定的区域
buffer_create_info是以下结构的指针
typedef struct _cl_buffer_region {
size_t origin;
size_t size;
}cl_buffer_region;
CL_BUFFER_CREATE_TYPE_REGION (origin,size)定义了buffer中的偏移量和大小(字节数)
如果使用CL_MEM_USE_HOST_PTR创建buffer,与所返回缓冲区对象关联的host_ptr为host_ptr *origin
返回的缓冲区对象会引用为buffer分配的数据存储库,并指向这个数据存储库中(origin,size)指定的一个特定区域
如果(origin, size)指定的区域超出buffer,errcode_ret返回CL_INVALID_VALUE
如果size为0,errcode_ret返回CL_INVALID_BUFFER_SIZE
对于origin值与CL_DEVICE_MEM_BASE_ADDR_ALIGN值对齐的buffer,
如果与这个buffer关联的上下文中没有设备,errcode_ret返回CL_MISALIGNED_SUB_BUFFER_OFFSET
再来看看前面的例子,下面的代码展示了如何将一个缓冲区划分到多个设备上:
#define NUM_BUFFER_ELEMENTS 100
cl_int errNum;
cl_uint numDevices;
cl_device_id *deviceIDs;
cl_context;
cl_kernel kernel;
std::vector<cl_command_queue> queues;
std::vector<cl_mem> buffers;
float *inputOutput;
cl_mem buffer;
//place code to create context, kernel, and command-queue here
//initialize inputOutput
buffer = clCreate(context,
CL_MEM_READ_WRITE | CL_MEM_COPY_HOST_PTR,
sizeof(float) *NUM_BUFFER_ELEMENTS,
inputOutput,
&errNum);
buffers.push_back(buffer);
//Create command-queues
for(int i = 0; i < numDevices; i++)
{
cl_command_queue queue = clCreateCommandQueue(context,
deviceIDs[i],
0,
&errNum);
queues.push_back(queue);
cl_kernel kernel = clCreateKernel(program,
"square",
&errNum);
errNum = clSetKernelArg(kernel,
0,
sizeof(cl_mem),
(void *)&buffers[i]);
kernels.push_back(kernel);
}
std::vector<cl_event> events;
//call kernel fo each device
for(int i = 0; i < queues.size(); i++)
{
cl_event event;
size_t gWI = NUM_BUFFER_ELEMENTS;
errNum = clEnqueueNDRangeKernel(queues[i],
kernels[i],
1,
NULL,
(const size_t*)&gWI,
(const size_t*)NULL,
0,
0,
&event);
events.push_back(event);
}
//Wait for commands submitted to complete
clWaitForEvents(events.size(), events.data());
与其他OpenCL对象类似,缓冲区和子缓冲区对象也有引用计数,下面两个操作将使引用计数递增和递减。
下面的例子将使一个缓冲区的引用计数递增:
cl_int clRetainMemObject(cl_mem buffer)
buffer 一个合法的缓冲区对象
下面的例子使一个缓冲区的引用计数递减:
cl_int clReleaseMemObject(cl_mem buffer)
buffer 一个合法的缓冲区对象
引用计数为0时,OpenCL实现会释放与这个缓冲区或子缓冲区关联的内存。一旦实现已经释放了一个缓冲区或子缓冲区的资源,程序中就不能再引用这个对象了。
例如,要正确地释放上一个子缓冲区例子中的OpenCL缓冲区资源,可以使用以下代码:
for(int i = 0; i < buffers.size(); i++)
{
buffers.clReleaseMemObject(buffers[i]);
}
查询缓冲区和子缓冲区
与其他OpenCL对象类似,可以查询缓冲区和子缓冲区,返回它们如何构建、当前状态(例如引用计数)等有关信息。可以使用以下命令完成缓冲区和子缓冲区查询:
cl_int clGetMemObjectInfo(cl_mem buffer,
cl_mem_info param_name,
size_t param_value_size,
void *param_value,
size_t *param_value_size_ret)
buffer 要读取的一个合法的缓冲区对象
param_name 这是一个枚举,用来指定要查询的信息。
param_name可取的合法值由枚举cl_mem_info定义
param_value_size param_value指向的内存的字节数。这个大小必须大于或等于返回类型的大小
param_value 这是一个内存指针,所查询的值将由这里返回。如果值为NULL,则忽略这个参数
param_value_size_ret 查询写至param_value的总字节数
OpenCL缓冲区和子缓冲区查询
cl_mem_info
CL_MEM_TYPE cl_mem_object_type 对于缓冲区和子缓冲区,返回CL_MEM_OBJECT_BUFFER
CL_MEM_FLAGS cl_mem_flage 返回缓冲区创建期间指定的flags域值
CL_MEM_SIZE size_t 返回与缓冲区关联的数据存储库的大小(字节数)
CL_MEM_HOST_PTR void* 返回创建缓冲区时指定的host_ptr参数,对于子缓冲区,则返回host_ptr *origin
CL_MEM_MAP_COUNT cl_uint 返回一个整数,表示当前映射缓冲区的次数
CL_MEM_REFERENCE_COUNT cl_uint 返回一个整数,表示缓冲区的当前引用计数
CL_MEM_CONTEXT cl_context 返回创建缓冲区的OpenCL上下文对象
CL_MEM_ASSOCIATED_MEMOBJECT cl_mem 对于一个子缓冲区,则返回创建子缓冲区的缓冲区,否则返回NULL
CL_MEM_OFFSET size_t 对于一个子缓冲区,返回偏移量,否则结果为0
下面的代码给出一个简单的例子,展示了如何查询一个内存对象以确定它是一个缓冲区还是另外某种OpenCL内存对象类型:
cl_int errNum;
cl_mem memory;
cl_mem_object_type type;
//initialize memory object and so on
errNum = clGetMemObjectInfo(memory,
CL_MEM_TYPE,
sizeof(cl_mem_object_type),
&type,
NULL);
switch(type)
{
case CL_MEM_OBJECT_BUFFER:
{
//handle case when object is buffer or sub-buffer
break;
}
case CL_MEM_OBJECT_IMAGE2D:
case CL_MEM_OBJECT_IMAGE3D:
{
//handle case when object is a 2D or 3D image
break;
}
default
//something very bad has happened
break;
}
读、写和复制缓冲区和子缓冲区
缓冲区和子缓冲区可以由宿主机应用程序读、写,将数据移入或移出宿主机内存。下面的命令使一个写命令人队,将宿主机内存中的内容复制到一个缓冲区区域中:
cl_int clEnqueueWriteBuffer(cl_command_queue command_queue,
cl_mem buffer,
cl_bool blocking_write,
size_t offset,
size_t cb,
void *ptr,
cl_uint num_events_in_wait_list,
const cl_event *event_wait_list,
cl_event *event)
command_queue 这是一个命令队列,写命令将在这个队列中排队
buffer 一个合法的缓冲区对象(数据将从这个缓冲区读取)
blocking_write 如果设置为CL_TRUE,则clEnqueueWriteBuffer阻塞,直至从ptr写数据,
否则,直接返回,用户必须查询event来检查命令的状态
offset 缓冲区对象中写数据的起始偏移量(字节数)
cb 从缓冲区读取的字节数
ptr 宿主机内存中的一个指针,指示所写的数据从哪里读取
num_events_in_wait_list 数组event_wait_list中的项数。如果event_wait_list为NULL,这个参数必须为0,否则必须大于0
event_wait_list 如果为非NULL,则event_wait_list是一个事件数组,与必须完成的OpenCL命令关联。
也就是说,在开始执行写命令之前,这些命令必须处于CL_COMPLETE状态
event 如果为非NULL,则函数返回的对应写命令的事件将由这个参数返回
继续完成之前的缓冲区例子,不过并非在缓冲区创建时从宿主机指针复制数据,下面的代码能实现同样的行为:
cl_mem buffer = clCreateBuffer(context,
CL_MEM_READ_WRITE,
sizeof(int)*NUM_BUFFER_ELEMENTS*numDevices,
NULL,
&errNum);
//code to create sub-buffers, command-queues, and so on
//write data to buffer zero using command-queue zero
clEnqueueWriteBuffer(queues[0],
buffers[0],
CL_TRUE,
0,
sizeof(int)*NUM_BUFFER_ELEMENTS*numDevices,
(void*)inputOutput,
0,
NULL,
NULL);
以下命令使一个读命令入队,将一个缓冲区对象中的内容复制到宿主机内存中:
cl_int clEnquueReadBuffer(cl_command_queue command_queue,
cl_mem buffer,
cl_bool blocking_read,
size_t offset,
size_t cb,
void *ptr,
cl_uint num_events_in_wait_list,
const cl_event *event_wait_list,
cl_event *event)
command_queue 这是一个命令队列,读命令将在这个队列中排队
buffer 一个合法的缓冲区对象(数据将从这个缓冲区读取)
blocking_read 如果设置为CL_TRUE,则clEnqueueReadBuffer阻塞,直至数据读入ptr
否则直接返回,用户必须查询event来检查命令的状态
offset 缓冲区对象中读数据的起始偏移地址(字节数)
cb 从缓冲区读取的字节数
ptr 宿主机内存中的一个指针,指示所读的数据写至哪里
num_events_in_wait_list 数组event_wait_lis中的项数。如果event_wait_list为NULL,则这个参数必须为0;否则,必须大于0
event_wait_list 如果为非NULL,则event_wait_list是一个事件数组,与必须完成的OpenCL命令关联。
也就是说,在开始执行读命令之前,这些命令必须处于CL_COMPLETE状态
event 如果为非NULL,则函数返回的对应读命令的事件将由这个参数返回
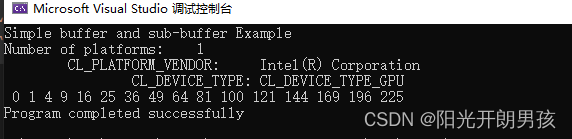
继续考虑缓冲区例子,下面的示例代码将读回并显示运行square内核的结果:
//Read back computed dat
clEnqueueReadBuffer(queues[0],
buffers[0],
CL_TRUE,
0,
sizeof(int)*NUM_BUFFER_ELEMENTS*numDevices,
(void*)inputOutput,
0,
NULL,
NULL);
//Display output in rows
for(unsigned i = 0; i < numDevices; i++)
{
for(unsigned elems = i*NUM_BUFFER_ELEMEMNTS; elems < (i+1)*NUM_BUFFER_ELEMENTS; elems++)
{
std::cout << " " << inputOutput[elems];
}
std::cout << std::endl;
}
创建和读、写缓冲区和子缓冲区示例内核代码
__kernel void square(__global int *buffer)
{
const size_t id = get_global_id(0);
buffer[id] = buffer[id] * buffer[id];
}
创建和读、写缓冲区和子缓冲区示例代码
info.hpp
#ifndef __INFO_HDR__
#define __INFO_HDR__
// info.hpp
// Simple C++ code to abstract clGetInfo*, described in chapter 3.
#if defined(linux) || defined(__APPLE__) || defined(__MACOSX)
# include main.cpp
#include simple.cl
__kernel void square(__global * buffer)
{
size_t id = get_global_id(0);
buffer[id] = buffer[id] * buffer[id];
}
OpenCL 1.1还允许读、写缓冲区中2维或3维的矩形区段。对于从概念上讲,维度至少大于1的数据(OpenCL将所有缓冲区对象都看做这种数据),处理这些数据时这个特性尤其有用。来看一个简单的例子,这里展示了一个2维数组(见图7-1a),以及一个相应的区段,通常称为一个切片(slice),见图7-1b。

区段仅限于缓冲区中连续的内存区域,不过可以有一个行和切片长度,以处理诸如对齐约束等边界情况。对于寻址的宿主机内存和所读、写的缓冲区,这些可能有所不同。
缓冲区中的2维或3维区域可以用以下函数读入宿主机内存:
cl_int clEnqueueReadBufferRect(cl_command_queue command_queue,
cl_mem buffer,
cl_bool blocking_read,
const size_t buffer_origin[3],
const size_t host_origin[3],
const size_t region[3],
size_t buffer_row_pitch,
size_t buffer_slice_pitch,
size_t host_row_pitch,
size_t host_slice_pitch,
void *ptr,
cl_uint num_events_in_wait_list,
const cl_event *event_wait_list,
cl_event *event)
command_queue 这是一个命令队列。读命令将在这个队列中排队。
buffer 一个合法的缓冲区对象(数据将从这个缓冲区读取)。
blocking_read 如果设置为CL_TRUE,则elEnqueueReadBufferRect阻塞,直至数据从buffer读出并写至ptr;
否则直接返画,用户必须查询event来检查命令的状态。
buffer_origin 定义与所读取缓冲区关联的内存区域中的(x, y, z)偏移量。
host_origin 定义ptr指示的内存区域中的(x, y, z)偏移量
region 按字节数定义所读取2维或3维矩形的(度,高度,深度)。
对于一个2维矩形区域,region [2]必须为1。
buffer_row_pitch 按字节数定义所读取2维或3维矩形的(度,高度,深度)。
对于一个2维矩形区域,region[2]必须为1。
buffer_slice_pitch 与buffer关联的内存区域所用的各个2维切片的长度(字节数)。
如果buffer_slice_pitch为0,则buffer_slice_pitch计算为region[1]*buffer_row_pitch
ptr 宿主机内存中的一个指针,指示所读的数据写至哪里。
num_events_in_wait_list 数组event_wait_list中的项数。
如果event_wait_list为NULL,则这个参数必须为0;否则必须大于0。
event_wait_list 如果为非NULL,则event_wait_list是一个事件数组,与必须完成的OpencL命令关联。
也就是说,在开始执行读命令之前,这些命令必须处于CL_COMPLETE状态。
event 如果为非NULL,函数返回的对应读命令的事件将由这个参数返回
clEnqueueReadBufferRect实现计算缓冲区中区域和宿主机内存中区域时要用到一些规则,下面对这些规则做个总结:
1)与缓冲区关联的内存区域中的偏移量按如下方式计算:
buffer_origin[2] * buffer_slice_pitch +
buffer_origin[1] * buffer_row_pitch +
buffer_origin[0]
对于2维矩形区域,buffer_origin[2]必须为0。
2)与宿主机内存关联的内存区域中的偏移量按如下方式计算:
buffer_origin[2] * buffer_slice_pitch +
buffer_origin[1] * buffer_row_pitch +
buffer_origin[0]
对于2维矩形区域,buffer_origin[2]必须为0。
举一个简单的例子,如图7-1所示,下面的代码展示了如何从一个缓冲区读取一个2×2的区域,将它读入宿主机内存,并显示结果:
//
// Book: OpenCL(R) Programming Guide
// Authors: Aaftab Munshi, Benedict Gaster, Timothy Mattson, James Fung, Dan Ginsburg
// ISBN-10: 0-321-74964-2
// ISBN-13: 978-0-321-74964-2
// Publisher: Addison-Wesley Professional
// URLs: http://safari.informit.com/9780132488006/
// http://www.openclprogrammingguide.com
//
// raytracer.cpp
//
// This is a (very) simple raytracer that is intended to demonstrate
// using OpenCL buffers.
#include 将这个代码放在一个完整的程序中,运行这个程序会得到以下输出。
5 6
9 10
可以用以下命令将一个2维或3维缓冲区区域从宿主机内存写入一个缓冲区:
cl_int clEnqueueWriteBufferRect(cl_command_queue command_queue,
cl_mem buffer,
cl_bool blocking_write,
const size_t buffer_origin[3],
const size_t host_origin[3],
const size_t region[3],
size_t buffer_row_pitch,
size_t buffer_slice_pitch,
size_t host_row_pitch,
size_t host_slice_pitch,
void *ptr,
cl_uint num_events_in_wait_list,
const cl_event *event_wait_list,
cl_event *event)
command_queue 这是一个命令队列,写命令将在这个队列中排队
buffer 一个合法的缓冲区对象(数据将从这个缓冲区读取)
blocking_write 如果设置为CL_TRUE,则clEnqueueWrtieBufferRect阻塞,直至数据从ptr写入
否则直接返回,用户必须查询event来检查命令的状态
buffer_origin 定义与所写缓冲区关联的内存区域中的(x,y,z)偏移量
host_origin 定义ptr指示的内存区域中的(x,y,z)偏移量
region 按字节数定义所写2维或3维矩形的(宽度,高度,深度)
buffer_row_pitch 与buffer关联的内存区域所用的各个2维切片的长度(字节数)
buffer_slice_pitch 与buffer关联的内存区域所用的各个2维切片的长度(字节数)
ptr 宿主机内存中的一个指针,指示所写的数据从哪里读取
num_events_in_wait_list 数组event_wait_list中的项数。
如果event_wait_list为NULL,这个参数必须为0;否则必须大于0
event_wait_list 如果为非NULL,则event_wait_list是一个事件数组,与必须完成的OpenCL命令关联
也就是说,在开始执行写命令之前,这些命令必须处于CL_COMPLETE状态
event 如果为非NULL,函数返回的对应写命令的事件将由这个参数返回
经常会遇到这样的情况:应用程序需要在两个缓冲区之间复制数据。OpenCL提供了以下命令来完成这个工作:
cl_int clEnqueueCopyBuffer(cl_command_queue command_queue,
cl_mem src_buffer,
cl_mem dst_buffer,
size_t src_offset,
size_t dst_offset,
size_t cb,
cl_uint num_events_in_wait_list,
const cl_event *event_wait_list,
cl_event *event)
command_queue 这是一个命令队列,写命令将在这个队列中排队
src_buffer 一个合法的缓冲区对象,用做源缓冲区
dst_buffer 一个合法的缓冲区对象,用做目标缓冲区
src_offset 从src_buffer复制数据的起始偏移量
dst_offset 向dst_buffer写入数据的起始偏移量
cb 复制的字节数
num_events_in_wait_list 数组event_wait_list中的项数
如果event_wait_list为NULL,则这个参数必须为0;否则必须大于0
event_wait_list 如果为非NULL,则event_wait_list是一个事件数组,与必须完成的OpenCL命令关联
也就是说,在开始执行写命令之前,这些命令必须处于CL_COMPLETE状态
event 如果为非NULL,函数返回的对应写命令的事件将由这个参数返回
只需将数据读回宿主机,再写入目标缓冲区,就可以很容易地模拟这个功能,不过还是建议应用程序调用clEnqueueCopyBuffer(尽管并不绝对必要),因为这个函数调用允许OpenCL实现管理数据的放置和传输。类似于读、写缓冲区,还可以使用以下命令将缓冲区中一个2维或3维区域复制到另一个缓冲区:
cl_int clEnqueueCopyBufferRect(cl_command_queue commad_queue,
cl_mem src_buffer,
cl_mem dst_buffer,
const size_t src_origin[3],
const size_t dst_origin[3],
const size_t region[3],
size_t src_row_pitch,
size_t src_slice_pitch,
size_t dst_row_pitch,
size_t dst_slice_pitch,
cl_uint num_events_in_wait_list,
const cl_event *event_wait_list,
cl_event *event)
command_queue 这是一个命令队列,读命令将在这个队列中排队
src_buffer 一个合法的缓冲区对象,用做源缓冲区
dst_buffer 一个合法的缓冲区对象,用做目标缓冲区
src_origin 定义与src_buffer关联的内存区域中的(x,y,z)偏移量
dst_origin 定义与dst_buffer关联的内存区域中的(x,y,z)偏移量
region 按字节数定义所读取2维或3维矩形的(宽度,高度,深度)
src_row_pitch 与src_buffer关联的内存区域所用的每行长度(字节数)
src_slice_pitch 与src_buffer关联的内存区域所用的各个2维切片的长度(字节数)
dst_row_pitch 与dst_buffer关联的内存区域所用的每行长度(字节数)
dst_slice_pitch 与dst_buffer关联的内存区域所用的各个2维切片的长度(字节数)
num_events_in_wait_list 数组event_wait_list中的项数
如果event_wait_list为NULL,这个参数必须为0;否则必须大于0
event_wait_list 如果为非NULL,则event_wait_list是一个事件数组,与必须完成的OpenCL命令关联
也就是说,在开始执行复制命令之前,这些命令必须处于CL_COMPLETE状态
event 如果为非NULL,函数返回的对应写命令的事件将由这个参数返回
映射缓冲区和子缓冲区
OpenCL支持将一个缓冲区的一个区域直接映射到宿主机内存,允许使用标准C/C++代码来回复制内存。映射缓冲区和子缓冲区有一个好处,返回的宿主机指针可以传入库和其他函数抽象,这些库和函数抽象可能并不知道所访问的内存实际上由OpenCL管理和使用。下面的函数将一个命令入队,从而将一个特定缓冲区对象的区域映射到宿主机地址空间,并返回这个映射区域的指针:
void *clEnqueueMapBuffer(cl_command_queue command_queue,
cl_mem buffer,
cl_bool blocking_map,
cl_map_flags map_flags,
size_t offset,
size_t cb,
cl_uint num_events_in_wait_list,
const cl_event *event_wait_list,
cl_event *event,
cl_int *errcode_ref)
command_queue 这是一个命令队列,读命令将在这个队列中排队
buffer 一个合法的缓冲区对象(数据将从这个缓冲区读取)
blocking_map 如果设置为CL_TRUE,则clEnqueueMapBuffer阻塞,直到数据映射到宿主机内存
否则,直接返回,用户必须查询event来检查命令的状态
map_flags 这是一个位域,用来指示缓冲区对象中(offset,cb)指定的区域如何映射
map_flags可取的合法值由枚举cl_map_flag定义
offset 缓冲区对象中读取数据的起始偏移量(字节数)
cb 从buffer读取的字节数
num_events_in_wait_list 数组event_wait_list中的项数
如果event_wait_list为NULL,这个参数必须为0;否则,必须大于0
event_wait_list 如果为非NULL,则event_wait_list是一个事件数组,与必须完成的OpenCL命令关联
也就是说,在开始执行读命令之前,这些命令必须处于CL_COMPLETE状态
event 如果为非NULL,函数返回的对应读命令的事件将由这个参数返回
errcode_ret 如果为非NULL,函数返回的错误码将由这个参数返回
cl_map_flags支持的值
cl_map_flags 描述
CL_MAP_READ 映射完成读操作
CL_MAP_WRITE 映射完成写操作
要释放额外的资源,告诉OpenCL运行时不再需要这个缓冲区映射,可以使用以下命令:
cl_in clEnqueueUnmapMemObject(cl_command_queue command_queue,
cl_mem buffer,
void *mapped_pointer,
cl_uint num_events_in_wait_list,
const cl_event *event_wait_list,
cl_event *event)
command_queue 这是一个命令队列,该命令将在这个队列中排队
buffer 之前映射到mapped_pointer的一个合法的缓冲区对象
mapped_pointer 对buffer前一个clEnqueueMapBuffer调用返回的宿主机地址
num_events_in_wait_list 数组event_wait_list中的项数
如果event_wait_list为NULL,这个参数必须为0;否则,必须大于0
event_wait_list 如果为非NULL,则event_wait_list是一个事件数组,与必须完成的openCL命令关联。
也就是说,在开始执行读命令之前,这些命令必须处于CL_COMPLETE状态。
event 如果为非NULL,函数返回的对应读命令的事件将由这个参数返回
下面的代码展示了如何使用clEnqueueMapBuffer和 clEnqueueUnmapMemObject对所处理的缓冲区来回移动数据,而不是使用clEnqueueReadBuffer和 clEnqueuewriteBuffer完成复制。以下代码初始化这个缓冲区:
cl_int * mapPtr = (cl_int*) clEnqueueMapBuffer(
queues[0],
buffers[0],
CL_TRUE,
CL_MAP_WRITE,
0,
sizeof(cl_int) * NUM_BUFFER_ELEMENTS * numDevices,
0,
NULL,
NULL,
&erriNum);
checkErr(errNum, *clEnqueueMapBuffer (..)*);
for (unsigned int i = 0; i < NUM_BUFFER_ELEMENTs *numDevices; i++)
{
mapPtr[i] = inputoutput[i];
}
errNum = clEnqueueUnmapMemObject(
queues[0],
buffers[0],
mapPtr,
0,
NULL,
NULL);
clFinish(queues[0]);
下面的代码读回最终的数据:
cl_int * mapPtr = (cl_int*)clEnqueueMapBuffer(
queues[0],
buffers[0],
CL_TRUE,
CL_MAP_READ,
0,
sizeof(cl_int) *NUM_BUFFER__ELEMENTS * numDevices,
0,
NULL,
NULL,
&errNumy);
checkErr(errum, "clEnqueueMapBuffer(..) ");
for (unsigned int i = 0; i < NUM_BUFFER_ELEMENTS *numDevices; i++)
{
inputoutput [i] = mapPtr[i];
}
errNum =clEnqueueUnmapMemObject(
queues[0],
buffers[0],
mapPtr,
0,
NULL,
NULL);
clFinish(queues[0]);