Ubuntu16.04 单机部署kubeflow1.0.2
Ubuntu16.04 单机部署kubeflow1.0.2
- 开篇
-
- kubeflow的配置要求
- 安装Kubernetes
-
- 1、ubuntu关闭防火墙、selinux、swap
- 2、安装Docker
- 3、安装k8s
- 安装kubeflow
-
- 1、工具和配置文件下载
- 2、编译配置文件
- 3、镜像下载
- 4、有关镜像的修改和配置
- 5、创建PV
- 6、安装
- 7、启动kubeflow ui
- 问题
-
- 1、重启服务器或docker
- 2、无法删除命名空间
- 3、解决kubeflow组件的容器无法访问外网
- 4、使用平台过程中需要额外的PV资源
- 5、如何永久删除pod
- 6、错误:‘too many open files’
- 7、导入Tensorflow: illegal instruction ,崩溃
- 8、不能删除pv,pvc
- 基础知识
-
- 1、k8s集群部分常见问题处理
- 2、istio知识
- 3、容器访问
- 4、制作镜像,Dockerfile文件详解
开篇
服务器系统: Ubuntu16.04
服务器网络信息: 192.168.51.170,可连国内网
软件部署步骤: docker-----Kubernetes----kubeflow
软件版本:Kubernetes 1.15.2、kubeflow 1.0.2
注意:单机部署和集群部署的步骤有所不同
kubeflow的配置要求
Kubernetes集群(可以是单节点集群)必须满足以下最低要求:
集群必须至少包括一个工作节点,并且至少包括:
- 4 CPU
- 50 GB存储
- 12 GB内存
推荐的Kubernetes版本是1.14,Kubernetes 1.14已经过验证和测试。
您的群集必须至少运行1.11版的Kubernetes。
Kubernetes的旧版本可能与最新的Kubeflow版本不兼容。以下矩阵提供了关于kubeflow和Kubernetes版本之间兼容性的信息。
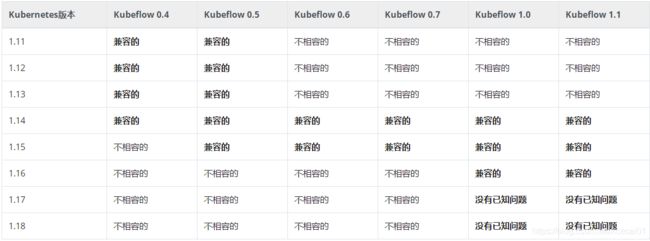
上图表格中关于兼容性的意思是:
- 不相容的:组合无效,会出问题
- 兼容的:k8s的所有功能都已经过kubeflow版本的测试和验证
- 没有已知问题:该组合尚未经过全面测试,但没有报告任何问题,不建议使用
安装Kubernetes
参考博客:
《ubuntu 使用阿里云镜像源快速搭建kubernetes 1.15.2集群》
https://blog.csdn.net/shykevin/article/details/98811021
《Ubuntu 18.04 环境下 kubernetes v1.16.2 单机部署说明》
https://www.cnblogs.com/zhangwenjian/p/11719005.html
1、ubuntu关闭防火墙、selinux、swap
a、防火墙关闭和开启
关闭防火墙
root@xxxx:~# ufw disable
开启防火墙
root@xxxx:~# ufw enable
b、查看和关闭SELinux
查看SELinux状态
root@xxxx:~# getenforce # 查看selinux是否开启,如为enable则开启
Disabled
方式1:临时关闭SELinux(不用重启机器)
root@xxxx:~# setenforce 0 ##设置SELinux 成为permissive模式
##setenforce 1 设置SELinux 成为enforcing模式
方式2:修改配置文件需要重启机器,永久修改
root@xxxx:~# vim /etc/selinux/config
将SELINUX=enforcing改为SELINUX=disabled
重启机器即可,可待下一步骤完成后重启
c、关闭swap
root@xxxx:~# swapoff -a
root@xxxx:~# cp /etc/fstab /etc/fstab_bak
root@xxxx:~# cat /etc/fstab_bak | grep -v swap > /etc/fstab
重启机器
d、修改/etc/sysctl.conf
root@xxxx:~# vim /etc/sysctl.conf # 文件最后面添加如下内容
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
root@xxxx:~# sysctl -p # 使配置生效
2、安装Docker
更新apt源,并添加https支持
root@xxxx:~# apt-get update && sudo apt-get install apt-transport-https ca-certificates root@xxxx:~# curl software-properties-common -y
使用utc源添加GPG Key
root@xxxx:~# curl -fsSL https://mirrors.ustc.edu.cn/docker-ce/linux/ubuntu/gpg | sudo apt-key add
添加Docker-ce稳定版源地址
root@xxxx:~# add-apt-repository "deb [arch=amd64] https://mirrors.ustc.edu.cn/docker-ce/linux/ubuntu $(lsb_release -cs) stable"
安装docker-ce
root@xxxx:~# apt-get update
root@xxxx:~# apt install docker-ce=18.06.1~ce~3-0~ubuntu
3、安装k8s
添加apt key以及源
root@xxxx:~# apt update && sudo apt install -y apt-transport-https curl
root@xxxx:~# curl -s https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | sudo apt-key add -
root@xxxx:~# echo "deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main" >>/etc/apt/sources.list.d/kubernetes.list
安装
root@xxxx:~# apt update
root@xxxx:~# apt install -y kubelet=1.15.2-00 kubeadm=1.15.2-00 kubectl=1.15.2-00
root@xxxx:~# apt-mark hold kubelet=1.15.2-00 kubeadm=1.15.2-00 kubectl=1.15.2-00
安装kubernetes集群(单节点集群)
root@xxxx:~# kubeadm init --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.15.2 --pod-network-cidr=10.244.0.0/16
–image-repository 指定镜像源,指定为阿里云的源,这样就会避免在拉取镜像超时,如果没问题,过几分钟就能看到成功的日志输入
–pod-network-cidr这个子网不能跟本机子网相同,比如本机是192.168.0.0/16,且这个子网要跟后面的网络插件flannel配置相同,flannel将配网段10.244.0.0/16,原由可以参考如下博客:
《搭建Kubernetes集群踩坑日志之coreDNS 组件出现CrashLoopBackOff问题的解决》
https://blog.csdn.net/u011663005/article/details/87937800
《离线使用kubeadm安装kubernetes集群》
https://blog.csdn.net/crazybean_lwb/article/details/107569115
执行以上命令后会输出含以下信息的日志:
…
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown ( i d − u ) : (id -u): (id−u):(id -g) $HOME/.kube/config
注意:出现以下警告信息:[WARNING IsDockerSystemdCheck]: detected “cgroupfs” as the Docker cgroup driver. The recommended driver is “systemd”. Please follow the guide at https://kubernetes.io/docs/setup/cri/
…
忽略以上信息中的警告(二次重启k8s会出问题,后面会说解决方法),并配置docker加速器和dns,以更快下载镜像:
vim /etc/docker/daemon.json
{
"registry-mirrors": ["https://e8fyp85s.mirror.aliyuncs.com"],
"dns": ["8.8.8.8", "114.114.114.114"]
}
要使普通用户能使用k8s,需要切换到普通账户执行以上信息中的命令:
root@xxxx:~# su putong_user
putong_user@xxxx:~# mkdir -p $HOME/.kube
putong_user@xxxx:~# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
putong_user@xxxx:~# sudo chown $(id -u):$(id -g) $HOME/.kube/config
到目前为止,已经可以使用kubectl命令查看k8s的一些组件是否正常了,在进行下一步之前,建议无基础的朋友可以先学习以下知识了解k8s的作用和使用,以对后续遇到的问题进行自主问题定位和处理。
《k8s和Docker关系简单说明》
https://blog.csdn.net/yanghaolong/article/details/86680282
《Kubernetes资源对象Pod、ReplicaSet、Deployment、Service之间的关系》
https://blog.csdn.net/u010606397/article/details/90752262
《k8s核心yml--Pod、Deployment、Service》
https://blog.csdn.net/javaxuexilu/article/details/100738640
《附:Kubectl常用命令(持续更新)》
https://zhuanlan.zhihu.com/p/85810571
安装网络插件,让pod之间通信(选择很多,比如calico、flannel,这里选择flannel)
网络插件知识:
《K8s CNI网络最强对比:Flannel、Calico、Canal和Weave》
https://www.sohu.com/a/304555150_618296
《Flannel配置详解》
http://devops.weiminginfo.com/cloud/docker/1092.html
首先配置KUBECONFIG
putong_user@xxxx:~# sudo echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> /etc/profile
putong_user@xxxx:~# sudo source /etc/profile
putong_user@xxxx:~# echo $KUBECONFIG
重启docker
systemctl restart docker
安装flannel
putong_user@xxxx:~# sudo kubectl apply -f kube-flannel.yml # kube-flannel.yml自行下载
kube-flannel.yml下载网址如下:
链接:https://pan.baidu.com/s/1WOaNkB-FG08LYvbuoTWRmA
提取码:jbe4
之后通过执行以下命令查看k8s的安装情况:
putong_user@xxxx:~# sudo kubectl get pod -n kube-system
会看到kube-flannel和coreDNS两个pod没有正常running,执行以下命令查看flannel日志:
putong_user@xxxx:~# sudo kubectl descirbe pod -n kube-system kube-flannel-xxxxx
可看到缺少/run/flannel/subnet.env文件,flannel配置文件,解决办法参考如下博客:
《open /run/flannel/subnet.env: no such file or directory》
https://blog.csdn.net/ANXIN997483092/article/details/86711006
之后便可看到kube-system的所有pod都运行正常:
root@xxx:~# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-bccdc95cf-6dpjz 1/1 Running 26 21d
coredns-bccdc95cf-bbnbn 1/1 Running 25 21d
etcd-pengrui-s5520hc 1/1 Running 28 26d
kube-apiserver-pengrui-s5520hc 1/1 Running 29 26d
kube-controller-manager-pengrui-s5520hc 1/1 Running 30 26d
kube-flannel-ds-amd64-dvj4b 1/1 Running 16 21d
kube-proxy-zbnwb 1/1 Running 27 26d
kube-scheduler-pengrui-s5520hc 1/1 Running 30 26d
安装kubeflow
参考博客:
《kubeflow0.6.2版本搭建》
https://blog.csdn.net/tilyp/article/details/102547015
《【最新】k8s中kubeflow(v1.0)部署全过程+踩坑全集(图文)》
https://blog.csdn.net/qq_46595591/article/details/107765833
《安装kubeflow》
https://blog.csdn.net/crazybean_lwb/article/details/107570017#comments_13856796
kubeflow大致安装的流程:
1、下载kfctl安装工具(kfctl_v1.0.2-0-ga476281_linux.tar.gz)
2、下载kubeflow部署配置文件(v1.0.2.tar.gz(各组件配置文件)和kfctl_k8s_istio.v1.0.2.yaml(总部署配置文件))
3、用kfctl工具执行以上总部署配置文件,完成kubeflow安装
配置文件被执行时会从网上拉取所需的镜像用于容器部署,其中有可以直接下载的镜像,也有需要到国外仓库获取的镜像,最好是手动先把所有镜像下载到本地,然后修改配置文件的镜像拉取策略,使其首先从本地获取镜像用于容器启动。
1、工具和配置文件下载
从https://github.com/kubeflow/kfctl/releases/下载v1.0.2版本对应的kfctl二进制文件:
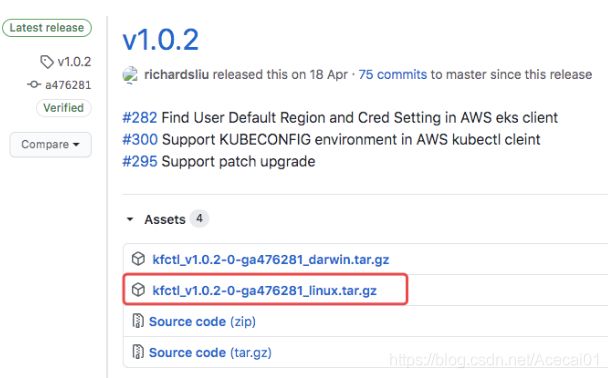
解压安装包并添加到执行路径:
putong_user@xxxx:~# tar -xvf kfctl_v1.0.2-0-ga476281_linux.tar.gz
putong_user@xxxx:~# sudo cp kfctl /usr/bin
下载各组件配置文件压缩包到/root路径:
wget https://github.com/kubeflow/manifests/archive/v1.0.2.tar.gz
从https://github.com/kubeflow/manifests/blob/v1.0-branch/kfdef/kfctl_k8s_istio.v1.0.2.yaml拷贝yaml文件到本地/root路径;
修改yaml文件,将使用manifests文件从远程改为本地:

2、编译配置文件
root@xxxx:~# mkdir /data/my-kubeflow
root@xxxx:~# cd /data/my-kubeflow
root@xxxx:/data/my-kubeflow# kfctl build -V -f "/root/kfctl_k8s_istio.v1.0.2.yaml"
root@xxxx:/data/my-kubeflow# ls
kustomize
该文件夹中含有编译出来的配置文件,各组件的镜像下载源和下载策略都需要在其中的对应文件里面进行修改
3、镜像下载
kubeflow1.0.2涉及到的镜像如下:
# pull istio images
docker pull istio/sidecar_injector:1.1.6
docker pull istio/proxyv2:1.1.6
docker pull istio/proxy_init:1.1.6
docker pull istio/pilot:1.1.6
docker pull istio/mixer:1.1.6
docker pull istio/galley:1.1.6
docker pull istio/citadel:1.1.6
# pull ml-pipeline images
docker pull gcr.io/ml-pipeline/viewer-crd-controller:0.2.5
docker pull gcr.io/ml-pipeline/api-server:0.2.5
docker pull gcr.io/ml-pipeline/frontend:0.2.5
docker pull gcr.io/ml-pipeline/visualization-server:0.2.5
docker pull gcr.io/ml-pipeline/scheduledworkflow:0.2.5
docker pull gcr.io/ml-pipeline/persistenceagent:0.2.5
docker pull gcr.io/ml-pipeline/envoy:metadata-grpc
# pull kubeflow-images-public images
docker pull gcr.io/kubeflow-images-public/profile-controller:v1.0.0-ge50a8531
docker pull gcr.io/kubeflow-images-public/notebook-controller:v1.0.0-gcd65ce25
docker pull gcr.io/kubeflow-images-public/katib/v1alpha3/katib-ui:v0.8.0
docker pull gcr.io/kubeflow-images-public/katib/v1alpha3/katib-controller:v0.8.0
docker pull gcr.io/kubeflow-images-public/katib/v1alpha3/katib-db-manager:v0.8.0
docker pull gcr.io/kubeflow-images-public/jupyter-web-app:v1.0.0-g2bd63238
docker pull gcr.io/kubeflow-images-public/centraldashboard:v1.0.0-g3ec0de71
docker pull gcr.io/kubeflow-images-public/tf_operator:v1.0.0-g92389064
docker pull gcr.io/kubeflow-images-public/pytorch-operator:v1.0.0-g047cf0f
docker pull gcr.io/kubeflow-images-public/kfam:v1.0.0-gf3e09203
docker pull gcr.io/kubeflow-images-public/admission-webhook:v1.0.0-gaf96e4e3
docker pull gcr.io/kubeflow-images-public/metadata:v0.1.11
docker pull gcr.io/kubeflow-images-public/metadata-frontend:v0.1.8
docker pull gcr.io/kubeflow-images-public/kubernetes-sigs/application:1.0-beta
docker pull gcr.io/kubeflow-images-public/ingress-setup:latest
# pull knative-releases images
docker pull gcr.io/knative-releases/knative.dev/serving/cmd/activator:<none>
docker pull gcr.io/knative-releases/knative.dev/serving/cmd/webhook:<none>
docker pull gcr.io/knative-releases/knative.dev/serving/cmd/controller:<none>
docker pull gcr.io/knative-releases/knative.dev/serving/cmd/networking/istio:<none>
docker pull gcr.io/knative-releases/knative.dev/serving/cmd/autoscaler-hpa:<none>
docker pull gcr.io/knative-releases/knative.dev/serving/cmd/autoscaler:<none>
docker pull gcr.io/knative-releases/knative.dev/serving/cmd/queue:<none>
# pull extra images
docker pull gcr.io/kfserving/kfserving-controller:0.2.2
docker pull gcr.io/tfx-oss-public/ml_metadata_store_server:v0.21.1
docker pull gcr.io/spark-operator/spark-operator:v1beta2-1.0.0-2.4.4
docker pull gcr.io/kubebuilder/kube-rbac-proxy:v0.4.0
docker pull gcr.io/google_containers/spartakus-amd64:v1.1.0
# pull argoproj images
docker pull argoproj/workflow-controller:v2.3.0
docker pull argoproj/argoui:v2.3.0
其中的镜像大体分为两类,一类是gcr.io仓库的镜像,一类是非gcr.io仓库的镜像,gcr.io仓库的镜像需要服务器的docker能够访问国外网站进行下载,非gcr.io仓库的镜像直接拉取即可,下面讲述如何拉取gcr.io仓库的镜像。
以gcr.io/ml-pipeline/viewer-crd-controller:0.2.5镜像为例,下载方式为:
方法一、登录阿里云,去阿里镜像中心搜索该镜像名,找到合适的版本下载即可:
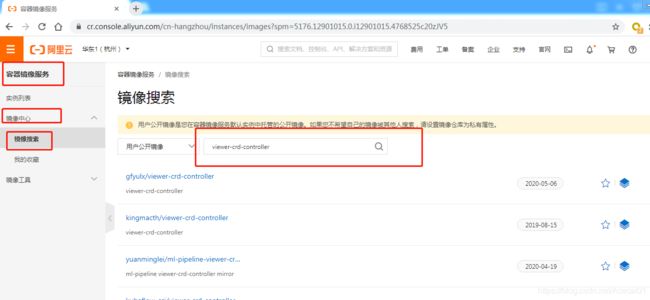
建立阿里云仓库的方法可参考:
https://blog.csdn.net/weixin_46380571/article/details/108460489
方法二、从本人构建的阿里云镜像仓库拉取镜像,拉取方法是:
比如 gcr.io/ml-pipeline/viewer-crd-controller:0.2.5 改成下面的地址:
registry.cn-shenzhen.aliyuncs.com/crl-aliyun/ml-pipeline.viewer-crd-controller:0.2.5
比如 gcr.io/kubeflow-images-public/profile-controller:v1.0.0-ge50a8531 改成:
registry.cn-shenzhen.aliyuncs.com/crl-aliyun/kubeflow-images-public.profile-controller:v1.0.0-ge50a8531
修改规律是:
gcr.io/改成registry.cn-shenzhen.aliyuncs.com/crl-aliyun/,后面ml-pipeline/viewer-crd-controller:0.2.5中的‘/’改成‘.’即可
对于阿里仓库而言,registry.cn-shenzhen.aliyuncs.com/crl-aliyun是命名空间,ml-pipeline.viewer-crd-controller是一个仓库,里面可以放很多个ml-pipeline.viewer-crd-controller的版本。
下载镜像:
root@xxxx:~# docker pull registry.cn-shenzhen.aliyuncs.com/crl-aliyun/ml-pipeline.viewer-crd-controller:0.2.5
上面关于knative-releases的几个特殊镜像没有版本号,如下:
gcr.io/knative-releases/knative.dev/serving/cmd/activator:
去上一节编译出的/data/my-kubeflow/kustomize/文件夹下,查看文件knative-install/base/kustomization.yaml可知所需版本为v0.11.0,不过本人未找到该版本的镜像,用0.9.0替代了,下载方式如下:
docker pull jimmysong/knative-serving-cmd-activator:0.9
docker pull jimmysong/knative-serving-cmd-webhook:0.9
docker pull jimmysong/knative-serving-cmd-controller:0.9
docker pull jimmysong/knative-serving-cmd-networking-istio:0.9
docker pull jimmysong/knative-serving-cmd-autoscaler-hpa:0.9
docker pull jimmysong/knative-serving-cmd-autoscaler:0.9
docker pull jimmysong/knative-serving-cmd-queue:0.9
这knative-releases相关镜像除了得修改tag名,还得修改配置文件,后面会讲述。
4、有关镜像的修改和配置
镜像下载之后,查看镜像:
root@xxxx:~# docker images | grep viewer-crd-controller
registry.cn-shenzhen.aliyuncs.com/crl-aliyun/ml-pipeline.viewer-crd-controller 0.2.5 f9292373a0d3 4 months ago 114MB
可以看到以上镜像tag还是阿里的,这里需要改tag,因为kubeflow配置文件中涉及的镜像拉取地址是gcr.io/仓库,意味着用配置文件部署平台时,会去gcr.io/仓库拉镜像,显然不能让它这么干,本地已经有镜像了,就让其在本地拿镜像,在不修改配置文件中镜像地址的前提下(配置文件太多,不可能一个个去修改镜像拉取的地址为阿里的仓库),修改本地镜像的tag,改成gcr.io/前缀的即可;另外配置文件的镜像拉取策略大多是always,意味着每次执行配置文件都会去gcr.io/仓库拉镜像,就算本地已经有了gcr.io/的镜像也不会用,所以这个镜像拉取策略也得改;上一节中最后的特殊镜像类knative-releases由于未下载到配置文件中的要求的版本,所以需要把相应配置文件中的镜像版本号改一下;于是需要进行三大步操作,下面一一讲述。
1、修改已下载镜像的tag,同样以viewer-crd-controller镜像作为例子:
root@xxxx:~# docker tag registry.cn-shenzhen.aliyuncs.com/crl-aliyun/ml-pipeline.viewer-crd-controller:0.2.5 gcr.io/ml-pipeline/viewer-crd-controller:0.2.5
经过这个步骤会把这个镜像新增一个名字gcr.io/ml-pipeline/viewer-crd-controller:0.2.5(相当于取了个别名,镜像的id是一样的,只是有两不同tag),此时如果执行‘docker images |grep viewer-crd-controller’可以看到同image id的两个不同tag。
然后删除原先的那个镜像tag:
root@xxxx:~# docker rmi registry.cn-shenzhen.aliyuncs.com/crl-aliyun/ml-pipeline.viewer-crd-controller:0.2.5
经过这一步就成功把本地阿里的镜像换成了gcr.io的镜像
再次执行如下命令:
root@pengrui-S5520HC:/home/pengrui# docker images |grep viewer-crd-controller
gcr.io/ml-pipeline/viewer-crd-controller 0.2.5 f9292373a0d3 4 months ago 114MB
可以看到镜像tag换成了gcr.io的
所有指明gcr.io仓库的镜像都要这么改,可以手动根据以上几步操作修改,也可以自己写shell脚本修改。
2、修改配置文件的镜像拉取策略:
/data/my-kubeflow/kustomize/文件夹下有繁多的配置文件,要把配置文件中如下图左边字段值改成右边字段的值,即镜像拉取策略由Always改成IfNotPresent,要实现这个操作可以写python代码遍历其中所有的配置文件,进行如下图的修改,保证容器部署时能够在本地取镜像,而非去网络拉取镜像。

不想写Python代码的,可以把/data/my-kubeflow/kustomize/文件夹拷贝到windows系统,用工具everything从文件夹中搜索包含‘imagepull’字段的文件,如下图,手工一一打开搜索出来的文件进行修改。

3、knative-releases相关的配置文件修改:
把/data/my-kubeflow/kustomize/文件夹拷贝到windows系统,用工具everything从文件夹中搜索包含‘gcr.io/knative-releases’字段的文件,如下图所示:
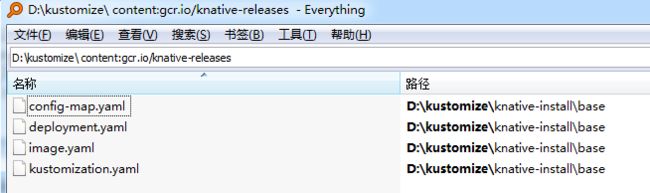
打开以上四个文件,把所有v0.11.0的字眼全部改成v0.9.0,把镜像地址也改成如下图样式:

其中kustomization.yaml的修改如下,所有项都这么修改:

以上操作都完成后,可开始进行下一步操作。
5、创建PV
参考博客:
《PersistentVolumeClaim》
https://blog.csdn.net/bbwangj/article/details/82355337
《Kubernetes-持久化存储卷PersistentVolume》
https://blog.csdn.net/huwh_/article/details/96016049
PV是存储资源(可供容器挂载使用),kubeflow有4个组件需要用到PV资源,分别是katib-mysql、metadata-mysql、minio、mysql,这4个组件在安装时会发出PVC请求,寻找满足条件的PV资源,用于存储数据。
PV分为静态和动态分配,在明确知道有多少组件需要存储资源情况下,比如上面讲的4个组件,katib-mysql和metadata-mysql各需要10G的PV,minio和mysql各需要20G的PV,那么可以创建4个满足条件的静态PV,以供使用。而如果不知道需要多少PV资源,可以创建动态分配PV的机制,来一个PVC请求,就按请求分配一个PV。
动态创建PV的方法可参考如下博客:
《基于国内阿里云镜像解决kubeflow一键安装》
https://www.liangzl.com/get-article-detail-160195.html
《Kubernetes 安装 local-path-storage》
https://blog.csdn.net/shida_csdn/article/details/109276162
创建kubeflow所需4个静态pv资源的方法可参考如下博客:
https://blog.csdn.net/tilyp/article/details/102547015
本教程选择创建静态PV供kubeflow组件使用,编写kubeflow-pv1.yaml,kubeflow-pv2.yaml,kubeflow-pv3.yaml,kubeflow-pv4.yaml用于创建4个PV资源,4个yaml文件的内容如下,存储大小修改下面storage字段即可,这里统一创建20G的PV,path字段修改成自己服务器的硬盘目录即可(挑一个大点的硬盘)
apiVersion: v1
kind: PersistentVolume
metadata:
name: kubeflow-pv1
spec:
capacity:
storage: 20Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/data1/kubeflow-pv1"
分别执行以上4个配置文件:
root@xxxx:~# kubectl apply -f kubeflow-pv1.yaml
root@xxxx:~# kubectl apply -f kubeflow-pv2.yaml
root@xxxx:~# kubectl apply -f kubeflow-pv3.yaml
root@xxxx:~# kubectl apply -f kubeflow-pv4.yaml
# 查看创建的PV
root@xxxx:~ kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS ...... AGE
kubeflow-pv1 20Gi RWO Retain Available ...... 21d
kubeflow-pv2 20Gi RWO Retain Available ...... 21d
kubeflow-pv3 20Gi RWO Retain Available ...... 21d
kubeflow-pv4 20Gi RWO Retain Available ...... 21d
以上4个PV的STATUS都是Available,接下来安装kubeflow时会被绑定到相应的组件中
6、安装
执行以下命令等待安装:
root@xxxx:~# cd /data/my-kubeflow
root@xxxx:/data/my-kubeflow# kfctl apply -V -f "/root/kfctl_k8s_istio.v1.0.2.yaml"
如果显示如需下图的警告,则继续等待:
![]()
如果显示报错,是由于cert-manager和istio-system镜像安装需要时间,等待一段时间重新执行 kfctl apply -V -f ${CONFIG_FILE}
正常输出完日志即表示镜像安装完成,接下来等待pod安装完毕即可。
如果kubeflow的pod出现下图中的running状态即表示kubeflow安装完成:
root@xxxx:~# kubectl get pod -n kubeflow
NAME READY STATUS RESTARTS AGE
admission-webhook-bootstrap-stateful-set-0 1/1 Running 20 21d
admission-webhook-deployment-569558c8b6-xxsq7 1/1 Running 0 14d
application-controller-stateful-set-0 1/1 Running 0 37h
argo-ui-7ffb9b6577-xd6j9 1/1 Running 16 21d
centraldashboard-659bd78c-n8v58 1/1 Running 16 21d
jupyter-web-app-deployment-878f9c988-2nmwl 1/1 Running 16 21d
katib-controller-7f58569f7d-kt2nn 1/1 Running 24 21d
katib-db-manager-54b66f9f9d-s544w 1/1 Running 220 21d
katib-mysql-dcf7dcbd5-c2rnj 1/1 Running 16 21d
katib-ui-6f97756598-52sbt 1/1 Running 16 21d
kfserving-controller-manager-0 2/2 Running 41 21d
metacontroller-0 1/1 Running 16 21d
metadata-db-65fb5b695d-d7mfg 1/1 Running 17 21d
metadata-deployment-65ccddfd4c-4h5sr 1/1 Running 63 21d
metadata-envoy-deployment-7754f56bff-ggljk 1/1 Running 16 21d
metadata-grpc-deployment-5c6db9749-v5kw5 1/1 Running 216 21d
metadata-ui-7c85545947-h9zh9 1/1 Running 16 21d
minio-6b67f98977-6ml9j 1/1 Running 16 21d
ml-pipeline-6cf777c7bc-flmc6 1/1 Running 145 21d
ml-pipeline-ml-pipeline-visualizationserver-6d744dd449-7bn44 1/1 Running 4 16d
ml-pipeline-persistenceagent-5c549847fd-q4r5k 1/1 Running 163 21d
ml-pipeline-scheduledworkflow-674777d89c-6kwf8 1/1 Running 16 21d
ml-pipeline-ui-549b5b6744-cnlmq 1/1 Running 16 21d
ml-pipeline-viewer-controller-deployment-fc96b4795-7sg9d 1/1 Running 25 21d
mysql-85bc64f5c4-nfj98 1/1 Running 16 21d
notebook-controller-deployment-7db7c8589d-7zdsh 1/1 Running 23 21d
profiles-deployment-56b7c6788f-q4pjl 2/2 Running 39 21d
pytorch-operator-cf8c5c497-rc5rw 1/1 Running 23 21d
seldon-controller-manager-6b4b969447-8drmz 1/1 Running 35 21d
spark-operatorsparkoperator-76dd5f5688-sksr5 1/1 Running 16 21d
spartakus-volunteer-5dc96f4447-vf7qh 1/1 Running 16 21d
tensorboard-6c8c7d4698-8m2vw 1/1 Running 4 15d
tf-job-operator-5fb85c5fb7-wsv76 1/1 Running 22 21d
workflow-controller-689d6c8846-q2q7k 1/1 Running 25 21d
如果有一些pod还在安装则耐心等待即可
7、启动kubeflow ui
如果以上部分正常走完,接下来使用k8s端口转发启动ui即可:
# 端口转发
root@xxxx:~# nohup kubectl port-forward -n istio-system svc/istio-ingressgateway 8088:80 --address=0.0.0.0 &
接下来去访问你的ui即可: http://hostip:8088
问题
1、重启服务器或docker
问题1,如果/etc/docker/daemon.json添加配置:
"exec-opts": ["native.cgroupdriver=systemd"]
导致k8s重新启动不了,不要这么配置,原因如下:
https://blog.csdn.net/qq_41054648/article/details/102637301
问题2,重启容器后,kubectl命令用不了,发生以下错误:
The connection to the server 192.168.51.170:6443 was refused - did you specify the right host or port?
a、首先确认K8S服务是否启动
root@xxxx:~# systemctl status kubelet
b、看到k8s是启动的,可能是存储空间不足,本人删除根目录无用东西,以及一些无用的镜像后,重启docker,k8s正常了
问题3,重启服务器后,k8s和kubeflow都不正常:
原因可能是交换区、防火墙和selinux可能因为重启又开了,需要配置永久关闭后重启服务器
问题4,重启服务器或docker导致各种问题,找不到头绪,那么可以删除kubeflow和重新初始化k8s:
kubeadm reset操作步骤
root@xxxx:~# kubeadm reset
之后重新回到上面–安装Kubernetes–>3、安装k8s–>安装kubernetes集群(单节点集群)–kubeadm init…开始一步步执行
2、无法删除命名空间
想重装kubeflow,需要删除istio-system和kubeflow命名空间,
参考如下博客最后面一小节,删除istio-system:
《使用 Helm Chart 部署及卸载 istio》
https://www.jianshu.com/p/9fa9759bf6bb
直接删除kubeflow:
root@xxxx:~# kubectl delete ns kubeflow
可能发现删除不掉的情况,namespace一直处于Terminating状态,参考如下博客彻底删除:
《k8s问题【删除namespace一直处于Terminating状态】》
https://blog.csdn.net/wzy_168/article/details/103734269
3、解决kubeflow组件的容器无法访问外网
参考博客
《搭建Kubernetes集群时DNS无法解析问题的处理过程》
https://www.jianshu.com/p/590a8dfdf9a9
《Flannel配置详解》
http://devops.weiminginfo.com/cloud/docker/1092.html
《Docker修改/etc/default/docker里的DOCKER_OPTS参数不生效问题解决》
https://blog.csdn.net/skh2015java/article/details/82466485
《Jupyter notebook中的sudo问题详解》
https://www.shangmayuan.com/a/f6667809c1a14364ab4aded4.html
《Linux BOND接口配置》
https://blog.csdn.net/sinat_20184565/article/details/81318503
问题复原步骤:
# 查看pod名
root@xxxx:~# kubectl get pod -n kubeflow
NAME READY STATUS RESTARTS AGE
...
ml-pipeline-ml-pipeline-visualizationserver-6d744dd449-7bn44 1/1 Running 4 16d
...
# 查看以上pod中包含哪些镜像:
root@xxxx:~# kubectl describe pod ml-pipeline-ml-pipeline-visualizationserver-6d744dd449-7bn44 -n kubeflow | grep Image
Image: gcr.io/ml-pipeline/visualization-server:0.2.5
Image ID: docker://sha256:9331771ab6cca733dadaf309b2c9789e9faffe620025939a9d42d3d6e5b46832
# 查询包含以上镜像名的id
root@xxxx:~# docker images | grep gcr.io/ml-pipeline/visualization-server
gcr.io/ml-pipeline/visualization-server 0.2.5 9331771ab6cc 4 months ago 3.84GB
# 查询包含以上镜像id的运行容器
root@xxxx:~# docker ps | grep 9331771ab6cc
c626daaf7ab5 9331771ab6cc "python3 server.py" 2 weeks ago Up 13 days k8s_ml-pipeline-visualizationserver_ml-pipeline-ml-pipeline-visualizationserver-6d744dd449-7bn44_kubeflow_90b2da27-10b3-4df3-a234-71a1ebb83f99_4
# 进入以上容器:
root@xxxx:~# docker exec -u 0 -it c626daaf7ab5 /bin/bash
...
# 进容器后可以用ping命令,得知无法ping通服务器物理ip
...
解决办法:
root@xxxx:~# cat /run/flannel/subnet.env
FLANNEL_NETWORK=10.244.0.0/16
FLANNEL_SUBNET=10.244.0.1/24
FLANNEL_MTU=1450
FLANNEL_IPMASQ=true
root@xxxx:~# vim /etc/default/docker
#DOCKER_OPTS="--dns 8.8.8.8 --dns 8.8.4.4"
DOCKER_OPTS=" --bip=10.244.0.1/24 --mtu=1450"
以上两个参数的值必须与 /run/flannel/subnet.env 中 FLANNEL_SUBNET 和FLANNEL_MTU一致
root@xxxx:~# vim /lib/systemd/system/docker.service
#ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock
EnvironmentFile=/etc/default/docker
ExecStart=/usr/bin/dockerd $DOCKER_OPTS -H fd://
#重启docker:
root@xxxx:~# systemctl daemon-reload
root@xxxx:~# systemctl restart docker
在物理服务器查看docker0的网卡信息,ifconfig,看到docker0的ip已和cni0重复了,貌似有点问题,但是解决了kubeflow相关的容器不能上网的问题。
新的问题是,docker run -it busybox启动的容器不能连主机网卡和外网了,即默认用网桥brige模式启动的容器无法连外网,这导致在用dockerfile做镜像时无法下载连接
但是‘docker run --network=host -it busybox ’可以连外网,即用host模式启动的容器却可以连外网。意味着制作镜像时,‘docker build --network=host …’ , 也需要加–network=host才能联网下载基础镜像。
原因是不是docker0的ip已和cni0重复?这个问题如何解决?
4、使用平台过程中需要额外的PV资源
后续在kubeflow平台使用过程中,还会涉及到很多需要PV的地方,参考以下教程创建动态分配PV机制:
https://github.com/shikanon/kubeflow-manifests
下载以上地址的代码,执行如下步骤:
root@xxxx:~ cd kubeflow-manifests/local-path
root@xxxx:~ kubectl apply -f local-path-storage.yaml
根据以上步骤创建动态PV,需要保证根目录有足够的空间。
5、如何永久删除pod
参考一下博客:
https://blog.csdn.net/chen_haoren/article/details/108579445
6、错误:‘too many open files’
参考以下博客:
https://www.cnblogs.com/caidingyu/archive/2019/02/26/10436560.html
设置sysctl fs.inotify.max_user_instances=2048
7、导入Tensorflow: illegal instruction ,崩溃
参考博客:
https://www.jianshu.com/p/f85544b0deb9
8、不能删除pv,pvc
《k8s不能删除pv,pvc》
https://www.cnblogs.com/wangxu01/articles/11684063.html
基础知识
1、k8s集群部分常见问题处理
《k8s集群部分常见问题处理》
https://www.cnblogs.com/sandshell/p/11752539.html
2、istio知识
《istio架构及各个组件介绍》
https://www.cnblogs.com/itanony/p/11976340.html
《Istio从懵圈到熟练 – 二分之一活的微服务》
https://segmentfault.com/a/1190000020301822
《istio 数据面调试指南》
https://cloud.tencent.com/developer/article/1581954
3、容器访问
《Jupyter notebook中的sudo问题详解》
https://www.shangmayuan.com/a/f6667809c1a14364ab4aded4.html
4、制作镜像,Dockerfile文件详解
《Dockerfile文件详解》
https://www.cnblogs.com/panwenbin-logs/p/8007348.html