9Django-----------Django框架------------安装使用、基本介绍
Django框架
- 一、Django框架介绍
- 二、Django框架搭建
-
- (一)环境搭建
- (二)项目实例
- 三、项⽬结构介绍
-
- (一)URL与视图
-
-
- 1)视图的定义
- 2)路由的定义
- 3)URL模块化
- 4)URL添加参数
- 5)url命名
-
- (二)模板
-
-
- 1)if标签
- 2)for...in...标签
- 3)a标签
-
- (三)数据库
-
-
- 1)Django配置连接数据库
- 2)创建ORM模型
- 3)映射模型到数据库中
- 4)ORM的增删改查
- 5)F表达式和Q表达式----优化ORM
- 6)QuerySet的⽅法
- 7)ORM模型迁移
-
- (四)⾼级视图
-
-
- 1)请求方式
- 2)⻚⾯重定向
- 3)HttpRequest对象
- 4)返回对象
- 5)类视图
-
- (五)错误处理
- (六)表单
-
-
- 1)⽤表单验证数据
- 2)ModelForm
- 3)⽂件上传
-
- (七)cookie和session
-
-
- 1)操作cookie
- 2)操作session
-
- (八)上下⽂处理器
- 四、Django报错
-
- (一)编码解码错误
- (二)migrate迁移错误
一、Django框架介绍
- django框架是一个web框架, 而且是一个后端框架程序, 它不是服务器, 需要注意
- django框架帮我们封装了很多的组件, 帮助我们实现各种功能, 具有很强的扩展性.
- Django适用大项目更好。flask小项目,轻便
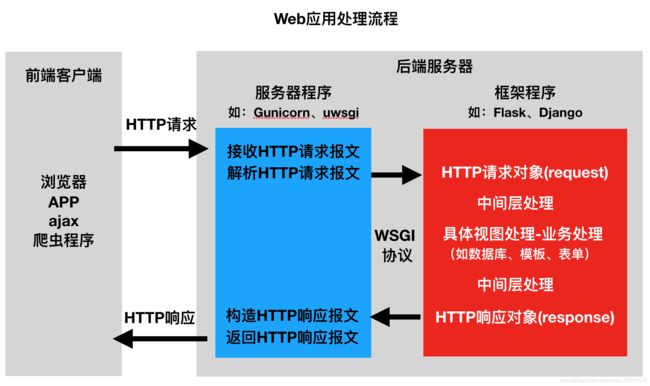
工作流程
- Django设计模式MVT。Django也遵循MVC思想,但是有⾃⼰的⼀个名词,叫做MVT
- Django的接收、返回请求的生命周期,MVT是其中的一部分
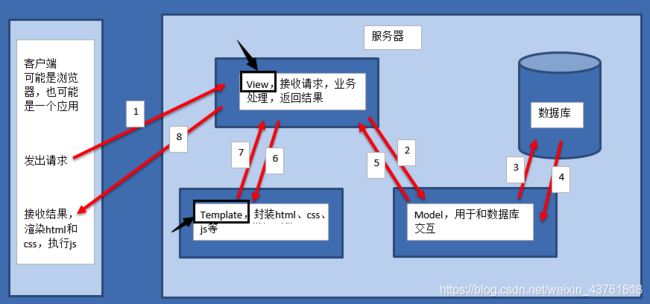
- M全拼为Model,数据库交互的,并向回馈反映给View,负责和数据库交互,进行数据处理。用于封装与应用程序的业务逻辑相关的数据及对数据的处理方法,是Web应用程序中用于处理应用程序的数据逻辑的部分,Model只提供功能性的接口,通过这些接口可以获取Model的所有功能。白话说,这个模块就是Web框架和数据库的交互层。
- V全拼为View,用View接受请求 ,接收请求,进行业务处理,返回应答。将数据与HTML语言结合起来的引擎
- T全拼为Template,Templates把View数据渲染出来,负责封装构造要返回的html。负责实际的业务逻辑实现
Django开发原则
- 快速开发和DRY原则。Do not repeat yourself.不要⾃⼰去重复⼀些⼯作。
官⽹⼿册介绍
- Django的官⽹:https://www.djangoproject.com/
- Django Book2.0版本的中⽂⽂档:http://djangobook.py3k.cn/2.0/chapter0 1/
二、Django框架搭建
(一)环境搭建
步骤
- 1.创建一个文件夹作为项目文件夹
- 2.系统环境变量的设置:WORKON_HOME
- 3. cmd进入你的项目文件夹,下载pipenv
- 4.pipenv shell 生成你的虚拟环境
- 5.下载django 2.2的版本,pip install Django==2.2
- 6.pycharm里面配置生成的虚拟环境
为什么需要虚拟环境
- 到目前为止,我们所有的第三方包安装都是直接通过 pip install xxx 的方式进行安装的,这样安装会将那个包安装到你的系统级的 Python环境中。但是这样有一个问题,就是如果你现在用 Django 1.10.x 写了个网站,然后你的领导跟你说,之前有一个旧项目是用 Django 0.9 开发的,让你来维护,但是 Django 1.10 不再兼容 Django 0.9 的一些语法了。这时候就会碰到一个问题,我如何在我的电脑中同时拥有 Django 1.10 和 Django 0.9 两套环境呢?这时候我们就可以通过虚拟环境来解决这个问题。
(二)项目实例
1.创建项目
- 方法一:.cmd通用
- django-admin startproject 项目名
- 方法二:.专业版pycharm
- create project里面直接选择
- create project里面直接选择
2.运行项目—manage.py入口文件,启动
- 运行项目两种方法
- 方法一:终端运行
- python manage.py runserver 端口号(可以不加,默认端⼝号是8000)
- 方法二:直接运行manage.py文件
- 将manage.py文件的在edit configurations中设置parameters ----设置为runserver,直接运行文件就可以启动文件
- 不添加参数,直接运行会显示manage.py help的帮助文档,并不会运行项目,python manage.py help也可以查看帮助文档
- 方法一:终端运行
- 说明:
- 只要生成了项目文件,就可以运行了,这样可以在本地访问你的⽹站,默认端⼝号是8000,这样就可以在浏览器中通过打开浏览器访问 http://127.0.0.1:8000/
- runserver是固定的,flask可以自定义启动命令
3.迁移数据库—manage.py迁移
- 方法
- python manage.py migrate ----迁移数据库
- 为什么没有启动数据库,但却可以执行迁移?
- Django默认使用sqlite3(settings中设置的)—小,简单,追求磁盘运行效率,mysql是高并发功能多的,单机话使用sqlite3还是不错的
- 如果换成mysql还是要启动的
- 迁移: 将模型迁移到数据库中
三、项⽬结构介绍
项目文件夹结构
├── 项目名
│ ├── __init__.py
│ ├── settings.py (项目配置文件)
│ ├── urls.py (项目路由)
│ └── wsgi.py (python网关)
├── manage.py (脚手架)
├── db.sqlite3 (数据库)
└── templates (模板目录)
manage.py:
- 以后和项⽬交互基本上都是基于这个⽂件。⼀般都是在终端输⼊ python manage.py [⼦命令]。可以输⼊python manage.py help看下能做什 么事情。除⾮你知道你⾃⼰在做什么,⼀般情况下不应该编辑这个⽂件。
settings.py:
- 本项⽬的设置项,以后所有和项⽬相关的配置都是放在这个⾥ ⾯。
urls.py:
- 这个⽂件是⽤来配置URL路由的。⽐如访问http://127.0.0.1/news/ 是访问新闻列表⻚,这些东⻄就需要在这个⽂件中完成。
wsgi.py:
- 项⽬与WSGI协议兼容的web服务器⼊⼝,部署的时候需要⽤到的, ⼀般情况下也是不需要修改的。
app应用文件夹
project和app的关系- app是django项⽬的组成部分。⼀个app代表项⽬中的⼀个模块,所有URL请求 的响应都是由app来处理。⽐如⾖瓣,⾥⾯有图书,电影,⾳乐,同城等许许多多的模块,如果站在django的⻆度来看,图书,电影这些模块就是app,图 书,电影这些app共同组成⾖瓣这个项⽬。因此这⾥要有⼀个概念,django项⽬由许多app组成,⼀个app可以被⽤到其他项⽬,django也能拥有不同的 app
- 一个app实现某个功能或者模块,比如用户模块,订单模块;
一个project是配置文件和多个app的集合,这些app组合成整个站点;
一个project可以包含多个app; - 为什么创建app:就是为了将不同功能的代码分开,分成一个个的文件来管理
好管理,开发比较方便 好维护
创建app- cmd下运行:python manage.py startapp [app名称]
app中的⽂件:__init__.py 说明⽬录是⼀个Python模块 ,作用:在这里做声明 models.py 写和数据库相关的内容 views.py 写视图函数。接收请求,处理数据 与M和T进⾏交互 tests.py 写测试用例。写测试代码的⽂件(暂时不需要关⼼) admin.py 后台管理有关。⽹站后台管理相关的应⽤注册- 建⽴应⽤和项⽬之间的联系,需要对应⽤进⾏注册。
- 修改settings.py中的INSTALLED_APPS配置项
DEBUG模式
- 默认开启了debug模式,那么修改代码,然后按下ctrl+s,那么Django会⾃动重启项⽬。
Django项⽬中代码出现了问题,在浏览器中和控制台中会打印错误信息 - 如果项⽬上线了,关闭debug模式,不然有很⼤的安全隐患,关闭DEBUG模式,在setting⽂件中,将DEBUG = False
(一)URL与视图
- 数据表创建好了,现在需要我们的页面了,Django如何载入页面呢?
- 在view.py文件下就可以创建咱们的视图逻辑了
- 这里咱们使用类的方式来写,当然也可以用函数的方式来写 这里我更推荐使用类的方式.
- 用户访问浏览器,一般两种方式,get获取网页和post提交数据,get也可以提交数据,以一种明文形式显示在url中,post提交的数据url中不显示,一种安全的数据提交方式,get方式提交数据一般应用于一些排序方式和类别过滤中,post用于用户提交的表单数据,比较隐私的数据,get方式提交数据为小数据信息,而post方式提交数据可以是大数据信息
- 由于django会有CSRF验证所以我们在提交表单的时候要构建一个csrf的token,这里django提供了方法让我们直接构建出一条token
1)视图的定义
- 视图⼀般都写在app的views.py中。
- 特点:
- 第⼀个参数必须是
request对象- (⼀个HttpRequest)这个对象存储了请求过来的所有信息,包 括携带的参数以及⼀些头部信息等
- 在视图中,⼀般是完成逻辑相关的操作。 ⽐如这个请求是添加⼀篇博客,那么可以通过request来接收到这些数据,然后存储到数据库中,最后再把执⾏的结果返回给浏览器
- return返回结果必须是
HttpResponseBase对象或者⼦类的对象。-----定义应用news/views.py----- from django.http import HttpResponse def news(request): return HttpResponse("新闻!") -----注册应用urls.py------ from news import views urlpatterns = [ path("news",views.news) ]
- 第⼀个参数必须是
2)路由的定义
URL映射
作用:- 视图写完后,要与URL进⾏映射,也即⽤户在浏览器中输⼊什么url的时候可以请求到这个视图函数。在⽤户输⼊了某个url,请求到我们的⽹站的时候, django会从项⽬的urls.py⽂件中寻找对应的视图。在urls.py⽂件中有⼀个 urlpatterns变量,以后django就会从这个变量中读取所有的匹配规则。匹配规 则需要使⽤django.urls.path函数进⾏包裹,这个函数会根据传⼊的参数返回 URLPattern或者是URLResolver的对象。
- 实现绑定视图函数
实现:django.urls.path-----urls.py------ from django.contrib import admin from django.urls import path from book import views urlpatterns = [ path('admin/', admin.site.urls), path('book/',views.book_list) ]re_path函数:有时候我们在写url匹配的时候,想要写使⽤正则表达式来实现⼀些复杂的需 求,那么这时候我们可以使⽤re_path来实现。re_path的参数和path参数⼀模 ⼀样,只不过第⼀个参数也就是route参数可以为⼀个正则表达式。- route参数
- $表示结束匹配
- ()给分组。
- 固定写法?P<变量> 给分区取名:(?P\d{4})
- route参数
3)URL模块化
模块化原因:- 因为当有多个app的时候,每个都对应一个view,在总urls每个导入就必须重命名,会很麻烦,所以需要模块化,把每个app新建一个urls文件,把路由放到里面,然后在总的urls导入这个app文件夹就行
- URL中包含另外⼀个urls模块:在我们的项⽬中,不可能只有⼀个app,如果把所有的app的views中的视图都 放在urls.py中进⾏映射,肯定会让代码显得⾮常乱。因此django给我们提供了 ⼀个⽅法,可以在app内部包含⾃⼰的url匹配规则,⽽在项⽬的urls.py中再统 ⼀包含这个app的urls。使⽤这个技术需要借助include函数。
实现方法:include------urls.py⽂件-------- from django.contrib import admin from django.urls import path,include urlpatterns = [ path('admin/', admin.site.urls), path('book/',include("book.urls")) ##以后在请求book的app相关的url的时候都需要加⼀个book的前缀。 ##这里的路由与app的路由拼接,最后形成最终的url ] ------book/urls.py⽂件-------- from django.urls import path from . import views urlpatterns = [ path('', views.index), path('sign/', views.login) ]
4)URL添加参数
作用:- 有时候,url中包含了⼀些参数需要动态调整。⽐如简书某篇⽂章的详情⻚的 url,是https://www.jianshu.com/p/a5aab9c4978e后⾯的a5aab9c4978e 就是这篇⽂章的id,那么简书的⽂章详情⻚⾯的url就可以写成 https://www.jianshu.com/p/,其中id就是⽂章的id。那么如何在django中实 现这种需求呢。这时候我们可以在path函数中,使⽤尖括号的形式来定义⼀个 参数。⽐如我现在想要获取⼀本书籍的详细信息,那么应该在url中指定这个参数。
特点:- 路由的严格的开始和严格的结束
- Django前面不加,结尾必须加/
- flask必须前面加/ ,结尾加与不加会有区别,但可以选择
- 路由的严格的开始和严格的结束
参数传递的两种方法:- <>尖括号:这类参数定义的话就必须传进去,路由和视图函数都需要定义参数
- ?关键字参数:路由不需要定义参数,视图函数不需要传参,是通过
request.GET.get("") 拿到关键字参数的值
URL映射--路由的传参---urls.py- path传递参数:
- <>尖括号:‘book/
/’
- <>尖括号:‘book/
- re_path传递参数:
- 尖括号:r"^article_list/(?P\d{2})/" 这里()给分组。固定写法?P<变量> 给分区取名
- path传递参数:
- 视图函数—views.py
- <>尖括号: def book_detail(request,book_id):
- ?关键字参数:request.GET.get(“id”)
''' <>尖括号 ''' -----book/urls.py------ urlpatterns = [ path('/',views.book_detail) re_path(r"(?P \d{4})/",views.article_list) ] -----book/views.py----- def book_detail(request,book_id): text = "您输⼊的书籍的id是:%s" % book_id 14 return HttpResponse(text) def current_year(request, year): return HttpResponse('年份是%s' % year) ''' ?关键字参数 ''' -----urls.py------ from book import views urlpatterns = [ path('admin/', admin.site.urls), path('book/detail/',views.book_detail) ] -----book/views.py----- def book_detail(request): book_id = request.GET.get("id") text = "您输⼊的书籍id是:%s" % book_id return HttpResponse(text)
URL反转传递参数
作用:利用当前url,添加参数,可以是适用于重定向的返回的url改变实现:- <>尖括号:kwargs来传递参数。例如:reverse(“book:detail”,kwargs={“book_id”:1})
- ?关键字:直接拼接,例如reverse(“front:singin”) + “?name=jr”
- 因为django中的reverse反转url的时候不区分GET请求和POST请求,因此不能在反转的时候添加查询字符串的参数。如果想要添加查询字符串的参数,只能 ⼿动的添加。
5)url命名
为什么需要URL命名:因为在项⽬开发的过程中URL地址可能经常变动,如果写死会经常去修改,指定了命名就可以修改视图函数了和视图函数的url如何给⼀个URL指定名称:path(‘login/’, views.login) 改为path(‘signIn/’, views.login, name=“login”),这样我们并不需要因为改变了路由就需要将视图函数改变应⽤命名空间:在多个app之间可能产⽣同名的URL,即 name是同样的,这时候为了避免这种情况,可以使⽤ 命名空间来加以区分。在urls.py中添加app_name即可------front\urls.py------ from django.urls import path from . import views # 这个就是应用命名空间 app_name = 'front' urlpatterns = [ path('', views.index), path('signIn/', views.login, name='login'), ] ------front\views.py------ from django.shortcuts import render, redirect from django.http import HttpResponse def index(request): name = request.GET.get('name') if name: return HttpResponse('前台首页') else: return redirect('front:login') def login(request): return HttpResponse('前台登录页面')
实例命名空间
作用:- ⼀个app,可以创建多个实例。可以使⽤多个URL映射同⼀个App。在做反转的时候,如果使⽤应⽤命名空间,就会发⽣混淆,为了避免这个问题,可以使⽤实例命名空间,实例命名空间使⽤,namespace=‘实例命名空间’
- 然后在函数里面就可以拿到路由名
实现:namespace=‘实例命名空间’""" 实例命名空间namespace """ ------urls.py⽂件-------- from django.contrib import admin from django.urls import path,include urlpatterns = [ path('admin/', admin.site.urls), path('cms1/', include("cms.urls",namespace='cms1')), path('cms2/', include("cms.urls",namespace='cms2')), ] ------cms/views.py⽂件-------- current_namespace = request.resolver_match.namespace print(current_namespace)
(二)模板
模板介绍
- 在之前的章节中,视图函数只是直接返回⽂本,⽽在实际⽣产环境中其实很少 这样⽤,因为实际的⻚⾯⼤多是带有样式的HTML代码,这可以让浏览器渲染出 ⾮常漂亮的⻚⾯。DTL是Django Template Language三个单词的缩写,也就 是Django⾃带的模板语⾔。当然也可以配置Django⽀持Jinja2等其他模板引 擎,但是作为Django内置的模板语⾔,和Django可以达到⽆缝衔接⽽不会产⽣ ⼀些不兼容的情况。
DTL与普通的HTML⽂件的区别
- DTL模板是⼀种带有特殊语法的HTML⽂件,这个HTML⽂件可以被Django编 译,可以传递参数进去,实现数据动态化。在编译完成后,⽣成⼀个普通的 HTML⽂件,然后发送给客户端。
渲染模板步骤
首先:模板选择(都需要配置)- 总模板开启:
------settings.py 中TEMPLATES-------- # DIRS优先级高于APP_DIRS。DIRS就是总模板。APP_DIRS就是开启应用模板 # 默认DIRS为[],应用模板开启,添加os.path.join(BASE_DIR, 'templates')就是说明会在总模板的文件夹中找 'DIRS': [os.path.join(BASE_DIR, 'templates')], 'APP_DIRS': True, - 某应用的模板开启
------settings.py 中TEMPLATES-------- # 默认APP_DIRS是开启的,但是应用还需要注册,总模板如果开启的话会先找它,因为优先级更大 # APP_DIRS:默认为True,这个设置为True后,会在INSTALLED_APPS的安 装了的APP下的templates⽂件加中查找模板。settings.py中 INSTALLED_APPS数组中添加你的app名字 'DIRS': [], 'APP_DIRS': True, ------settings.py 中INSTALLED_APPS------- # 往列表中添加某应用名称 'book'
- 总模板开启:
其次:模板加载,方式两种:- 1.render_to_string:找到模板,然后将模板编译后渲染成Python的字符串格 式。最后再通过HttpResponse类包装成⼀个HttpResponse对象返回回去。
from django.template.loader import render_to_string from django.http import HttpResponse def book_detail(request,book_id): html = render_to_string("index.html") return HttpResponse(html) - 2.以上⽅式虽然已经很⽅便了。但是django还提供了⼀个更加简便的⽅式,直接将模板渲染成字符串和包装成HttpResponse对象⼀步到位完成
from django.shortcuts import render def book_list(request): return render(request,'index.html')
- 1.render_to_string:找到模板,然后将模板编译后渲染成Python的字符串格 式。最后再通过HttpResponse类包装成⼀个HttpResponse对象返回回去。
查找顺序:- 先在DIRS这个列表依次查找路径下查找模板
- 再检查当前这个视图所处的app是否已经安装,如果已经安装了,那么就先在当前这个app下的templates⽂件夹中查找模板
- 如果没有找到,那么会在其他已经安装了的app中查找。如果所有路径下都没有找到,那么会抛出⼀ 个TemplateDoesNotExist的异常
模板传参
- 模板中可以包含变量,Django在渲染模板的时候,可以传递变量对应的值过去 进⾏替换。变量的命名规范和Python⾮常类似,只能是阿拉伯数字和英⽂字符 以及下划线的组合,不能出现标点符号等特殊字符。变量需要通过视图函数渲 染,视图函数在使⽤render或者render_to_string的时候可以传递⼀个context 的参数,这个参数是⼀个字典类型
- 字典里面键值存储的对象可以是:字符串、字典、列表(元组)、类实例对象。取值取不到的话标签就不会显示
- 键值是字典:.key取值
- 键值是列表(元组):.0取值(.索引)
- 键值类实例对象:.属性取属性值
- 不能通过中括号的形式访问字典和列表中的值,dict[‘key’]和list[1]是不 ⽀持的!
--------views.py-------- def profile(request): return render(request,'profile.html',context={'username':'juran'}) class Person(object): def __init__(self,username): self.username = username def index(request): p = Person("居然") content = { 'person':p } return render(request,"index.html",context=content) -------profile.html-----{{ username }}
-------index.html-----{{ person.username }}
常⽤的模板标签
- 更多标签:https://docs.djangoproject.com/en/2.0/ref/templates/builtins/
1)if标签
- if标签相当于Python中的if语句,有elif和else相对应,但是所有的标 签都需要⽤标签符号({%%})进⾏包裹。if标签中可以使⽤==、!=、<、<=、 >、>=、in、not in、is、is not等判断运算符。
- 必须以{% endif %}结尾

2)for…in…标签
- for…in…标签:类似于Python中的for…in…。可以遍历列表、元 组、字符串、字典等⼀切可以遍历的对象。
{% for book in books %}{{ book }}
{% endfor %} --------反向遍历reversed------ {% for book in books reversed %}{{ book }}
{% endfor %}- 1.遍历字典的时候,需要使⽤items、keys和values等⽅法。在DTL中,执⾏⼀个 ⽅法不能使⽤圆括号的形式。
{% for key,value in person.items %}key:{{ key }}
value:{{ value }}
{% endfor %} - 2.在for循环中,DTL提供了⼀些变量可供使⽤,用来标识每一次的循环信息
forloop.counter:当前循环的下标。以1作为起始值。 forloop.counter0:当前循环的下标。以0作为起始值。 forloop.revcounter:当前循环的反向下标值。⽐如列表有5个元素,那么第⼀次遍历这 个属性是等于5,第⼆次是4,以此类推。并且是以1作为最后⼀个元素的下标。 forloop.revcounter0:类似于forloop.revcounter。不同的是最后⼀个元素的下标 是从0开始。 forloop.first:是否是第⼀次遍历。 forloop.last:是否是最后⼀次遍历。 forloop.parentloop:如果有多个循环嵌套,那么这个属性代表的是上⼀级的for循环 - 3.for…in…empty标签:这个标签使⽤跟for…in…是⼀样的,只不过是在遍历的 对象
如果没有元素的情况下,会执⾏empty中的内容。{% for person in persons %}- {{ person }}
{% empty %} 暂时还没有任何⼈ {% endfor %} - 4.注意:在for循环中,
break,continue语句是⽤不了的。
- 1.遍历字典的时候,需要使⽤items、keys和values等⽅法。在DTL中,执⾏⼀个 ⽅法不能使⽤圆括号的形式。
3)a标签
- a标签:在模版中,我们经常要写⼀些url,⽐如某个a标签中需要定义
href属性。
模板常⽤过滤器
- 在模版中,有时候需要对⼀些数据进⾏处理以后才能使⽤。⼀般在Python中我 们是通过函数的形式来完成的。⽽在模版中,则是通过过滤器来实现的。过滤 器使⽤的是|来使⽤。
- add
定义:将传进来的参数添加到原来的值上⾯。这个过滤器会尝试将值和参数int强转成整形,然后进⾏相加。如果强转失败了,那么会将值和参数进⾏拼接,直接相加。如果是字符串,那么会拼接成字符串,如果是列表,那么会拼接成⼀个列表。-------templates\index.html--------- {{ value|add:"2" }} ## 如果value是等于4,那么结果将是6。如果value是等于⼀个普通的字符串,⽐ 如abc,那么结果将是abc2
- cut
定义:移除值中所有指定的字符串。类似于python中的replace(args,"")。-------templates\index.html--------- {{ value|cut:" " }}
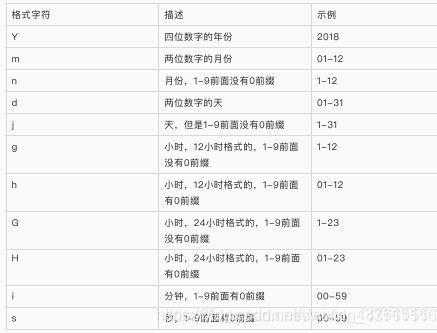
- date
定义:将⼀个⽇期按照指定的格式,格式化成字符串。有默认的格式,可以修改成自己想要的-------templates\index.html--------- {{ birthday|date:"Y/m/d" }} ------views.py------------ from django.shortcuts import render def book_list(request): context = {"birthday": datetime.now()} return render(request,'index.html',context=content)
- default
定义:如果值被评估为False。⽐如[],"",None,{}等这些在if判断中为False的值, 都会使⽤default过滤器提供的默认值。-------templates\index.html--------- {{ value|default:"nothing" }} ## 如果value是等于⼀个空的字符串。⽐如"",那么以上代码将会输出nothing。
- first/last
定义:返回列表/元组/字符串中的第⼀个元素/最后⼀个元素。-------templates\index.html--------- {{ value|first }} {{ value|last }}
- floatformat
定义:使⽤四舍五⼊的⽅式格式化⼀个浮点类型。如果这个过滤器没有传递任何参 数。那么只会在⼩数点后保留⼀个⼩数,如果⼩数后⾯全是0,那么只会保留整 数。当然也可以传递⼀个参数,标识具体要保留⼏个⼩数。-------templates\index.html---------- {{ 34.32|floatformat }}
34.3 2- {{ 34.35|floatformat }}
34.4 3- {{ 34.353333|floatformat:3}}
34.353
- join
定义:类似与Python中的join,将列表/元组/字符串⽤指定的字符进⾏拼接.-------templates\index.html--------- {{ value|join:"/" }} ## 如果value是等于['a','b','c'],那么以上代码将输出a/b/c。
- ength
定义:获取⼀个列表/元组/字符串/字典的⻓度。-------templates\index.html--------- {{ value|length }} ##如果value是等于['a','b','c'],那么以上代码将输出3。如果value为None,那么 以上将返回0
- ength
定义:获取⼀个列表/元组/字符串/字典的⻓度。-------templates\index.html--------- {{ value|length }} ##如果value是等于['a','b','c'],那么以上代码将输出3。如果value为None,那么 以上将返回0
模版结构优化
- 抽取重复代码
- 抽取部分:类似函数调用的部分,标签include。
- include标签寻找路径的⽅式。也是跟render渲染模板的函数是⼀样的。默认include标签包含模版,会⾃动的使⽤主模版中的上下⽂,也即可以⾃动的 使⽤主模版中的变量。
- 如果想传⼊⼀些其他的参数,那么可以使⽤with语句
--------header.html ------重复代码我是header
⽤户名:{{ username }}
--------footer.html -----重复代码我是footer
--------main.html -------调用重复代码、传参 {% include "header.html" with username='juran' %}我是main内容
{% include 'footer.html' %}
- 整体继承:
- block 是提供接口的部分,在这部分内容可以支持重写,一定要接接口命名,这样继承的子模板才可以通过extends标签来修改模板,在定义block的时候,除了在block
开始的地⽅定义这个block的名字,还可以在block结束的时候定义名字。⽐如{% block title %}{% endblock title %}。这 在⼤型模版中显得尤其有⽤,能让你快速的看到block包含在哪⾥。 - extends标签必须放在模版的第⼀⾏。⼦模板中的代码必须放在block中,否则将不会被渲染
- {{block.super}} 。如果在某个block中需要使⽤⽗模版的内容,那么可以使⽤{{block.super}}来继 承。⽐如上例,{%block title%},如果想要使⽤⽗模版的title,那么可以在⼦ 模版的title block中使⽤{{ block.super }}来实现。
--------base.html ------重复代码{% block title %}我的站点{% endblock %} {% block content %} {% endblock %}--------------index.html----------继承并重写 {% extends "base.html" %} {% block title %}博客列表{% endblock %} {% block content %} {% for entry in blog_entries %}{{ entry.title }}
{{ entry.body }}
{% endfor %} {% endblock %}
- block 是提供接口的部分,在这部分内容可以支持重写,一定要接接口命名,这样继承的子模板才可以通过extends标签来修改模板,在定义block的时候,除了在block
- 抽取部分:类似函数调用的部分,标签include。
加载静态⽂件
- 在⼀个⽹⻚中,不仅仅只有⼀个html⻣架,还需要css样式⽂件,js执⾏⽂件以 及⼀些图⽚等。因此在DTL中加载静态⽂件是⼀个必须要解决的问题。在DTL 中,使⽤static标签来加载静态⽂件。要使⽤static标签,⾸先需要{% load static %}。
- 1.⾸先确保django.contrib.staticfiles已经添加到settings.INSTALLED_APPS 中。
- 2.确保在settings.py中设置了STATIC_URL。
- 3.在已经安装了的app下创建⼀个⽂件夹叫做static,然后再在这个static⽂件 夹下创建⼀个当前app的名字的⽂件夹,再把静态⽂件放到这个⽂件夹下。
- 例如你的app叫做book,有⼀个静态⽂件叫做logo.jpg,那么路径为 book/static/book/logo.jpg。(为什么在app下创建⼀个static⽂件夹,还需要在这个static下创建⼀个同app名字的⽂件夹呢?原因是如果直接把静态⽂件放在static⽂件夹下,那么在模版加载静态⽂件的时候就是使⽤logo.jpg,如果在多个app之间有同名的静态⽂件,这时候可能就会产⽣混淆。⽽在static⽂件 夹下加了⼀个同名app⽂件夹,在模版中加载的时候就是使⽤app/logo.jpg, 这样就可以避免产⽣混淆。)
- 4.如果有⼀些静态⽂件是不和任何app挂钩的。那么可以在settings.py中添加 STATICFILES_DIRS,以后DTL就会在这个列表的路径中查找静态⽂件。
STATICFILES_DIRS = [ os.path.join(BASE_DIR,"static") ] - 5.在模版中使⽤load标签加载static标签。⽐如要加载在项⽬的static⽂件夹下 的style.css的⽂件。
{% load static %} - 6.如果不想每次在模版中加载静态⽂件都使⽤load加载static标签,那么可以在 settings.py中的TEMPLATES/OPTIONS添加
------settings.py-------TEMPLATES/OPTIONS 'builtins':['django.templatetags.static'],这样以后在模版中就可以直接使⽤static标 签,⽽不⽤⼿动的load了。 - 7.如果没有在settings.INSTALLED_APPS中添加django.contrib.staticfiles。 那么我们就需要⼿动的将请求静态⽂件的url与静态⽂件的路径进⾏映射了。
from django.conf import settings from django.conf.urls.static import static urlpatterns = [ # 其他的url映射 ] + static(settings.STATIC_URL, document_root=settings.STATICFILES_DIRS[0]) ```
(三)数据库
- 我们使⽤Django来操作MySQL,实际上底层还是通过Python来操作的。因此 我们想要⽤Django来操作MySQL,⾸先还是需要安装⼀个驱动程序。在 Python3中,驱动程序有多种选择。⽐如有pymysql以及mysqlclient等。这⾥ 我们就使⽤mysqlclient来操作。mysqlclient安装⾮常简单。只需要通过pip install mysqlclient即可安装。
- 常⻅MySQL驱动介绍:
- MySQL-python:也就是MySQLdb。是对C语⾔操作MySQL数据库的⼀个 简单封装。遵循了Python DB API v2 但是只⽀持Python2,⽬前还不⽀持Python3。 2. mysqlclient:是MySQL-python的另外⼀个分⽀。⽀持Python3 并且修复 了⼀些bug。 3. pymysql:纯Python实现的⼀个驱动。因为是纯Python编写的,因此执⾏效 率不如MySQL-python。并且也因为是纯Python编写的,因此可以和 Python代码⽆缝衔接。
49 - MySQL Connector/Python:MySQL官⽅推出的使⽤纯Python连接MySQL 的驱动。因为是纯Python开发的。效率不⾼。
1)Django配置连接数据库
- 在操作数据库之前,⾸先先要连接数据库。这⾥我们以配置MySQL为例来讲 解。Django连接数据库,不需要单独的创建⼀个连接对象。只需要在 settings.py⽂件中做好数据库相关的配置就可以了
--------------settings.py-------------- DATABASES = { 'default': { # 数据库引擎(是mysql还是oracle等) 'ENGINE': 'django.db.backends.mysql', # 数据库的名字 'NAME': 'logic', # 连接mysql数据库的⽤户名 'USER': 'root', # 连接mysql数据库的密码 'PASSWORD': 'root', # mysql数据库的主机地址 'HOST': '127.0.0.1', # mysql数据库的端⼝号 'PORT': '3306', } } ## 连接Linux服务器MySQL问题:https://blog.csdn.net/qq473179304/article/d etails/56665364
在Django中操作数据库
- 在Django中操作数据库有两种⽅式。第⼀种⽅式就是使⽤原⽣sql语句操作,第⼆种就是使⽤ORM模型来操作。
- 随着项⽬越来越⼤,采⽤写原⽣SQL的⽅式在代码中会出现⼤量的SQL语句, 那么问题就出现了: 1.SQL语句重复利⽤率不⾼,越复杂的SQL语句条件越多,代码越⻓。会出现很 多相近的SQL语句。 2.很多SQL语句是在业务逻辑中拼出来的,如果有数据库需要更改,就要去修 改这些逻辑,这会很容易漏掉对某些SQL语句的修改。 3.写SQL时容易忽略web安全问题,给未来造成隐患。SQL注⼊。
ORM模型介绍
- ORM,全称Object Relational Mapping,中⽂叫做对象关系映射,通过ORM 我们可以通过类的⽅式去操作数据库,⽽不⽤再写原⽣的SQL语句。通过把表映射成类,把⾏作实例,把字段作为属性,ORM在执⾏对象操作的时候最终还 是会把对应的操作转换为数据库原⽣语句。
- 优点 :1.易⽤性:使⽤ORM做数据库的开发可以有效的减少重复SQL语句的概率,写 出来的模型也更加直观、清晰。 2.性能损耗⼩:ORM转换成底层数据库操作指令确实会有⼀些开销。但从实际 的情况来看,这种性能损耗很少(不⾜5%),只要不是对性能有严苛的要求, 综合考虑开发效率、代码的阅读性,带来的好处要远远⼤于性能损耗,⽽且项 ⽬越⼤作⽤越明显。 3.设计灵活:可以轻松的写出复杂的查询。 4.可移植性:Django封装了底层的数据库实现,⽀持多个关系数据库引擎,包 括流⾏的MySQL、Postg
2)创建ORM模型
- ORM模型⼀般都是放在app的models.py⽂件中。每个app都可以拥有⾃⼰的模 型。并且如果这个模型想要映射到数据库中,那么这个app必须要放在
settings.py的INSTALLED_APP中进⾏安装。以下是写⼀个简单的书籍ORM模 型。 - 这个模型想要映射到数据库中,就必须继承⾃这个类:django.db.models.Model
-----------------------models.py---------------------------- from django.db import models class Book(models.Model): id = models.AutoField(primary_key=True) name = models.CharField(max_length=20,null=False) author = models.CharField(max_length=20,null=False) pub_time = models.DateTimeField(default=datetime.now) price = models.FloatField(default=0) # 查询到的数据可以直接 def __str__(self): return 'id:%s, name:%s' % (self.id, self.name) --- 以上便定义了⼀个模型。这个模型继承⾃django.db.models.Model,如果这个模型想要映射到数据库中,就必须继承⾃这个类。这个模型以后映射到数据库 中,表名是模型名称的⼩写形式,为book。 --- 在这个表中,有四个字段,⼀个为 name,这个字段是保存的是书的名称,是varchar类型,最⻓不能超过20个字 符,并且不能为空。 第三个字段是作者名字类型,同样也是varchar类型,⻓度 不能超过20个。 第四个是出版时间,数据类型是datetime类型,默认是保存这 本书籍的时间。 第五个是这本书的价格,是浮点类型。 还有⼀个字段我们没有写,就是主键id,在django中,如果⼀个模型没有定义 主键,那么将会⾃动⽣成⼀个⾃动增⻓的int类型的主键,并且这个主键的名字 就叫做id。
模型常⽤字段
- AutoField
- 映射到数据库中是int类型,可以有⾃动增⻓的特性。⼀般不需要使⽤这个类 型,如果不指定主键,那么模型会⾃动的⽣成⼀个叫做id的⾃动增⻓的主键。如果你想指定⼀个其他名字的并且具有⾃动增⻓的主键,使⽤AutoField也是可以 的。
- 虽然,自增长都是从1开始,但是如果直接在数据库将id改成负数也是没有问题的,因为这里的字段约束的只是在Django层面,并不能让mysql也遵循,mysql是int整数类型
- BigAutoField
- 64位的整形,类似于AutoField,只不过是产⽣的数据的范围是从1- 9223372036854775807。范围更大
- BooleanField
- 在模型层⾯接收的是True/False。在数据库层⾯是tinyint类型。如果没有指定 默认值,默认值是None。
- CharField
- 在数据库层⾯是varchar类型。在Python层⾯就是普通的字符串。这个类型在使⽤的时候必须要指定最⼤的⻓度,也即
必须要传递max_length这个关键字参数进去。 - 最⼤⻓度计算:https://www.cnblogs.com/canger/p/9850727.html
- 在数据库层⾯是varchar类型。在Python层⾯就是普通的字符串。这个类型在使⽤的时候必须要指定最⼤的⻓度,也即
- DateTimeField
- ⽇期时间类型,不仅仅可以存储⽇期,还可以存储时间。映射到数据库中是 datetime类型。django创建关于时间的model时,有三个可选,datetimefield、datefield和timefield,这三个分别对应datetime、date、time对象,都是封装了对应的,都有auto_now和auto_now_add
- 1.auto_now:最新修改时间,在每次这个数据保存的时候,都使⽤当前的时间。 ⽐如作为⼀个记录修改⽇期的字段,可以将这个属性设置为True。
- 2.auto_now_add:添加数据的时间。在每次数据第⼀次被添加进去的时候,都使⽤当前的时间。 ⽐如作为⼀个记录第⼀次⼊库的字段,可以将这个属性设置为True。
-------------settings.py------------ # 将'UTC'改为'Asia/Shanghai' TIME_ZONE = 'Asia/Shanghai' # 将控制UTC时区的开关关闭,不关会报错 USE_TZ = False ---------models.py--------- create_time = models.DateTimeField(auto_now_add=True) update_time = models.DateTimeField(auto_now=True)
- EmailField
- 类似于CharField。在数据库底层也是⼀个varchar类型。最⼤⻓度是254个字符,校验用户输入的邮箱地址时是否符合标准
- 作用:form表单验证的时候,做正则匹配的时候,验证的时候才可以看到效果
- email = models.EmailField(null=True)
| 其他字段类型 | 作用 |
|---|---|
| FileField | ⽤来存储⽂件的。 |
| ImageField | ⽤来存储图⽚⽂件的。 |
| FloatField | 浮点类型。映射到数据库中是float类型。 IntegerField |
| BigIntegerField | ⼤整形。值的区间是-9223372036854775808—— 9223372036854775807。 PositiveIntegerField |
| SmallIntegerField | ⼩整形。值的区间是-32768——32767。 PositiveSmallIntegerField |
| TextField | ⼤量的⽂本类型。映射到数据库中是longtext类型。 UUIDField |
| URLField | 类似于CharField,只不过只能⽤来存储url格式的字符串。并且默认的 max_length是200。 |
Field字段的常⽤参数
- 更多Field参数请参考官⽅⽂档:https://docs.djangoproject.com/zh- hans/2.2/ref/models/fields/
- null
- 如果设置为True,Django将会在映射表的时候指定是否为空。默认是为 False。在使⽤字符串相关的Field(CharField/TextField)的时候,官⽅推荐
尽量不要使⽤这个参数,也就是保持默认值False。因为Django在处理字符串相 关的Field的时候,即使这个Field的null=False,如果你没有给这个Field传递任 何值,那么Django也会使⽤⼀个空的字符串""来作为默认值存储进去。因此如果再使⽤null=True,Django会产⽣两种空值的情形(NULL或者空字符串)。 如果想要在表单验证的时候允许这个字符串为空,那么建议使⽤blank=True。 如果你的Field是BooleanField,那么对应的可空的字段则为 NullBooleanField。
- 如果设置为True,Django将会在映射表的时候指定是否为空。默认是为 False。在使⽤字符串相关的Field(CharField/TextField)的时候,官⽅推荐
- db_column
- 这个字段在数据库中的名字。如果没有设置这个参数,那么将会使⽤模型中属性的名字。
- 如果设置列的名字与属性的名字不同,是映射到数据库中的字段名,那么我们在查询的时候还是得按照属性名查询,因为这个还是一个类对象
- default
- 默认值。可以为⼀个值,或者是⼀个函数,但是不⽀持lambda表达式。并且不 ⽀持列表/字典/集合等可变的数据结构。
- db_column
- 这个字段在数据库中的名字。如果没有设置这个参数,那么将会使⽤模型中属 性的名字。
- primary_key
- 是否为主键。默认是False。
- unique
- 在表中这个字段的值是否唯⼀。⼀般是设置⼿机号码/邮箱等。
模型中Meta配置
- 对于⼀些模型级别的配置。我们可以在模型中定义⼀个类,叫做Meta。然后在 这个类中添加⼀些类属性来控制模型的作⽤。⽐如我们想要在数据库映射的时 候使⽤⾃⼰指定的表名,⽽不是使⽤模型的名称。那么我们可以在Meta类中添 加⼀个db_table的属性。
- db_table
- 这个模型映射到数据库中的表名。如果没有指定这个参数,那么在映射的时候 将会使⽤模型名来作为默认的表名。
- ordering
- 设置在提取数据的排序⽅式。⽐如我想在查找数据的时候根据添加的时间排序
class Book(models.Model): name = models.CharField(max_length=20,null=False) desc = models.CharField(max_length=100, pub_date = models.DateTimeField(auto_now_add=True) class Meta: db_table = 'book_model' ordering = ['pub_date'] # 正序 ordering = ['-pub_date'] # 倒序
- 设置在提取数据的排序⽅式。⽐如我想在查找数据的时候根据添加的时间排序
- db_table
外键ForeignKey
- 外键和表关系
- 在MySQL中,表有两种引擎,⼀种是InnoDB,另外⼀种是myisam。如果使⽤的是InnoDB引擎,是⽀持外键约束的。外键的存在使得ORM框架在处理表关系 的时候异常的强⼤。因此这⾥我们⾸先来介绍下外键在Django中的使⽤。
- 类定义为class ForeignKey(to,on_delete,**options)。第⼀个参数是引⽤的是 哪个模型,第⼆个参数是在使⽤外键引⽤的模型数据被删除了,这个字段该如 何处理,⽐如有CASCADE、SET_NULL等。这⾥以⼀个实际案例来说明。⽐ 如有⼀个Category和⼀个Article两个模型。⼀个Category可以有多个⽂章,⼀ 个Article只能有⼀个Category,并且通过外键进⾏引⽤。
- 创建外键:
- 采用InnoDB引擎,
- 注册应用 app_installl
- 外键跨app,直接加上app名称就行,如app.model_name
- 自相关:to参数可以为’self’,或者是 这个模型的名字,在论坛开发中,⼀般评论都可以进⾏⼆级评论,即可以针对 另外⼀个评论进⾏评论,那么在定义模型的时候就需要使⽤外键来引⽤⾃身
- 外键删除操作:
- 如果⼀个模型使⽤了外键。那么在对⽅那个模型被删掉后,该进⾏什么样的操作。可以通过on_delete来指定。可以指定的类型如下:
- SET()删改关系修改了,数据库可以不用重新去映射,flask修改关系就必须修改表结构,以上这些选项只是Django级别的,数据级别依旧是RESTRICT!

----------------------models.py------------------------- class Category(models.Model): name = models.CharField(max_length=100) class Article(models.Model): title = models.CharField(max_length=100) content = models.TextField() # author = models.ForeignKey("User",on_delete=models.CASCADE) category = models.ForeignKey("Category",on_delete=models.CASCA DE) ### 自相关 class Comment(models.Model): content = models.TextField() origin_comment = models.ForeignKey('self',on_delete=models.CAS CADE,null=True) # 或者 # origin_comment = models.ForeignKey('Comment',on_delete=model s.CASCADE,null=True) --------------------views.py-------------------------- from django.shortcuts import render from django.http import HttpResponse from .models import Article,Category def index(request): category = Category(name="news") category.save() article = Article(title='PHP',content='123') # 等于对象,就可以获取外键值 article.category = category article.save() ### 外键删除设置参考 # 级联删除 # category = models.ForeignKey('Category', on_delete=models.CASCADE, null=True) # PROTECT # category = models.ForeignKey('Category', on_delete=models.PROTECT) # SET_NULL 前提是可以为null category = models.ForeignKey('Category', on_delete=models.SET_NULL, null=True) # SET_DEFAULT 前提是需要把它改为别的外键的id # category = models.ForeignKey('Category', on_delete=models.SET_DEFAULT, default=4) # category = models.ForeignKey('Category', on_delete=models.SET_DEFAULT, default=Category.objects.get(pk=2)) # SET # category = models.ForeignKey('Category', on_delete=models.SET(Category.objects.get(pk=2)))
3)映射模型到数据库中
- 将ORM模型映射到数据库中,总结起来就是以下⼏步:
- 1.在settings.py中,配置好DATABASES,做好数据库相关的配置。
- 2.在app中的models.py中定义好模型,这个模型必须继承⾃ django.db.models。
- 3.将这个app添加到settings.py的INSTALLED_APP中。
- 4.在命令⾏终端,进⼊到项⽬所在的路径,然后执⾏命令python manage.py makemigrations来⽣成迁移脚本⽂件。
- 5.同样在命令⾏中,执⾏命令python manage.py migrate来将迁移脚本⽂件映 射到数据库中。
4)ORM的增删改查
- 这部分在app的视图函数文件里面完成
- 完成对数据库的修改的需要save来提交才可以修改数据库
- 添加数据
------------------------views.py--------------- from django.shortcuts import render from django.db import connection from .models import Book from django.http import HttpResponse def add_book(request): book = Book(name="Python",author="JR",price=78) book.save() return HttpResponse("书籍添加成功") - 删除数据
## 先查出来再删 book = Book.objects.get(pk=1) book.delete() - 修改数据
# 先查出来再改 book = Book.objects.get(pk=2) book.price = 200 book.save() - 查询数据
- 查找是数据库操作中⼀个⾮常重要的技术。查询⼀般就是使⽤filter、exclude 以及get三个⽅法来实现。我们可以在调⽤这些⽅法的时候传递不同的参数来实 现查询需求。在ORM层⾯,这些查询条件都是使⽤field+__+condition的⽅式 来使⽤的。
- get 查不到会报错。filter 查不到为空,这个更优
- 因为查询出来的是对象,所以想要打印对象是显示的信息,可以在模型中添加__str__方法
- 查询时间的话,如果直接指定某天某时某刻还是查不到,因为默认的时间是保留至小数6位的,所以查询指定时间还是用范围查找更好
-------------------views. 1.根据主键进⾏查找 book = Book.objects.get(pk=1) print(book) 2.根据字段来查找 book = Book.objects.filter(name="Python") print(book) 3.查询所有 book = Book.objects.all() - 查询条件:
- exact:精确查询。使⽤精确的=进⾏查找。如果提供的是⼀个None,那么在SQL层⾯就是被解释 为NULL
article = Article.objects.get(id__exact=14) article = Article.objects.get(id__exact=None) ## 可以得到Django执⾏的SQL语句。但是只能作⽤于QuerySet对 象上 print(article.query) ## select * from article where id=14; ## select * from article where id IS NULL; - iexact:like模糊查询。使⽤like进⾏查找。注意上⾯这个sql语句,因为在MySQL中,没有⼀个叫做ilike的。所以exact和 iexact的区别实际上就是LIKE和=的区别,在⼤部分collation=utf8_general_ci 情况下都是⼀样的(collation是⽤来对字符串⽐较的)
article = Article.objects.filter(title__iexact='hello world') ## select * from article where title like 'hello world'; - contains/icontain:包含,判断某个字段是否包含某个数据。区分大小写。icontain包含 不区分大小写
articles = Article.objects.filter(title__contains='hello') ## select * where title like binary '%hello%' ## binary指判断大小写 - in:取所有含有容器里面的值,取值,端点。提取那些给定的field的值是否在给定的容器中。容器可以为list、tuple或者任 何⼀个可以迭代的对象,包括QuerySet对象
articles = Article.objects.filter(id__in=[1,2,3]) ## select *from articles where id in (1,2,3) ## 当然也可以传递⼀个QuerySet对象进去。 # 查找标题为hello的⽂章分类,因为有外键引用,可以直接根据外键选出合适的 articles = Article.objects.filter(title__icontains="hello") category = Category.objects.filter(article__in=articles) # 查找⽂章ID为1,2,3的⽂章分类 合并上面的查询 category = Category.objects.filter(article__id__in=[1,2,3]) # 想要获取⽂章标题中包含"hello"的所有的分类 categories = Category.object.filter(article__title__contains="hell o") - ⽐较运算:gt⼤于gte⼤于等于。lt⼩于lte⼩于等于。
# 将所有id⼤于4的⽂章全部都找出来。 articles = Article.objects.filter(id__gt=4) ## select * from articles where id > 4; - range:范围查询。判断某个field的值是否在给定的区间中。对应SQL的between
#查询时间范围 start_date = datetime(year=2019, month=12, day=1,hour=10,minute=0, second=0) 2 end_date = d end_date = datetime(year=2019, month=12, day=30,hour=10,minute=0,s econd=0) date_range = Common.objects.filter(test_date__range=(start_date,en d_date)) - date:年月日。针对某些date或者datetime类型的字段。可以指定date的范围。并且这个时间 过滤,还可以使⽤链式调⽤。
date_test = Common.objects.filter(test_date__date=datetime(year=20 18,month=12,day=19)) - year:年。根据年份进⾏查找。
articles = Article.objects.filter(pub_date__year=2018) articles = Article.objects.filter(pub_date__year__gte=2017) # select ... where pub_date between '2018-01-01' and '2018-12-31'; # select ... where pub_date >= '2017-01-01'; - time:时分秒。根据时间进⾏查找。
articles = Article.objects.filter(pub_date__time=time(hour=15,minu te=21,second=10)) - 聚合函数:aggregate只返回使⽤聚合函数后的字段和值。 annotate会携带对象信息,会分组,返回列表形式。在原来模型字段的基础之上添加⼀个使⽤了聚合函数的字段,并 且在使⽤聚合函数的时候,会使⽤当前这个模型的主键进⾏分组(group by)。
1.Avg:求平均值。⽐如想要获取所有图书的价格平均值。那么可以使⽤以下代 码实现。 result = Book.objects.aggregate(Avg('price')) print(result) ## {"price__avg":23.0} ## 其中price__avg的结构是根据field__avg规则构成的。如果想要修改默认的名字,那么 可以将Avg赋值给⼀个关键字参数 ## result = Book.objects.aggregate(my_avg=Avg('price')) ## {"my_avg":23} 2.Count:获取指定的对象的个数 Count类中,还有另外⼀个参数叫做distinct,默认是等于False,如果是等于True,那 么将去掉那些重复的值 ## ⽐如要获取作者表中所有的不重复的邮箱总共有多少个。 result = Author.objects.aggregate(count=Count('email',distinct=Tr ue)) # 统计每本图书的销量 result = Book.objects.annotate(book_nums=Count("bookorder")) for book in result: print("%s/%s"%(book.name,book.book_nums)) 3.Max和Min:获取指定对象的最⼤值和最⼩值。⽐如想要获取Author表中,最 ⼤的年龄和最⼩的年龄分别是多少。 result = Author.objects.aggregate(Max('age'),Min('age')) ## {"age__max":88,"age__min":18} # 统计每本售卖图书的最⼤值和最⼩值 request = Book.objects.annotate(max=Max("bookorder__price"),min=Mi n("bookorder__price")) 4.Sum:求指定对象的总和。⽐如要求图书的销售总额。 # 每⼀本图书的销售总额 result = Book.objects.annotate(total=Sum("bookorder__price")) # 统计2019年,销售总额 result = BookOrder.objects.filter(create_time__year=2019).aggregat e(total=Sum("price"))
- exact:精确查询。使⽤精确的=进⾏查找。如果提供的是⼀个None,那么在SQL层⾯就是被解释 为NULL
5)F表达式和Q表达式----优化ORM
F表达式
- 引入:
- F表达式是⽤来优化ORM操作数据库的。⽐如我们要将公司所有员⼯的薪⽔都增加1000元,如果按照正常的流程,应该是先从数据库中提取所有的员⼯⼯资 到Python内存中,然后使⽤Python代码在员⼯⼯资的基础之上增加1000元,最 后再保存到数据库中。这⾥⾯涉及的流程就是,⾸先从数据库中提取数据到 Python内存中,然后在Python内存中做完运算,之后再保存到数据库中。⽽我们的F表达式就可以优化这个流程,他可以不需要先把数据从数据库中提取 出来,计算完成后再保存回去,他可以直接执⾏SQL语句,就将员⼯的⼯资增 加1000元。
----------普通方法----------- employees = Employee.objects.all() for employee in employees: employee.salary += 1000 employee.save() -----------F表达式----------- from djang.db.models import F Employee.objects.update(salary=F("salary")+1000) # F表达式并不会⻢上从数据库中获取数据,⽽是在⽣成SQL语句的时候,动态的获取传给F表达 式的值。 ## 如果想要获取作者中,name和email相同的作者数据。如果不使⽤F表达 式。 ----------普通方法----------- authors = Author.objects.all() for author in authors: if author.name == author.email: print(author) -----------F表达式----------- from django.db.models import F authors = Author.objects.filter(name=F("email"))
- F表达式是⽤来优化ORM操作数据库的。⽐如我们要将公司所有员⼯的薪⽔都增加1000元,如果按照正常的流程,应该是先从数据库中提取所有的员⼯⼯资 到Python内存中,然后使⽤Python代码在员⼯⼯资的基础之上增加1000元,最 后再保存到数据库中。这⾥⾯涉及的流程就是,⾸先从数据库中提取数据到 Python内存中,然后在Python内存中做完运算,之后再保存到数据库中。⽽我们的F表达式就可以优化这个流程,他可以不需要先把数据从数据库中提取 出来,计算完成后再保存回去,他可以直接执⾏SQL语句,就将员⼯的⼯资增 加1000元。
- 作用:
- 表示的是数据库表表的某一列的值
- 可以在不实际把数据库的数据存入到python内存当中的前提下,引用值和操作数据库
- 直接产生数据库级别的sql语句
- 事务和F都可以保证不会丢失操作
Q表达式
- 就是and or not做这些事情的
- and 并:&。条件之间可以直接逗号连接,不需要Q。但如果已经使用了Q,条件直接的链接就是用&
- or 或:|。需要用到Q 。如Q(条件1)|Q(条件2)
- not :~。
- 需要Q 需要取反的是条件2 Q(条件1)& ~Q(条件2)
- 条件2不能直接!=表示不等于 这个时候有两个条件是用&来链接,然后取反的条件在前面加上~
# 获取id等于3,或者名字中包含⽂字"传"的图书 5 books = Book.objects.filter(Q(id=3)|Q(name__contains="传")) # 获取书名包含"传",但是id不等于3的图书 books = Book.objects.filter(Q(name__contains='传') & ~Q(id=3))
6)QuerySet的⽅法
QuerySet API
- 我们通常做查询操作的时候,都是通过模型名字.objects的⽅式进⾏操作。其实 模型名字.objects是⼀个django.db.models.manager.Manager对象,⽽ Manager这个类是⼀个“空壳”的类,他本身是没有任何的属性和⽅法的。他的 ⽅法全部都是通过Python动态添加的⽅式,从QuerySet类中拷⻉过来的
- 所以我们如果想要学习ORM模型的查找操作,⾸先要学会QuerySet上的⼀些 API的使⽤
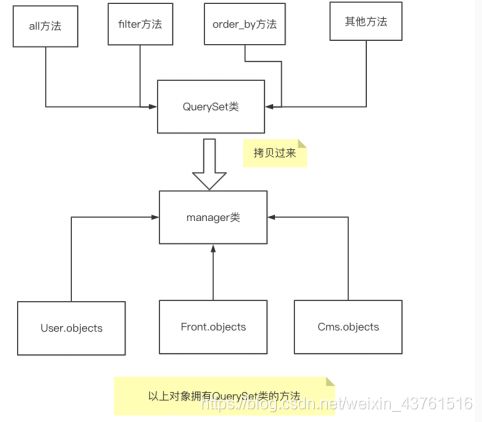
QuerySet的⽅法
- objects是啥?
- Book.objects类型 是个manager类,打开这个类,是继承的QuerySET- manager 拥有所有QuerySET查询集里面的方法,所以我们查询的到对象可以拥有QuerySET的方法进行二次过滤
- filter
- 将满⾜条件的数据提取出来,返回⼀个新的 QuerySet
- exclude
- 排除满⾜条件的数据,返回⼀个新的
- exclude与filter相反 取反
# 提取那些标题不包含`hello`的图书 Article.objects.exclude(title__contains='hello')
- annotate
- 给 QuerySet 中的每个对象都添加⼀个使⽤查询表达式(聚合 函数、F表达式、Q表达式、Func表达式等)的新字段
# 将在每个对象中都添加⼀个`author__name`的字段,⽤来显示这个⽂章的作者的年龄 articles = Article.objects.annotate(author_name=F("author__name"))
- 给 QuerySet 中的每个对象都添加⼀个使⽤查询表达式(聚合 函数、F表达式、Q表达式、Func表达式等)的新字段
- order_by :
- 指定将查询的结果根据某个字段进⾏
排序。如果要倒叙排序, 那么可以在这个字段的前⾯加⼀个负号# 根据创建的时间正序排序(从⼩到⼤,默认排序规则) articles = Article.objects.order_by("create_time") # 根据创建的时间倒序排序 articles = Article.objects.order_by("-create_time") # 根据作者的名字进⾏排序 articles = Article.objects.order_by("author__name") # ⾸先根据创建的时间进⾏排序,如果时间相同,则根据作者的名字进⾏排序 articles = Article.objects.order_by("create_time",'author__name' ) # 根据图书订单的评分来排序 articles = BookOrder.objects.order_by("book__rating")
- 指定将查询的结果根据某个字段进⾏
- values
- ⽤来指定在提取数据出来,需要提取哪些字段。默认情况下会把表 中所有的字段全部都提取出来,可以使⽤ values 来进⾏指定,并且使⽤了 values ⽅法后,提取出的 QuerySet 中的数据类型不是模型,⽽是在 values ⽅法中指定的字段和值形成的字典
- 用的比较多,是因为其他都是取全部的字段,但是这个可以
指定取哪个字段。返回的是字典,和以前不一样,不能和以前一样取数据,把所有字段都取出来了,取所有字段,可以指定字段来取,大大提高数据库的性能需要的时候查哪些
以前返回的是对象,取的是对象articles = Article.objects.values("title",'content') for article in articles: print(article)
- values_list
- 类似于 values 。只不过返回的 QuerySet 中,存储的不是字典,⽽是元组,可以通过下标取
articles = Article.objects.values_list("id","title") print(articles) #等
- 类似于 values 。只不过返回的 QuerySet 中,存储的不是字典,⽽是元组,可以通过下标取
- all
- 获取这个 ORM 模型的 QuerySet 对象。
- select_related :
- 在提取某个模型的数据的同时,也提前将相关联的数据 提取出来。⽐如提取⽂章数据,可以使⽤ select_related 将 author 信息提 取出来,以后再次使⽤ article.author 的时候就不需要再次去访问数据库 了。可以减少数据库查询的次数
- selected_related 只能⽤在
⼀对多或者⼀对⼀中,不能⽤在 多对多 或者 多对⼀ 中。⽐如可以提前获取⽂章的作者,但是不能通过作者获取这个作者的 ⽂章,或者是通过某篇⽂章获取这个⽂章所有的标签-----普通的查询------- article = Article.objects.get(pk=1) article.author # 重新执⾏⼀次查询语句 ---------select_related-------- article = Article.objects.select_related("author").get(pk=2) article.author # 不需要重新执⾏查询语句了
- prefetch_related
- 这个⽅法和 select_related ⾮常的类似,就是 在访问多个表中的数据的时候,减少查询的次数。这个⽅法是为了解决
多对⼀和多对多的关系的查询问题。⽐如要获取标题中带有 hello 字符串的⽂章以及 他的所有标签from django.db import connection articles = Article.objects.prefetch_related("tag_set").filter(titl e__contains='hello') print(articles.query) # 通过这条命令查看在底层的SQL语句 for article in articles: print("title:",article.title) print(article.tag_set.all())
- 这个⽅法和 select_related ⾮常的类似,就是 在访问多个表中的数据的时候,减少查询的次数。这个⽅法是为了解决
- create :
- 添加数据不需要调用save方法,只需要一行代码
- 创建⼀条数据,并且保存到数据库中。这个⽅法相当于先⽤指定 的模型创建⼀个对象,然后再调⽤这个对象的 save ⽅法
article = Article(title='abc') article.save() # 下⾯这⾏代码相当于以上两⾏代码 article = Article.objects.create(title='abc')
- get_or_create :
- 根据某个条件进⾏查找,如果找到了那么就返回这条数 据,如果没有查找到,那么就创建⼀个
obj,created= Category.objects.get_or_create(title='默认分类')
- 根据某个条件进⾏查找,如果找到了那么就返回这条数 据,如果没有查找到,那么就创建⼀个
- get_or_create :
- 根据某个条件进⾏查找,如果找到了那么就返回这条数据,如果没有查找到,那么就创建⼀个
- 运用场景:注册用户
obj,created= Category.objects.get_or_create(title='默认分类') # 如果有标题等于 默认分类 的分类,那么就会查找出来,如果没有,则会创建并 且存储到数据库中。 # 这个⽅法的返回值是⼀个元组,元组的第⼀个参数 obj 是这个对象,第⼆个参 数 created 代表是否创建的。
- exists :
- 判断某个条件的数据是否存在。返回布尔值,只会查询一条,limit 1。有一条存在就true,性能比较节省。
- 如果要判断某个条件的元素是否 存在,那么建议使⽤ exists ,这⽐使⽤ count 或者直接判断 QuerySet 更有 效得多。
if Article.objects.filter(title__contains='hello').exists(): print(True) # ⽐使⽤count更⾼效: if Article.objects.filter(title__contains='hello').count() > 0: # 也⽐直接判断QuerySet更⾼效 if Article.objects.filter(title__contains='hello'):
- update
- 执⾏更新操作,在 SQL 底层⾛的也是 update 命令。⽐如要将所 有 category 为空的 article 的 article 字段都更新为默认的分类
Article.objects.filter(category__isnull=True).update(category_id=3 )
- 执⾏更新操作,在 SQL 底层⾛的也是 update 命令。⽐如要将所 有 category 为空的 article 的 article 字段都更新为默认的分类
- update
- 执⾏更新操作,在 SQL 底层⾛的也是 update 命令。⽐如要将所 有 category 为空的 article 的 article 字段都更新为默认的分类
Article.objects.filter(category__isnull=True).update(category_id=3 )
- 执⾏更新操作,在 SQL 底层⾛的也是 update 命令。⽐如要将所 有 category 为空的 article 的 article 字段都更新为默认的分类
- update
- 执⾏更新操作,在 SQL 底层⾛的也是 update 命令。⽐如要将所 有 category 为空的 article 的 article 字段都更新为默认的分类
- 不需要save,但不会更新auto_now修改时间
Article.objects.filter(category__isnull=True).update(category_id=3 )
- 切⽚操作:
- 有时候我们查找数据,有可能只需要其中的⼀部分
- 切片也可以减少内存开销
- 切⽚操作并不是把所有数据从数据库中提取出来再做切⽚操作。⽽是在数据库 层⾯使⽤ LIMIE 和 OFFSET 来帮我们完成。所以如果只需要取其中⼀部分的数据的时候,建议⼤家使⽤切⽚操作
books = Book.objects.all()[1:3] for book in books: print(book)
将QuerySet转换为SQL去执⾏
- ⽣成⼀个QuerySet对象并不会⻢上转换为SQL语句去执⾏
from django.db import connection books = Book.objects.all() print(connection.queries) # 空的列表。说明上⾯的QuerySet并没有真正的执⾏。 - 在以下情况下QuerySet会被转换为SQL语句执⾏
迭代:在遍历QuerySet对象的时候,会⾸先先执⾏这个SQL语句,然后再把 这个结果返回进⾏迭代。⽐如以下代码就会转换为SQL语句:for book in Book.objects.all(): print(book)使⽤步⻓做切⽚操作:QuerySet可以类似于列表⼀样做切⽚操作。做切⽚操 作本身不会执⾏SQL语句,但是如果如果在做切⽚操作的时候提供了步⻓,那么就会⽴⻢执⾏SQL语句。需要注意的是,做切⽚后不能再执⾏filter⽅ 法,否则会报错。调⽤len函数:调⽤len函数⽤来获取QuerySet中总共有多少条数据也会执⾏ SQL语句。调⽤list函数:调⽤list函数⽤来将⼀个QuerySet对象转换为list对象也会⽴⻢ 执⾏SQL语句。判断:如果对某个QuerySet进⾏判断,也会⽴⻢执⾏SQL语句。
7)ORM模型迁移
迁移命令
- 迁移文件depend中会依赖上一个文件,如果其中的文件错误就会影响后面的
- makemigrations:将模型
⽣成迁移脚本。模型所在的app,必须放在 settings.py中的INSTALLED_APPS中。这个命令有以下⼏个常⽤选项:-
app_label:后⾯可以跟⼀个或者多个app,那么就只会针对这⼏个app⽣成 迁移脚本。 如果没有任何的app_label,那么会检查INSTALLED_APPS中所有的app下 的模型,针对每⼀个app都⽣成响应的迁移脚本。 -
--name:给这个迁移脚本指定⼀个名字。 -
--empty:⽣成⼀个空的迁移脚本。一般用不到。如果你想写⾃⼰的迁移脚本,可以使⽤ 这个命令来实现⼀个空的⽂件, 然后⾃⼰再在⽂件中写迁移脚本。
-
- migrate:将新⽣成的迁移脚本。
映射到数据库中。创建新的表或者修改表的 结构。以下⼀些常⽤的选项:-
app_label:将某个app下的迁移脚本映射到数据库中。如果没有指定,那么 会将所有在INSTALLED_APPS中的app下的模型都映射到数据库中。 -
app_label migrationname:给将某个app下指定名字的migration⽂件映射到 数据库中。 -
--fake:可以将指定的迁移脚本名字添加到数据库中。但是并不会把迁移脚 本转换为SQL语句,修改数据库中的表。 -
--fake-initial:将第⼀次⽣成的迁移⽂件版本号记录在数据库中。但并不会 真正的执⾏迁移脚本。
-
- showmigrations:查看某个app下的迁移⽂件。没啥用。如果后⾯没有app,那么将 查看INSTALLED_APPS中所有的迁移⽂件。
python manage.py showmigrations [app名字] - sqlmigrate:查看某个迁移⽂件在映射到数据库中的时候,转换的SQL语句。没啥用。
python manage.py sqlmigrate book 0001_initial
migrate在这个过程中做了啥
- 1.将迁移文件翻译成aql语句,然后在到数据库中执行sql语句
- 2.如果sql语句执行没有问题那么就将这迁移记录写入到的django.migrations表格中
将Django的核⼼表映射到数据库中
- Django中还有⼀些核⼼的表也是需要创建的。不然有些功能是⽤不了的。⽐如auth相关表。如果这个数据库之前就是使⽤Django开发的,那么这些表就已经存在了。可以不⽤管了。如果之前这个 数据库不是使⽤Django开发的,那么应该使⽤migrate命令将Django中的核⼼ 模型映射到数据库中。
根据已有的表⾃动⽣成模型
- 在实际开发中,有些时候可能数据库已经存在了。如果我们⽤Django来开发⼀ 个⽹站,读取的是之前已经存在的数据库中的数据。那么该如何将模型与数据 库中的表映射呢?根据旧的数据库⽣成对应的ORM模型,需要以下⼏个步骤:
- Django给我们提供了⼀个
inspectdb的命令,可以⾮常⽅便的将已经存在的 表,⾃动的⽣成模型。想要使⽤inspectdb⾃动将表⽣成模型。- 1.⾸先需要在 settings.py中配置好数据库相关信息。不然就找不到数据库。
DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': "migrations_demo", 'HOST': '127.0.0.1', 'PORT': '3306', 'USER': 'root', 'PASSWORD': 'root' } } - 2.终端生成模型文件保存
python manage.py inspectdb > models.py - 3.修正模型:
- 1 模型名:⾃动⽣成的模型,是根据表的名字⽣成的,可能不是你想要的。 这时候模型的名字你可以改成任何你想要的。
- 2 模型所属app:根据⾃⼰的需要,将相应的模型放在对应的app中。放在同⼀个app中也是没有任何问题的。只是不⽅便管理。
- 3 模型外键引⽤:将所有使⽤ForeignKey的地⽅,模型引⽤都改成字符串。这样不会产⽣模型顺序的问题。另外,如果引⽤的模型已经移动到其他的app中了,那么还要加上这个app的前缀。
- 4 让Django管理模型:将Meta下的
managed=False必须删掉,如果保留这 个,那么以后这个模型有任何的修改,使⽤migrate都不会映射到数据库中。 - 5 当有多对多的时候,应该也要修正模型。将中间表注释了,然后使⽤ ManyToManyField来实现多对多。并且,使⽤ManyToManyField⽣成的中间表的名字可能和数据库中那个中间表的名字不⼀致,这时候肯定就不能正 常连接了。那么可以通过db_table来指定中间表的名字。
class Article(models.Model): title = models.CharField(max_length=100, blank=True, null=True ) content = models.TextField(blank=True, null=True) author = models.ForeignKey('front.User', models.SET_NULL, blan k=True, null=True) tags = models.ManyToManyField("Tag",db_table='article_tag') class Meta: db_table = 'article - 6 表名:切记不要修改表的名字。不然映射到数据库中,会发⽣找不到对 应表的错误
- 1.⾸先需要在 settings.py中配置好数据库相关信息。不然就找不到数据库。
(四)⾼级视图
1)请求方式
常⽤的请求
- 1.GET请求:GET请求⼀般⽤来向服务器索取数据,但不会向服务器提交数据, 不会对服务器的状态进⾏更改。⽐如向服务器获取某篇⽂章的详情。
- 2.POST请求:POST请求⼀般是⽤来向服务器提交数据,会对服务器的状态进⾏更改。⽐如提交⼀篇⽂章给服务器。
设置请求方式
- 1.常⽤的请求method:视图函数添加参数method=[‘GET’]
- 2.限制请求装饰器:require_http_methods(需要传递⼀个允许访问的⽅法的列表)、require_GET和require_POST、require_safe
from django.views.decorators.http import require_http_methods,require_GET,require_POST,require_safe # require_GET是require_http_methods(['GET'])的简写形式,里面封装了这个方法 # @require_http_methods(['GET']) @require_GET def get_func(request): return HttpResponse('get_func') # @require_http_methods(['POST']) @require_POST def post_func(request): return HttpResponse('post_func') # 这个装饰器相当于是require_http_methods(['GET','HEAD'])的简写形式, # 只允许使⽤相对安全的⽅式来访问视图。因为GET和HEAD不会对服务器产⽣增删改的⾏为 @require_safe def my_view(request): pass
限制请求装饰器
- 为什么要做限制请求方法:如果用户请求方式不对,就不让你访问,反爬等安全问题更好
- 如果请求方式不对,会报forbidden 403错误,在settinng中MIDDLEWARE 中间键中,‘django.middleware.csrf.CsrfViewMiddleware’,csrf保护域名,会阻挡,所以会报forbidden 403错误 ,如果关闭 csrf,页面选择错误方式访问会直接不显示任何东西
2)⻚⾯重定向
重定向
- 重定向分为永久性重定向和暂时性重定向,在⻚⾯上体现的操作就是浏览器会 从⼀个⻚⾯⾃动跳转到另外⼀个⻚⾯。⽐如⽤户访问了⼀个需要权限的⻚⾯, 但是该⽤户当前并没有登录,因此我们应该给他重定向到登录⻚⾯。
- 永久性重定向:http的状态码是301,多⽤于旧⽹址被废弃了要转到⼀个新的 ⽹址确保⽤户的访问,最经典的就是京东⽹站,你输⼊www.jingdong.com 的时候,会被重定向到www.jd.com,因为jingdong.com这个⽹址已经被废 弃了,被改成jd.com,所以这种情况下应该⽤永久重定向。
- 暂时性重定向:http的状态码是302,表示⻚⾯的暂时性跳转。⽐如访问⼀ 个需要权限的⽹址,如果当前⽤户没有登录,应该重定向到登录⻚⾯,这种 情况下,应该⽤暂时性重定向。
设置重定向
- redirect(to, *args, permanent=False, **kwargs)
- to是⼀个url,permanent代表的是这个重定向是否是⼀ 个永久的重定向,默认是False。
from django.shortcuts import reverse,redirect def profile(request): if request.GET.get("username"): return HttpResponse("%s,欢迎来到个⼈中⼼⻚⾯!") else: return redirect(reverse("user:login"))
- to是⼀个url,permanent代表的是这个重定向是否是⼀ 个永久的重定向,默认是False。
3)HttpRequest对象
WSGIRequest对象
- Django在接收到http请求之后,会根据http请求携带的参数以及报⽂信息创建 ⼀个WSGIRequest对象,并且作为视图函数第⼀个参数传给视图函数。也就是 我们经常看到的request参数。在这个对象上我们可以找到客户端上传上来的所 有信息。这个对象的完整路径是django.core.handlers.wsgi.WSGIRequest。
WSGIRequest对象常⽤属性
- WSGIRequest对象上⼤部分的属性都是只读的。因为这些属性是从客户端上传 的,没必要做任何的修改
- path :请求服务器的完整“路径”,但不包含域名和参数。⽐如 http://www.baidu.com/xxx/yyy/ ,那么 path 就是 /xxx/yyy/ 。
- method :代表当前请求的 http ⽅法。⽐如是 GET 还是 POST 。
- GET :⼀个 django.http.request.QueryDict 对象。操作起来类似于 字典。这个属性中包含了所有以 ?xxx=xxx 的⽅式上传上来的参数。request.GET.get() 网页拿参数?name=
- POST :也是⼀个 django.http.request.QueryDict 对象。这个属性 中包含了所有以 POST ⽅式上传上来的参数。request.POST.get() 拿表单
- FILES :也是⼀个 django.http.request.QueryDict 对象。这个属性中
包含了所有上传的⽂件。 - COOKIES :⼀个标准的Python字典,包含所有的 cookie ,键值对都是字 符串类型。 放到浏览器 。比之前多了csrftoken 防止恶意攻击,会安全一点需要拿到csrftoken
- session :⼀个类似于字典的对象。⽤来操作服务器的 session。放到服务器
- META :存储的客户端发送上来的
所有 header 信息。- CONTENT_LENGTH :请求的正⽂的⻓度(是⼀个字符串)。
- CONTENT_TYPE :请求的正⽂的MIME类型。
- HTTP_ACCEPT :响应可接收的Content-Type。
- HTTP_ACCEPT_ENCODING :响应可接收的编码。
- HTTP_ACCEPT_LANGUAGE : 响应可接收的语⾔。
- HTTP_HOST :客户端发送的HOST值。
- HTTP_REFERER :在访问这个⻚⾯上⼀个⻚⾯的url。
- QUERY_STRING :单个字符串形式的查询字符串(未解析过的形式)
- REMOTE_HOST :客户端的主机名。
- REQUEST_METHOD :请求⽅法。⼀个字符串类似于 GET 或者 POST 。
- SERVER_NAME :服务器域名。
- SERVER_PORT :服务器端⼝号,是⼀个字符串类型。
WSGIRequest对象常⽤⽅法
- is_secure() :是否是采⽤ https 协议。
- is_ajax() :是否采⽤ ajax 发送的请求。原理就是判断请求头中是否存在 X-Requested-With:XMLHttpRequest 。
- get_host() :服务器的域名。如果在访问的时候还有端⼝号,那么会加上 端⼝号。⽐如 www.baidu.com:9000 。
- get_full_path() :返回完整的path。如果有查询字符串,还会加上查询 字符串。⽐如 /music/bands/?print=True 。
- get_raw_uri() :获取请求的完整 url 。
--------------views.py--------------- def index(request): # a = 1/0 from django.core.handlers.wsgi import WSGIRequest # print(type(request)) # print(request.path) # print(request.method) # print(request.GET.get('page')) # print(request.POST.get('page')) # print(request.COOKIES) # print(request.META) # for key, value in request.META.items(): # print(key, value) # print(request.is_secure()) # get_host():服务器的域名。如果在访问的时候还有端口号,那么会加上端口号。比如www.baidu.com: 9000。 print(request.get_host()) # get_full_path():返回完整的path。如果有查询字符串,还会加上查询字符串。比如 / music / bands /?print = True。 print(request.get_full_path()) # get_raw_uri():获取请求的完整url。 print(request.get_raw_uri()) return HttpResponse('hello world')
4)返回对象
常用返回对象
- HttpResponse对象、JsonResponse对象
HttpResponse对象
- Django服务器接收到客户端发送过来的请求后,会将提交上来的这些数据封装成⼀个HttpRequest对象传给视图函数。那么视图函数在处理完相关的逻辑 后,也需要返回⼀个响应给浏览器。⽽这个响应,我们必须返回 HttpResponseBase或者他的⼦类的对象。⽽HttpResponse则是HttpResponseBase⽤得最多的⼦类
- 常⽤属性
- 1.content:返回的内容。
--------------views.py--------------- response = HttpResponse() response.content = "⾸⻚" return response - 2.status_code:返回的HTTP响应状态码。
- 3.content_type:返回的数据的MIME类型,默认为text/html。浏览器会根据 这个属性,来显示数据。如果是text/html,那么就会解析这个字符串,如果text/plain,那么就会显示⼀个纯⽂本。直接填写标签信息可以显示,因为content_type是text/html默认。如果将content_type修改成文本text/plain,就不能显示标签。常⽤的Content-Type如下:
- text/html(默认的,html⽂件)
- text/plain(纯⽂本)
- text/css(css⽂件)
- text/javascript(js⽂件)
- multipart/form-data(⽂件提交)
- application/json(json传输)
- application/xml(xml⽂件)
- 4.设置请求头 response[‘X-Access-Token’] = ‘xxxx’。
- 1.content:返回的内容。
- 常⽤⽅法
- 1.set_cookie:⽤来设置cookie信息。
- 2.delete_cookie:⽤来删除cookie信息。
- 3.write:HttpResponse是⼀个类似于⽂件的对象,可以⽤来写⼊数据到数据体(content)中。content与write作用相同
--------------views.py--------------- def book(request): # return HttpResponse('喝高了
', content_type='text/plain;charset=utf-8') res = HttpResponse() # res.content = 'book' # res.status_code = 404 # res.content = 'hello
' res['username'] = 'cheney' res.write('hello') return res
JsonResponse对象
- JSONresponse 非常方便,可以直接转字典,如果是列表呢 safe=False才可以实现,如果是元组的话,会变成列表样式的json字符串
- ⽤来对象dump成json字符串,然后返回将json字符串封装成Response对象返 回给浏览器。并且他的Content-Type是application/json。
- 默认情况下JsonResponse只能对字典进⾏dump,如果想要对⾮字典的数据进 ⾏dump,那么需要给JsonResponse传递⼀个safe=False参数。
- 以上代码会报错,应该在使⽤HttpResponse的时候,传⼊⼀个safe=False参 数
--------------views.py--------------- from django.http import JsonResponse def index(request): return JsonResponse({"username":"juran","age":18} from django.http import JsonResponse def index(request): persons = ['张三','李四','王五'] # return JsonResponse(persons) # 会报错 return JsonResponse(persons,safe=False,json_dumps_params={'ensure_ ascii':False})
5)类视图
类视图
- 在写视图的时候,Django除了使⽤函数作为视图,也可以使⽤类作为视图。使⽤类视图可以使⽤类的⼀些特性,⽐如继承等。
- 类视图常用对象:View、TemplateView、ListView
- 映射的时候就需要调⽤View的类⽅法as_view()来进⾏转换。as_view()
- 作用:帮我们拿到用户请求方式
- 内部逻辑:该方法就是判断你请求的方式是什么名字、接收请求方式。会拿到参数做循环判断,通过as_view()才能获得请求的是post才是get。这个方法需要两个参数,一个是请求的方式,一个是你设置的请求的地址。如果你请求的方式和你请求的地址不在允许的范围内就会报错,这个函数需要传递两个参数。如果没有as_view()就拿不到请求方式的名字
View
- django.views.generic.base.View是主要的类视图,
所有的类视图都是继承⾃他。如果我们写⾃⼰的类视图,也可以继承⾃他。然后再根据当前请求的 method,来实现不同的⽅法。⽐如这个视图只能使⽤get的⽅式来请求,那么 就可以在这个类中定义get(self,request,args,kwargs)⽅法。以此类推,如果 只需要实现post⽅法,那么就只需要在类中实现 post(self,request,args,kwargs)。 - 请求方法:除了get⽅法,View还⽀持以下⽅法 [‘get’,‘post’,‘put’,‘patch’,‘delete’,‘head’,‘options’,‘trace’]。
- 请求方法错误:
- 如果⽤户访问了View中没有定义的⽅法。⽐如你的类视图只⽀持get⽅法,⽽出 现了post⽅法,那么就会把这个请求转发给 http_method_not_allowed(request,*args,**kwargs)。
- 我们可以通过重写该方法,自定义访问错误时响应的东西
--------------views.py--------------- from django.views import View class BookDetailView(View): def get(self,request,*args,**kwargs): return render(request,'detail.html') -------------urls.py-------------------- # 类视图写完后,还应该在urls.py中进⾏映射 # 映射的时候就需要调⽤View的类⽅法as_view()来进⾏转换。⾃动查找指定⽅法。 urlpatterns = [ path("detail//", views.BookDetailView.as_view(),name= 'detail') ] --------------views.py--------------- # 请求方法错误时,比如这里只定了post方法,如果我们get请求的话就会调用http_method_not_allowed class AddBookView(View): def post(self,request,*args,**kwargs): return HttpResponse("书籍添加成功!") def http_method_not_allowed(self, request, *args, **kwargs): return HttpResponse("您当前采⽤的method是:%s,本视图只⽀持使⽤po st请求!" % request.method) -------------urls.py-------------------- path("addbook/",views.AddBookView.as_view(),name='add_book')
TemplateView
- django.views.generic.base.TemplateView,这个类视图是专⻔⽤来返回模版的。
- 常用类属性:
- template_name:这个属性是⽤来存储模版的路径
- TemplateView:会⾃动的渲染这个变量指向的模 版。
- 常用类方法
- get_context_data:这个⽅法是⽤来返回上下⽂数据的,也就是在给模版传的参数的。如果不需要传参的话就没必要定义模板视图
# 模版中需要传递get_context_data参数 --------------views.py--------------- from django.views.generic.base import TemplateView class HomePageView(TemplateView): template_name = "home.html" def get_context_data(self, **kwargs): context = super().get_context_data(**kwargs) context['username'] = "juran" return context -------------urls.py-------------------- from django.urls import path from .views import HomePageView urlpatterns = [ path('', HomePageView.as_view(), name='home'), path('about/', TemplateView.as_view(template_name="about.html"), ] # 模版中不需要传递参数,直接只在urls.py中使⽤ TemplateView来渲染模版。 -------------urls.py-------------------- from django.urls import path from django.views.generic import TemplateView urlpatterns = [ path('about/', TemplateView.as_view(template_name="about.html"), ]
- get_context_data:这个⽅法是⽤来返回上下⽂数据的,也就是在给模版传的参数的。如果不需要传参的话就没必要定义模板视图
ListView
- 做分页的视图。在⽹站开发中,经常会出现需要列出某个表中的⼀些数据作为列表展示出来。 ⽐如⽂章列表,图书列表等等。在Django中可以使⽤ListView来帮我们快速实 现这种需求。
- 常用类属性:
- model :重写 model 类属性,指定这个列表是给哪个模型的。
- template_name :指定这个列表的模板
- paginate_by :指定这个列表⼀⻚中展示多少条数据。
- context_object_name :指定这个列表模型在模板中的参数名称。
- ordering :指定这个列表的排序⽅式。
- page_kwarg :获取第⼏⻚的数据的参数名称。默认是 page 。
- 常用类方法:
- get_context_data :获取上下⽂的数据。在这里可以得到有多少条,多少页等信息
- get_queryset :如果你提取数据的时候,并不是要把所有数据都返回,那 么你可以重写这个⽅法。将⼀些不需要展示的数据给过滤掉。
- Paginator和Page类:Paginator和Page类都是⽤来做分⻚的。他们在Django中的路径为 django.core.paginator.Paginator和django.core.paginator.Page。以下对这 两个类的常⽤属性和⽅法做解释
- Paginator常⽤属性:
- count:总共有多少条数据。
- num_pages:总共有多少⻚。
- page_range:⻚⾯的区间。⽐如有三⻚,那么就range(1,4)
- Page常⽤属性和⽅法:
- has_next:是否还有下⼀⻚。
- has_previous:是否还有上⼀⻚。
- next_page_number:下⼀⻚的⻚码。
- previous_page_number:上⼀⻚的⻚码
- number:当前⻚。属性,其他都是方法
- start_index:当前这⼀⻚的第⼀条数据的索引值。
- end_index:当前这⼀⻚的最后⼀条数据的索引值。
--------------------article_list.html----------------Title {% for article in articles %}- {{ article.title }}-{{ article.content }}
{% endfor %} --------------------models.py---------------- from django.db import models class Article(models.Model): title = models.CharField(max_length=20) content = models.TextField() create_time = models.DateTimeField(auto_now_add=True) --------------------urls.py-------------------- from django.urls import path from . import views urlpatterns = [ path('', views.ArticleListView.as_view(), name='list'), ] --------------------views.py---------------- from .models import Article from django.views.generic import ListView class ArticleListView(ListView): # 数据库模型 model = Article # 需要分页的模板 template_name = 'article_list.html' # 每页的数据量 paginate_by = 10 # 查询出来的数据的变量的名字 context_object_name = 'articles' # 通过create_time 这个字段来进行排序 ordering = 'create_time' # 进行翻页的参数 page_kwarg = 'page' def get_context_data(self, **kwargs): context = super(ArticleListView, self).get_context_data(**kwargs) # print(context) # for key, value in context.items(): # print(key, value) # paginator = context.get('paginator') # # count:总共有多少条数据。 # print(paginator.count) # # num_pages:总共有多少页。 # print(paginator.num_pages) # # page_range:页面的区间。比如有三页,那么就range(1, 4)。 # print(paginator.page_range) page = context.get('page_obj') # has_next:是否还有下一页。 print(page.has_next()) # has_previous:是否还有上一页。 print(page.has_previous()) # next_page_number:下一页的页码。 # previous_page_number:上一页的页码。 # number:当前页。 print(page.number) # start_index:当前这一页的第一条数据的索引值。 # end_index:当前这一页的最后一条数据的索引值。 return context def get_queryset(self): return Article.objects.filter(id__lte=89)
- Paginator常⽤属性:
(五)错误处理
错误处理
- 在⼀些⽹站开发中。经常会需要捕获⼀些错误,然后将这些错误返回⽐较优美 的界⾯,或者是将这个错误的请求做⼀些⽇志保存。
- 自定义错误返回页面效果
常⽤的错误码
- 404:服务器没有指定的url。
- 403:没有权限访问相关的数据。
- 405:请求的method错误。
- 400:bad request,请求的参数错误。
- 500:服务器内部错误,⼀般是代码出bug了。
- 502:⼀般部署的时候⻅得⽐较多,⼀般是nginx启动了,然后uwsgi有问题
⾃定义错误模板
- 1.关闭debug,添加域名
--------------------settings.py---------------- DEBUG = False ALLOWED_HOSTS = ["127.0.0.1"] - 2.调用模板
- 直接在templates⽂件夹下新建相应错误代码的模板⽂件。对于404和500这种⾃动抛出的错误。我们可以直接在templates⽂件夹下新建相应错误代码的模板⽂件。
- 或者专⻔定义⼀个app,⽤来处理这些错误
--------------------templates/405.html----------------Title 405错误
# templates⽂件夹下,可重定向到错误页面 ---------------views.py-------------- def index(request): return redirect(reverse('405')) # 或者专⻔定义⼀个app,⽤来处理这些错误 ---------------urls.py-------------- from django.urls import path from . import views urlpatterns = [ path("405",views.view_405,name="405") ] ---------------views.py-------------- from django.http import HttpResponse from django.shortcuts import render def view_405(request): return render(request,"errors/405.html",status=405)
(六)表单
HTML中的表单:
- 单纯从前端的html来说,表单是⽤来提交数据给服务器的,不管后台的服务器⽤ 的是Django还是PHP语⾔还是其他语⾔。只要把input标签放在form标签中, 然后再添加⼀个提交按钮,那么以后点击提交按钮,就可以将input标签中对应 的值提交给服务器了。
Django中的表单
- Django中的表单丰富了传统的HTML语⾔中的表单。在Django中的表单,主要做以下两件事 1. 渲染表单模板。 2. 表单验证数据是否合法。
1)⽤表单验证数据
Django中表单使⽤流程
- 在讲解Django表单的具体每部分的细节之前。我们⾸先先来看下整体的使⽤流 程。
- 1.⾸先我们在后台服务器定义⼀个表单类,继承⾃django.forms.Form
----------------forms.py---------------- class MessageBoardForm(forms.Form): title = forms.CharField(max_length=3,label='标题',min_length=2, error_messages={"min_length":'标题字符段不符合要求!'}) content = forms.CharField(widget=forms.Textarea,label='内容',er ror_messages={"required":'content字段必须填写!'}) email = forms.EmailField(label='邮箱') reply = forms.BooleanField(required=False,label='回复') - 2.在视图中,根据是GET还是POST请求来做相应的操作。如果是GET请求, 那么返回⼀个空的表单,如果是POST请求,那么将提交上来的数据进⾏校验。
----------------views.py---------------- from .forms import MessageForm from django.views import View from django.forms.utils import ErrorDict class IndexView(View): # 在使⽤GET请求的时候,我们传了⼀个form给模板,那么以后模板就可以使⽤ form来⽣成⼀个表单的html代码 def get(self,request): form = MessageBoardForm() return render(request,'index.html',{'form':form}) # 在使⽤POST请求的时候,我们根据前端上传上来的数据,构建⼀个新的表单 # 这个表单是⽤来验证数据是否合法的,如果数据都验证通过了,那么我们可以通过cleaned_data来获取相应的数据。在模板中渲染表单的HTML def post(self,request): form = MessageBoardForm(request.POST) if form.is_valid(): title = form.cleaned_data.get('title') content = form.cleaned_data.get('content') email = form.cleaned_data.get('email') reply = form.cleaned_data.get('reply') return HttpResponse('success') else: print(form.errors) return HttpResponse('fail') -----------urls.py-------------------- from django.urls import path from . import views urlpatterns = [ path('', views.IndexView.as_view(), name='index') ] - 3.编写前端网页
# 我们在最外⾯给了⼀个form标签,然后在⾥⾯使⽤了table标签来进⾏美化,在 使⽤form对象渲染的时候,使⽤的是table的⽅式,当然还可以使⽤ul的⽅式 (as_ul),也可以使⽤p标签的⽅式(as_p),并且在后⾯我们还加上了⼀个 提交按钮。这样就可以⽣成⼀个表单了 ----------------index.html---------------
- 1.⾸先我们在后台服务器定义⼀个表单类,继承⾃django.forms.Form
常⽤的Field
- 使⽤Field可以是对数据验证的第⼀步。你期望这个提交上来的数据是什么类型,那么就使⽤ 什么类型的Field。
- CharField:⽤来接收⽂本。
- 参数:max_length:这个字段值的最⼤⻓度。 min_length:这个字段值的最⼩⻓度。required:这个字段是否是必须的。默认是必须的。 error_messages:在某个条件验证失败的时候,给出错误信息。
- EmailField:⽤来接收邮件,会⾃动验证邮件是否合法。
- 错误信息的key:required、invalid
- FloatField:⽤来接收浮点类型,并且如果验证通过后,会将这个字段的值转换为浮点类 型。
- 参数: max_value:最⼤的值。 min_value:最⼩的值。 错误信息的key:required、invalid、max_value、min_value。
- IntegerField:⽤来接收整形,并且验证通过后,会将这个字段的值转换为整形。
- 参数: max_value:最⼤的值。 min_value:最⼩的值。 错误信息的key:required、invalid、max_value、min_value。
- URLField:⽤来接收url格式的字符串。
- 错误信息的key:required、invalid。
- CharField:⽤来接收⽂本。
常⽤验证器
- 在验证某个字段的时候,可以传递⼀个validators参数⽤来指定验证器,进⼀步对数据进⾏过滤。验证器有很多,但是很多验证器我们其实已经通过这个Field 或者⼀些参数就可以指定了。⽐如EmailValidator,我们可以通过EmailField来 指定,⽐如MaxValueValidator,我们可以通过max_value参数来指定。
- MaxValueValidator:验证最⼤值。
- MinValueValidator:验证最⼩值。
- MinLengthValidator:验证最⼩⻓度。
- MaxLengthValidator:验证最⼤⻓度。
- EmailValidator:验证是否是邮箱格式。
- URLValidator:验证是否是URL格式。
- RegexValidator:如果还需要更加复杂的验证,那么我们可以通过正则表达式的验证器:RegexValidator。⽐如现在要验证⼿机号码是否合格,那么我们可以通过以下代码实现:
------------------forms.py----------------- class MyForm(forms.Form): telephone = forms.CharField(validators=[validators.RegexValida tor("1[345678]\d{9}",message='请输⼊正确格式的⼿机号码!')])
⾃定义验证
- 有时候对⼀个字段验证,不是⼀个⻓度,⼀个正则表达式能够写清楚的,还需 要⼀些其他复杂的逻辑,那么我们可以对某个字段,进⾏⾃定义的验证。⽐如 在注册的表单验证中,我们想要验证⼿机号码是否已经被注册过了,那么这时 候就需要在数据库中进⾏判断才知道。对某个字段进⾏⾃定义的验证⽅式是, 定义⼀个⽅法,这个⽅法的名字定义规则是:clean_fieldname。如果验证失败,那么就抛出⼀个验证错误。⽐如要验证⽤户表中⼿机号码之前是否在数据 库中存在,那么可以通过以下代码实现
- 自定义验证器写在表单类里面,一定要返回,不返回其他地方就拿不到
- 自定义验证器会在除了其他验证都正确的时候才会访问这个方法,自定义验证之间不会相互影响
# # 验证数据对某个字段进⾏验证 ------------------forms.py----------------- class MyForm(forms.Form): telephone = forms.CharField(validators=[validators.RegexValidator("1[345678]\d{9}",message='请输⼊正确格式的⼿机号码!')]) def clean_telephone(self): telephone = self.cleaned_data.get('telephone') exists = User.objects.filter(telephone=telephone).exists() if exists: raise forms.ValidationError("⼿机号码已经存在!") return telephone ------------------forms.py----------------- # 针对多个字段进⾏验证,那么可以重写clean⽅法。⽐如要在注册的时候,要判断提交的两个密码是否相等 class MyForm(forms.Form): telephone = forms.CharField(validators=[validators.RegexValid ator("1[345678]\d{9}",message='请输⼊正确格式的⼿机号码!')]) pwd1 = forms.CharField(max_length=12) pwd2 = forms.CharField(max_length=12) def clean(self): cleaned_data = super().clean() pwd1 = cleaned_data.get('pwd1') pwd2 = cleaned_data.get('pwd2') if pwd1 != pwd2: raise forms.ValidationError('两个密码不⼀致!')
提取错误信息
- 如果验证失败了,那么有⼀些错误信息是我们需要传给前端的。这时候我们可 以通过以下属性来获取
- 1.form.errors:这个属性获取的错误信息是⼀个包含了html标签的错误信息。
- 2.form.errors.get_json_data():这个⽅法获取到的是⼀个字典类型的错误信息。将某个字段的名字作为key,错误信息作为值的⼀个字典。
- 3.form.as_json():这个⽅法是将form.get_json_data()返回的字典dump成 json格式的字符串,⽅便进⾏传输。
提取错误处理
- 上述⽅法获取的字段的错误值,都是⼀个⽐较复杂的数据。⽐如以下: {‘username’: [{‘message’: ‘Enter a valid URL.’, ‘code’: ‘invalid’}, {‘message’: ‘Ensure this value has at most 4 characters (it has 22).’, ‘code’: ‘max_length’}]}
- 那么如果我只想把错误信息放在⼀个列表中,⽽不要再放在⼀个字典中。这时 候我们可以定义⼀个⽅法,把这个数据重新整理⼀份。
# 这样就可以把某个字段所有的错误信息直接放在这个列表中 class MyForm(forms.Form): username = forms.URLField(max_length=4) def get_errors(self): errors = self.errors.get_json_data() new_errors = {} for key,message_dicts in errors.items(): messages = [] for message in message_dicts: messages.append(message['message']) new_errors[key] = messages return new_errors
2)ModelForm
ModelForm
- ⼤家在写表单的时候,会发现表单中的Field和模型中的Field基本上是⼀模⼀样 的,⽽且表单中需要验证的数据,也就是我们模型中需要保存的。那么这时候 我们就可以将模型中的字段和表单中的字段进⾏绑定。ModelForm
# 现在有个Article的模型。 ------------------models.py----------------- from django.db import models from django.core import validators class Article(models.Model): title = models.CharField(max_length=10,validators=[validators. MinLengthValidator(limit_value=3)]) content = models.TextField() author = models.CharField(max_length=100) category = models.CharField(max_length=100) create_time = models.DateTimeField(auto_now_add=True) # 那么在写表单的时候,就不需要把Article模型中所有的字段都⼀个个重复写⼀ 遍了。 ------------------forms.py----------------- from django import forms # MyForm是继承⾃forms.ModelForm,然后在表单中定义了⼀个Meta类 # 在 Meta类中指定了model=Article,以及fields="all",这样就可以将Article模型 中所有的字段都复制过来,进⾏验证。 class MyForm(forms.ModelForm): class Meta: model = Article fields = "__all__"- 选择验证的字段fields/exclude:
- 验证全部:
fields="all"这样就可以将Article模型 中所有的字段都复制过来,进⾏验证。 - 验证部分:如果只想针对其中⼏个字段进⾏验证, 那么可以给fields指定⼀个列表,将需要的字段写进去。⽐如只想验证title和 content,那么可以使⽤以下代码实现:
fields = ['title','content'] - 验证反集:如果要验证的字段⽐较多,只是除了少数⼏个字段不需要验证,那么可以使⽤ exclude来代替fields。⽐如我不想验证category,
exclude = ['category']
- 验证全部:
- ⾃定义错误消息:使⽤ModelForm,因为字段都不是在表单中定义的,⽽是在模型中定义的,因此⼀些错误消息⽆法在字段中定义。那么这时候可以在Meta类中,定义 error_messages,然后把相应的错误消息写到⾥⾯去。
class MyForm(forms.ModelForm): class Meta: model = Article 4 exclude = ['category'] error_messages ={ 'title':{ 'max_length': '最多不能超过10个字符!', 'min_length': '最少不能少于3个字符!' }, 'content': { 'required': '必须输⼊content!', } } - save⽅法:ModelForm还有save⽅法,可以在验证完成后直接调⽤save⽅法,就可以将这个数据保存到数据库中了
- 这个⽅法必须要在clean没有问题后才能使⽤,如果在clean之前使⽤,会抛出异常。
- 默认是⽣成这个模型的对象,自动将对象真正的插⼊到数据库中。
- 传入commit=False只⽣成这个模型的对象,先不上传,就可以把表单的字段修改后在上传到数据库
form = MyForm(request.POST) if form.is_valid(): form.save() return HttpResponse('succes') else: print(form.get_errors()) return HttpResponse('fail') # 如果表单上验证的字段没有包含模型中所有的字段,这时候就可以先创建对象, # 再根据填充其他字段,把所有字段的值都补充完成后,再保存到数据库中。 form = MyForm(request.POST) if form.is_valid(): article = form.save(commit=False) article.category = 'Python' article.save() return HttpResponse('succes') else: print(form.get_errors()) return HttpResponse('fail')
- 选择验证的字段fields/exclude:
3)⽂件上传
前端HTML代码实现
- 1.在前端中,我们需要填⼊⼀个form标签,然后在这个form标签中指定 enctype=“multipart/form-data”,不然就不能上传⽂件。
- 2.在form标签中添加⼀个input标签,然后指定input标签的name,以及 type=“file”。
---------------upload.html--------------Title
后端的代码实现
- 后端的主要⼯作是接收⽂件。然后存储⽂件。接收⽂件的⽅式跟接收POST的⽅ 式是⼀样的,只不过是通过FILES来实现
- 在定义模型的时候,我们可以给存储⽂件的字段指定为FileField,这个Field可以传递⼀个upload_to参数,⽤来指定上传上来的⽂件保存到哪⾥。
- 数据库存入的是文件的路径
---------------- models.py------------------- from django.db import models from django.core import validators class Article(models.Model): title = models.CharField(max_length=20, validators=[validators.MinLengthValidator(limit_value=3)], error_messages={'min_length': '最小长度为3'}) content = models.TextField() author = models.CharField(max_length=20) create_time = models.DateTimeField(auto_now_add=True) images = models.FileField(upload_to="files",null=True) ---------------- urls.py------------------- from django.urls import path from . import views from django.conf.urls.static import static from django.conf import settings urlpatterns = [ path('upload/', views.UploadView.as_view(), name='upload'), ] --------------forms.py------------------ class UploadForms(forms.ModelForm): class Meta: model = Article fields = '__all__' error_messages = { 'images': { } } --------------Views.py------------------ from django.shortcuts import render from django.views import View from .forms import UploadForms from django.http import HttpResponse from .models import Article class UploadView(View): def get(self, request): return render(request, 'upload.html') def post(self, request): # image = request.FILES.get('images') # print(request.POST) # print(image) # print(type(image)) # with open('demo.png', 'wb') as f: # f.write(image.read()) form = UploadForms(request.POST, request.FILES) print(form) if form.is_valid(): title = request.POST.get('title') content = request.POST.get('content') author = request.POST.get('author') # 接收文件 # 通过request.FILES接收到⽂件后 images = request.FILES.get('images') article = Article(title=title, content=content, author=author, images=images) # 再写⼊到指定的地⽅。这样就可以 完成⼀个⽂件的上传功能了。 # 调⽤完article.save()⽅法,就会把⽂件保存到files下⾯,并且会将这个⽂件的 路径存储到数据库中。 article.save() return HttpResponse('success') else: print(form.errors.get_json_data()) return HttpResponse('fail')- 文件存储:
- 1.upload_to:⽤来指定上传上来的⽂件保存到哪⾥。⽐如我们让他保存到项⽬的files⽂件夹下:upload_to=“files”
- 2.指定MEDIA_ROOT:
文件:我们也可以指定 MEDIA_ROOT,就不需要在FielField中指定upload_to,他会⾃动的将⽂件上 传到MEDIA_ROOT的⽬录下。 - 3.指定upload_to和MEDIA_ROOT:可以将文件存储在MEDIA_ROOT的⽬录下的upload_to="files"的文件夹下。
-----------------settings.py-----配置文件夹---- ## 指定MEDIA_ROOT⽬录。 MEDIA_ROOT = os.path.join(BASE_DIR,'media') MEDIA_URL = '/media/' -------------urls.py.py------添加MEDIA_ROOT⽬录下的访问路径 urlpatterns = [ path('', views.index), ] + static(settings.MEDIA_URL,document_root=settings.MEDIA_ROOT) -----------------models.py--------------- # 如果我们同时指定MEDIA_ROOT和upload_to,那么会将⽂件上传到 MEDIA_ROOT下的upload_to⽂件夹中。 #小文件夹命名方式: '%Y/%m/%d/' 增加文件 年月日,这样方便分类管理 images = models.FileField(upload_to='%Y/%m/%d/', null=True)
- 文件存储:
限制上传的⽂件拓展名
- 如果想要限制上传的⽂件的拓展名,那么我们就需要⽤到表单来进⾏限制。
- 字段添加验证器 validators =[validators.FileExtensionValidator([‘txt’,‘pdf’])]
- 普通的Form表单:模型和表单都需要添加验证器
- ⽤ModelForm,直接从模型中读取字段,在models中字段添加参数验证器validators就行
# 普通的Form表单 ----------------models.py---------------- thumbnial=models.FileField(upload_to='%Y/%m/%d/',validators =[validators.FileExtensionValidator(['txt','pdf'])]) ----------------forms.py---------------- class BookForms(forms.Form): 10 files = forms.FileField(validators=[validators.FileExtensionV alidator(['txt'],message="必须是TXT")]) ---------------views.py----------------- class uploadfile(View): def get(self,request): return render(request,"upload.html") def post(self,request): form = BookForms(request.POST,request.FILES) if form.is_valid(): title = request.POST.get('title') files = request.FILES.get('files') FilesUpload.objects.create(title=title,files=files) return HttpResponse("success") else: print(form.errors.get_json_data()) return HttpResponse("fail")
上传图⽚
- 上传图⽚跟上传普通⽂件是⼀样的。只不过是上传图⽚的时候Django会判断上 传的⽂件是否是图⽚的格式(除了判断后缀名,还会判断是否是可⽤的图 ⽚)。如果不是,那么就会验证失败。
- 使⽤ImageField,必须要先安装Pillow库:pip install pillow
----------------models.py----------- class Article(models.Model): title = models.CharField(max_length=100) content = models.TextField() thumbnail = models.ImageField(upload_to="%Y/%m/%d/") --------------forms.py------------ class BookForms(forms.Form): files = forms.ImageField(error_messages={"invalid_image":"格式 不对"})
(七)cookie和session
cookie和session介绍
-
1.cookie:在⽹站中,http请求是⽆状态的。也就是说即使第⼀次和服务器连接 后并且登录成功后,第⼆次请求服务器依然不能知道当前请求是哪个⽤户。 cookie的出现就是为了解决这个问题,第⼀次登录后服务器返回⼀些数据 (cookie)给浏览器,然后浏览器保存在本地,当该⽤户发送第⼆次请求的时 候,就会⾃动的把上次请求存储的cookie数据⾃动的携带给服务器,服务器通 过浏览器携带的数据就能判断当前⽤户是哪个了。cookie存储的数据量有限, 不同的浏览器有不同的存储⼤⼩,但⼀般不超过4KB。因此使⽤cookie只能存 储⼀些⼩量的数据
-
2.session: session和cookie的作⽤有点类似,都是为了存储⽤户相关的信息。 不同的是,cookie是存储在本地浏览器,session是⼀个思路、⼀个概念、⼀个 服务器存储授权信息的解决⽅案,不同的服务器,不同的框架,不同的语⾔有 不同的实现。虽然实现不⼀样,但是他们的⽬的都是服务器为了⽅便存储数据 的。session的出现,是为了解决cookie存储数据不安全的问题的。
-
3.cookie和session使⽤:web开发发展⾄今,cookie和session的使⽤已经出 现了⼀些⾮常成熟的⽅案。在如今的市场或者企业⾥,⼀般有两种存储⽅式:
- 3.1 存储在服务端:通过cookie存储⼀个sessionid,然后具体的数据则是保存在session 中。如果⽤户已经登录,则服务器会在cookie中保存⼀个sessionid,下次再次请求的时 候,会把该sessionid携带上来,服务器根据sessionid在session库中获取⽤户的session 数据。就能知道该⽤户到底是谁,以及之前保存的⼀些状态信息。这种专业术语叫做server side session。Django把session信息默认存储到数据库中,当然也可以存储到其他地⽅, ⽐如缓存中,⽂件系统中等。存储在服务器的数据会更加的安全,不容易被窃取。但存储在 服务器也有⼀定的弊端,就是会占⽤服务器的资源,但现在服务器已经发展⾄今,⼀些 session信息还是绰绰有余的。
- 3.2 将session数据加密,然后存储在cookie中。这种专业术语叫做client side session。 flask框架默认采⽤的就是这种⽅式,但是也可以替换成其他形式。
-
参考文档:session和cookie:https://www.cnblogs.com/sss4/p/7071334.html
1)操作cookie
- 设置cookie:设置cookie是设置值给浏览器的。因此我们需要通过response的对象来设置, 设置cookie可以通过response.set_cookie来设置,这个⽅法的相关参数如 下:
- key:这个cookie的key。
- value:这个cookie的value。
- max_age:最⻓的⽣命周期。单位是秒。
- expires:过期时间。跟max_age是类似的,只不过这个参数需要传递⼀个具体的⽇期,⽐ 如datetime或者是符合⽇期格式的字符串。如果同时设置了expires和max_age,那么将 会使⽤expires的值作为过期时间。
- path:对域名下哪个路径有效。默认是对域名下所有路径都有效。
- domain:针对哪个域名有效。默认是针对主域名下都有效,如果只要针对某个⼦域名才有 效,那么可以设置这个属性.
- secure:是否是安全的,如果设置为True,那么只能在https协议下才可⽤
- httponly:默认是False。如果为True,那么在客户端不能通过JavaScript进⾏操作
from datetime import datetime from django.utils.timezone import make_aware def cookie_test(request): response = HttpResponse("index") expires = make_aware(datetime(year=2018,month=12,day=27,hour= 3,minute=20,second=0)) response.set_cookie("username","juran",expires=expires,path= "/cms/") return response def get_cookie_test(request): cookies = request.COOKIES 13 username = cookies.get('username') return HttpResponse(username)
- 删除cookie:通过delete_cookie即可删除cookie。实际上删除cookie就是将指定的cookie 的值设置为空的字符串,然后使⽤将他的过期时间设置为0,也就是浏览器关闭 后就过期。
def delete_cookie(request): response = HttpResponse('delete') response.delete_cookie('username') return response - 获取cookie:获取浏览器发送过来的cookie信息。可以通过request.COOKIES来或者。这个 对象是⼀个字典类型。⽐如获取所有的cookie
cookies = request.COOKIES for cookie_key,cookie_value in cookies.items(): print(cookie_key,cookie_value)
2)操作session
- django中的session默认情况下是存储在服务器的数据库中的,在表中会根据 sessionid来提取指定的session数据,然后再把这个sessionid放到cookie中发 送给浏览器存储,浏览器下次在向服务器发送请求的时候会⾃动的把所有 cookie信息都发送给服务器,服务器再从cookie中获取sessionid,然后再从数 据库中获取session数据。但是我们在操作session的时候,这些细节压根就不 ⽤管。我们只需要通过request.session即可操作。
def index(request): request.session['username'] = 'jr' request.session.get('username') return HttpResponse('index') - session常⽤的⽅法如下:
- 1. get :⽤来从 session 中获取指定值。
- 2. pop :从 session 中删除⼀个值。
- 3. keys :从 session 中获取所有的键。
- 4. items :从 session 中获取所有的值。
- 5. clear :清除当前这个⽤户的 session 数据。
- 6.flush :删除 session 并且删除在浏览器中存储的 session_id ,⼀般在 注销的时候⽤得⽐较多。
- 7. set_expiry(value) :设置过期时间。 整形:代表秒数,表示多少秒后过期。 0 :代表只要浏览器关闭, session 就会过期。 None :会使⽤全局的 session 配置。在 settings.py 中可以设置 SESSION_COOKIE_AGE 来配置全局的过期时间。默认是 1209600 秒,也就 是2周的时间。 -1:代表已经过期
- 8. clear_expired :清除过期的 session 。 Django 并不会清除过期的 session ,需要定期⼿动的清理,或者是在终端,使⽤命令⾏ python manage.py clearsessions 来清除过期的 session 。
- 修改session的存储机制:默认情况下,session数据是存储到数据库中的。当然也可以将session数据存 储到其他地⽅。可以通过设置SESSION_ENGINE来更改session的存储位置, 这个可以配置为以下⼏种⽅案:
- 1. django.contrib.sessions.backends.db:使⽤数据库。默认就是这种⽅案。
- 2. django.contrib.sessions.backends.file:使⽤⽂件来存储session。
- 3. django.contrib.sessions.backends.cache:使⽤缓存来存储session。想 要将数据存储到缓存中,前提是你必须要在settings.py中配置好CACHES, 并且是需要使⽤Memcached,⽽不能使⽤纯内存作为缓存。
- 4. django.contrib.sessions.backends.cached_db:在存储数据的时候,会将 数据先存到缓存中,再存到数据库中。这样就可以保证万⼀缓存系统出现问 题,session数据也不会丢失。在获取数据的时候,会先从缓存中获取,如果 缓存中没有,那么就会从数据库中获取。
- 5. django.contrib.sessions.backends.signed_cookies:将session信息加密 后存储到浏览器的cookie中。这种⽅式要注意安全,建议设置 SESSION_COOKIE_HTTPONLY=True,那么在浏览器中不能通过js来操作 session数据,并且还需要对settings.py中的SECRET_KEY进⾏保密,因为 ⼀旦别⼈知道这个SECRET_KEY,那么就可以进⾏解密。另外还有就是在 cookie中,存储的数据不能超过4k
----------------settings.py----------------- CACHES = { 'default':{ 'BACKEND':'django.core.cache.backends.memcached.MemcachedC ache', 'LOCATION':'127.0.0.1:11211' } } SESSION_ENGINE = 'django.contrib.sessions.backends.cached_db'
(八)上下⽂处理器
上下⽂处理器介绍
- 上下⽂处理器是可以返回⼀些数据,在全局模板中都可以使⽤。⽐如登录后的 ⽤户信息,在很多⻚⾯中都需要使⽤,那么我们可以放在上下⽂处理器中,就 没有必要在每个视图函数中都返回这个对象。 在 settings.TEMPLATES.OPTIONS.context_processors 中,有许多内置的上下⽂处理器。
- 一些上下⽂处理器的作⽤:
- 1. django.template.context_processors.debug :增加⼀个 debug 和 sql_queries 变量。在模板中可以通过他来查看到⼀些数据库查询。
- 2. django.template.context_processors.request :增加⼀个 request 变量。这个 request 变量也就是在视图函数的第⼀个参数。
- 3. django.contrib.auth.context_processors.auth : Django 有内置的⽤户系统,这个上下⽂处理器会增加⼀个 user 对象。
- 4. django.contrib.messages.context_processors.messages :增加⼀个 messages 变量。
- 5. django.template.context_processors.static :在模板中可以使 ⽤ STATIC_URL 。
- 6. django.template.context_processors.csrf :在模板中可以使⽤ csrf_token 变量来⽣成⼀个 csrf token 。
- ⾃定义上下⽂处理器: 有时候我们想要返回⾃⼰的数据。那么这时候我们可以⾃定义上下⽂处理器。 ⾃定义上下⽂处理器的步骤如下:
- 1. 你可以根据这个上下⽂处理器是属于哪个 app ,然后在这个 app 中创建⼀个 ⽂件专⻔⽤来存储上下⽂处理器。⽐如 context_processors.py 。或者 是你也可以专⻔创建⼀个 Python包 ,⽤来存储所有的上下⽂处理器。
- 2. 在你定义的上下⽂处理器⽂件中,定义⼀个函数,这个函数只有⼀个 request 参数。这个函数中处理完⾃⼰的逻辑后,把需要返回给模板的数 据,通过字典的形式返回。如果不需要返回任何数据,那么也必须返回⼀个 空的字典。
def frontuser(request): userid = request.session.get("userid") userModel = models.FrontendUser.objects.filter(pk=userid).first () if userModel: return {'frontuser':userModel} else: return {}
四、Django报错
(一)编码解码错误
- UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0xa6 in position 9737: illegal multibyte sequence
- Django2.2的这个版本编码解码问题
- 解决办法:
- 修改源代码: 在虚拟环境里这个目录下:venv\Lib\site-packages\django\views* 找到debug.py这个文件 如果没有使用虚拟环境,该文件在Python安装目录里的Lib\site-packages\django\views\里 找到该文件的 331行代码如下:
with Path(CURRENT_DIR, 'templates', 'technical_500.html').open() as fh:
修改成:
with Path(CURRENT_DIR, 'templates', 'technical_500.html').open(encoding='utf-8') as fh:
(二)migrate迁移错误
migrations中的迁移版本和数据库中的迁移版本对不上怎么办?
- 1.找到哪⾥不⼀致,然后使⽤python manage.py --fake [版本名字],将这个版本标记为已经映射。
- 2.删除指定app下migrations和数据库表django_migrations中和这个app相关 的版本号,然后将模型中的字段和数据库中的字段保持⼀致,再使⽤命令 python manage.py makemigrations重新⽣成⼀个初始化的迁移脚本,之后再 使⽤命令python manage.py migrate --fake-initial来将这个初始化的迁移脚 本标记为已经映射。以后再修改就没有问题了。
前面删掉数据库一部分的迁移记录,迁移的时候报错
- 解决办法
- 1:删除该app名字下的migrations下的相应的迁移文件的文件。进入数据库,找到django_migrations的表,删除该app名字对应的相关记录。这个时候直接migrate会报错
- 2:跳过最初的迁移第一步:python manage.py migrate --fake-initial
- 3:直接迁移 python manage.py migrate 重新运行迁移命令.
- 解决的原因:
- migrate执行的时候首先将迁移文件翻译成sql语句,然后在到数据库中执行sql语句,很显然我们是在第一步就出错了,因为我们的迁移之前做过,数据库中已经存在了表格,这个时候再去创建表格就会无法执行,所以我们就需要省掉第一步,直接把sql迁移数据initial加入,没有执行,然后直接执行修改的数据,直接对表进行修改
- 执⾏命令python manage.py makemigrations⽣成初始化的迁移脚本。⽅便后⾯通过ORM来管理表。这时候还需要执⾏命令python manage.py migrate --fake-initial,因为如果不使⽤–fake-initial,那么会将迁移脚本会映射到数据库中。这时候迁移脚本会新创建表,⽽这个表之前是已经存在了的,所以 肯定会报错。此时我们只要将这个0001-initial的状态修改为已经映射,⽽不真正执⾏映射,下次再migrate的时候,就会忽略他。