EXCEL与PYTHON系列第一篇---Pandas(2)to_excel详解-xlsxwriter及openpylx
引言
这是excel+python-pandas章的第二篇文章;上一篇我们讲了read_excel,这一篇我们就来讲to_excel
pandas和excel其实基本上是独立的,甚至可以说从某种意义上来说pandas与excel是可以画等号的
pandas与excel的交互都是通过第三方库(引擎)来实现的,上一篇中我们就简单介绍了xlrd等的第三方库,在本篇中我们会更加详细的来讲解pandas用来做数据导出到excel的几个重要的库。
正文
一、导出引擎
使用pandas导出数据到excel表很简单,来看代码:
import pandas as pd
df = pd.DataFrame({"a": [1, 2, 3, 4], "b": [5, 6, 7, 8]})
df.to_excel("pf.xlsx")import pandas as pd df = pd.DataFrame({"a": [1, 2, 3, 4], "b": [5, 6, 7, 8]}) df.to_excel("pf.xlsx")
如果直接全部导出的话,to_excel只需要一个表名字+后缀的入参就行
上面的数据导出来之后的样子是这样的:

编辑
图1
可以看到导出的数据自动添加了自增的行索引,还加了一些格式
行索引的添加是pandas的功劳,而格式则主要取决于第三方库(引擎)
to_excel默认使用的引擎包括,xlxswriter,openpyxl,xlwt
.xlsx后缀的文件默认使用xlsxwriter库,如果我们要用其他的库,那么我们就可以用engine参数
这边我们来详细的讲一下xlsxwriter
首先我们要知道,导出数据到excel之后我们确实可以使用xlsxwriter来调整格式,但是一般不推荐
因为实际工作中我们会使用模板(template),格式都已经预设好了,pandas只需要负责自己最专业的事情,数据处理分析,就行。
但是不管怎么样,我们还是来看一下,如果需要导出带自定义格式的excel文件的话要怎么做
先来生成一些数据:
import pandas as pd
name = ["张三","李四","王五"]
score = [80,90,100]
df = pd.DataFrame({'姓名': name,'成绩-2021第一学年三年四班': score})import pandas as pd name = ["张三","李四","王五"] score = [80,90,100] df = pd.DataFrame({'姓名': name,'成绩-2021第一学年三年四班': score})
这个数据我们如果直接用to_excel导出来的话样子是这样的:
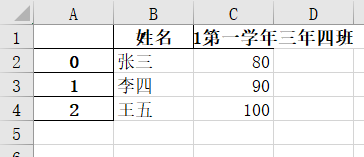
编辑
图2
我们来设置列名的格式,上对齐、底色、自动换行:
header_format = workbook.add_format({
'text_wrap': True,
'valign': 'top',
'fg_color': '#D7E4BC'})然后使用方法ExcelWriter,搭配to_excel来完成格式的设置:
writer = pd.ExcelWriter("pf.xlsx", engine='xlsxwriter')
df.to_excel(writer, sheet_name='Sheet1', startrow=1, header=False)
workbook = writer.book
worksheet = writer.sheets['Sheet1']
header_format = workbook.add_format({
'text_wrap': True,
'valign': 'top',
'fg_color': '#D7E4BC',})
for col_num, value in enumerate(df.columns.values):
worksheet.write(0, col_num + 1, value, header_format)
writer.save()我们先来看结果,然后再来解释代码:
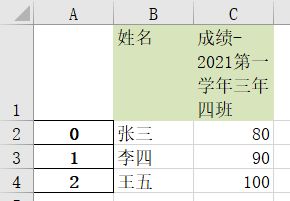
编辑
图3
代码中首先调ExcelWriter,指定使用xlsxwriter来写数据。然后在to_excel的时候设置了两个条件
也就是startrow=1, header=False;意思就是说要求导出的时候忽略第一行的列名,因为我们要修改列的设置,后面我们会将设置好格式的列再次加入到导出数据中。
用to_excel生成excel表后,读取到数据所在的表,也就是:
worksheet = writer.sheets['Sheet1']这个是不是和VBA有点像,如果是VBA的话我们会这样写:
worksheet = thisworkbook.worksheets("Sheet1")然后我们用workbook的add_format方法来设置格式。这里设置了三个,也就是自动换行,对其方式,和单元格颜色填充
接着我们将数据的列名再次写入到excel表格中,最后保存,就完成了
这里有一点不知道大家有没有注意到,我们是先用to_excel生成了表格,然后读取表格,设置单元格格式
大家看到了,为了设置标题的几个格式我们多写了很多的代码,原来只需要一行,现在变成了十几行,这就是为啥在实际应用中我们在大部分情况下都使用模板。
anyway,我们再来举一个栗子。假设还是使用上面的数据,我们要给成绩那列加个条件格式,将成绩大于89分的凸显出来,那我们就可以这样做:
format = workbook.add_format({'bg_color': '#FFC7CE','font_color': '#9C0006'})
(max_row, _) = df.shape
worksheet.conditional_format("C2:C"+str(max_row+1),{'type':'cell','criteria': '>=','value':89,'format':format})结果呢就是这样滴:

编辑切换为居中
图4
上面的语句并不是直接将大于89的单元格标上颜色,而是加了条件格式的规则
使用xlsxwriter还可以完成很多的设置,比如说筛选,生成图表等等。但还是那句话,用模板
除了xlsxwriter以外还有一个常用的引擎,openpyxl,这个引擎和xlsxwriter的差别还是蛮大的,主要体现在:
-
xlsxwriter是以0作为数组的初始标签的,openpyxl则是1。
-
openpyxl在处理.xlsm后缀的文件时更加的便捷
-
xlsxwriter对excel的各项功能的实现更加的完善
-
openpyxl能读写,但xlsxwriter,只能写
-
xlsxwriter不能将数据写到已存在的表中,也就是说如果要将数据写入一张设置好的excel模板里面单用xlsxwriter是无法实现的
关于数据引擎就讲这么多了,如果大家感兴趣可以私信楼主,有机会的话可以开几篇来单讲。
二、to_excel参数设置
我们回过来看to_excel的一些重要的入参:
-
engine:指定引擎
-
header:表头设置,默认第一行是表头
-
startrow:开始的行数,默认从第一行开始读取
-
sheet_name:要写入的目标表名
-
na_rep:空值的替换值
-
index:行标签,也就是那列自增的列
to_excel的参数就不详细说了,都非常的简单易懂,而且实际工作中一般也用大不到
这里要特别说一下如果写入的数据比较多的话,记得要设置内存使用量
另外记得安装lxml库,这个库写过python爬虫的应该熟。如果使用openpylx读写的话,lxml能提高读写效率
结语
本篇文章主要讲了pandas的to_excel方法,也介绍了xlsxwriter。后面一篇讲什么有点犹豫,有几个思路:
-
讲大数据的读写
-
继续讲pandas
-
讲xlwings
楼主是倾向接下来讲xlwings
pandas有很多内容可以讲,但是和excel相关的其实就read和write了,对于pandas来说excel是数据源和结果展示平台。要接着讲pandas的话就偏离了excel+python的大主题了
所以大家没有意见的话下期就开始讲xlwings了