对抗网络GAN详解:GAN训练不稳定解决方法、GAN中使用的深度学习技巧、GAN使用任务领域、GAN资料大全整理
- 不建议用博弈论思想 (game theory) 去理解对抗网络,减弱生成器 G 与判别器 D 间的对抗属性有利于稳定训练。
- 不要把判别器理解成一个分类器 (Discriminator, Classifier),让判别器回归判别属性,像 Critic 那样输出一个评分。这样能让判别器为生成器提供更良好的优化梯度。
- 神经网络 A 可以用标好的数据去训练,这是单层优化。若数据没有被标记,我也可以训练网络 B 对数据进行标记,之后网络 A 可以在 B 的协助下进行训练,这是双层优化 。双层优化视角下,对抗网络的生成器 G 判别器 D 就是 A 与 B,强化学习的 Actor-Critic 也是 A 与 B。这两个领域的一些方法可通用。
现在也有一些介绍对抗网络的文章,可我没有在里面找到我想看的内容。所以我要写给现在有需要的人。怀着这样的想法,这篇文章的内容变得很长。因此我给出了详细目录,读者可以只看感兴趣的部分。这篇文章我主要从双层优化视角回答 3 个问题,其他部分的内容作为补充:
- 为何原版 GAN 训练不稳定?
- 如何让 GAN 训练稳定?
- 什么时候不能用 GAN?
详细目录
0. 检查自己是否已经入门深度学习(可跳过,被我放在了文末)
1. 入门对抗网络
1.1 公式解读(将数学语言翻译成简体中文)
1.2 图像生成
2. 为何原版GAN训练不稳定?
2.1 梯度消失 vanishing gradient
2.2 模式崩塌 mode collapse
2.3 持续震荡 oscillate over time
3. 如何让GAN训练稳定?
3.1 衡量两个分布的距离
3.1.1 相对熵(KL散度)、交叉熵(cross entropy)
3.1.2 Wassertein距离、梯度惩罚(Gradient Penalty)
3.1.3 谱归一化 (Spectral Normalization, SN)
3.1.4 总结:判别器从Discriminator 转变为 Critic
3.2 在GAN中使用深度学习技巧
3.2.1 上采样该用什么?
3.2.2 优化器该用哪个?
3.2.3 批归一化BatchNorm 该怎么用?
3.3 对判别器的小改进
3.3.1 TTUR (Two Time-Scale Update Rule) 多更新几次判别器
3.3.2 历史缓存 keep the historical buffer
3.3.3 标签平滑与分类
3.3.4 渐进训练 ProGAN
3.3.5 PatchGAN (FCN)
4. 什么时候不能用GAN?
4.1 数据增强
4.2 迁移学习
4.3 超分辨率
4.4 语义分割
4.5 图片修补
5. 对抗网络综述(见附件)
6. 我没有讲的部分内容
6.1 InfoGAN类,生成同一类别下不同的图片
6.2 sinGAN类,小样本学习
入门对抗网络所必要了解的内容都可以在本页面找到。被我删去的基础解释可以在《深度学习》(花书)的合法免费中文版 pdf 里找到。2014 年提出了对抗网络的 Ian Goodfellow 是作者之一。请善用搜索功能 ctrl + F,这是电子版的优势(纸质书做得到吗. jpg)

1. 入门对抗网络
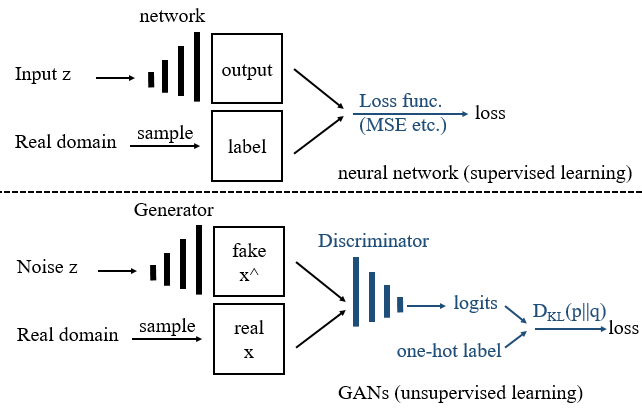
图 1 上方是监督训练,我们需要标记好的成对数据 (input z, label) 用于训练。若泛化性好,那么在没训练过的数据上,神经网络也能输出我们想要的内容。若人类提供不了训练数据,那么一个成熟的神经网络应该学会自己给数据打标签,自己监督自己学习。图 1 下方是用对抗网络实现的无监督训练,我们只需要准备好没有标记过的真实数据 (从 real domain 中抽样 sample 得到) 用于训练对抗网络。
这种从有监督到无监督的跨越是如何完成的?我们把图 1 上方的蓝色部分是一个静态的损失函数(如:均方差 MSE),它被替换为下方的蓝色部分,一个叫判别器 Discriminator 的神经网络。我们让判别器学习辨认真实数据,接着把训练好的判别器和生成器连在一起,这就能用判别器提供的梯度 gradient 对生成器进行优化了。
用判别器提供的梯度 gradient 对生成器进行优化?什么意思?
你可以将判别器放到损失函数的位置上去理解,在对抗网络中,这个静态的损失函数现在被换成一个神经网络。后面的 「1.1 解读对抗网络的公式」会细讲。
我不倾向于从博弈论角度去理解对抗网络。原始的对抗网络中,生成器与判别器会进行一场永恒的对抗。对抗中,生成器学习学习「造假」而判别器学习「鉴别」。在我看来,当生成器生成高质量数据时,判别器不应该坚持认为这种高质量数据与真实数据不同。训练后期还坚持这种对抗思想容易造成训练不稳定。
我将对抗网络理解成:用判别器这个神经网络取代了静态损失函数,从有监督跨越到无监督。经过这种修改,原本对单个网络的优化任务,现在变成对两个神经网络的双层优化任务,由此带来的训练不稳定问题我们后面会解决。
Generative Adversarial Networks 的缩写可以是 GAN 或 GANs。
1.1 公式解读(将数学语言翻译成简体中文)
下面是 对抗网络 2014 原论文 的公式(1),V 表示 value function,D 表示判别器 Discriminator,G 表示生成器 Generator:
max D min G V ( D , G ) = E x ∼ p d a t a ( x ) log [ D ( x ) ] + E z ∼ p z ( z ) log [ 1 − D ( G ( z ) ) ] \max_D \min_G V(D,G)= \mathbb{E}_{x \sim p_{data}(x)} \log [D(x)] + \mathbb{E}_{ z \sim p_z(z)} \log[1-D(G(z))] maxDminGV(D,G)=Ex∼pdata(x)log[D(x)]+Ez∼pz(z)log[1−D(G(z))]
拆开来写(稍有简略):
max D F ( D , G ) = E x ∼ p ( x ) , z ∼ p ( z ) [ log [ D ( x ) ] + log [ 1 − D ( G ( z ) ) ] ] \max_D F(D,G) = ~\mathbb{E}_{x \sim p(x), z \sim p(z)} \bigg[ \log [D(x)] + \log[1-D(G(z))] \bigg] maxDF(D,G)= Ex∼p(x),z∼p(z)[log[D(x)]+log[1−D(G(z))]]
min G f ( D , G ) = E z ∼ p ( z ) [ log [ 1 − D ( G ( z ) ) ] ] \min_Gf(D,G)= ~\mathbb{E}_{ z \sim p(z)} \bigg[ \log[1-D(G(z))] \bigg] minGf(D,G)= Ez∼p(z)[log[1−D(G(z))]]
将数学语言翻译成简体中文:
这里用 F ( D , G ) F(D,G) F(D,G)F(D,G) 表示这是一个用于优化网络的函数、它能提供一个优化目标 objective 。需要传入此优化函数的神经网络是生成器与判别器。因为对抗网络是双层优化结构,所以它还有另一个优化目标 f ( D , G ) f(D, G) f(D,G)f(D, G) ,同理。 max D ( ⋅ ) \max_D(~\cdot~) maxD( ⋅ )\max_D(\cdot) 即 maximize,表示:选用合适的优化器去更新神经网络 D 的参数,让这个被优化的目标的值最大化。min 同理。
这里的优化函数、优化器是什么? 在深度学习中就是优化器 optimizer ,它可以是 Adam、SGD 等。详见 “3.2.2 优化器该用哪个?”
空心的 E ( ⋅ ) \mathbb{E}(~\cdot~) E( ⋅ )\表示求期望。 x ∼ p d a t a ( x ) x \sim p_{data}(x) x∼pdata(x) 表示张量 x 服从真实数据 data 的分布(换句话说:数据 x 从真实数据域从采样得到)。为方便描述,下面我们将来自真实数据的 x 称为 real,将生成器生成的伪造数据 x ^ = G ( z ) \hat{x} = G(z) x^=G(z)称为 fake。
在此公式中,判别器后将输出它认为这个数据来自真实数据的概率。训练良好的判别器当然会认为数据 real 来源于真实数据的概率接近 100%。因此 max D F ( D , G ) \max_D F(D,G) maxDF(D,G) 把判别器的优化目标设置为 “让判别器尽可能做出正确的判断,即将 real 判别为 real,将 fake 判别为 fake”。同理, f ( D , G ) f(D,G) f(D,G) 把生成器的优化目标设置为:让 G 的生成结果尽可能被判别器误认为来自于真实数据,让 G 尽可能生成去可以以假乱真的数据。
对生成器 D 的优化需要将判别器 D 的参数暂时固定下来(或称 冻结参数 freeze),使用从判别器 D 中流过梯度对 G 网络的参数进行更新。
TensorFlow 叫 张量流,我们应该好好体会 “流动” 在深度学习中的意思。
公式中的 - log(pro) 可以用来计算信息的熵。有 -log(100%)→0, -log(0)→ ∞,非常符合常识。下面举一段信息量很大的话作为例子:“当地球上最后一个人独自坐在房间里的时候,外面响起了敲门声。”——只剩最后一个人,因此门被敲响的概率变得很低,当你获知低概率的事件发生时,你一下子获取了非常多的信息,继而你更需要重新调整自己的认知决策。这是我感性地对 “发生概率越低的事件发生了,其信息量越大” 的理解,希望能帮到数学天赋差的人。此外,汉语不适合用来描述数学概念,英语也不适合,最适合描述数学概念的语言是数学语言,所以我一定要在入门教程中讲公式。
1.2 图像生成
为了适应图像任务,DCGAN (Deep Convolutional Generative Adversarial Network) 将
全连接层(full connect layer) + 激活函数 (如 ReLU)
替换为
卷积层(convolutional layer) + 泄露非线性整流单元 (Leaky ReLU)
实际使用时,要用reshape 方法调整维度。
DCGAN 发表那时(2014),大家还热衷于探索激活函数 (activation function),而现在常用的还是:最简单的 ReLU、可用在输出层的 Tanh(-1, 1)、sigmoid(0, 1)、用于分类的 Softmax、用于深层网络的 Switch、Hard-switch、以及来自 Transformer 结构的 GELU。其他的 ReLU 的变体请自行搜索。中间层的激活函数一般用 ReLU,而在深层网络中使用 Switch 或 GELU 可以提高性能。

原始的生成器输入 (n,) 维度的噪声,然后生成 (width, height, channel) 维度的图片,(RGB 图片的通道数 channel 为 3),此时生成器的结构与自动编码器 Auto-encoders 的 解码器 Encoder 结构是相似的。若在此解码器的前方加上编码器 Decoder,则此生成器就能执行 图片到图片的翻译任务 Image-to-image translate(或者说是风格迁移 style transfer)。若是对空间特征依赖程度高的任务,则可以在相同宽度的张量之间加上 short connect (U-Net 的这种思想与残差网络 ResNet 相像)以提升翻译性能。(这一部分是 Pix2Pix 的内容,或称 Conditional GAN)

上图中,我把判别器(分类器)输出的东西称为 logits。
代码里常有logits出现,请自己去弄懂它。
tf.nn.sigmoid_cross_entropy_with_logits(labels=None, logits=None, name=None)
↑
torch.nn.functional.binary_cross_entropy_with_logits()
↑
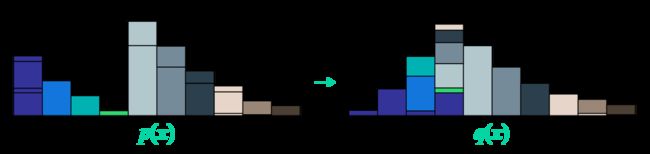
上图中,我将 GAN 原本的 KL 散度换成了 Wassertein 距离,并在 Discriminator 后方标注 Critic,目的是为了表明 Discriminator 已经逐渐从一个分类器 演变成一个评分器 Critic。上图中下方的 FCN 是 全卷积网络 Fully Convolutional Network 的意思。这些都是为了对抗网络能稳定训练而做出的改进,详见「3.3 稳定的判别器」
2. 为何原版 GAN 训练不稳定
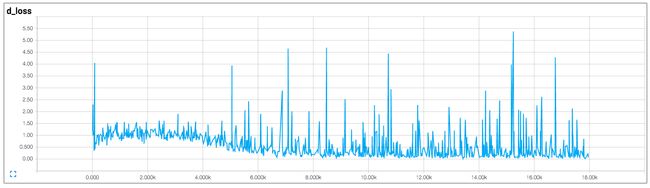
Improved Techniques for Training GANs. 2014. 讨论了许多稳定对抗网络训练的技巧。下面的图 5 是判别损失曲线,Bad Result、Good Result 分别是不稳定、稳定的训练过程。
- 蓝色:判别器 D 在真实数据 real 上的判别损失曲线,数值越小判别越准。
- 橙色:判别器 D 在生成数据 fake 上的判别损失曲线,数值越小判别越准。
- 绿色:生成器 G 的生成数据 fake 在判别器 D 上的判别损失曲线,数值越大,则判别器认为生成图像越接近真实图像。
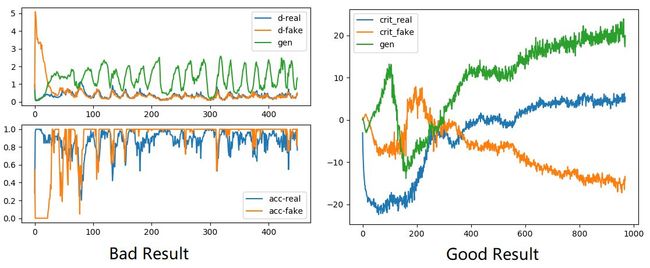
了解对抗网络的人类能根据图 5 左的曲线详述这个不稳定的训练过程:
- 前期,生成的图片非常假,被判别器一眼识破,因而判别器的损失急剧下降到 0,生成器的损失上升到极大值。
- 中期,生成图片的质量逐渐上升,因此生成器损失逐渐回落。同时,判别器的判别难度也不断变高,表现为判别器损失逐渐增加。若此过程可以持续,则模型会逐渐收敛。
- 后期,震荡开始(50~500),训练不稳定。生成器与判别器有一方的损失开始波动。同时或者带动另一方的损失波动。如果用肉眼看生成器的输出,则会观察到生成器生成的图片在较差与很差之间波动。(不收敛 non-convergence,训练后期模型持续震荡 oscillate over time)
当然,上面还不是最差的情况,同样差的情况还有生成器生成单一的图片(模式崩塌 mode collapse )。最差的情况是判别器的损失一直为 0(梯度消失 vanishing gradient),使得生成器也一直生成低质量的数据。
一个稳定的训练过程应该是:
- 判别器能大概率正确识别出 real 的图片(蓝色曲线应该一直处于低值)
- 判别器对 fake 图片的识别正确率不高不低,但是很稳定(橙色曲线)
- 生成器的损失在中期逐渐升高,后期收敛到一个稳定的值(绿色曲线)
然而,曲线稳定只表明训练可以终止,曲线的值不能作为生成图片质量的判断依据,生成器的生成质量与数据质量密切相关,数据质量决定生成器的上限。
评定生成图片的质量:高质量的生成图片,可以让训练良好的分类器正确识别,可以在预训练模型上与真实图片有更接近的感知损失 (perceptual loss),可以让人类觉得像(有的论文甚至雇人用双盲实验评估生成图片的质量),评价生成图片的质量的方法可以搜索最新的开源论文,它们用什么,我们就用什么。
2.1 梯度消失 vanishing gradient
下图图片来自 对抗网络原版论文的图 1,图左 in practically 是我自己加上去的。
- 黑色虚线表示真实数据的分布(虚线表示数据是一个个离散的点)
- 绿色实线表示生成器的生成分布
- 蓝色虚线表示判别器对生成数据的判别分布
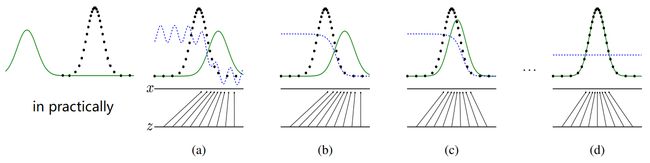
“in practically” 表现了梯度消失时的实际情况。生成器生成的图片的分布于真实数据的分布几乎没有重合。此时判别器非常准确,为所有真实数据输出了 100%,为所有生成数据输出 0%,因此训练不足的生成器无法从过于准确的判别器那里得到合适的优化方向。因而无法完成从 (a)~(d) 的修正过程。具体的表现就是梯度消失 vanishing gradient。
2.2 模式崩塌 mode collapse
这只是训练对抗网络中你会观察到的一种现象,即生成器会因为过于「投机取巧」而生成单一的数据。也就是生成器会将不同的输入 z 映射到少数几个 x 上面去。

2.3 持续震荡 oscillate over time
这是训练对抗网络中你可能会观察到的一种现象,即生成器与判别器的损失函数周期性震荡,输出的生成数据的质量也周期性变化。请注意,batch size 足够小时也会引起 loss 的小幅度波动,但这种现象与周期性震荡导致的不收敛不同,它们没有周期性,且生成图片的质量也不会变差。
原版的对抗网络训练不稳定有两个主要原因:训练不平衡。双层优化不稳定。可以说这些问题导致了对抗网络的训练不稳定。已发表的 GAN 变种众多,而青史留名仅有几种。下面提及的算法均为稳定训练做出巨大贡献。
3. 如何让 GAN 训练稳定
3.1 衡量两个分布的距离
我们需要一个衡量两个分布 p、q 的相似程度的函数 D ( p ∣ ∣ q ) D(p||q) D(p∣∣q)D(p||q) 。当两个分布完全相同时输出 0,分布差异越大则输出的数值越大。也可以说它输出两个分布之间的「距离」。以下内容只是对这篇写的很好的文章 “交叉熵、相对熵(KL 散度)、JS 散度和 Wasserstein 距离(推土机距离)” 的简要概括,详细内容移步原文。
3.1.1 相对熵 (KL 散度)、交叉熵 (cross entropy)
原版的对抗网络用 KL 散度衡量两个分布之间的差异。我不喜欢 KL 散度这个译名,我们应该利用汉字命名能携带密集信息的优势将它称为「相对熵 / 相对散度」:

式子的前部分 − H ( p ( x ) ) -H(p(x)) −H(p(x))在对抗网络中是不变的,因此我们关注的后半部分可以单独拿出来讨论。后半部分就是我们熟悉的「交叉熵 cross entropy」:
H ( p , q ) = − ∑ i = 1 n p ( x i ) log ( q ( x i ) ) H(p, q) = -\sum_{i=1}^{n} p\left(x_{i}\right) \log \left(q\left(x_{i}\right)\right) H(p,q)=−∑i=1np(xi)log(q(xi))
容易看出 D K L ( p ∣ ∣ q ) ≠ D K L ( q ∣ ∣ p ) D_{KL}(p||q) \neq D_{KL}(q||p) DKL(p∣∣q)=DKL(q∣∣p) ,即 KL 散度是不对称的。但距离怎么可以不对称呢?于是对抗网络开始改用 JS 散度:
D J S ( p ∣ ∣ q ) = 1 2 ( D K L ( p ∣ ∣ m ) + D K L ( q ∣ ∣ m ) ) , m = p + q 2 D_{JS}(p||q) = \frac{1}{2}\bigg( D_{KL}(p||m) + D_{KL}(q||m) \bigg), ~m = \frac{p+q}{2} DJS(p∣∣q)=21(DKL(p∣∣m)+DKL(q∣∣m)), m=2p+q
JS 散度只是对相对熵 KL 散度的一种小改进。构造出一个分布 p + q 2 \frac{p+q}{2} 2p+q 充当比较介质后,JS 散度是对称的。(个人看法:我不喜欢 JS 散度,它只是强行满足了对称强迫症而已,梯度消失的问题、训练不稳定的问题依然没有解决)我们需要新方法去衡量两个分布的距离 。
3.1.2 Wassertein 距离、梯度惩罚 (Gradient Penalty)
- 令人拍案叫绝的 Wasserstein GAN - 郑华滨 2017-02
- 从 Wasserstein 距离、对偶理论到 WGAN - 苏剑林 2019-01 (推荐去看)
- How to Develop a Wasserstein Generative Adversarial Network (WGAN) From Scratch - Jason Brownlee 2019-07 (需要)
如果将上述比喻中的 “货物” 换成 “沙土”,那么 Wasserstein 距离就是在求最省力的“搬土” 方案了,所以 Wasserstein 距离也被称为“推土机距离”(Earth Mover’s Distance)。---- 这复了制苏剑林介绍 WGAN 的文章内容。
有了推土机距离,对抗网络在训练初期再也不用担心梯度消失了。训练中的对抗网络对生成器与判别器的训练不平衡的容忍程度更高,是对抗网络的一大进步。判别器在它的帮助下得以为生成器提供更加良好的梯度。尽管它并没有完全解决对抗网络的收敛问题。
后来还发展出了 WGAN-GP(Wassertein GAN with Gradient Penalty 梯度惩罚),详细介绍可以看它→ WGAN-GP 方法介绍 - AI 搬运工 。简单地说:WGAN 大家在小数据集 mnist 上用得不错,然而当数据集变大,判别器层数加深之后,训练后期 WGAN 不容易收敛。于是想到要为 WGAN 中判别器提供的梯度增加一个惩罚,即:将梯度的 L2 范数要约束在 1.0 附近。WGAN-GP 带上梯度惩罚后后,训练速度有所增加,但依然不稳定。
参考资料: 机器学习算法实践 - 岭回归和 LASSO - 邵正将 2017-10
3.1.3 谱归一化 (Spectral Normalization, SN)
谱归一化(或者叫 谱范数正则化,这是更好的翻译)它继承了 WGAN-GP 的一部分思想,也对判别器提供的梯度进行约束,它另辟蹊径:通过估算并除以某一层神经网络的谱范数,使这一层神经网络的最大导数就变为 1(即符合 1-Lipschitz 连续 1-Lipschitz continuity),让这层网络函数变得光滑。
相差无几的输入会对应相近的输出,这与人类的直觉相符合:若两张图片差不了多少,那么我们对这些图片的直观感受也是接近的。而训练不好的神经网络它会做出让人类匪夷所思的判断:例如对两张差不多的图片输出完全相反的结果。符合 1-Lipschitz 连续(或者说 1-Lipschitz 约束)的光滑网络函数不容易做出这种判断。

论文使用 幂迭代法 Power Iteration 估算谱范数,减少计算耗时,在深度学习框架中(PyTorch,TensorFlow1,TensorFlow2),经常能看到谱归一化有超参数 iter number 用来调节迭代次数,默认是 1,足够了。详细推导移步→ Spectral Normalization 谱归一化 - 尹相楠 2019-05
3.1.4 总结:判别器从 Discriminator 转变为 Critic
- WGAN:将交叉熵改为推土机距离 (Earth’s Mover Distance, Wassertein 距离)
- WGAN-GP:梯度惩罚 Gradient Penalty(对判别器提供的梯度的范数进行约束)
- SN:谱归一化 Spectral Norm(对网络权重使用谱范数进行规范化)
谱归一化(一般是在判别器中使用),发展到这里,我们其实应该把 判别器 Discriminator 称为 Critic(评分器?我不知道如何翻译比较好,强化学习里也是 Actor-Critic)。
原本在对抗网络的博弈论思想中,他们把生成器与判别器的组合优化过程视为两个网络相互对抗的过程。现在我们可以将判别器视为 Critic,它不再输出「概率」,而是输出「评价、评分」,分数越高则表明判别器 Critic 对生成器的生成数据评价越高。
判别器 Discriminator 的任务是正确判别 fake 与 real,这个目标将会在训练后期加重判别器与生成器的对抗,造成训练的不稳定。而将判别器视为 Critic 可以减弱两个网络之间的对抗属性,输入 critic 的数据与真实数据越接近,则 critic 将会认为它与真实数据的「距离」越近。双层优化中的两个网络不再拥有相互冲突的优化目标。
我个人认为:深度学习的一些跨越是从用神经网络取代经典结构做出的,例如:
对抗网络 GAN,用 Discriminator 取代 静态的损失函数
强化学习 DQN,用 Q Network 取代 Q table
强化学习 DPG,用 Policy Network 取代 argmax (Greedy-policy)
…
3.2 在 GAN 中使用深度学习技巧
3.2.1 上采样该用什么?
用不严谨的说法帮助理解:我们直接用双指放大、缩小一张图片(位图)的 resize 操作就是一种升采样、降采样的方法。在通道数不变时,降采样会丢失数据,升采样会让数据增加(普通的 resize 通过插值放大图片)。而自动编码器的降采样伴随着通道数的增加,信息被尽可能保留,因而数据可以在分解后尽量重构复原。(分解,重构——Edward Elric)
如图 4,编码器 Encoder(蓝色)需要对张量进行降采样 (downsample),可用以下方法:
- 二维卷积层 Conv2D,并设置步长大于 1
- 二维卷积层 Conv2D,设置步长为 1 但是使用 最值池化 (MaxPooling) 或者均值池化(即 resize 方法)
如图 4,解码器 Decoder(红色)需要对张量进行升采样 (upsample 上采样),可用以下方法(有些方法被不严谨地称为反卷积 (Deconvolution 逆卷积)):
- resize:基于插值放大图片,再接上普通卷积层。计算量稍大,不容易有棋盘纹理
- Transposed Conv2D:转置卷积,并设置步长为 1/2 之类的数(有时也直接说 2)
- PixelShuffle:像素重新排列,先用普通卷积提升通道数,然后使用 reshape
棋盘纹理 (Checkerboard Artifacts) 因为卷积对齐而产生的人造痕迹。 Deconvolution and Checkerboard Artifacts - AUGUSTUS ODENA Google Brain - 2016-10(非常好的文章,甚至有网页互动帮助理解) ,棋盘纹理 (Checkerboard Artifacts) 是一类伪影。
伪影 (blocking artifacts) 其实就是生成图片中,能让人类能看出是生成图片才会有的伪造痕迹。伪影是很主观的感受。

下图是 StyleGAN 的人脸生成结果。用于训练人脸的图片中,耳朵下方有会有耳环的干扰,生成图片的耳垂附近会有伪影(经常做对抗网络图片生成的人会对这些地方比较敏感),这个人类的衣服也不对称(左边露出肩头),牙齿之类更是老生常谈。StyleGAN 这方面已经很好。

了解了降采样与各种上采样后,你还可以进一步了解 FPN (Feature Pyramid Network 特征金字塔网络),关键词 “多尺度特征识别”,这个结构也能用来改进 GAN。薰风读论文:Feature Pyramid Network 详解特征金字塔网络 FPN 的来龙去脉 2019-08
3.2.2 优化器该用哪个?
在 Adam 优化器出来后,就有很多文章自称 “拳打 Adam,脚踢 SGD + 动量”,如下
机器之心(的捧杀标题):速度媲美 Adam,性能堪比 SGD:北大、浙大学霸本科生提出全新优化算法 AdaBound 2019-02
单从这个标题提供的信息,你无法快速确定 AdaBound 是否好用,但是你能确定 “被他们当靶子的 Adam 必定训练速度快 以及 SGD 必定训练效果好”。若你想要了解 AdaBound 是否真的适合自己,那么 知乎 如何评价优化算法 AdaBound? ,就回答和 Reddit 讨论认为 AdaBound 在论文使用的小数据集上的表现名副其实,在 ImageNet 上不尽人意
Adam (Adaptive Moment Estimation) 结合了之前各种优化算法的优点,在性能不差的情况下训练快,对初始超参数不敏感。**SGD(stochastic gradient descent 随机梯度下降)**训练效果好,速度慢,加上动量 momentum 后快一点,不易陷入局部最优,在大数据集上可以用它得到更好的结果。各有千秋,按需选用。
Adam 本质上是带有动量项的 RMSProp——深度学习最全优化方法总结比较(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam) - 余昌黔 2016-09(推荐)
常有人推荐在对抗网络中使用 RMSProp 取代 Adam,而我坚持使用 Adam,理由:
- 尽管我认可「RMSProp 适合处理非平稳目标」。然而近几年大家逐渐驯服 GAN,现在训练 GAN 不再需要处理那么不平稳的目标
- Adam 本质上是带有动量项的 RMSProp。把 Adam 的超参数 beta 从默认的 (0.9, 0.999) 调整为 (0.5, 0.999) 能强行得到 RMSProp 的效果。况且目前(2020-07)PyTorch 的 torch.optim 下面只能找到 Adam 和 SGD+Mo 两种默认的优化器。
All models were trained with mini-batch stochastic gradient descent (SGD) with a mini-batch size of 128 — Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks, 2015.
Specifically, the Adam version of stochastic gradient descent was used to train the models with a learning rate of 0.0002 and a momentum (beta1) of 0.5.
We used the Adam optimizer with tuned hyperparameters. We found the suggested learning rate of 0.001, to be too high, using 0.0002 instead. Additionally, we found leaving the momentum term β1 at the suggested value of 0.9 resulted in training oscillation and instability while reducing it to 0.5 helped stabilize training. — Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks, 2015.
Tips for Training Stable Generative Adversarial Networks by Jason Brownlee on June 19, 2019, 5. Use Adam Optimization
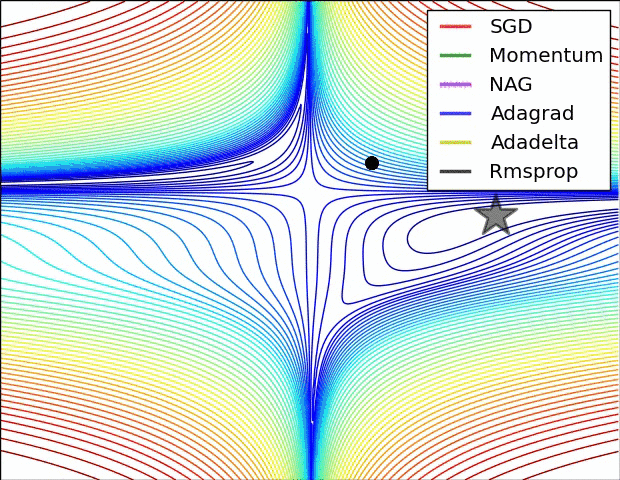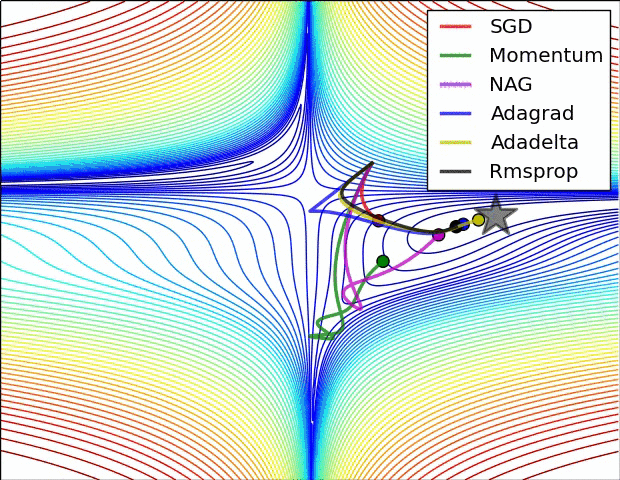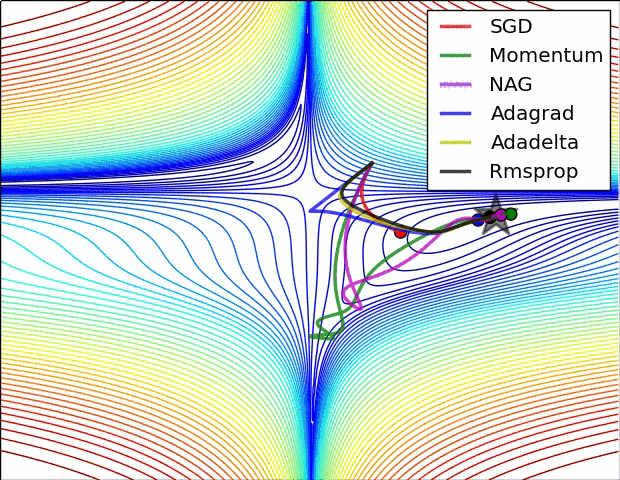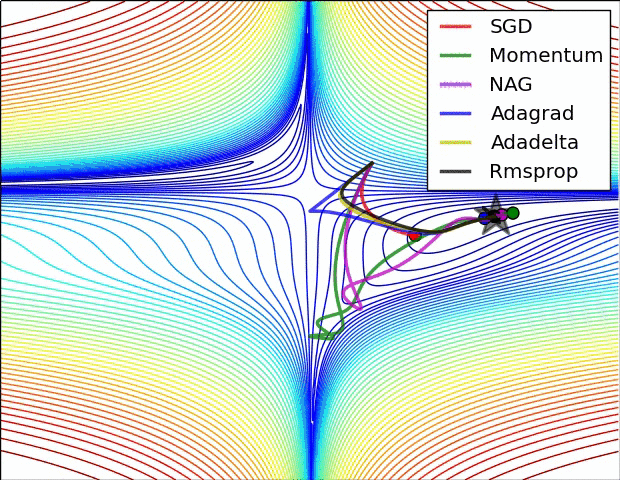
3.2.3 批归一化 BatchNorm 该怎么用?
在对抗网络中,BatchNorm 应该加在何处(应该放在卷积层之前,或是卷积层之后)?(ReLU 可换成其他激活函数)
- BatchNorm + Conv2D + ReLU
- Conv2D + BatchNorm + ReLU
答案是第一种。尽管这不需要做实验就能判断,但是好奇的我已经通过实验在对抗网络的图片生成任务上验证过了(其实两种方法差别不大)。「白化 whitening」是一种数据预处理步骤:对原数据进行规范化处理,减去均值除以方差。用接近正态分布 N(0, 1) 的数据去训练神经网络往往能得到更好的效果,具体到每一层的神经网络也是如此,因此 Batch Norm 应当加在卷积层之前。
不只是对抗网络,在深度学习中,计算资源充足时,加入几层 BatchNorm 可以显著地加快训练速度。相同时间内更容易得到性能更好的模型。在 batch size 较小的情况下,张量的均值与方差不稳定,这个问题曾经影响了 BN 的性能,但是现在的 BN 已经可以自行计算一段时间内的 std 和 mean 并得到稳定数值,在 batch size 较小时也能使用。不过要注意训练时 BatchNorm 是默认打开的,在推理的时候要主动关掉对 BatchNorm 的训练,不然 BN 训练好的均值与方差会变化。(PyTorch 里面就是 model.tran() 和 model.eval() 的区别)

想要了解更多请看:
BatchNorm 是什么? Batch Normalization: Accelerating Deep Network Training b y Reducing Internal Covariate Shift. 2015.
BatchNorm 是如何发挥作用? Batch Normalization is a Cause of Adversarial Vulnerability. 2019.
也有不该用 Batch Norm 的时刻,例如用对抗网络做超分辨率。
Since batch normalization layers normalize the features, they get rid of range flexibility from networks by normalizing the features, it is better to remove them.——超分辨率 EDSR. 2017.
Deep Multi-Scale Convolutional Neural Network for Dynamic Scene Deblurring. CVPR. 2017
EDSR - Enhanced Deep Residual Networks for Single Image Super-Resolution. 2017-10
3.3 对判别器的小改进
下面是稳定对抗网络训练的小技巧(trivial trick):为了稳定对抗网络的训练,同时使用多个改进才能得到立竿见影的效果。这些技巧对于双层优化问题也是通用的(对抗网络与强化学习)。我个人认为对抗网络训练不稳定的源头是判别器不稳定,以下的方法几乎都在改进判别器:
3.3.1 TTUR (Two Time-Scale Update Rule) 多更新几次判别器
生成器需要一个训练良好的判别器提供正确的梯度进行优化。由于生成器不断地生成新的数据用于判别器的训练,因此判别器容易欠拟合,因而多更新几次判别器可以减少判别器的梯度噪声。TTUR 的思想简单且有效。减小生成器的学习率也是如此(然而在 Adam 等自适应的优化方法中,减小学习率等不太有用)。刚入门对抗网络的人也能独立地提出与 TTUR 相同的想法。
3.3.2 历史缓存 keep the historical buffer
造成对抗网络训练震荡的原因还有一个:判别器是健忘的。如下图是对 WGAN 的四个生成阶段的截图。人类可以轻易的判断出靠右的 MNIST 生成图片质量好。而判别器在训练前期学习认出低质量的图片。等到了中期,它也学会了识别中等质量的图片。当判别器拿着真实图片与中等质量的图片学习时,生成器已经不再生成低质量图片(如上图最左),糟糕的事情发生了,判别器会将遗忘学过的内容。有时候震荡发生时,判别器会错误地给这些低质量图片一个过高的分数(你们可以自行验证)。

如此一来,一部分震荡的原因得到了解释:训练中期,判别器在中质成图片和真实图片上进行训练,失去了识别低质量图片的能力。健忘的判别器会为生成器提供错误的优化梯度,导致生成器生成低质量的图片。此时,终于有低质量的图片补充到训练数据中,判别器又得以重新学习识别低质量图片,循环往复,持续震荡,就是没法输出高质量的图片。初学者容易自己总结出此推论。
解决方案也简单,我们可以保存历史的判别器,然后综合不同判别器的意见,为生成器提供正确的梯度。或者我们可以主动保存历史生成的低质量、中质量图片,用于判别器 critic 的训练。当然可以在小数据集上,WGAN 等算法可以不用这种方法,等到数据量增大时就不得不用了。强化学习的 experiment replay buffer 与此想法不谋而合。刚入门的人也能独立提出与历史缓存相同的想法。
3.3.3 标签平滑与分类
前面已经说到,我们不要再将判别器视为一个与生成器「对抗」的网络 Discriminator ,而是把它看成一个为标签「无监督打分」的网络 Critic。其实这种趋势早在多年前就显现了。当时发现进行标签平滑 (real=1.0, fake=0.0) 改为 (real=0.9, fake=0.1) 效果更好,甚至为标签加一点噪声也行。
原本判别器只是一个二分类的分类器(输入图片来源于真实数据的概率)。后来发现直接把判别器当分类器更好,判断图片真伪的同时也顺便判断它的类别,这样模式崩塌 mode collapse 问题也能得到缓解。若生成的图片质量很低,则分类器会输出一个接近 0 的张量(记得把输出层的 softmax 移除),表示这张我认为是伪造的图片来源于每个类别的概率都很低。甚至用带噪声的标签让生成器生成指定类别的数据。后来有更多的变种,其思想都是接近的。刚入门的人也能独立提出与之类似的想法。
3.3.4 渐进训练 ProGAN
不同数据集的图片内容、图片尺寸、数据总量、类别数量
----------------------------------------------------------
Dataset ImageSize 描述
----------------------------------------------------------
MNIST 28 手写数字,60,000张,10类,灰度图
MNIST-fashion 28 潮流服饰,60,000张,10类,灰度图
CIFAR-10 32 普通图片,60,000张,10类,RGB通道
ImageNet 256 普通图片,14,000,000张,20,000类
CelebA-HQ 1024 人脸图片,30,000张,高清
当我们生成大尺寸的图片时,即便使用改进版的对抗网络,模型的训练也很困难。训练前期,判别器轻易地学会辨别大尺寸的生成图片,导致它无法给生成器提供可用的梯度,生成器迟迟无法生成能看的图片。所以我们用渐进式训练解决此问题:先生成小尺寸的图片,逐步生成大尺寸的图片。尽管这种想法刚入门对抗网络的人容易想到,但是它的代码实现难度不低,对性能有大影响的实现细节也特别多。ProGAN (Progressive GAN) 就做了这么一件事。
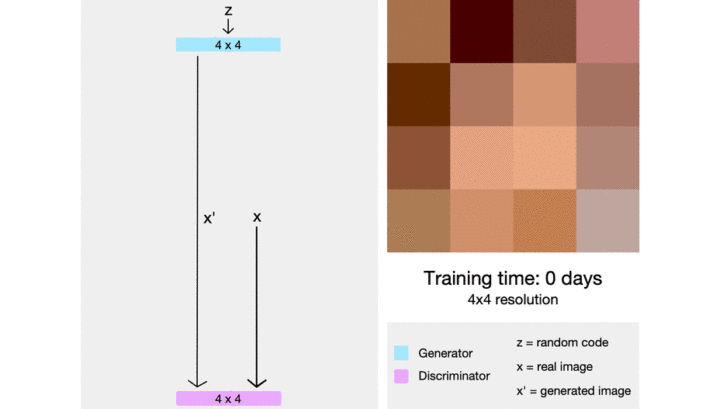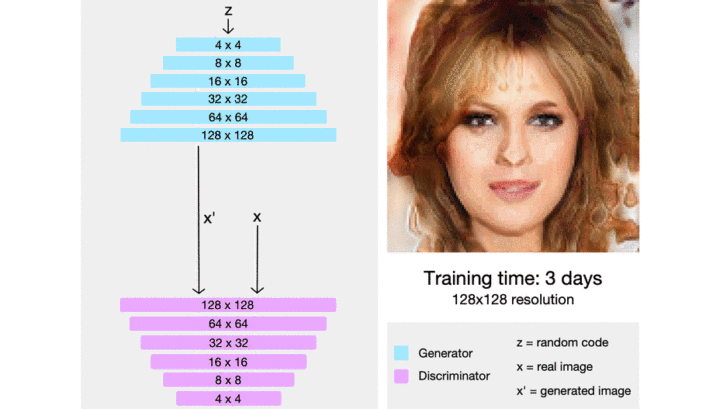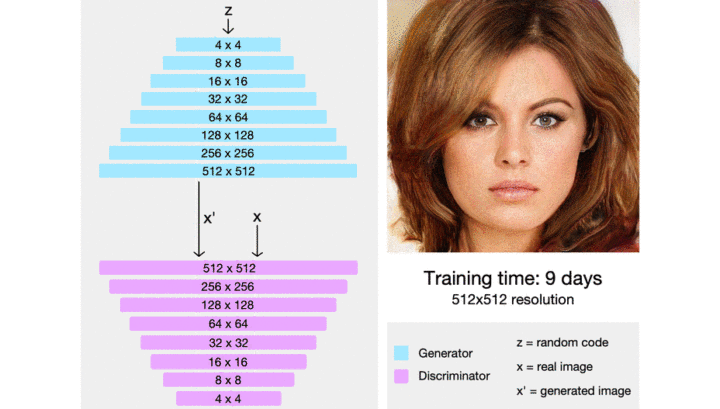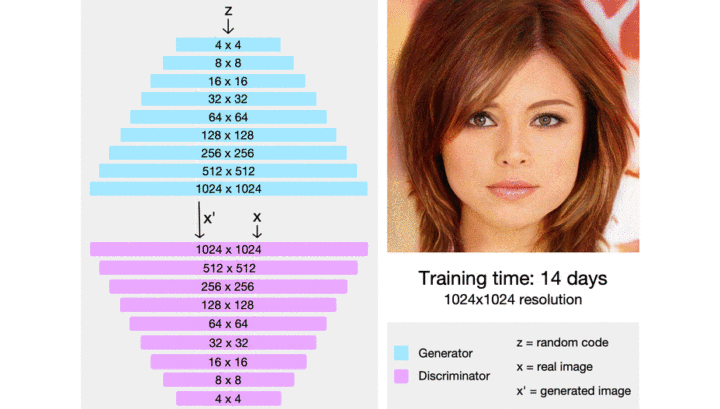
后来 NVIDIA 还接着 ProGAN 继续发了 styleGAN,styleGAN2。如果你希望复现最为扎实的工作 solid work(不希望复现不出来,又希望能复现到较新的 GAN),那么你可以选择他们的代码,你可以从他们的成熟代码中找到经过验证的抗网络训练技术。最近也有对渐进式训练的改进,如 CVPR2020 之 MSG-GAN:简单有效的 SOTA?
其实就是白嫖 Google,FAIR,NVIIDA,OpenAI,DeepMind,以及商汤、旷视的网络框架。若你在偏门的图像领域(例如医疗,地理等)看到一些新发布的图像论文使用非主流框架,或者旧框架,且不开源,那么你就要警惕,珍惜精力与时间。
此外,如果你希望了解在数据量大的情况下对抗网络应该如何使用,那么 DeepMind 2019 年的 BigBiGAN 就是在 ImageNet 上训练的(是 2019 年最好的表示学习模型),可能他们的工作更适合你(但是需要看入门教程的人,应该连跑一下他们的预训练模型都不行吧,你们可以先记着这些工作的名字,进阶后再去了解)

3.3.5 PatchGAN (FCN)
当生成的图片过大时,可能生成的图片中只有局部区域存在伪影,而其余部分生成质量很好,此时若让判别器对整张图片进行判断,那么一个单一的数值可能无法良好地描述这张图片的质量。 PatchGAN 把一张完整的待鉴定图片利用滑动窗口裁剪成 70x70 大小的小图片。接着将这些图片依次输入判别器进行鉴定。最后将判别器对多张小图的评分求和,作为最终评分。
我的看法:这种结构和 FCN 全卷积网络 Fully Convolutional Network 不谋而合,若在 FCN 感受野达到 70x70 的那一层进行 均值池化,则其效果与 patchGAN 是类似的,甚至用 FCN 更好。
4. 什么时候不能用 GAN
数据量小的时候,请谨慎使用对抗网络。我希望用十分具体的案例进行分析,我不下结论,我只列出做相关项目前必须想清楚的点:
4.1 数据增强
场景:我拥有 1 万张胸腔的 CT 图片(90% 的图片是正常人的胸腔),否可用对抗网络去生成新的胸腔图片用于数据增强?
考虑到 StyleGAN 用 3 万张高清人脸图片做图片生成任务,因此 1 万数据足矣,可以用 GAN 完成此生成任务。但是,这些生成图片是否可以用于数据增强 (Data Augmentation)?对抗网络的图片生成结果并不一定都是好的结果。在数据不足的情况下更是如此,甚至生成数据的多样性得不到保障。(若你数据充足,那么为何还需要数据增强呢?)
能否在生成图片上进行 “随机截取,轻度拉伸” 这些数据增强操作?若真实图片可以,那么生成的图片也可以,只是这样做意义很小:生成的图片已经是真实图片的衍生品了,对生成图片做数据增强会得到衍生品的衍生品,其效用必定大打折扣。
4.2 迁移学习
值得注意的是,上面的各种操作的初始真实数据一直是那 1 万张胸腔的 CT 图片。然而深度学习是数据驱动型算法,无论算法有多好,数据不够就是不够。想要发挥深度学习的优势,可以把原本用不了的数据也利用起来:
尽管只有 1 万张胸腔的 CT 图片可以用于训练某个模型,可我还有其他类型胸腔 CT 图片 9 万张。那么我可以拿所有的 10 万张真实图片(尽管不都是我需要的类别,但是它们都是胸腔图片)去训练对抗网络,让它按类别生成图像。甚至可以在 10 万张图片上进行预训练,然后用迁移学习的方法在 1 万张图片上训练。
4.3 超分辨率
对医疗图片进行超分辨率是否有意义?
首先,对风景图片进行超分辨率是很有意义的,此场景下对复原的准确性无苛刻要求,只是希望生成一张能瞒过人类的图片而已。然而,对医疗图片进行超分辨率就很值得推敲了,清晰度高的真实图片能帮助医生更好地诊断病情,而超分辨率的生成图片其准确性没有保障。
请思考:若有两张不同的大尺寸真实图片,其降采样得到的小尺寸图片完全一致,那么生成器作为一个函数,怎么可能把丢失信息的一张小尺寸图片映射成两张不同的大尺寸图片呢?这些都是踏入此研究领域的人需要直面的问题。

机器之心:高糊马赛克秒变高清,「脑补」面部细节,表情帝:这还是我吗? ,介绍了论文 PULSE. 2020. PULSE: Self-Supervised Photo Upsampling via Latent Space Exploration of Generative Models 的工作
4.4 语义分割
用对抗网络的风格迁移技术对医疗图片进行无监督的语义分割,如何做?
我非常关注「用对抗网络进行无监督语义分割」,简单思路是:将真实图片作为风格 A,将标签图片作为风格 B,训练一个对抗网络进行风格迁移,将风格 A 迁移到风格 B(当然你可以选用 Pix2Pix、cycleGAN 等算法)。以往我们需要标记正确的图片对 (a, b) 用于训练,现在我们只需要准备 A、B 两类图片就可以了,对抗网络将会自己学习语义分割。
但是我直到 2019 年 10 月也没有见到 solid work,主要难点是:
- 从真实图片到标签时,生成器的确能生成标签风格的图片,但是它不一定会打出你想要的标签,有时候生成的图片可能与输入的图片没有很强的联系,尽管有一些工作在 Cityscapes 这种简单的数据集上成功了,但是急需此类技术的正是那些比较难的领域。许多工作都是 Pix2Pix plus++。
- 的确用 cycleGAN 能完成空间位置有较强联系的图片到图片的翻译任务,但是从真实图片到标签是一个信息丢失的过程,因此 cycleGAN 从 A→B 易,从 B→A 难。
想要了解更多可以参考:
CycleGAN 论文的阅读与翻译,无监督风格迁移
4.5 图片修补
图片修补 EdgeConnect 论文的阅读与翻译:生成边缘轮廓先验,再填补缺失内容
与医疗图像相比,在普通图片上进行此类研究要更容易,因为数据容易获取,数据量更多,数据标签噪声小,复现的人多。因此我认为「无监督语义分割」在难度较低的 CV 领域取得的重大突破更有可能。这只是我个人的看法。这里还是把问题抛给即将尝试将对抗网络用在医疗图片领域上的研究人员:如果你们在医疗图片领域做出了成果,那么请考虑将这些技术推广到普通的 CV 领域来。U-Net 和 TTUR 都勉强算是先应用在生物领域的技术。若一项技术在医疗图片上有效,那么它在普通图片上也是有效的。若一篇论文没有(或者说不敢)将其在医疗图片上取得的进展主动在普通图片上进行测试,那么这是什么原因呢?
希望医疗图片领域的学生思考这个问题:当你复现一篇论文时,无论这篇文章发表在了哪里,若此论文开源代码差,不公开数据,使用的技术旧,文章效果好(甚至自称超越 ICE 顶会的 SOTA),那么我希望你珍惜自己的时间与精力,谨慎地安排下一步的工作计划。
5. 对抗网络综述(见附件)
我个人的看法是:相比 2019 年之前的几年,对抗网络的发展已经放缓,我上面讲的东西几乎都是 2018 年前的。若对抗网络领域出来什么东西能令我惊讶,那么应该是 few-shot 小样本这一块的内容吧。对抗网络前沿我讲不了,下面是一些对抗网络综述或者汇总,旧的综述比较经典,新的综述我没有找到特别好的:
- NIPS 2016 Tutorial: Generative Adversarial Networks - Ian Goodfellow. 2016. OpenAI (有点旧,鸡肋)
- Connecting Generative Adversarial Networks and Actor-Critic Methods 2016 (NIPS GANs Tutorial 在章节 5.6 Developing connections to reinforcement learning 提到它了,我个人很喜欢这篇文章,但是这篇文章讲的是双层优化)
- Improved Techniques for Training GANs - 2016-10 - OpenAI(有点旧,鸡肋)
- GAN 万字长文综述 - 邛亦简,写于 2017(虽不够新,尚可看)
- 学点诗歌和 AI 知识:超 100 篇!CVPR 2020 最全 GAN 生成对抗网络论文汇总!(可看)
- Recent Advances of Generative Adversarial Networks in Computer Vision. IEEE. 2019-02(较新,可看,见附件 “对抗网络在 CV 的综述 IEEE 2019-02”,因为知乎用的是百度网盘,若你无法去官网下这篇综述,你可以从下面↓ 这里下载)
我没有找到合适入门对抗网络的资料,无可奈何,只能自己写了,你现在看的这篇就是。对抗网络中,我特别关切的问题依然没有被解决,所以我已经充满遗憾地去做强化学习了,反正它(的 Actor-Critic Methods)和对抗网络一样都是双层优化问题。
推荐代码(比较全面的 GAN 及其变种的代码,用不同深度学习框架去实现):
- 用 PyTorch 的 GAN 实现(包含有) -《深度学习:入门与实战》
- 收集了 PyTorch 的 GAN 代码网址 - eriklindernoren PyTorch-GAN
- 用 Keras 的 GAN 实现 - eriklindernoren/Keras-GAN
- 收集了各种 GAN 的代码网址 - the GAN Zoo
抱歉,TensorFlow 的实现我没有怎么用过,可能是因为 DeepMind,Google 或者 NVIDIA 他们作者自己就是用 TensorFlow 实现的,一般可以通过论文直接找到作者自己发布在 Github 的实现。有许多好用的库我没有用过,所以没有列出。
6. 我没有讲的部分内容
6.1 其他图片生成算法
对抗网络在图像生成任务上大放异彩的同时,也有其他算法:
- VAE 变分自编码器 Variational Auto-Encoder (生成的图片一般比较模糊)
- NVAE Hierarchical VAE,它从对抗网络学了很多东西,例如你能看到它用了谱正则化。强大的 NVAE:以后再也不能说 VAE 生成的图像模糊了 2020-07
- VQ-VAE Vector Quantized AE(虽然叫 VAE,但它没有变分的思想,只是 AE,且在参数很多的瓶颈层使用了自回归 AutoRegressive),跟风解读强大的生成模型 VQ-VAE-2 2019-06
其他对抗网络变种:
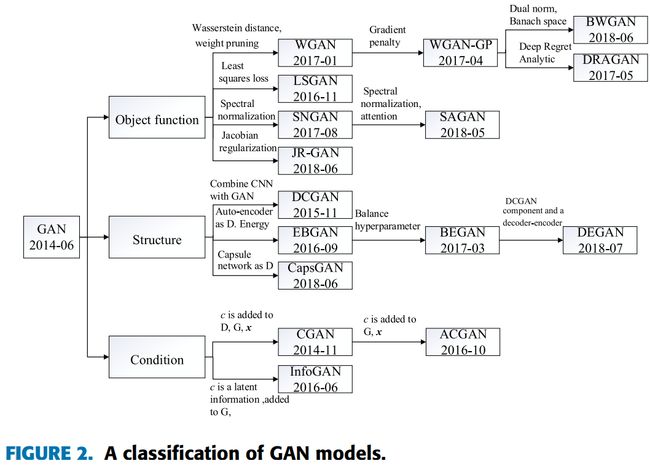
6.1.1 InfoGAN 类,生成同一类别下的不同图片
GAN, different, angle:使用对抗网络根据生其他角度的图片,可以是人脸,行人,或者普通物体(我复现过几篇,泛化性差),基本上是 infoGAN 的接棒者 经典论文复现 | InfoGAN:一种无监督生成方法 2018-10 ,InfoGAN — Generative Adversarial Networks Part III(需要)


6.1.2 sinGAN 类,小样本学习
GAN, few-shot, generate, realistic:小样本学习,如:sinGAN 可以针对单个样本进行学习,见 ICCV2019 最佳论文奖 SinGAN(一)原理剖析 - 2019-12

7. 检查自己是否已经入门深度学习(可跳过)
入门深度学习我的标准是:参考其他资料,自己挑选算法,在 MNIST 测试集上调整超参数,最后在验证集上达到 98% 的准确率(设备性能差则降低此标准)。看到程序 print 出 >98% 的准确率后,尝试回答:
- 如何正确使用训练集,测试集,验证集?(机器学习入门)
- 调整哪些超参数会对算法产生何种影响?(深度学习入门)
若答不出来,请反思并静下心来打基础。以下是我的回答:
7.1. 如何正确使用训练集,测试集,验证集?
在《深度学习》花书的 5.3 节 “超参数和验证集” 提及了:训练集,测试集,验证集的比例可为 60%,20%,20%。先使用 60% 的训练集进行训练,画出下图。你可以用相同方法调整其他超参数。
《深度学习》 Ian Goodfellow etc.(他也是对抗网络的作者) 中文版 pdf(俗称花书)
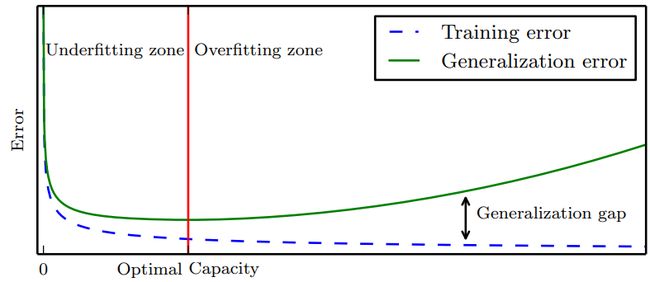
根据测试集调整超参数后,你需要将训练集与测试集合并,将这 80% 的数据用于训练,此时你可以适当地增加训练次数,完成训练后,在验证集上进行验证,若准确率超过 98%,那么你就完成入门了。请思考**为何非要有 “训练集,测试集,验证集” 这 3 个集:**简而言之,要避免在验证集上过拟合以保证模型的泛化(Generalization)。
7.2. 调整哪些超参数会对算法产生何种影响?
可以调节的超参数太多了,以前 自动机器学习 Auto Machine Learnng 甚至 网络架构搜索 Neural architecture search(NAS) 还没有长大,总有人沉迷调整超参数涨点(俗称炼丹)。初学者不应该沉迷在这种虚假的快乐中,还有更难的等着你们去学。调参方面总结基本规律才重要。
在 MNIST 数据集含有 60,000 个样本。可用于训练的有 50,000 个。以 batch size 为例:batch size 为 4 时,训练期间准确率有明显的波动,这是因为 batch size 过小导致梯度信息受个体样本影响大,不容易学到整体规律。batch size 为 1 万时,即便增加训练次数,错误率也无法下降到令人满意的数字,这是 batch size 过大,网络不容易学习数量稀少的难样本,并且有一些鞍点也因为批次过大而无法快速绕过。
缓慢增加或衰减某些超参数(甚至退火、循环)也能涨点。此时我们要将实验现象与理论原理联系起来,练习在调优前**预测调优后模型的变化,**而非沉浸在涨点中傻笑。还有很多要学,不按顺序边看边学也行,因人而异。