【sklearn】sklearn中的交叉验证
sklearn中的交叉验证
1、交叉验证的思想
把某种意义下将原始数据(dataset)进行分组,一部分作为训练集(train set),另一部分作为验证集(validation set or test set),首先用训练集对分类器进行训练,再利用验证集来测试训练得到的模型(model),以此来作为评价分类器的性能指标。
2、使用交叉验证法的理由
-交叉验证用于评估模型的预测性能,尤其是训练好的模型在新数据上的表现,可以在一定程序熵减少过拟合。
-交叉验证还可以从有限的数据中获取尽可能多的有效信息
3、model_selection.KFold 和 model_selection.cross_val_score的区别
KFold 就是对数据集划分为 训练集/测试集,然后将训练数据集划分为K折,每个折进行一次验证,而剩下的K-1 折进行训练,依次循环,直到用完所有的折。
而 cross_val_score 就是通过交叉验证评估得分。
K折交叉验证函数KFold函数:
KFold(n_split, shuffle, random_state)
参数:n_split:要划分的折数
shuffle: 每次都进行shuffle,测试集中折数的总和就是训练集的个数
random_state:随机状态
eg:
from sklearn.model_selection import KFold
from sklearn.datasets import load_iris
from sklearn.linear_model import LinearRegression
import numpy as np
import pandas as pd
KF = KFold(n_splits=5)
X, Y = load_iris().data, load_iris().target
alg = LinearRegression()
# 这里想强行使用DataFrame的数据格式,因为以后大家读取数据使用都是csv格式
# 所以必不可免要用 iloc
X, Y = pd.DataFrame(X), pd.DataFrame(Y)
# split():Generate indices to split data into training and test set.
for train_index, test_index in KF.split(X):
print("TRAIN:", train_index, "TEST:", test_index)
X_train, X_test = X.iloc[train_index], X.iloc[test_index]
y_train, y_test = Y.iloc[train_index], Y.iloc[test_index]
alg.fit(X_train, y_train)
。
。
。
4、主要方法
4.1、留出法(holdout cross validation)
在机器学习任务中,拿到数据后,我们首先会将原始数据集分为三部分:训练集,验证集和测试集。
训练集用于训练模型,验证集用于模型的参数选择配置,测试集对于模型来说是未知数据,用于评估模型的泛化能力。  这个方法操作简单,只需要随机将原始数据分为三组即可。
这个方法操作简单,只需要随机将原始数据分为三组即可。
不过如果只做一次分割,它对训练集,验证集和测试机的样本比例,还有分割后数据的分布是否和原始数据集的分布相同等因素比较敏感,不同的划分会得到不同的最优模型,,而且分成三个集合后,用于训练的数据更少了。于是有了k折交叉验证(k-fold cross validation)**.
eg:
>>> import numpy as np
>>> from sklearn.model_selection import train_test_split
>>> from sklearn import datasets
>>> from sklearn import svm
>>> iris = datasets.load_iris()
>>> iris.data.shape, iris.target.shape
((150, 4), (150,))
用train_test_split来随机划分数据集,其中40%用于测试集,有60条数据,60%为训练集,有90条数据:
>>> X_train, X_test, y_train, y_test = train_test_split(
... iris.data, iris.target, test_size=0.4, random_state=0)
>>> X_train.shape, y_train.shape
((90, 4), (90,))
>>> X_test.shape, y_test.shape
((60, 4), (60,))
用train来训练,用test来评价模型的分数。
>>> clf = svm.SVC(kernel='linear', C=1).fit(X_train, y_train)
>>> clf.score(X_test, y_test)
0.96...
4.2、k 折交叉验证(k-fold cross validation)
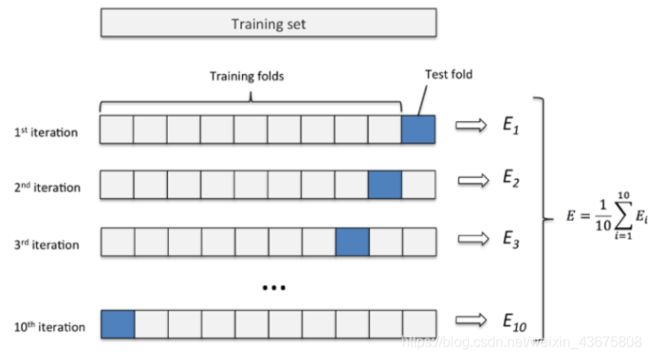
K折交叉验证通过对k个不同分组训练的结果进行平均来减少方差,因此模型的性能对数据的划分就不那么敏感。
- 第一步,不重复抽样将原始数据随机分为 k 份。
- 第二步,每一次挑选其中 1 份作为测试集,剩余 k-1 份作为训练集用于模型训练。
- 第三步,重复第二步 k 次,这样每个子集都有一次机会作为测试集,其余机会作为训练集。
- 在每个训练集上训练后得到一个模型,
- 用这个模型在相应的测试集上测试,计算并保存模型的评估指标,
- 第四步,计算 k 组测试结果的平均值作为模型精度的估计,并作为当前 k 折交叉验证下模型的性能指标。
K一般取10,数据量小的是,k可以设大一点,这样训练集占整体比例就比较大,不过同时训练的模型个数也增多。数据量大的时候,k可以设置小一点。当k=m的时候,即样本总数,出现了留一法。
举例,这里直接调用了cross_val_score,这里用了5折交叉验证
>>> from sklearn.model_selection import cross_val_score
>>> clf = svm.SVC(kernel='linear', C=1)
>>> scores = cross_val_score(clf, iris.data, iris.target, cv=5)
>>> scores
array([ 0.96..., 1. ..., 0.96..., 0.96..., 1. ])
得到最后平均分数为0.98,以及它的95%置信区间:
>>> print("Accuracy: %0.2f (+/- %0.2f)" % (scores.mean(), scores.std() * 2))
Accuracy: 0.98 (+/- 0.03)
我们可以直接看一下K-Fold是怎么样划分数据的:X有四个数据,把它分成2折,结构中最后一个集合是测试集,前面的是训练集,每一行为1折:
>>> import numpy as np
>>> from sklearn.model_selection import KFold
>>> X = ["a", "b", "c", "d"]
>>> kf = KFold(n_splits=2)
>>> for train, test in kf.split(X):
... print("%s %s" % (train, test))
[2 3] [0 1]
[0 1] [2 3]
同样的数据X,我们来看LeaveOneOut后是什么样子,那就是把它分成4折,结果中最后一个集合是测试集,只有一个元素,前面的是训练集,每一行为1折:
>>> from sklearn.model_selection import LeaveOneOut
>>> X = [1, 2, 3, 4]
>>> loo = LeaveOneOut()
>>> for train, test in loo.split(X):
... print("%s %s" % (train, test))
[1 2 3] [0]
[0 2 3] [1]
[0 1 3] [2]
[0 1 2] [3]
4.3、输入文章内容留一法(Leave one out cross validation)
每次的测试集都只有一个样本,要进行m次训练和预测,这个方法用于训练的数据只比整体数据集少一个样本,因此最接近原始样本的分布。但是训练复杂度增加了,因为模型的数量与原始数据样本数量相同。一般在数据缺少时使用。
此外:
- 多次 k 折交叉验证再求均值,例如:10 次 10 折交叉验证,以求更精确一点。
- 划分时有多种方法,例如对非平衡数据可以用分层采样,就是在每一份子集中都保持和原始数据集相同的类别比例。
- 模型训练过程的所有步骤,包括模型选择,特征选择等都是在单个折叠 fold 中独立执行的。
4.4、Bootstrapping
通过自助采样法,即在含有 m 个样本的数据集中,每次随机挑选一个样本,再放回到数据集中,再随机挑选一个样本,这样有放回地进行抽样 m 次,组成了新的数据集作为训练集。
这里会有重复多次的样本,也会有一次都没有出现的样本,原数据集中大概有 36.8% 的样本不会出现在新组数据集中。
优点是训练集的样本总数和原数据集一样都是 m,并且仍有约 1/3 的数据不被训练而可以作为测试集。
缺点是这样产生的训练集的数据分布和原数据集的不一样了,会引入估计偏差。
(此种方法不是很常用,除非数据量真的很少)
5、几种交叉验证(cross validation)方式的比较
5.1、train_test_split
在分类问题中,我们通常通过对训练集进行triain_test_split,划分出train 和test两部分,其中train用来训练模型,test用来评估模型,模型通过fit方法从train数据集中学习,然后调用score方法在test集上进行评估,打分;从分数上我们知道模型当前的训练水平如何。
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
import matplotlib.pyplot as plt
cancer = load_breast_cancer()
X_train,X_test,y_train,y_test = train_test_split(cancer.data,cancer.target,random_state=0)
logreg = LogisticRegression().fit(X_train,y_train)
print("Test set score:{:.2f}".format(logreg.score(X_test,y_test)))
结果:
Test set score:0.96
然而这中方式只进行了一次划分,数据结果具有偶然性,如果在某次划分中,训练集里全是容易学习的数据,测试集里全是复杂的数据,这样的就会导致最终的结果不尽人意。
5.2、Standard Cross Validation
针对上面通过train_test_split划分,从而进行模型评估方式存在的弊端,提出Cross Validation交叉验证。
Cross Validation:进行多次train_test_split划分;每次划分时,在不同的数据集上进行训练,测试评估,从而得到一个评价结果;如果是5折交叉验证,意思就是在原始数据集上,进行五次划分,每次划分进行一次训练,评估,最后得到5次划分后的评估结果,一般在这几次评估结果上取平均得到最后的评分,k-fold cross-validation ,其中K一般取5或10。

from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
import warnings
warnings.filterwarnings('ignore')
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(
cancer.data , cancer.target, random_state=0
)
logreg = LogisticRegression()
# CV 默认是3折交叉验证,可以修改cv=5,变为5折交叉验证
scores = cross_val_score(logreg,cancer.data , cancer.target)
print("Cross validation scores:{}".format(scores))
print("Mean cross validation score:{:2f}".format(scores.mean()))
结果:
Cross validation scores:[0.93684211 0.96842105 0.94179894]
Mean cross validation score:0.949021
交叉验证的优点:
原始采用的train_test_split方法,数据划分具有偶然性;交叉验证通过多次划分,大大降低了这种由一次随机划分带来的偶然性,同时通过多次划分,多次训练,模型也能遇到各种各样的数据,从而提高其泛化能力。
与原始的train_test_split相比,对数据的使用效率更高,train_test_split,默认训练集,测试集比例为3:1,而对交叉验证来说,如果是5折交叉验证,训练集比测试集为4:1;10折交叉验证训练集比测试集为9:1.数据量越大,模型准确率越高。
交叉验证的缺点:
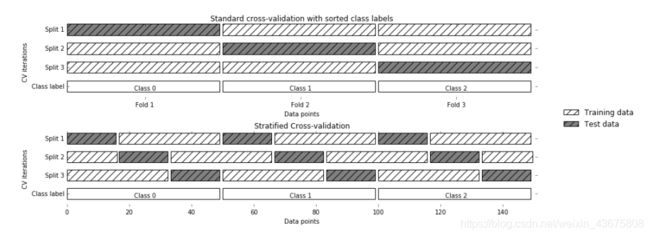
这种简答的交叉验证方式,从上面的图片可以看出来,每次划分时对数据进行均分,设想一下,会不会存在一种情况:数据集有5类,抽取出来的也正好是按照类别划分的5类,也就是说第一折全是0类,第二折全是1类,等等;这样的结果就会导致,模型训练时。没有学习到测试集中数据的特点,从而导致模型得分很低,甚至为0,为避免这种情况,又出现了其他的各种交叉验证方式。
5.3、Stratifid k-fold cross validation
分层交叉验证(Stratified k-fold cross validation):首先它属于交叉验证类型,分层的意思是说在每一折中都保持着原始数据中各个类别的比例关系,比如说:原始数据有3类,比例为1:2:1,采用3折分层交叉验证,那么划分的3折中,每一折中的数据类别保持着1:2:1的比例,这样的验证结果更加可信。
通常情况下,可以设置cv参数来控制几折,但是我们希望对其划分等加以控制,所以出现了KFold,KFold控制划分折,可以控制划分折的数目,是否打乱顺序等,可以赋值给cv,用来控制划分。
from sklearn.datasets import load_iris
from sklearn.model_selection import StratifiedKFold ,cross_val_score
from sklearn.linear_model import LogisticRegression
import warnings
warnings.filterwarnings('ignore')
iris_data = load_iris()
logreg = LogisticRegression()
strKFold = StratifiedKFold(n_splits=3,shuffle=False,random_state=0)
scores = cross_val_score(logreg,iris_data.data,iris_data.target,cv=strKFold)
print("straitified cross validation scores:{}".format(scores))
print("Mean score of straitified cross validation:{:.2f}".format(scores.mean()))
结果:
straitified cross validation scores:[0.96078431 0.92156863 0.95833333]
Mean score of straitified cross validation:0.95
5.4、Leave-one-out Cross-validation 留一法
留一法Leave-one-out Cross-validation:是一种特殊的交叉验证方式。顾名思义,如果样本容量为n,则k=n,进行n折交叉验证,每次留下一个样本进行验证。主要针对小样本数据。
from sklearn.datasets import load_iris
from sklearn.model_selection import LeaveOneOut , cross_val_score
from sklearn.linear_model import LogisticRegression
import warnings
warnings.filterwarnings('ignore')
iris = load_iris()
logreg = LogisticRegression()
loout = LeaveOneOut()
scores = cross_val_score(logreg,iris.data,iris.target,cv=loout)
print("leave-one-out cross validation scores:{}".format(scores))
print("Mean score of leave-one-out cross validation:{:.2f}".format(scores.mean()))
结果:
leave-one-out cross validation scores:[1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.
1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.
1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 0. 1. 1. 1. 0. 1.
1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 0. 0. 0. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.
1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.
1. 1. 1. 1. 1. 1. 1. 1. 1. 0. 1. 1. 1. 0. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.
1. 1. 1. 1. 1. 1.]
Mean score of leave-one-out cross validation:0.95
5.5、Shuffle-split cross-validation
控制更加灵活,可以控制划分迭代次数,每次划分测试集和训练集的比例(也就说:可以存在机不再训练集也不再测试集的情况)

from sklearn.datasets import load_iris
from sklearn.model_selection import ShuffleSplit,cross_val_score
from sklearn.linear_model import LogisticRegression
import warnings
warnings.filterwarnings('ignore')
iris = load_iris()
# 迭代八次
shufsp1 = ShuffleSplit(train_size=0.5,test_size=0.4,n_splits=8)
logreg = LogisticRegression()
scores = cross_val_score(logreg,iris.data,iris.target,cv=shufsp1)
print("shuffle split cross validation scores:\n{}".format(scores))
print("Mean score of shuffle split cross validation:{:.2f}".format(scores.mean()))
结果:
shuffle split cross validation scores:
[0.95 1. 0.86666667 0.95 0.88333333 0.88333333
0.85 0.9 ]
Mean score of shuffle split cross validation:0.91