Windows10下ChatGLM2-6B模型本地化安装部署教程图解
随着人工智能技术的不断发展,自然语言处理模型在研究和应用领域备受瞩目。ChatGLM2-6B模型作为其中的一员,以其强大的聊天和问答能力备受关注,并且最突出的优点是性能出色且轻量化。然而,通过云GPU部署安装模型可能需要支付相应的费用,这对于一些开发者来说可能存在一定的压力。为了更灵活地使用该模型,掌握安装环境的知识并了解部署流程,以便快速尝鲜ChatGLM2-6B模型,将其本地化部署成为了许多开发者追求的目标。
本文将为您提供一份详尽的教程,指导您在Windows 10操作系统下进行ChatGLM2-6B模型的本地化安装和部署,快速尝鲜ChatGLM2-6B模型。
目录
一、ChatGLM2-6B模型介绍
二、本地安装电脑配置要求
三、Cuda环境安装并检查是否安装成功
四、配置ChatGLM2-6B Conda虚拟环境
五、在虚拟环境中安装Pytorch
六、ChatGLM2-6B模型环境安装及模型下载
七、ChatGLM2-6B模型代码运行及本地大模型初体验
八、小结
一、ChatGLM2-6B模型介绍
ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 引入了如下新特性:
- 更强大的性能:基于 ChatGLM 初代模型的开发经验,我们全面升级了 ChatGLM2-6B 的基座模型。ChatGLM2-6B 使用了 GLM 的混合目标函数,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,评测结果显示,相比于初代模型,ChatGLM2-6B 在 MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
- 更长的上下文:基于 FlashAttention 技术,我们将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练,允许更多轮次的对话。但当前版本的 ChatGLM2-6B 对单轮超长文档的理解能力有限,我们会在后续迭代升级中着重进行优化。
- 更高效的推理:基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
- 更开放的协议:ChatGLM2-6B 权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。
链接源码地址:
GitHub - THUDM/ChatGLM2-6B: ChatGLM2-6B: An Open Bilingual Chat LLM | 开源双语对话语言模型ChatGLM2-6B: An Open Bilingual Chat LLM | 开源双语对话语言模型 - GitHub - THUDM/ChatGLM2-6B: ChatGLM2-6B: An Open Bilingual Chat LLM | 开源双语对话语言模型 https://github.com/THUDM/ChatGLM2-6B推理性能:
https://github.com/THUDM/ChatGLM2-6B推理性能:
ChatGLM2-6B 使用了 Multi-Query Attention,提高了生成速度。生成 2000 个字符的平均速度对比如下:
| Model | 推理速度 (字符/秒) |
|---|---|
| ChatGLM-6B | 31.49 |
| ChatGLM2-6B | 44.62 |
使用官方实现,batch size = 1,max length = 2048,bf16 精度,测试硬件为 A100-SXM4-80G,软件环境为 PyTorch 2.0.1
Multi-Query Attention 同时也降低了生成过程中 KV Cache 的显存占用,此外,ChatGLM2-6B 采用 Causal Mask 进行对话训练,连续对话时可复用前面轮次的 KV Cache,进一步优化了显存占用。因此,使用 6GB 显存的显卡进行 INT4 量化的推理时,初代的 ChatGLM-6B 模型最多能够生成 1119 个字符就会提示显存耗尽,而 ChatGLM2-6B 能够生成至少 8192 个字符。
| 量化等级 | 编码 2048 长度的最小显存 | 生成 8192 长度的最小显存 |
|---|---|---|
| FP16 / BF16 | 13.1 GB | 12.8 GB |
| INT8 | 8.2 GB | 8.1 GB |
| INT4 | 5.5 GB | 5.1 GB |
二、本地安装电脑配置要求
python版本要求:3.8以上,可在Anaconda中安装Python虚拟环境。
windows系统:Windows 10及以上,推荐有NVIDIA显卡(最好NVIDIA显卡20系列以上)
显卡要求:显存必须6G以上GPU(可以看到上面表格中,量化等级INT4,也需要5.1G显存以上)
检查自己的电脑是否有GPU及显存大小:
鼠标右击电脑最下方任务栏,选中“任务管理器”选项,即可打开任务管理器,再点击“性能”,如下图:

我本地电脑的显卡是NVIDIA GTX 1060 6G显存GPU ,16G内存,处理器i7-8750H CPU,刚好满足要求。想想部署成功后的测试画面就很卡。。。。。。
三、Cuda环境安装并检查是否安装成功
上面检查本地PC电脑配置,刚好满足部署ChatGLM2-6B的最低要求。所以,自己搭建本地模型,尝试体验一下,不需要拥有高端设备或庞大的计算能力来开始使用ChatGLM2-6B模型。只要你的本地PC电脑达到了ChatGLM2-6B模型的最低要求,就可以轻松安装和部署这一强大的聊天模型。
1、Cuda环境安装
cuda下载链接:
CUDA Toolkit Archive | NVIDIA DeveloperPrevious releases of the CUDA Toolkit, GPU Computing SDK, documentation and developer drivers can be found using the links below. Please select the release you want from the list below, and be sure to check www.nvidia.com/drivers for more recent production drivers appropriate for your hardware configuration.https://developer.nvidia.com/cuda-toolkit-archive
点击链接,即可进入该界面(我本地安装的是CUDA Toolkit 11.7.0,因为我的显卡只支持我安装Cuda Version 12.0以下的):

接着点击CUDA Toolkit 11.7.0,进入以下界面,选择windows10,exe(local)本地下载,然后点击Download即可。
下载完成后进行安装cuda。
具体安装教程可上网查找,这里推荐一个:
CUDA安装教程(超详细)_Billie使劲学的博客-CSDN博客目录前言cuda的下载及安装cuda版本CUDA toolkit Downloadcuda安装cuDNN下载及安装cuDNN下载cuDNN配置参考自前言windows10 版本安装 CUDA ,首先需要下载两个安装包CUDA toolkit(toolkit就是指工具包)cuDNN注:cuDNN 是用于配置深度学习使用官方教程CUDA:Installation Guide Windows :: CUDA Toolkit Documentatio_cuda安装https://blog.csdn.net/m0_45447650/article/details/123704930
2、检查Cuda是否安装成功
按住win + R 调出命令终端,输出cmd:

1)进入终端后,输入 nvidia-smi 查看是否已正确安装:
nvidia-smi如果返回以下信息,则CUDA已正确安装并可以被系统识别:
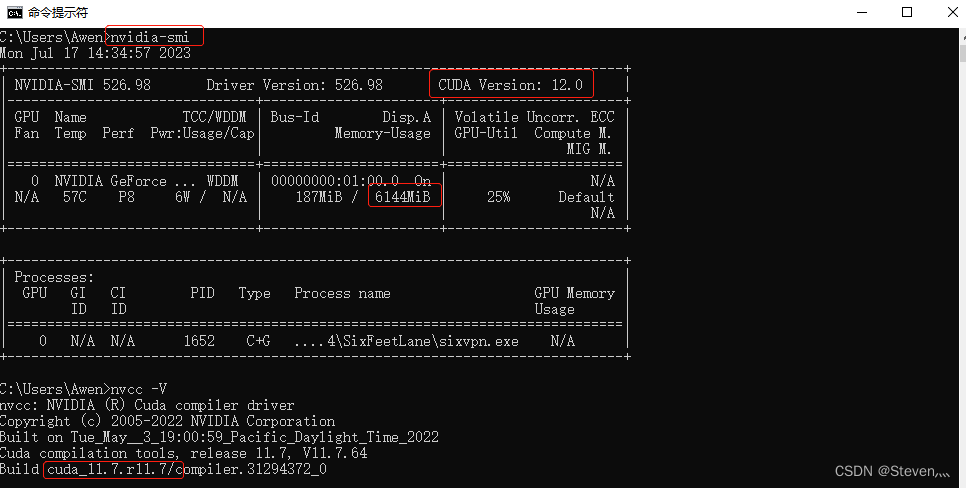
如果返回类似“command not found”的信息,则CUDA没有成功安装或者没有正确添加环境变量。
查看到本机可装CUDA版本最高为12.0,版本向下兼容,意思就是CUDA 12.0及以下版本的都可以安装,但一般不建议使用最新版本的,所以本地下载的是Cuda11.7版本。
2)或者输入 nvcc -V命令,测试CUDA是否安装成功
nvcc -V
如果返回类似“command not found”的信息,则CUDA没有成功安装或者没有正确添加环境变量。
四、配置ChatGLM2-6B Conda虚拟环境
Python 环境:使用Anaconda创建虚拟环境mygpt,虚拟环境的Python版本是Python3.10.11,激活虚拟环境activate mygpt,进入之后安装相对应的工具包即可。

(注:如果不会安装Anaconda,并在Anaconda中创建虚拟环境,百度找下教程,网上一大堆)
五、在虚拟环境中安装Pytorch
激活虚拟环境之后,首先在命令行输入下面命令即可:
注意这里的Pytorch需要和cuda版本一致,我上面下载的是cuda11.7;还有注意如果你的cuda版本和我不一致,以下命令也有差异。具体看官网命令,以对应版本官网命令为准。
Pytorch地址:
Start Locally | PyTorch An open source machine learning framework that accelerates the path from research prototyping to production deployment. https://pytorch.org/get-started/locally/#anaconda
https://pytorch.org/get-started/locally/#anaconda

绿色方框中就是安装命令:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
安装完成后,检查一下:
import torch
print(torch.cuda.is_available())
如果结果为True,则说明Pytorch安装成功。如果为False,则说明自己电脑上对应cuda版本和torch、torchvision版本文件不一致。
如何解决在cuda上安装torch后torch.cuda.is_available()返回False - 知乎
六、ChatGLM2-6B模型环境安装及模型下载
1、ChatGLM2-6B源码下载
1)方法一:源码下载链接:
GitHub - THUDM/ChatGLM2-6B: ChatGLM2-6B: An Open Bilingual Chat LLM | 开源双语对话语言模型
注:Github网站不稳定,有时需要科学上网。

如上图,点击下载Download ZIP即可下载ChatGLM2-6B源码,大概5-6M左右。
2)方法二:直接使用git命令clone (这个需要安装Git软件)
git clone https://github.com/THUDM/ChatGLM-6B.git下载完成之后,将下载好的文件放到本地D盘或者其他盘,尽量不要放C盘。

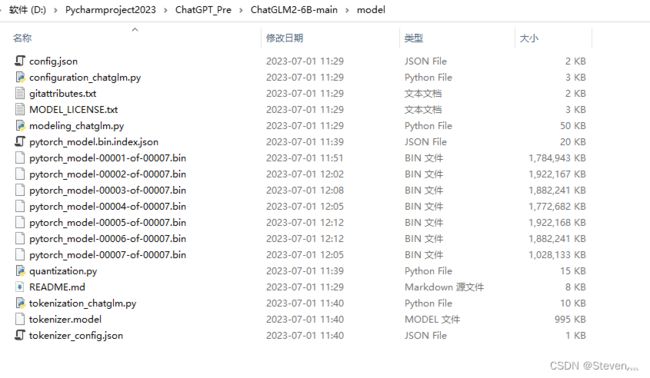
再在该路径下(ChatGLM2-6B-main文件夹下)新建一个model文件,用于放ChatGLM2-6B模型文件,大小11.6G。
2、ChatGLM2-6B模型下载
模型下载地址1:清华大学云盘
THUDM/chatglm-6b at main模型下载地址2:THUDM/chatglm-6b at main,(全部下载)
下载完成后,将下载后的模型文件放入到ChatGLM2-6B-main\model文件夹中:
3、requirements.txt中相关库安装
进入到D:\Pycharmproject2023\ChatGPT_Pre\ChatGLM2-6B-main目录下,执行以下命令,进行安装相关包:
pip3 install -r requirements.txt
直到现在,所有环境全部安装完成,胜利在望。。。
七、ChatGLM2-6B模型代码运行及本地大模型初体验
1、修改web_demo.py代码
在运行之前,需修改web_demo.py中的代码
下载下来的源代码,在web_demo.py文件中的第6-7行:
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True, device='cuda')修改为:
tokenizer = AutoTokenizer.from_pretrained("D:\Pycharmproject2023\ChatGPT_Pre\ChatGLM2-6B-main\model", trust_remote_code=True)
model = AutoModel.from_pretrained("D:\Pycharmproject2023\ChatGPT_Pre\ChatGLM2-6B-main\model", trust_remote_code=True).half().quantize(4).cuda()
其中D:\Pycharmproject2023\ChatGPT_Pre\ChatGLM2-6B-main\model为我电脑模型下载位置,更改为你自己的即可。
half().quantize(4).cuda()这个需要根据你电脑实际显卡GPU进行更改。
温馨提示:
根据实际显卡显存 (如何看自己的显存,前面我已经讲过了,自己的显存要和下面代码对应,不对应就会报错并且烧坏显卡,注意注意!!),可以更改第6行关于model运行方式:
# 6G 显存可以 4 bit 量化
model = AutoModel.from_pretrained("model", trust_remote_code=True).half().quantize(4).cuda()
# 10G 显存可以 8 bit 量化
model = AutoModel.from_pretrained("model", trust_remote_code=True).half().quantize(8).cuda()
# 14G 以上显存可以直接不量化,博主显存为16G选择的就是这个
model = AutoModel.from_pretrained("model", trust_remote_code=True).half().cuda()
我电脑配置只能选择第一个,即6G 显存可以 4 bit 量化。
2、运行启动ChatGLM2-6B模型
进入到环境中,运行python web_demo.py即可启动,稍等一下:

接着浏览器会自动打开Web界面:
3、ChatGLM2-6B模型测试体验

在ChatGLM2-6B生成答案时,我看到我的显存占用情况,大概5G显存左右:

生成答案的时候确实卡卡卡卡卡卡,不流畅,电脑就这配置,只能熟悉一下安装流程和简单体验一下。
八、小结
本文旨在为读者提供一份详尽的教程,指导读者在Windows 10操作系统下进行ChatGLM2-6B模型的本地化安装和部署。总结如下:
-
确认模型要求:在开始之前,了解ChatGLM2-6B模型的基本要求对于成功地进行本地化部署是至关重要的。确保您的本地PC电脑满足这些要求,包括适当的硬件配置和操作系统版本。
-
配置GPU环境:为了充分利用本地GPU资源加速模型运行,确保正确配置GPU环境。这包括安装适当的GPU驱动程序和CUDA工具包,并配置相应的环境变量。
-
安装必要软件和依赖库:在进行模型安装之前,确保已正确安装Python环境,并根据需要安装必要的软件和依赖库。这包括PyTorch等库,以及其他必需的辅助工具。
-
加载和使用模型:一旦完成安装和配置,就可以下载ChatGLM2-6B源程序和大模型参数文件,运行并体验使用ChatGLM2-6B模型。
-
优化和调试:可以基于本地知识库问答进行微调模型,大家自行探索预研。
总结起来,通过本文所提供的详细教程,希望你们可以轻松地进行ChatGLM2-6B模型的本地化部署,并深入了解其优秀的聊天和问答能力。本地化部署为开发者提供了更大的灵活性和控制力,使得能够更好地应对各种需求和挑战。无论为了更灵活地使用该模型,掌握安装环境的知识并了解部署流程,以便快速尝鲜ChatGLM2-6B模型,还是为了探索自然语言处理模型的潜力,本地化部署都是一个值得尝试的选择。请按照本文提供的教程,开始您的ChatGLM2-6B模型之旅吧!
