学习C++这一篇就够了(提升篇)
-
C++中除了面向对象的编程思想外,还有另一种就是泛型编程
-
主要用到的技术就是模板
模板机制的分类:
-
函数模板
-
类模板
函数模板
作用:建立一个通用函数,其函数返回值类型和形参类型可以不具体定制,用虚拟的类型来表示
关键字:template
语法:
template
// template 函数声明或者定义
-
template:声明创建模板
-
typename:表明后面的符号是一种数据类型,也可以用class代替
-
T:通用的数据类型,名称可以替换,通常为大写字母
意义:将类型参数化,提高代码通用性。
使用方法:
-
自动类型推导
-
显示指定类型
注意事项:
-
自动类型推导,无论有几个 T,其必须要推导出一致的数据类型,才可以使用
-
函数模板必须要确定 T 的数据类型,才可以使用
与普通函数的区别:
-
普通函数调用时可以发生自动类型转换,也就是隐式转换
-
函数模板只有在调用显示指定类型才会发生隐式转换,用自动类型推导就不会
示例:
void SwapDouble(double &a, double &b) //这是一个普通的两个double类型数值交换的函数,缺点是数据类型被固定死了
{
double temp = a;
a = b;
b = temp;
}
template //声明一个函数模板,T是通用的数据类型
void mySwap(T &a, T &b)
{
T temp = a;
a = b;
b = temp;
}
template
void func()
{
cout << "注意事项" << endl;
}
int main()
{
int a = 20;
int b = 10;
char c = '5';
//1、自动推导类型,又编译器自动推导出数据类型
mySwap(a , b);
//mySwap(a , c); //×,因为 T 的数据类型不一致,一个是int型,一个是char型
// 同时自动推导类型不会发生隐式转换,无法将int变char型,也无法将char变int型
//2、显示指定类型,直接告诉编译器这两个传参的数据类型
mySwap(a , b)
//func(); //×,因为 T 没有一个确定的数据类型
func(); //√,因为我们给 T 指定了一个确定的数据类型
// 同时显示指定类型可以发生隐式转换,强制转换为int型
} 调用规则
-
如果普通函数和函数模板都实现了,优先使用普通函数
-
可以通过空模板参数列表强制调用函数模板
-
函数模板可以以发生函数重载
-
如果函数模板可以更好的匹配,那肯定是优先使用函数模板啦
示例:
void Print(int a , int b)
{
cout << "普通函数" << endl;
}
template
void Print(T a , T b)
{
cout << "函数模板" << endl;
}
template
void Print(T a , T b , T c)
{
cout << "函数模板" << endl;
}
int main()
{
int a = 10;
int b = 5;
char c1 = 'a';
char c2 = 'b';
Print(a , b); //1、普通函数和函数模板你都一样实现的情况下,优先调用普通函数
Print<>(a , b); //2、利用空模板参数列表来强制调用函数模板
Print<>(a , b , c); //3、函数模板可以发生函数重载
Print(c1 , c2); //4、函数模板可以更好的匹配,优先调用函数模板
//这是编译器所做的决定,它觉得直接将类型变成通用类型 比 将char转换成int更加方便
} 函数模板的局限性
一些特定的数据类型,函数模板就处理不了
示例:
template
void func(T a , T b) //如果a 和 b 都是数组类型,那赋值操作就运行不了
{ //如果 T 是某一个类自定义数据类型,也处理不了
a = b;
} -
为了解决这些问题,C++提供了模板的重载,为特定的数据类型提供具体化的模板
-
利用具体化的模板,可以解决类型自定义的通用性
-
但是模板其实不用去写,可以在STL中调用系统提供的模板
语法:
template<> 返回值类型 函数名(参数1,参数2,···)
示例:
class Person
{
public:
Person(string name ,int age)
{
this ->m_name = name;
this ->m_age = age;
}
string m_name;
int m_age;
};
template
bool Compare(T &a , T &b) //只能对比一些普通的变量,对于自定义的数据类型,无法处理
{
if(a == b)
return ture;
else
return flase;
}
//template<> 表示这是个具体化Person实现的函数模板
template<> bool Compare(Person &a , Person &b)
{
if(a.m_name == b.m_name && a.m_age == b.m_age)
return ture;
else
return flase;
}
int main()
{
Person p1("张三",20);
Person P2("李四",30);
if(Conpare(p1 , p2)) //只要参数是Person类型,编译器会自动调用具体化Person类型的函数模板
cout << "完全一致" << endl;
else
cout << "对比失败" << endl;
} 类模板
作用:建立一个通用的类,但是类中的成员变量类型未知,用一个虚拟的类型来表示
语法:
template
类
-
template:声明创建一个模板
-
typename:表明后面的 T 是一种数据类型,typename 也可以用class替代
-
T:通用的数据类型
与函数模板的区别:
-
类模板在使用的时候,没有自动类型推导的方式
-
类模板在模板参数列表中可以有默认参数类型
示例:
//temolate //类模板的参数列表可以说有默认参数类型
template //因为会有涉及到两个不同类型的变量,所以创建了两个虚拟的类型
class Person
{
public:
Person(NameType name, AgeType age)
{
this->m_name = name;
this->m_age = age;
}
NameType m_name;
AgeType m_age;
}
int main()
{
Person p1("张三",99); //既然指定了string类型,记得添加string头文件
// Person("李四",56); //×,类模板没有自动类型推导的方式
// Person p2("王五",66); //√,只要在前面有模板参数列表的声明中默认参数就可以用
} 类模板成员函数创建时机
-
普通类中的成员函数,在一可以就可以创建
-
类模板中的成员函数,在函数调用时才创建
示例:
class Person1
{
public:
void showPerson1(){ cout << "show Person1" << endl; }
}
class Person2
{
public:
void showPerson2() { cout << "show Person2" << endl; }
}
template
class myClass
{
public:
T obj;
void func1(){ obj.showPerson1(); } //因为是类模板,函数此时其实还没有创建,所以随便用别人家的函数也没事
void func2(){ obj.showPerson2(); }
}
int main()
{
myClass p1; // 将通用类型指定为 Person1 类型,创建了类 p1
p1.func1(); //此时才是创建成员函数 func1() 的时候,调用的时候才进行声明
//p1.func2(); //因为指定的是 Person1 类,所以只有 Person1类中的 showPerson1()函数被声明了
//Person2 类中的 showPerson2() 并没有被声明,说明不能调用
myClass p2;
//p2.func1();
p2.func2();
} 类模板对象做函数参数
作用:用模板实例出的对象来当做函数参数传入
传入方式:
-
指定传入的类型:直接显示对象的数据类型
-
参数模板化:将对象中的参数变为模板进行传递
-
整个类模板化:将整个对象进行模板化,传递下去
一般而言第一种传递方式比较常见;
第二种和第三种,其实有点像函数模板和类模板结合使用;
使用函数 typeid(temp) 可获知一个参数 temp 的类型;
示例:
template
class Person
{
Person(T1 name, T2 age)
{
this->m_name = name;
this->m_age = age;
}
showPerson()
{
cout << "名字:" << this->m_name <<"年龄: " << this->m_age << endl;
}
T1 m_name;
T2 m_age;
}
void func1( Person&p ) //1、指定传入类型
{
p.showPerson();
}
template //要加上这个,不然编译器不知道 T1 和 T2 是什么
void func2( Person&p ); //2、参数模块化,T1 和 T2 由编译器根据传参去推导
{
p.showPerson();
cout << T1 的数据类型 << typeid(T1).name << endl; //使用typeid()可获知 T1 / T2 的数据类型
cout << T2 的数据类型 << typeid(T2).name << endl;
}
template
void func3(T &p) //3、整个类进行模板化,T 由编译器根据传参去推导
{
p.showPerson();
cout << "T 的数据类型 " << typeid(T).name << endl; //获取 T 的数据类型
}
int main()
{
Person p("张三", 50);
func1(p); //1、指定传入类型
func2(p); //2、参数模板化
func3(p); //3、整个类进行模板化
} 类模板与继承
当类模板碰到继承时:
-
当子类继承的父类是一个类模板时,子类在声明时要指定父类 T 的类型
-
如果不指定,编译器就无法给子类分配内存
-
要想灵活指定父类中 T 的类型,子类也必须为类模板
语法:
template
class 子类:继承方式 父类
{
//T1 通用类型留给子类自己用
}
示例:
template
class Base
{
T m;
}
// class Son : public Base //×,父类是类模板,继承中需要指定父类中 T 的类型
class Son1 : public Base //将父类中的数据类型指定为 int 型,这样继承才可以成功
{
}
template
class Son2:public Base //这样 类模板的 Son2 的参数 T2 就变成了父类的 T 的类型,达到灵活指定父类 T类型的目的
{
T1 m;
}
int main ()
{
Son1 s1; //创建子类对象s1的时候,父类中的 T 类型就被强制指定成 int 型
Son2 s2; //创建子类对象s2的时候,父类中的 T 类型就随着子类的定义而改变,此时 父类中 T 便是 int 型
} 类模板成员函数的类外实现
类外实现的方法:
-
类内声明,类外写函数定义
-
类外写函数时,作用域需要加上模板参数列表
语法:
template
返回值类型 作用域
::成员函数() //作用域要加上模板参数列表
,不管传参和函数内部有没有用到 T , 都要写出来 {
}
示例:
template
class Person
{
public:
//Person(T1 name , T2 age) //这是成员函数之构造函数的类内实现
// {
// this->m_name = name;
// this->m_age = age;
// }
// void PrintPerson() //这是成员函数之普通函数的类内实现
// {
// cout << "姓名:" << this->m_name << "年龄" << this->m_age << endl;
// }
Person(T1 name, T2 age); //类外实现之类内声明
void PrintPerson();
T1 m_name;
T2 m_age;
}
template
Person::Person(T1 name ,T2 age)
{
this->m_name = name;
this->m_age = age;
}
template
void Person::PrintPerson()
{
cout << "姓名:" << this->m_name << "年龄" << this->m_age << endl;
}
int main()
{
Person p("张三" , 50);
p.PrintPerson();
} 分文件编写
在使用类模板过程中,进行分文件编写会出现一些问题:
一般的分文件编写:
.h:写类声明和成员函数定义
.cpp:写类中成员函数的实现
x.cpp:写主函数和应用功能
原因:类模板的成员函数在主函数调用的时候才创建,所以会导致预处理时链接不到
解决办法(建议用第二种):
-
直接包含.cpp源文件(将x.cpp中的#include".h">改成#include".cpp",而.cpp中也有包含头文件,这样改,就是在跑主函数之前,将声明和实现都跑了一遍)
-
将声明和实现写在同一个文件中,后缀名改成.hpp(.hpp是约定俗成的名字,不是强制的,但大家都这么写)
两种方法,目的都是在跑主函数之前,将声明和实现都先跑了一遍。
类模板与友元
类模板和友元配合成的全局函数的类内实现和类外实现:
-
类内实现:直接在类内声明友元即可(建议这个,比较简单)
-
类外实现:需要提前让编译器知道全局函数的存在(有点复杂,不建议)
示例:
template //类外实现——这部分最好写在最前面,提前让编译器知道这个Person类的存在
class Person;
template //类外实现——这部分实现最好写在前面,提前让编译器知道这个函数的存在
void PrintPerson2( Personp)
{
cout << "姓名:" << p.m_name << "年龄" << p.m_age << endl;
}
template
class person
{
friend void PrintPerson1( Person p) //全局函数,友元函数的类内实现,这个比较简单
{
cout << "姓名:" << p.m_name << "年龄" << p.m_age << endl;
}
friend void PrintPerson2<>( Person p); //全局函数,友元函数的类外实现,需要先类内声明,类外实现
//加一个空模板参数列表,将这个普通函数变成类模板函数
public:
Person(T1 name, T2 age)
{
this->m_name = name;
this->m_age = age;
}
private:
T1 m_name;
T2 m_age;
}
int main()
{
Person p("张三", 50);
PrintPerson1(p); //类内实现
PrintPerson2(p); //类外实现
} STL
-
之所以有C++的面向对象和泛型编程,目的就是提升可重复性
-
STL的诞生,就是为了建立一套数据结构和算法的标准,提高可重复利用性
STL基本概念
-
STL,即标准模板库
-
从广义上分为:容器、算法、迭代器
-
从细分上分为:容器、算法、迭代器、仿函数、适配器(配接器)、空间配置器
-
容器和算法通过迭代器进行无缝连接
-
STL所有的代码都运用到了函数模板和类模板
STL六大组件
六大组件就是上线说到的:容器、算法、迭代器、仿函数、适配器(配接器)、空间配置器
-
容器:各种数据结构,如vector、list、deque、set、map等,用来存放数据
-
算法:各种常用算法,如sort、find、copy、for_each等
-
迭代器:容器和算法之间的链接器
-
仿函数:类似函数,可作为算法的某种策略
-
适配器:一种用来修饰容器或者仿函数或者迭代器的东西
-
空间配置器:负责空间的分配和管理
容器
作用:存放数据,将广泛使用的数据结构给实现出来
常用的数据结构:数组、链表、树、栈、队列、集合、映射表等
容器的分类:
-
序列式容器:强调值的位置,每个元素都有固定的位置
-
关联式容器:二叉树结构,元素之间没有严格的物理上的顺序关系
算法
作用:问题的解法,即用有限的步骤,解决逻辑上的难题
算法的分类:
-
质变算法:运算中更改区间内元素的内容,如拷贝、替换、删除等
-
非质变算法:运算中不会更改区间内元素的内容,如查找、计数、遍历、寻值等
迭代器
作用:容器和算法之间的链接器,即就是提供一种方法,既能依序寻找容器内某个元素,又不暴露容器内部的表示方法
-
每个容器都有自己专属的迭代器
-
迭代器的使用方法类似于指针
-
最常用的是双向迭代器和随机访问迭代器
迭代器的种类:
| 种类 |
功能 |
支持运算 |
|---|---|---|
| 输入迭代器 |
对数据的只读访问 |
只读,支持++、==、!= |
| 输出迭代器 |
对数据的只写访问 |
只写,支持++ |
| 前向迭代器 |
对数据的向前操作 |
读写,支持++、==、!= |
| 双向迭代器 |
对数据的向前和向后操作 |
读写,支持++、-- |
| 随机访问迭代器 |
访问任何数据,功能最强 |
读写,支持++、--、[n]、-n、<、<=、>、>= |
String容器
基本概念
-
string是C++风格的字符串,但是本质上是一个类
-
String是内部封装了char类型,管理string这个类,用的是char*的容器
-
包含头文件#include
特点
-
string内部封装了很多成员函数方法,比如find查找,copy复制,delete删除,replace替换,insert插入等等
-
string管理char*所分配出来的内存,不用担心复制越界内存和取值越界,也不用担心溢出或者碎片,这些由容器内部统一管理
string构造函数
-
string();无参构造,主要用来创建一个空字符串
-
string(const char* s); 用来初始化一个字符串
-
string(const string& str); 用一个string对象来初始化另一个string对象
-
string(int n,char c); 初始化n个字符c
-
以上构造函数没有什么可比性,根据实际情况灵活运用即可
示例:
#include //只要涉及到string,就要包含其头文件
int main()
{
string s1; //1、用于创建一个空的字符串
const char* str = "中秋节";
string s2(str); //2、创建一个字符串s2,将字符串s1初始化赋值给字符串s2
cout << "str2 = " << s2 << endl;
string s3(s2); // 调用拷贝构函数
cout << "str3 = " << s3 << endl;
string s4(10,'A'); //3、创建一个字符串4,初始化赋值为10个‘A’
cout << "str4 = " << s4 << endl;
} 赋值操作
作用:给string字符串赋值
函数原型:
-
string& operator= ( const char *s ) ; 将char *类型的字符串赋值给当前字符串
-
string& operator= ( const string &s ) ; 将string类型字符串赋值给当前字符串
-
string& operator= ( char c ) ; 将字符c赋值给当前字符串
-
string& assign ( const char*s ) ; 将char *类型字符串赋值给当前字符串
-
string& assign ( const char *s, int n ) ; 将char *类型的字符串的前n个字符赋值给当前字符串
-
string& assign ( const string &s ) ; 将const类型的字符串赋值给当前字符串
-
string& assign ( int n,char s ) ; 将n个字符s赋值给当前字符串
示例:
int main()
{
string s1;
s1 = "hello C++"; //相当于operator=("hello C++"),由编译器进行内部转化
cout << "s1 = " << s1 << endl;
string s2;
s2 = s1; //相当于operator=(s1),由编译器进行内部转化
cout << "s2 = " << s2 << endl;
string s3;
s3 = 'A'; //相当于operator=('A'),由编译器进行内部转化
cout << "s3 = " << s3 << endl;
string s4;
s4.assign("Hello C++"); //也就是 string& assign ( const char *s)
cout << "s4 = " << s4 << endl;
string s5;
s5.assign(s4); //也就是 string& assign ( const string &s )
cout << "s5 = " << s5 << endl;
string s6;
s6.assign("hello C++",5); //也就是 string& assign ( const char *s,int n)
cout << "s6 = " << s6 << endl;
string s7;
s7.assign(10,'A'); //也就是 string& assign ( int n, char s)
cout << "s7 = " << s7 << endl;
}字符串拼接
作用:就是在字符串末尾再拼接一段字符串
函数原型:
-
string& operator+ ( const char *c ) ; //将char*类型的字符串拼接到当前字符串末尾
-
string& operator+ ( const char c ) ; //将字符c拼接到当前字符串末尾
-
string& operator+ ( const string& str ) ; //将string类型的字符串拼接到当前字符串末尾
-
string& append ( const char *s ) ; //将char*类型的字符串拼接到当前字符串末尾
-
string& append ( const char *s , int n ); //将char*类型字符串的前n个字符拼接到当前字符串末尾
-
string& append ( const string &s ) ; // 将string类型额字符串拼接到当前字符串末尾
-
string& append ( const string &s, int pos , int n ); //将string类型的字符串从pos个开始的n个字符拼接到当前字符串末尾
示例:
int main()
{
string s1 = "I";
s1 += "love games"; //相当于 string& operator+ ( const char *c ),由编译器内部自动转化
cout << "s1 = " << s1 <字符串比较
作用:字符串之间的比较
特点:
-
以其中的字符的ASCII值得方式进行比较
-
> 返回 1
-
< 返回 -1
-
= 返回 0
-
主要是用来比较两个字符串是否一样,比较大小没有什么意义
函数原型:
-
int compare ( const string& s) const ; //与string类型的字符串进行比较
-
int compare ( const char s ) const ; //与char*类型的字符串进行比较
示例:
int main()
{
string s1 = "dafwfw" ;
string s2 = "dasff" ;
if ( s1.compare( s2 ) == 0)
{
//主要是用来比较是否相等
}
else if (s1.compare(s2) > 0)
{
}
else
{
}
}字符存取
对单个字符进行存取有两种方法:
-
通过 [ ] 方式进行存取
-
通过at函数方式进行存取
函数原型:
-
char& operator[](int n) ; //通过[]方式存取
-
char& at(int n); //通过at方式存取
示例:
int main()
{
string s1 = "hello C++";
for(int i = 0 ; i < s1.size(); i++)
{
cout << s1[i] << endl; //通过 [] 方式读取
cout << s1.at(i) << endl; //通过 at 方式读取
}
str[0] = 'H'; //通过[]方式修改
str.at(1) = 'E'; //通过at方式修改
cout << s1 << endl ;
}字符的插入和删除
作用:对字符串中进行插入和删除字符的操作
函数原型:
-
string& insert ( int pos , const char* s ) ; //从pos位置开始插入字符
-
string& insert ( int pos , const string& s); //从pos位置开始插入字符
-
string& insert ( int pos , int n, char s); //从pos位置开始,插入n个字符s
-
string& erase( int pos , int n = npos ) ; //从pos位置开始,删除n个字符
-
参数pos的位置,都是从下标0开始的
示例:
int main()
{
string s1 = "hello" ;
s1.insert(1 , "aaaa"); //从下标1位置开始,插入字符串“aaaa”
cout << s1 << endl;
s1.erase( 1, 4 ); //从下标1位置开始,删除4个字符
cout << s1 << endl;
system("pause");
return 0;
}字符串子串
作用:从字符串中截取想要的子串
函数原型:
-
string substr( int pos , int n = npos) const ; //从pos位置开始,截取n个字符
示例:
int main()
{
string s1 = "safagrgwg";
string substr = s1.substr( 0 , 3 ); //从s1字符串中,从位置0开始,截取3个字符作为子串
cout << substr << end;
system("pause");
rerurn ;
}Vector容器
基本概念
-
vector数据结构与数组非常相似,但是只能进行尾部的插入和删除,所以也被称为单端数组
-
vector容器的迭代器是支持随机访问的迭代器,功能最强大的迭代器之一
-
包含头文件 #include
与普通数组的区别
-
数组是静态空间
-
vector可以动态扩展
-
动态扩展并不是在原空间上续接新空间,而是寻找更大的空间,将原数据拷贝过去,在新空间后续接空间,释放源空间
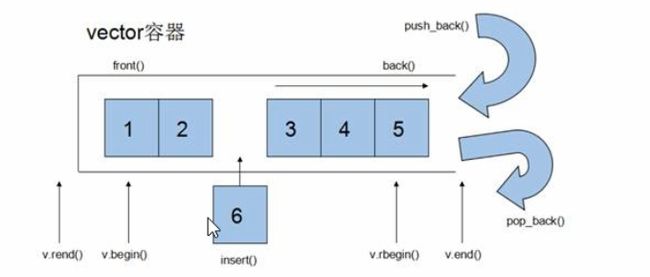 vector容器结构以及成员函数
vector容器结构以及成员函数
构造函数
作用:创建vector容器
函数原型:
-
vector
v ; //默认构造函数,T 是数据类型 , v是容器名字 -
vector ( v.begin() , v.end() ) ; //将v.[ begin() , end() ) 区间中的元素拷贝给本身
-
vector ( n , a ) ; //构造函数将 n 个 a 数值拷贝给本身
-
vector ( const vector &ver ) ; //拷贝构造函数
示例:
int main()
{
vector v1; //创建方法一:默认构造,无参构造
for ( int i = 0; i< 10; i++)
{
v1.push_back(i); //将0~9这些参数填入容器中
}
vector v2 ( v1,begin(), v1.end()); //创建方法二:将v1容器中的数据拷贝给容器v2
vector v3( 10, 100 ); //创建方法三:将10个100填入容器v3
vector v4( v3 ); //创建方法四:将v3容器数据拷贝给容器v4
system("pause");
return 0;
} vector赋值
作用:给vector容器进行赋值操作
函数原型:
-
vector& operator= ( const vector &vst ) ; //重载方式进行赋值
-
assign ( begin , end ) ; //将 [ begin , end )区间内的数值赋值给本身
-
assign (n , A) ; //将n个字符A赋值给本身
示例:
int main()
{
vector v1;
for(int i = 0 ; i < 10; i++)
{
v1.push_back(i);
}
vector v2; //赋值方法一:重载赋值
v2 = v1;
vector v3;
v3.assign(v1,begin() , v1.end() ); //赋值方式二:将v1的区间[begin ,end) 数据赋值给v3
vector v4;
v4.assign(10 , 200); //赋值方式三,将10个200赋值给v4
} 容量和大小
作用:获取vector容器的容量和大小参数
函数原型:
-
empty ( ) ; //判断是否为空
-
capacity ( ) ; //获取容器的容量
-
size ( ) ; //获取元素个数
-
resize ( int num ) ; //重新指定容器长度,容器变长,超出的用0表示;容器变短,超出的被删除
-
resize ( int num,int elem ) ; //重新指定容器元素,容器变长,超出的用elem表示,变短则超出的被删除
示例:
void PrintVector(vector& v) //利用迭代器写出的打印容器函数
{
for(vector::iterator i = v.begin();i < v.end(); i++)
{
cout << *i << " " ;
}
cout << endl;
}
int main()
{
vector v;
for( int i = 0;i < 10; i++)
v.push_back(i);
PrintVector(v);
if( v.empty() ) //判断容器是否为空
{
cout << "容器v为空" << endl;
}
else
{
cout << " 容器v不为空" << endl;
cout << "容器v的容量为:" << v.capacity() << endl; //获取容器的容量
cout << "容器v的大小为:" << v.size() << endl; //获取容器的元素个数
}
v.resize( 15 , 100); //重新指定容器长度
//如果超出容器本身长度,超出的用100表示
//如果比容器本身小,多余的会被删除
PrintVector(v);
v.resize ( 5 ); //重新指定容器长度
//如果超出容器本身长度,超出的默认0表示
//如果比容器本身小,多余的会被删除
PrintVector(v);
} 插入和删除
作用:在容器中插入元素和删除元素
函数原型:
-
push_back ( ) ; //尾部插入
-
pop_back ( ) ; //删除尾部最后一个元素
-
insert ( const_iterator pos , elem ) ; //插入元素elem,第一个参数是迭代器指向位置
-
insert (const_iterator pos , int num , elem ) ; //插入num个elem数值,第一个参数是迭代器指向位置
-
erase ( const_iterator pos ); //删除元素,第一个参数是迭代器指向位置
-
erase ( const_iterator begin , const_iterator end ); //删除从头到尾的元素
-
clear ( ); //删除容器内全部元素
示例:
void PrintVector( vector& v) //一个打印函数,用于打印容器内的数据
{
for( vector::iterator i = v.begin(); i v;
for(int i=0;i<10;i++)
v.push_back( i ); //尾部插入0~9元素
PrintVector(v);
v.pop_back(); //删除最后一个元素
PrintVector(v);
v.insert(v.begin() , 100); //在迭代器begin位置插入元素100
PrintVector(v);
v.insert( v.begin() , 3, 100 ); //在迭代器begin位置插入3个元素100
PrintVector(v);
v.erase( v.begin() ); //产出迭代器begin位置的元素
PrintVector(v);
v.erase( v.begin() , v.end() ); //产出迭代器从begin到end之间的元素
PrintVector(v);
v.clear(); //删除容器内全部元素
PrintVector(v);
system("pause");
return 0;
} 数据存取
作用:获取容器中的数据
函数原型:
-
at ( int idx ) ; //返回索引下的元素
-
operator[ ] ; //重载方式返回索引下的元素
-
front ( ) ; //获取容器第一个元素
-
back ( ) ; //获取容器中最后一个元素
示例:
int main()
{
vector v;
for(int i = 0; i< 10; i++)
{
v.push_back ( i ) ; //开始填充容器元素
}
for(i = 0; i< 10; i++)
cout << v[i] << " "; //以重载方式operator[]获取容器元素
cout << endl;
for(i = 0;i < 10; i++)
cout << v.at(i) << " "; //以at()方式获取容器元素
cout << endl;
cout << "容器v的的第一个元素:" << v.front() << endl; //获取第一个元素v.front()
cout << "容器v的最后一个元素:" << v.back() << endl; //获取最后一个元素v.back()
} 容器互换
作用1:实现两个容器之间的元素互换
作用2:用于收缩容器容量(原理就是创建一个小容量的容器与本身的大容量容器互换)
函数原型:
-
swap( vec ) ; //将容器vec中的元素与本身互换
示例:
void PrintVector( vector& v )
{
for(vectot::iterator it = v.begin(); it < v.end(); it++)
{
cout << *it << " ";
}
cout << endl;
}
int main()
{
//==========================作用1:容器元素互换========================================//
vector v1;
for(int i = 0 ; i< 10 ; i++)
v1.push_back(i);
vector v2;
for(int i = 10; i > 0; i--)
v2.push_back(i);
PrintVector(v1); //元素互换之前
PrintVector(v2);
v1.swap ( v2 ) ;
PrintVector(v1); //元素互换之后
PrintVector(v2);
//==============================作用2:收缩容器内存============================================//
vector v;
for(int i = 0; i < 10000; i++) //创建一个容器,里面有10000个元素
v.push_back(i);
cout << "此时容器大小为:" << v.size() << endl; //此时大小 = 10000
cout << "此时容器的容量为:" << v.capacity() << endl; //此时容量 > 10000
v.resize(3); //重新指定容器大小 = 3
cout << "此时容器大小为:" << v.size() << endl; //此时大小 = 3
cout << "此时容器的容量为:" << v.capacity() << endl; //但是此时容量依旧是 > 10000,这就很浪费内存
vector v.swap ( v ) ; //以v为拷贝,创建一个匿名对象x,此时x大小和容量 = 3
//将容器x 与 容器v进行互换
//容器x变成了容器v,此时x的大小 = 3,,容量 > 10000
//容器v就换成了容器x,此时v就变成大小和容量 = 3
//而容器x由于是匿名对象,执行完其内存就后就被系统释放掉了
cout << "此时容器的容量为:" << v.capacity() << endl; //此时容器v的容量 = 3
cout << "此时容器大小为:" << v.size() << endl; //此时容器的大小 = 3
} 预留内存
作用:在一开始就开辟出足够的空间,减少动态扩展的次数
原理:因为一旦容器输入数据量较大的时候,编译器会根据内存实际情况时不时进行动态扩展,动态扩展次数一旦多了,操作时间就长了,所以最好是在一开始就预留足够多的空间,将动态扩展次数维持为1次。
函数原型:
-
reserve ( int len ) ; //预留len个元素长度,预留位置不初始化,也不可以访问
示例:
int main()
{
vector v;
v.reserve(10000); //从一开始就预留10000个元素大小的内存
int num = 0;
int *p = NULL:
for(int i = 0; i< 10000; i++)
{
v.push_back( i );
if( p != &v[0]) //以 指针p实时跟踪容器首元素位置 来确定动态扩展次数
{
p = &v[0];
num ++;
}
}
cout << "动态扩展的次数:" << num << endl;
} vector排序
-
作用:利用算法对容器内元素进行排序
-
需要包含算法头文件 #include
-
对于随时访问的迭代器都可以使用该排序函数
函数原型:
-
sort( iterator begin , iterator end ) ; // 对begin和end之间的元素进行从小到大排序
示例:
void PrintVector( const vector& dv)
{
for( vector::const_iterator it = d.begin(); it != d.end(); it++ )
{
cout << *it << " ";
}
cout << endl;
}
int main()
{
vector d;
d.push_back(10);
d.push_back(30);
d.push_back(20);
d.push_back(100);
d.push_back(50);
d.push_back(70);
Printvector(d); //排序前
sort( d.begin(), d.end() ); //进行排序
Printvector(d); //排序后
system("pause");
return 0;
} deque容器
-
与数组类似,可以进行头部和尾部的插入和删除,因为也被称为双端容器
-
deque容器的迭代器也是支持随机访问的
-
头文件#include
deque与vector的区别:
-
vector容器只能尾部插入和删除,因为对于头部操作效率很低,数据量越大越低
-
deque容器头部的插入和删除速度比vector快多了
-
vector和deque内部结构不同,导致元素的速度vector会更快,导致deque没有容量限制,可以无限扩张
-
二者的迭代器都支持随机访问,是最强大的迭代器之一
 deque内部结构和成员函数
deque内部结构和成员函数
内部工作原理
-
deque内部有一个中控器,用于记录每段缓冲区的地址,缓冲区中放置真实数据
-
中控器+缓冲区,使得deque看起来像是一块连续的内存
 deque内部工作原理
deque内部工作原理
构造函数
作用:创建deque容器
函数原型:
-
deque
d ; //默认构造函数,T表示数据类型 -
deque( begin , end ) ; //将容器[ begin , end )区间内的数据拷贝给本身
-
deque( count , elem ) ; //将count个elem数值拷贝给本身
-
deque ( const deque& d ) ; //拷贝构造函数,将容器数据整个拷贝给本身
示例:
void PrintDeque( const deque& d ) //为了放置d容器被中间意外修改,最后增加const修饰
{
for(deque::const_iterator i = d.begin(); i != d.end(); i++) //迭代器就得使用const修饰的迭代器
{
cout << *i << " ";
}
cout << endl;
}
int main()
{
deque d1; //构造方法一:无参构造
for( int i = 0; i < 10 ; i++)
{
d1.push_back(i);
}
PrintDeque(d1);
deque d2( d1.begin() , d1.end() ); //构造方法二:将d1的[begin() , end()) 区间之内的数据拷贝给容器d2
PrintDeque(d2);
deque d3(10 , 200); //构造方式三:将10 个 200 拷贝给容器d3
PrintDeque(d3);
deque d4 (d1); //构造方式四:将d1容器整个拷贝给d4
PrintDeque(d4);
system("pause");
return 0;
} 赋值操作
作用:给deque容器进行赋值
函数原型:
-
deque& operator=( const deque& d) ; //重载方式进行赋值
-
assign ( begin , end ); //将[ begin , end )区间内的数据赋值给容器
-
assign ( count , elem ); //将count个elem数值赋值给容器
示例:
void PrintDeque ( const deque& d )
{
for( deque::const_iterator it = d.begin(); it != d.end(); it++ )
{
cout << *it << " " ;
}
cout << endl;
}
int main()
{
deque d1;
for(int i = 0; i< 10; i++)
d1.push_back( i );
PrintDeque(d1);
deque d2;
d2 = d1; //赋值方式一:重载方式
PrintDeque(d2);
deque d3;
d3.assign( d1.begin() , d1.end() ); //赋值方式二:将d1的[ begin , end )之间数据赋值给d3
PrintDeque(d3);
deque d4;
d4.assign( 10 , 200); //赋值方式三:将10个200赋值给容器d4
PrintDeque(d4);
system("pause");
return 0;
} 获取大小,没有容量限制
-
作用:获取deque内部的元素长度
-
由于中控器+缓冲区的内部结构,导致deque是没有容量限制的,理论上内存可以无限扩张,所以没有获取容量的函数
函数原型:
-
empty( ) ; // 判断容器是否为空
-
size( ) ; //获取元素个数
-
resize ( num ) ; //重新指定容器长度,若容器变长,以默认值0填充新位置;若长度变短,超出部分删除
-
resize ( num , elem ) ; //重新指定容器长度,若容器变长,以elem填充新位置,若变短,超出部分删除
示例:
void PrintfDeque(const deque& d)
{
for( deque::const_iterator i = d.begin(); i != d.end(); i++ )
{
cout << *i << " " ;
}
cout << endl;
}
int main()
{
deque d;
for(int i = 0; i < 10 ; i++ )
d.push_back(i);
if ( d.empty() )
{
cout << "容器d为空:" << endl;
}
else
{
cout << "容器d不为空:" << endl;
PrintfDeque(d);
cout << "容器d的长度为:" << d.size() << endl;
}
d.resize( 5 );
PrintDeque(d);
d.resize(10 ,100);
PrintfDeque(d);
system("pause");
return 0;
} 插入和删除
作用:在容器两端进行插入和删除新数据
函数原型:
-
push_back( elem); // 尾部插入数据elem
-
push_front( elem); //头部插入数据elem
-
pop_back( ); //删除最后一个元素
-
pop_front( ); //删除第一个元素
-
insert( pos ,elem); //在迭代器位置pos插入数据elem
-
insert( pos , n, elem ); //在迭代器位置pos插入n个elem数据
-
insert( pos, begin, end ); //在迭代器位置pos插入[begin , end)区间内的数据
-
erase( pos); //删除迭代器位置pos的数据
-
erase( begin , end ); //删除从begin到end之间的数据
-
clear(); //删除容器内所有元素
示例:
void PrintDeque( const deque& d )
{
for( deque::const_iterator it = d.begin(); it != d.end(); it++)
cout << *it << " " ;
cout << endl;
}
int main()
{
deque d1;
for(int i = 0; i< 10 ; i++)
d1.push_back(i); //容器尾部添加数据
PrintDeque(d1);
d.push_front(100); //容器头部插入100
d.pop_back(); //删除最后一个元素
d.pop_front(); //删除第一个元素
PrintDeque(d1);
deque d2;
deqeu::iterator i = d2.begin(); //用迭代器指定位置
d2.insert(i , 100 ); //在指定位置 i 插入100
d2.insert(i+1 , 2, 50 ); //在指定位置 i 插入2个50
PrintDeque(d2);
d2.insert(i , d1.begin(), d1.end() ); //在指定位置 i 插入d1的[begin , end )所有数据
PrintDeque(d2);
d2.earse(i); //删除指定位置的元素
d2.erase(d2.begin(), d2.end() ); //删除从begin到end之间的元素
d2.clear(); //删除容器内所有元素
PrintDeque(d2);
} 数据存取
作用:对deque容器中的数据进行存取
函数原型:
-
operator[ ] ; //重载方式返回索引idx的数据
-
at( int dix ) ; //at()返回索引idx的数据
-
front( ) ; //返回第一个元素
-
at( ) ; //at()返回索引idx的数据
示例:
void PrintDeque( const deque& d )
{
for( deque::const_iterator it = d.begin(); it != d.end(); it++)
cout << *it << " ";
cout << endl;
}
int main()
{
deque d;
for(int i = 0;i< 10;i++ )
{
d.push_back(i);
}
for(i=0;i<10;i++)
cout << d[i] << " "; //重载方式获取容器元素
cout << endl;
for(i = 0;i<10;i++)
cout << d.at(i) << " " ; //at()方式获取容器元素
cout < deque排序
-
作用:利用算法对容器内元素进行排序
-
需要包含算法头文件 #include
-
对于随时访问的迭代器都可以使用该排序函数,包括vector容器
函数原型:
-
sort( iterator begin , iterator end ) ; // 对begin和end之间的元素进行从小到大排序
示例:
void PrintDeque( const deque& d )
{
for( deque::const_iterator it = d.begin(); it != d.end(); it++ )
{
cout << *it << " ";
}
cout << endl;
}
int main()
{
deque d;
d.push_back(10);
d.push_back(30);
d.push_back(20);
d.push_back(100);
d.push_back(50);
d.push_back(70);
PrintDeque(d); //排序前
sort( d.begin(), d.end() ); //进行排序
PrintDeque(d); //排序后
system("pause");
return 0;
} stack容器
-
stack容器是一种前进后出的数据结构,又称为栈容器
-
该容器只有顶端的元素才可以给外界获取
-
该容器不允许有遍历行为
-
包含头文件 #include
 stack容器内部结构以及成员函数
stack容器内部结构以及成员函数
构造函数
函数原型:
-
stack
stk ; //默认构造函数 -
stack( const stack &stk ) ; // 拷贝构造函数
赋值操作
函数原型:
-
stack& operator=( const stack& stk ) ; //重载方式进行赋值
数据存取
函数原型:
-
push( elem ) ; //向栈顶添加元素
-
pop( ) ; //删除栈顶第一个元素
-
top( ) ; //返回栈顶元素
大小获取操作
函数原型:
-
empty( ) ; //判断容器是否为空
-
size( ) ; // 返回容器的大小
示例:
int main()
{
stack stk; //创建一个栈容器
for(int i = 0; i< 10; i++ )
{
stk.push(i); //往栈顶添加元素
}
while( !stk.empty() ) //判断栈是否为空
{
cout << "栈顶的元素为:" << stk.top() << endl; //返回栈顶元素
cour << "栈的长度为:" << stk.size() << endl; //返回栈的大小
stk.pop(); //删除栈顶元素
}
system("pause");
return 0;
} queue容器
-
queue容器是一种先进先出的数据结构,又称为队列容器
-
允许从一段添加元素,另一端删除元素
-
只有队尾和队头可以被外界使用,因此不允许有遍历行为
-
包含头文件 #include
 queue内部结构和成员函数
queue内部结构和成员函数
构造函数
函数原型:
-
queue
que ; //默认构造函数 -
queue( const queue& que ) ; //拷贝构造函数
赋值操作
函数原型:
-
queue& operator=( const queue& que ) ; //重载方式赋值
数据存取
函数原型:
-
push( elem ) ; //往队尾添加元素
-
pop( ) ; //删除队头的元素
-
back( ) ; //返回最后一个元素
-
front( ) ; //返回第一个元素
大小获取
函数原型:
-
empty( ) ; //判断队列是否为空
-
size( ) ; // 判断队列的大小
示例;
class Person()
{
public;
Person(string name , int age)
{
this->m_name = name;
this->m_age = age;
}
string m_name;
int m_age;
}
int main()
{
queue q;
Person p1("张三" ,10 );
Person p2("李四" , 20 );
Person p1("王五" ,30 );
Person p1("赵六" ,40 );
q.push(p1);
q.push(p2);
q.push(p3);
q.push(p4);
while( !empty() )
{
cout << "第一元素:" << q.front() << endl;
cout << "最后一个元素:" << q.back() << endl;
cout << "容器的长度:" << q.size() << endl;
q.pop();
}
} list容器
-
list容器是一种双向循环的数据结构,又称为链式容器
-
内部结构并不是连续的内存,迭代器不能随访问,只能前移和后移,属于双向迭代器
-
包含头文件 #include
-
动态存储分配,不会存在内存浪费和溢出的问题
-
随机访问,插入和删除非常方便
-
占用空间比较大,遍历的消耗非常大
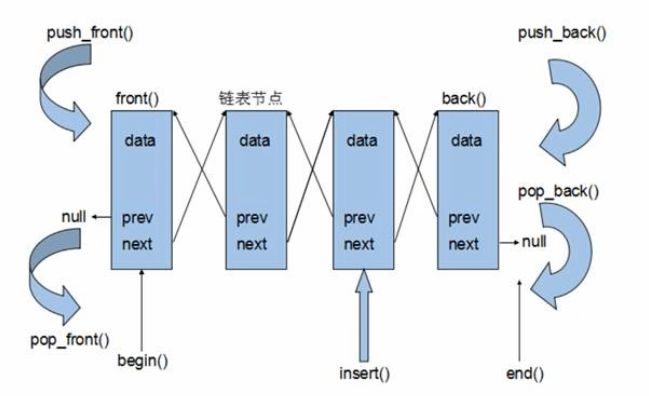 list容器内部结构以及成员函数
list容器内部结构以及成员函数
构造函数
作用:创建一个list容器
函数原型:
-
list
lst ; //默认构造函数 -
list( begin , end ) ; //将区间 [ begin ,end)之间的元素拷贝给本身
-
list( n , elem ) ; // 将 n个elem拷贝给本身
-
list( const list &lst) ; // 拷贝构造函数
赋值与交换
作用:给list容器赋值,以及交换list容器
函数原型:
-
list& operator=( const list& lst ) ; // 重载方式进行赋值
-
assign( begin() , end() ) ; //将区间[ begin , end)之间的元素赋值给本身
-
assign( n , elem ) ; //将 n 个 elem赋值给本身
-
swap( lst ) ; // 将容器 与 本身的元素互换
示例:
void PrintList( const list& L)
{
for( list::const_iterator it = L.begin(); it!=L.end(); it++ )
{
cout << *it << " " ;
}
cout << endl;
}
int main()
{
list L1; //创建方法一:默认构造函数L1
for( int i = 0 ; i<10; i++ )
L1.push_back( i );
PrintList(L1);
list L2( L1.begin() , L1.end() ); //创建方法二:将L1区间[ begin , end )之间的数据拷贝给L2
PrintList(L2);
list L3( 10 ,100 ); //创建方法三:将 10 个 100 拷贝给L3
PrintList(L3);
List L4(L1); //创建方法四:将L1整个容器本身拷贝给L4
PrintList(L4);
List L5;
L5 = L1; //赋值方式一:重载方式赋值
PrintList(L5);
List L6;
L6.assign( L1.begin() , L1.end() ); //赋值方式二:将L1[begin ,end)之间的元素赋值给L6
PrintList(L6);
List L7;
L7.assign( 10 , 200 ); //赋值方式三:将10 个 200 赋值给L7
PrintList(L7);
L7.swap( L6 ); //将容器L6 与容器 L7 进行元素交换
PrintList(L6);
PrintList(L7);
} 大小操作
作用:获取容器list的长度
函数原型:
-
size( ) ; //返回元素个数
-
empty( ) ; // 判断是否为空
-
resize( num ) ; //重新指定容器长度,容器变长,以默认值0填充,容器变短,超出的元素被删除
-
resize( num , elem ) ; //重新指定容器长度,容器变长,以数值elem填充,容器变短,超出的元素被删除
示例:
void PrintList( const list& L)
{
for( list::const_iterator it = L.begin(); it!=L.end(); it++ )
{
cout << *it << " " ;
}
cout << endl;
}
int main()
{
list L1;
for( int i = 0 ; i<10; i++ )
L1.push_back( i );
PrintList(L1);
if( L1.empty()) // 判断容器是否为空
{
cout << "L1 为空:" << endl;
}
else
{
cout << "L1不为空:" << endl;
cout << "L1的元素个数为:" << L1.size() << endl; //判断容器的长度
}
L1.resize( 5 ); //重新指定容器大小为5,超出长度5的元素被删除
PrintList(L1);
L1.resize(10 , 10000); //重新指定容器大小为10,超出原有长度的位置用10000填充
PrintList(L1);
} 插入和删除
作用:对list容器进行元素插入和删除
函数原型:
-
push_back( elem ); //尾部插入数据
-
push_front( elem ); //头部插入数据
-
pop_back(); //删除最后一个元素
-
pop_front(); //删除第一个元素
-
insert( pos, elem ); //在迭代器pos位置插入数值elem
-
insert( pos , n , elem ); //在迭代器pos位置插入n个elem
-
insert( pos , begin , end ); //在迭代器pos位置插入从begin到end之间的元素
-
erase( pos ); //删除迭代器pos位置的元素
-
erase( begin , end ); //删除迭代器[ begin , end ) 之间的元素
-
remove( elem ); //删除容器中与elem相同的所有元素
示例;
void PrintList( const list& L)
{
for( list::const_iterator it = L.begin(); it!=L.end(); it++ )
{
cout << *it << " " ;
}
cout << endl;
}
int main()
{
list L;
for(int i = 0;i<10; i++)
{
L.push_back(i); //尾部插入元素
L.push_front(i); //头部插入元素
}
PrintList(L);
L.pop_front(); //删除第一个元素
L.pop_back(); //删除最后一个元素
PrintList(L);
list::iterator it = L.begin();
L.insert( it , 1000); //在迭代器it位置插入1000
L.insert( it++ ,5, 1000); //在迭代器it++位置插入5个1000
PrintList(L);
L.remove( 10000 ); //移除容器中与1000相同的所有元素
PrintList(L);
list L1;
L1.insert( L1.begin() , L.begin() , L.end() ); //将L[begin,end)之间的元素赋值给L1容器
PrintList( L1 );
L1.erase(L1.begin); //擦除迭代器位置的元素
L1.earse( L1.begin() , L1.end() ); //擦除容器从begin到end之间的元素
PrintList( L1 );
system("pause");
return 0;
} 数据存取
-
存取方式不是[]获取,也不是at()获取
-
因为list容器本质是链表,既不是连续的内存,迭代器也不支持随机访问
函数原型:
-
front(); // 返回第一个元素
-
back(); // 返回最后一个元素
示例:
void PrintList( const list& L)
{
for( list::const_iterator it = L.begin(); it!=L.end(); it++ )
{
cout << *it << " " ;
}
cout << endl;
}
int main()
{
list L;
for(int i = 0;i<10; i++)
{
L.push_back(i); //尾部插入元素
}
PrintList(L);
cout << "第一个元素是:" << L.front() << endl;
cout << "最后一个元素是:" << L.end() << endl;
list::iterator it = L.begin();
it++; //√,没报错,说明迭代器支持前移
it--; //√,没报错,说明迭代器支持后移
//it = it + 1 ; //×,编译器报错,说明迭代器不支持地址随机跳跃,it = it-1也一样不行
//it = it + 2 ; //×,编译器报错,说明迭代器不支持地址随机跳跃,it = it-2也一样不行
//it = it + x ; //×,编译器报错,说明迭代器不支持地址随机跳跃,it = it-x也一样不行
system("pause");
return 0;
} 反转和排序规则
作用:将容器中的元素反转,以及对元素进行排序
函数原型:
-
reverse(); //容器元素进行反转
-
sort(); //容器元素进行从小到大排序,没有迭代器参数,所以这个是内部成员函数,不是标准算法
-
//对于定义数据类型,必须要指定排序规则(高级排序),否则编译器是不知道怎么排的
示例:
void PrintList( const list& L)
{
for( list::const_iterator::it = L.begin(); it!= L.end(); it++ )
{
cout << *it << " " ;
}
cout << endl;
}
bool mycompare(int v1 , int v2) //指定排序规则,提供降序方法
{
return v1 > v2 ; //指定规则:第一个数 > 第二个数,代表降序
}
int main()
{
list L;
L.push_back(10);
L.push_back(30);
L.push_back(50);
L.push_back(80);
L.push_back(60);
PrintList(L); //反转前
L.reverse();
PrintList(L); //反转后
//sotr( L.begin(), L.end() ); //×,因为list迭代器不支持随机访问,所以不能使用标准算法库的函数
L.sort(); //√,list容器内部提供一个自己的排序算法,排序是从小到大
L.sort(myCompare); //√,提供一个降序排序,这是底层算法决定的,会用就行
system("pause");
return 0;
} set/multiset容器
-
在set/multiset容器中,所有的元素都会在插入时自动排序,默认从小到大
-
两者属于关联式容器,内部结构是用二叉树实现的
-
两者的头文件都是 #include
set和multiset的区别:
-
set容器不允许有重复的元素出现,即使强制插入重复元素,插入也会失败
-
multiset容器可以有重复的元素出现
set的构造函数
作用:创建set容器
函数原型:
-
set
st ; // 默认构造函数 -
set(const set& st) ; //拷贝构造函数
set的赋值函数
函数原型:
-
set& operator( const set& st); // 函数重载实现赋值操作
set的插入和删除
函数原型:
-
insert( elem ) ; // 插入只有insert()方式,不能指定位置,因为会自动排序
-
erase(pos) ; // 删除迭代器pos位置的元素
-
erase ( elem ); //删除数值为elem的元素
-
erase( begin , end ); //删除[ begin,end)之间的元素
-
clear(); //清除所有元素
set的大小和交换
-
作用:统计容器的大小以及交换set容器
-
没有重新指定容器大小的操作,因为会有默认值填充位置,而set容器中不能出现重复的元素
函数原型:
-
size( ); //返回容器中元素个数
-
empty( ); //判断容器是否为空
-
swap( ); // 交换两个集合容器中的数据
set的查找和统计
作用:对set容器进行数据查找以及数据统计
函数原型:
-
find( key ); //查找一个元素是否存在,存在则返回元素迭代器位置,不存在返回set.end()
-
cout( key ); //统计key的元素个数,对于set而言不是0就是1,因为不允许有重复元素
示例:
void PrintSet( const set& s)
{
for(set::const_iterator it = s.begin();it!= s.end();it++)
{
cout << *it << " " ;
}
cout << endl;
}
int main()
{
set s1; //默认构造函数创建set容器s1
s1.insert(10); //插入一些数据
s1.insert(50);
s1.insert(30);
s1.insert(60);
s1.insert(20);
PrintSet(s1);
set s2(s1); //拷贝构造函数,创建容器s2
PrintSet(s2);
set s3;
s3 = s1; //重载方式进行赋值
PrintSet(s3);
if( s1.empty())
{
cout << "容器s1为空" << endl;
}
else
{
cout << "容器s1不为空" << endl;
cout << "容器s1的个数:" << s1.size() << endl;
}
set s4;
for(int i = 0; i<10;i++)
{
s4.insert(i); //插入一些元素
}
PrintSet(s4);
s4.swap(s1); //s4与s1容器进行交换
PrintfSet(s4);
s4.erase( s4.begin() ); //删除迭代器位置begin的元素
PrintSet(s4);
s4.erase( 5 ); // 删除数值为 5 的元素
PrintSet(s4);
erase(s4.begin() , s4.end()); // 删除在[begin,end)区间之间的元素
PrintSet(s4);
s4.clear(); //清除所有元素
PrintSet(s4);
set::iterator pos = s1.find(30); //查找元素是否存在,存在则返回元素的迭代器位置
if( pos != s1.end() )
{
cout << "找到元素:" << *pos << endl;
}
else
{
cout << "没有找到元素" << endl;
}
cout << "统计元素个数" << s1.count(30) << endl; //统计元素30的个数
//对于set容器而言,不是0就是1,因为其不会出现重复的元素
} set和multiset的区别
-
set不可以插入重复数据,而multiset可以
-
set插入数据会返回插入结果,同时也是这样检测是不是重复元素
-
multiset插入数据不会检测,因此可以插入重复数据
set.insert()的函数原型:
-
_Pairib insert( value_type&& _Val) ;
-
using _Pairib = pair
; //set.insert()的返回值类型是对组,返回迭代器位置和插入结果
multiset.insert()的函数原型:
-
iterator insert(value_type&& _Val); //multiset.insert()返回值类型只有迭代器位置,没有检测结果
示例:
void PrintfSet( set& s)
{
for( set::iterator it = s.begin(); it != s.end(); it++)
{
cout << *it << " " ;
}
cout << endl;
}
int main()
{
set s;
pair::iterator, bool> ret = s.insert(10); //获取第一次插入数据的迭代器位置和插入结果
if(ret.second) //ret.second存放的就是插入结果
cout << "第一次插入成功" << endl;
else
cout << "第一次插入失败" << endl;
ret = s.insert(10); //获取第二次插入的迭代器位置和插入结果
if(ret.second)
cout << "第二次插入成功" << endl;
else
cout << "第二次插入失败" << endl; //因为是插入了相同的元素,所以这一次的插入失败
multiset ms; //multiset容器是可以插入相同元素的
ms.insert(30);
ms.insert(30);
PrintSet(ms);
} pair对组创建
作用:成对出现的数据,可以返回两个数据
创建方法的函数原型:
-
pair
p (value1, value2 ); -
pair
p = make_pair( value1, value2 );
示例:
int main()
{
pair p1("Tom" , 20); // 第一种创建方式
cout << "姓名:" << p1.first << "年龄:" << p1.second << endl;
pair p2 = make_pair("jerry" , 30); // 第二种创建方式
cout << "姓名:" << p2.first << "年龄:" << p2.second << endl;
system("pause");
return 0;
} set容器排序
-
作用:set容器排序是默从小到大,但是可以可以通过仿函数来改变排序规则
-
要在插入数据之前就指定排序规则
-
如果是自定义数据类型,一定要指定排序规则
示例1:指定排序规则——内置数据类型
class Mycompare
{
public:
bool operator()( int val1,int val2)
{
return val1 > val2 ;
}
};
int main()
{
//set s1; //这么写,那插入的数据肯定就是默认从下到大了
set s1; // 既然要指定排序规则,就要在插入之前做好指定,由MyCompare类型来指定
//而set<>中的参数只能是数据类型,所以MyCompare得用数据类型来表示,不能用函数名
s1.insert(30); //现在插入的数据,就会根据Mycompare来降序排或者升序排
s1.insert(10);
s1.insert(50);
s1.insert(40);
s1.insert(20);
for( set::iterator it = s1.begin(); it!=s1.end(); it++ )
{
cout << *it << " ";
}
cout << endl;
} 示例2:指定排序规则——自定义数据类型
class Person
{
public:
Person(string name , int age)
{
this->m_name = name;
this->m_age = age;
}
string m_name;
int m_age;
}
class ComparePerson
{
public:
bool operator()(set& p1 , set& p2)
{
return p1.m_age > p1.m_age ; //指定规则为按照年龄进行降序排序
}
};
int main()
{
set s;
Person p1("刘备" , 40); //如果没有指定排序规则的话,set容器都不知道按照什么进行排序,容器自己都蒙了
Person p2("关羽" , 30);
Person p3("张飞" , 28);
Person p4("赵云" , 20);
s.insert(p1); //此时插入数据,容器就会按照年龄来进行排序
s.insert(p2);
s.insert(p3);
s.insert(p4);
for(set::iterator it = s.begin(); it != s.s.end(); it++)
{
//cout << "姓名:" << *it.m_name << "年龄:" << *it.m_age << endl;
cout << "姓名:" << it->m_name << "年龄:" << it->m_age << endl;
}
system("pause");
return 0;
} map/multimap容器
-
map/multimap都是关联式容器,内部结构是二叉树
-
map容器中的元素全是pair对组
-
pair中第一个元素为key(键值,起到索引作用),第二个元素为value(实值)
-
所有的元素都会根据元素的key键值自动排序,默认从小到大
-
可以根据键值快速找到value值,高效率高性能
-
map/multimap两者的头文件都是#include
map和multimap的区别:
-
map容器中不允许有重复的key值元素
-
multimap容器中允许有重复的key值元素
map的构造函数
函数原型;
-
map
mp ; // 默认构造函数 -
map
; // 拷贝构造函数
map的赋值函数
函数原型:
-
map& operator=( const map& mp) ; // 重载等号操作符进行赋值操作
map的大小和交换
函数原型:
-
size(); // 返回元素个数
-
empty(); // 判断容器是否为空
-
swap(); // 交换两个map容器
map的插入和删除
函数原型:
-
insert(elem); // 插入元素,地址没法自定义,因为会自动排序
-
erase(key); // 删除key值的元素
-
erase(pos); // 删除迭代器pos位置的元素
-
erase(begin , end); // 删除区间为[begin,end)之间的元素
-
clear(); // 清除容器中所有元素
map的查找和统计
函数原型:
-
find( key ); //查找元素是否存在,存在则返回元素迭代器,不存在则返回map.end() ;
-
count( key ); //返回键值为key的元素的个数,对于map,不是0就是1,因为不允许出现重复元素
示例:
void PrintMap( map& m )
{
for( map::iterator::it = m.begin(); it != m.end(); it++)
{
cout << "key = " << *it.first << "value = " << it->second << endl;
}
cout << endl;
}
int main()
{
map m1; // 创建方式一:默认构造函数
m1.insert( pair(1,10) ); //插入方式一
m1.insert( pair(3,30) );
m1.insert( make_pair(2,20) ); //插入方式二
m1.insert( make_pair(4,40) );
m1.insert( map::value_type(6,60)) //插入方式三
m1.insert( map::value_type(7,70))
m1[6] = 90; //插入方式四,不建议用,如果插错了,value会被赋成0
m1[7] = 80; //不建议用这方式赋值,只适合用来访问
PrintMap(m1);
map m2(m1); //创建方式二:拷贝构造函数
PrintMap(m2);
map m3; //重载运算符进行赋值操作
m3 = m1;
if( m3.empty()) // 判断容器是否为空
cout << "map容器为空" << endl;
else
{
cout << "map容器不为空" << endl;
cout << "容器元素个数:" << m3.size() << endl; // 获取容器元素个数
}
map m4;
for(int i = 0;i<10 ;i++)
{
m4.insert( pair(i,i*10) );
}
PrintMap(m4); // 容器交换前
m4.swap(m1); //容器m4与m1进行交换
PrintMap(m4); //跟容器m1交换后
m4.erase(m4.begin()); //删除迭代器begin位置的元素
PrintMap(m4);
m4.erase(20); //删除key值为20的元素
PrintMap(m4);
m4.erase(m4.begin , m4.end); //删除区间为 [m4.begin , m4.end())之间的元素
PrintMap(m4);
m4.clear(); //清除容器m4中的所有元素
PrintMap(m4);
map::iterator pos = m1.find(3); //找到元素3,如果存在,则返回元素迭代器元素
if( pos != m1.end()) //如果不存在,则返回m1.end()
{
cout << "找到了元素" << endl;
cout << "key = " << *pos.first << "value = " << "*pos.second" << endl;
}
else
{
cout << "未找到元素" << endl;
}
int num = m1.count(3); //获取key = 3 的元素个数
cout << "num = " << num << endl; //对于map容器,不是1就是0
system("pause");
return 0;
} map容器排序
-
作用:利用仿函数,改变排序规则
-
排序规则一定要在插入数据前指定
示例:
class MyCompare
{
public:
bool operator()(int v1,int v2)
{
return v1 > v2 ; //指定降序的排序规则
}
};
int main()
{
map m;
m.insert( pair(1,10) );
m.insert( pair(3,30) );
m.insert( make_pair(2,20) );
m.insert( make_pair(4,40) );
m.insert( make_pair(6,60) );
m.insert( make_pair(5,50) );
for( map::iterator::it = m.begin(); it != m.end(); it++)
{
cout << "key = " << *it.first << "value = " << it->second << endl;
}
system("pause");
return 0;
} 函数对象/仿函数
-
本质上是一个类,重载函数调用运算符的类,其创建的对象也就被称为函数对象
-
因为函数对象在发生重载时,就像函数调用一样,所以也叫做仿函数
-
说白了就是一个对象,一个可以当函数用的对象
特点:
-
函数对象在使用时跟函数差不多,可以有参数,也可以有返回值
-
函数对象可以有自己的状态,函数没有
-
函数对象可以作为参数传递
示例:
calss MyAdd
{
public:
int oprator()(int v1, int v2) //特点1:本质是一个类,函数对象既可以有参数,也可以有返回值
{
return v1+v2;
}
};
clss MyPrint
{
public:
MyPrint()
{
this->count++; //特点2:函数对象可以拥有自己的状态
}
void operator()(string str)
{
cout << str << endl;
}
int count;
};
void test(MyPrint& mp , string str) //特点3:可以作为函数参数传递
{
mp(str);
}
int main()
{
MyAdd add;
cout << "add = " << add(10 , 30) << endl; //特点1:像普通函数一样调用
MyPrint print;
print("Hello C++"); //特点2:可以有自己的状态,比如获取自己被调用了几次
print("Hello C++");
print("Hello C++");
print("Hello C++");
cout << "print被调用的次数为:" << print.count << endl;
test(print , "Hello C++"); //特点3:函数对象作为参数进行传递
}谓词
-
返回bool类型的仿函数,就称为谓词
-
如果operator()接受一个参数,就是一元谓词
-
如果operator()接受两个参数,就是二元谓词
一元谓词
-
如果operator()接受一个参数,就是一元谓词
示例:
class GreatFive
{
public:
bool operator()(int val) // 返回值是bool类型的仿函数,并且只有一个参数,就称为一元谓词
{
return val > 5;
}
};
int main()
{
vector v;
for(int i=0;i<10;i++)
{
v,push_back(i);
}
//功能,找到容器中,元素大于5的元素
// GreatFive()是一元谓词,是一个匿名的函数对象,功能是说明要找到大于5的元素
vectot::iterator it = find_if( v.begin(), v.end().Greatfive() );
if( it == v.end() )
{
cout << "没找到" << endl;
}
else
{
cout << "找到了" << *it << endl;
}
return 0;
} 二元谓词
-
如果operator()接受两个参数,就是二元谓词
示例:
class MyCompare
{
public:
bool operator()(int val1,int val2) // 返回类型为bool类型,并且有两个参数,所以是二元谓词
{
return val1 > val2 ; // 功能是从大到小
}
};
int main()
{
vector v;
v.push_back(40);
v.push_back(30);
v.push_back(50);
v.push_back(20);
v.push_back(70);
v.push_back(10);
sort( v.begin() , v.end() ); // 默认是从小到大
//利用仿函数改变排序规则,从大到小
sort( v.begin() , v.end(), MyCompare() );
return 0;
} 内建函数对象
-
STL内建了一些已经封装好了的函数对象
-
这些对象是由仿函数所产生的,用法和一般对象一样
-
需要加入头文件#include
-
内建函数对象是已经写好的标准算法入口,愿意你就用,不愿意就自己写一个
分类:
-
算术仿函数
-
关系仿函数
-
逻辑仿函数
算术仿函数
作用:实现四则运算
函数原型:
-
template
T plus // 加法仿函数,二元运算 -
template
T minus //减法仿函数,二元运算 -
template
T multiplies //乘法仿函数,二元运算 -
template
T divides //除法仿函数,二元运算 -
template
T modulus //取模仿函数,二元运算 -
template
T negate //取反仿函数 ,一元运算
示例:
#include
int main()
{
negate n; //创建一个内建的取反对象
cout << n(57) << endl; //这就完成取反操作了
plus p; //创建一个内建的加法对象,这里只需要声明一个int的数据类型就好了,因为只有同一类型的才能算术运算
cout << p(10,20) << endl; //这样就完成加法操作了
system("pause");
return 0;
} 关系仿函数
作用:实现关系对比
函数原型:
-
template
bool equal_to // 等于 -
template
bool not_equal_to //不等于 -
template
bool greater //大于 -
template
bool greater_equal //大于等于 -
template
bool less //小于 -
template
bool less_equal //小于等于
示例:不用自己写的仿函数,用内建函数对象来改变排序规则
#include
#include
#include
class MyCompare
{
public:
bool operator()(int val1, int val2)
{
return val1 > val2;
}
};
int main()
{
vector v;
v.push_back(50);
v.push_back(30);
v.push_back(70);
v.push_back(40);
v.push_back(20);
v.push_back(10);
// sort(v.begin() , v.end(), MyCompare()); // 自己写的反函数开改变排序规则,实现大于等于的降序
sort(v.begin(), v.end(), greater()); // 用内建函数对象来改变排序规则,实现大于等于的降序
system("pause");
return 0;
} 逻辑仿函数
作用:实现逻辑运算
函数原型:
-
template
bool logical_and // 逻辑与 -
template
bool logical_or //逻辑或 -
template
bool logical_not //逻辑非
示例:用逻辑非操作将容器v1的元素取反并搬运到容器v2中
#include
#include
#include
int main()
{
vector v1;
v1.push_back(true);
v1.push_back(flase);
v1.push_back(true);
v1.push_back(flase);
vector v2;
v2.resize( v1.size() ); //重新指定容器v2的大小
//transform这是标准算法,用于搬运元素
//用逻辑非的规则将容器v1搬运到容器v2中
transform(v1.begin(), v1.end(), v2.begin(), logical_not());
system("pause");
return 0;
} 学习C++这一篇就够了(基础篇) https://mp.csdn.net/mp_blog/creation/editor/131559599
https://mp.csdn.net/mp_blog/creation/editor/131559599
学习C++这一篇就够了(进阶篇)https://mp.csdn.net/mp_blog/creation/editor/131565205
先更新到这儿吧,需要后面在补充。
希望以上内容可以帮助到大家。
祝各位生活愉快。