Flink-----任务调度slot和subtask配置
Flink 在进行 slot sharing 的时候,不会考虑当前 slot 的任务数、磁盘 IO 这些,而是会遵循“相同 task 的多个subtask 不能分配到同一个 slot 中”这样的一个规则。
举个例子:
如果作业中有 A, B 两个 vertex,并发为 2,那就有 A1, A2, B1, B2 这 4 个 subtask。
那么 A1 和 A2 不能放到一个 slot 中,B1 和 B2 不能够放到一个 slot 中。
所以,slot sharing 的结果只能是 (A1, B1), (A2, B2) 或 (A1, B2), (A2, B1) 这两种情况。
通常情况下,A 和 B 之间的负载可能存在较大差异,而 A1 和 A2、B1 和 B2 之间通常不会有太大差异。
因此,slot sharing 的规则使得每个 slot 中都分配了一个 A 和一个 B,各个 slot 之间的负载大体上是均衡的。
概述
为了实现并行执行,Flink应用会将算子划分为不同任务,然后将这些任务分配到集群中的不同进程上去执行。和很多其他分布式系统一样,Flink应用的性能很大程度上取决于任务的调度方式。任务被分配到的工作进程、任务间的共存情况以及工作进程中的任务数都会对应用的性能产生显著影响。本节中我们就讨论一下如何通过调整默认行为以及控制作业链与作业分配(处理槽共享组)来提高应用的性能。
其实这两个概念我们可以看作:资源共享链与资源共享组。当我们编写完一个Flink程序,从Client开始执行——>JobManager——>TaskManager——>Slot启动并执行Task的过程中,会对我们提交的执行计划进行优化,其中有两个比较重要的优化过程是:任务链与处理槽共享组,前者是对执行效率的优化,后者是对内存资源的优化。
作业链
一、执行过程

- Chain:Flink会尽可能地将多个operator链接(chain)在一起形成一个task pipline。每个task pipline在一个线程中执行
- 优点:它能减少线程之间的切换,减少消息的序列化/反序列化,减少数据在缓冲区的交换(即降低本地数据交换成本),减少了延迟的同时提高整体的吞吐量。
- 概述:在StreamGraph转换为JobGraph过程中,关键在于将多个 StreamNode 优化为一个 JobVertex,对应的 StreamEdge 则转化为 JobEdge,并且 JobVertex 和 JobEdge 之间通过 IntermediateDataSet (中间数据集)形成一个生产者和消费者的连接关系。每个JobVertex就是JobManger的一个任务调度单位(任务Task)。为了避免在这个过程中将关联性很强的几个StreamNode(算子)放到不同JobVertex(Task)中,从而导致因为Task执行产生的效率问题(数据交换(网络传输)、线程上下文切换),Flink会在StreamGraph转换为JobGraph过程中将可以优化的算子合并为一个算子链(也就是形成一个Task)。这样就可以把这条链上的算子放到一个线程中去执行,这样就提高了任务执行效率。
可见,StreamGraph转换为JobGraph过程中,实际上是逐条审查每一个StreamEdge和该SteamEdge两头连接的两个StreamNode的特性,来决定该StreamEdge两头的StreamNode是不是可以合并在一起形成算子链。这个判断过程flink给出了明确的规则,我们看一下StreamingJobGraphGenerator中的isChainable()方法:

该方法返回true时两个端点才可以合并到一起,根据源码我们可以得出形成作业链的规则如下:
- 上下游的并行度一致(槽一致)
- 该节点必须要有上游节点跟下游节点;
- 下游StreamNode的输入StreamEdge只能有一个)
- 上下游节点都在同一个 slot group 中(下面会解释 slot group)
- 下游节点的 chain 策略为 ALWAYS(可以与上下游链接,map、flatmap、filter等默认是ALWAYS)
- 上游节点的 chain 策略为 ALWAYS 或 HEAD(只能与下游链接,不能与上游链接,Source默认是HEAD)
- 上下游算子之间没有数据shuffle (数据分区方式是 forward)
- 用户没有禁用 chain
二、开启/禁用全局作业链
用户能够通过禁用全局作业链的操作来关闭整个Flink的作业链,但是这个操作会影响到这个作业的执行情况,除非我们非常清楚作业的执行过程,否则不建议这么做:StreamExecutionEnvironment.disableOperatorChaining()。全局作业链关闭之后,如果想创建对应Operator的作业链,可以使用startNewChain()方法:someStream.filter(...).map(...).startNewChain().map(...)。注意该方法只对当前操作符及之后的操作符有效,所以上述代码只对两个map进行链条绑定。
三、禁用局部作业链
如果我们只想对某个算子执行禁用作业链,只需调用disableChaining()方法:someSteam.map().disableChaining().filter(),该方法只会禁用当前算子的链条(上述代码中就是map),对其他算子操作不产生影响。
处理槽共享组(出于某中目的将多个Task放到同一个slot中执行)
一、Task Slot
TaskManager 是一个 JVM 进程,并会以独立的线程来执行一个task。为了控制一个 TaskManager 能接受多少个 task,Flink 提出了 Task Slot 的概念,通过 Task Slot 来定义Flink 中的计算资源。solt 对TaskManager内存进行平均分配,每个solt内存都相同,加起来和等于TaskManager可用内存,但是仅仅对内存做了隔离,并没有对cpu进行隔离。将资源 slot 化意味着来自不同job的task不会为了内存而竞争,而是每个task都拥有一定数量的内存储备。
通过调整 task slot 的数量,用户可以定义task之间是如何相互隔离的。每个 TaskManager 有一个slot,也就意味着每个task运行在独立的 JVM 中。每个 TaskManager 有多个slot的话,也就是说多个task运行在同一个JVM中。而在同一个JVM进程中的task,可以共享TCP连接(基于多路复用)和心跳消息,可以减少数据的网络传输。也能共享一些数据结构,一定程度上减少了每个task的消耗。
二、共享槽
问题:
- 一个TaskManager中至少有一个插槽slot,每个插槽均分内存并且之间是内存隔离的,但是共享CPU。算子根据计算复杂度可以分为资源密集型与非资源密集型算子(可以认为有的算子计算时内存需求大,有些算子内存需求小)。现在有这么个情况:某个Job下的Tasks中既有资源密集型Task(A),又有非资源密集型Task(B),他们被分到不同的slot上,这就会产生问题:
- 有的slot内存使用率大,有的slot内存使用率小,这样就很不公平,一个槽资源没有得到充分的利用;
- 对于槽资源有限的情况,任务并行度也不高。
解决方案

默认情况下,Flink 允许subtasks共享slot,条件是它们都来自同一个Job的不同task的subtask。结果可能一个slot持有该job的整个pipeline。允许槽共享,会有以下两个方面的好处:
- 对于slot有限的场景,我们可以增大每个task的并行度。比如如果不设置SlotSharingGroup,默认所有task在同一个共享组(可以共享所有slot),那么Flink集群需要的任务槽与作业中使用的最高并行度正好相同。但是如上图所示,如果我们强制指定了map的slot共享组为test,那么map和map下游的组为test,map的上游source的共享组为默认的default,此时default组中最大并行度为10,test组中最大并行度为20,那么需要的Slot=10+20=30;
- 能更好的利用资源:如果没有slot共享,那些资源需求不大的map/source/flatmap子任务将和资源需求更大的window/sink占用相同的资源,槽资源没有充分利用(内存没有充分利用)。
具体共享机制实现
Flink决定哪些任务需要共享slot 以及哪些任务必须放入特定slot。虽然task共享Slot提升资源利用率,但是如果一个Slot中容纳过多task反而会造成资源低下(比如极端情况下所有task都分布在一个Slot内)。所以在Flink中task需要按照一定规则共享Slot ,主要通过SlotSharingGroup和CoLocationGroup定义:
- CoLocationGroup:强制将subTasksk放到同一个slot中,是一种硬约束:
- 保证把JobVertices的第n个运行实例和其他相同组内的JobVertices第n个实例运作在相同的slot中(所有的并行度相同的subTasks运行在同一个slot );
- 主要用于迭代流(训练机器学习模型) ,用来保证迭代头与迭代尾的第i个subtask能被调度到同一个TaskManager上。
SlotSharingGroup: 它是Flink中用来实现slot共享的类,尽可能的允许不同的JobVertices部署在相同的Slot中,但这是一种宽约束,只是尽量做到不能完全保证。
- 算子的默认group为default,所有任务可以共享同一个slot;
- 要想确定一个未做SlotSharingGroup设置的算子的group是什么,可以根据上游算子的 group 和自身是否设置 group共同确定(也就是说如果下游算子没有设置分组,它继承上游算子的分组);
- 为了防止不合理的共享,用户可以通过提供的API强制指定operator的共享组。因为不合理的共享槽资源(比如默认情况下所有任务共享所有的slot)会导致每个槽中运行的线程述增多,增加了机器负载。所以适当设置可以减少每个slot运行的线程数,从而整体上减少机器的负载。比如: someStream.filter(...).slotSharingGroup("group1")就强制指定了filter的slot共享组为group1。
三、Slot共享以及task的调度过程
- Flink在调度任务分配Slot的时候遵循两个重要原则:
- 同一个Job中的同一分组中的不同Task可以共享同一个Slot;
- Flink是按照拓扑顺序依次从Source调度到sink。
- 假设有两个TM:TM1、TM2,每个TM有3个Slot:S1,S2,S3。假设source/map的并行度为2,keyBy/window/sink的并行度为4,那么调度的顺序依次为source/map[1] ->source/map[2] ->keyBy/window/sink[1]->keyBy/window/sink[2]->keyBy/window/sink[3]->keyBy/window/sink[4]。那么Flink调度任务时(使用默认共享分组):
- 首先调度子任务source/map[1]到TM1.S1;
- 然后调度子任务source/map[2] ,根据Flink的调度原则:source/map[1] 和source/map[2] 属于同一个Task下的两个SubTask,所以他们不能放到同一个Slot中,所以source/map[2]被调度到TM1.S2;
- 然后调度keyBy/window/sink,keyBy/window/sink的子任务会被依次调度到TM1.S1、TM1.S2、TM2.S1、TM2.S2 (因为亲和性调度)。但是如果source/map与keyBy/window/sink属于不同分组,那么keyBy/window/sink会被调度到TM1.S3、TM2.S1、TM2.S2、TM2.S3(因为slotGroup不同)。
四、亲和性具体处理过程
主要做了两件事情:
- 在calculatePreferredLocations中确定从该subTask对应ExecutionJobVertex的所有上游中找到最合适的上游”偏向位置集合”。
- 通过SlotPool$ProviderAndOwner.allocateSlot继续确定从”偏向位置集合”找到一个共享slot。
我们知道, 多个subTask允许共享slot, 细节后面会详细描述。 那么当前subTask与哪些已经分配的subTask共享slot呢? 下游subTask与哪个上游subTask共享slot呢?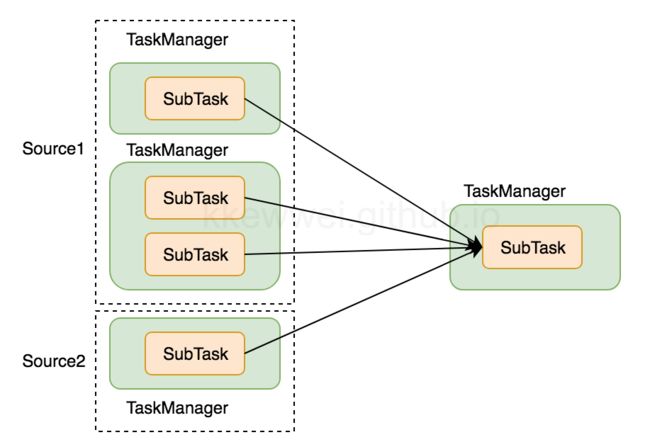
flink会根据subTask上游slot的分配来确定当前slot的分配:
- 若该ExecutionVertex没有上游(例如source), 那么返回为空, 没有”偏好位置集合”, 之后将申请新的slot。
- 若当前ExecutionVertex有属于不同JobVertex多个ExecutionJobVertex的上游, 那么当前sub分配到哪些共享slot的可选路径只能是: 属于同一个JobVertex的上游节点个数最少。上图的话, 就会选择source2的所有subTask作为”偏好位置集合”。我们接下来看第二步, 最终会进入到allocateSharedSlot决定subTask分配到哪些”偏好位置集合”里slot上。
总结
- 一个Task的子任务SubTask个数称为它的并行度;
- 一个Task的并行度等于分配给它的Slot个数(前提槽资源充足);
- 同一个Job下的不同Task可一个放到同一个Slot中——处理槽共享分组;
参考
Apache Flink 中文用户邮件列表 - flink对task分配slot问题
Flink原理-JobManager端的SubTask申请slot及部署 | Hexo
Flink 任务到底需要多少个 Slot
Flink原理-TaskManager处理SubTask | Hexo
Apache Flink 1.8 Documentation: Distributed Runtime Environment