Hadoop集群配置及运行
本文章基于尚硅谷Hadoop 3.x视频进行总结,仅作为学习交流使用 视频链接如下:30_尚硅谷_Hadoop_入门_集群配置_哔哩哔哩_bilibili
集群配置整体思路
1.切换到/opt/module/hadoop-3.3.4/etc/hadoop,配置core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml,分发hadoop文件夹
集群启动整体思路
1.第一次启动时需要配置workers配置文件,以及进行hdfs的初始化( hdfs namenode -format )
2.启动集群,需要分别在hadoop102上启动hdfs,以及在hadoop103上启动yarn。
第一部分.集群配置
1.切换到配置文件目录
[atguigu@hadoop102 hadoop]$ pwd
/opt/module/hadoop-3.3.4/etc/hadoop
2.配置核心配置文件
配置core-site.xml
[atguigu@hadoop102 hadoop]$ vim core-site.xml
fs.defaultFS
hdfs://hadoop102:8020
hadoop.tmp.dir
/opt/module/hadoop-3.3.4/data
配置hdfs-site.xml
[atguigu@hadoop102 hadoop]$ vim hdfs-site.xml
dfs.namenode.http-address
hadoop102:9870
dfs.namenode.secondary.http-address
hadoop104:9868
配置yarn-site.xml
[atguigu@hadoop102 hadoop]$ vim yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
hadoop103
yarn.nodemanager.env-whitelist JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
配置mapred-site.xml
[atguigu@hadoop102 hadoop]$ vim mapred-site.xml
mapreduce.framework.name
yarn
3.分发配置文件
[atguigu@hadoop102 hadoop]$ cd ..
[atguigu@hadoop102 etc]$ xsync hadoop/
第二部分.群起集群并测试
1.配置workers
切换到配置文件目录
[atguigu@hadoop102 hadoop]$ pwd
/opt/module/hadoop-3.3.4/etc/hadoop
配置 workers
[atguigu@hadoop102 hadoop]$ vim workers
hadoop102
hadoop103
hadoop104
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
分发workers文件
[atguigu@hadoop102 hadoop]$ xsync workers
2.启动集群
返回hadoop根目录
[atguigu@hadoop102 hadoop-3.3.4]$ pwd
/opt/module/hadoop-3.3.4
格式化NameNode
[atguigu@hadoop102 hadoop-3.3.4]$ hdfs namenode -format
启动HDFS
[atguigu@hadoop102 hadoop-3.3.4]$ sbin/start-dfs.sh
Starting namenodes on [hadoop102]
Starting datanodes
hadoop104: WARNING: /opt/module/hadoop-3.3.4/logs does not exist. Creating.
hadoop103: WARNING: /opt/module/hadoop-3.3.4/logs does not exist. Creating.
Starting secondary namenodes [hadoop104]
#查看已经开启的服务
[atguigu@hadoop102 hadoop-3.3.4]$ jps
3990 DataNode
3832 NameNode
4219 Jps
#Web端查看HDFS的NameNode
(a)浏览器中输入:http://hadoop102:9870
(b)查看HDFS上存储的数据信息
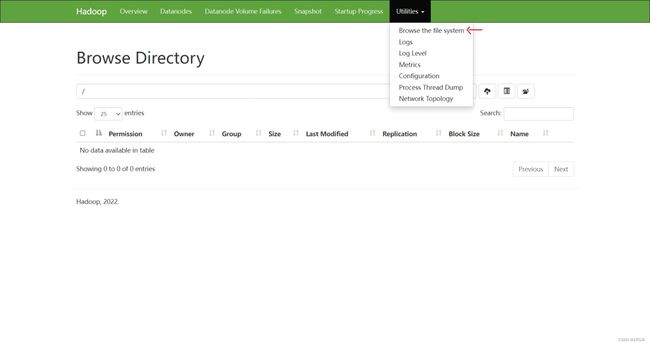
在配置了ResourceManager的节点(hadoop103)启动YARN
[atguigu@hadoop103 hadoop-3.3.4]$ sbin/start-yarn.sh
#Web端查看YARN的ResourceManager
(a)浏览器中输入:http://hadoop103:8088
(b)查看YARN上运行的Job信息

3. 集群基本测试
在集群上创建文件夹
[atguigu@hadoop102 hadoop-3.3.4]$ hadoop fs -mkdir /wcinput
上传小文件
[atguigu@hadoop102 hadoop-3.3.4]$ hadoop fs -put wcinput/word.txt /wcinput
上传大文件
[atguigu@hadoop102 hadoop-3.3.4]$ hadoop fs -put /opt/software/jdk-8u341-linux-x64.tar.gz /
执行wordcount程序
[atguigu@hadoop102 hadoop-3.3.4]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar wordcount /wcinput /wcoutput
4.集群崩溃处理办法
停掉已经开启的服务
[atguigu@hadoop102 hadoop-3.3.4]$ sbin/stop-dfs.sh
[atguigu@hadoop103 hadoop-3.3.4]$ sbin/stop-yarn.sh
删除每个虚拟机 hadoop-3.3.4文件夹下的data目录和logs目录
5.配置历史服务器
配置mapred-site.xml
[atguigu@hadoop102 hadoop]$ vim mapred-site.xml
mapreduce.jobhistory.address
hadoop102:10020
mapreduce.jobhistory.webapp.address
hadoop102:19888
分发 mapred-site.xml
[atguigu@hadoop102 hadoop]$ xsync mapred-site.xml
启动历史服务器
[atguigu@hadoop102 hadoop-3.3.4]$ bin/mapred --daemon start historyserver
6.配置日志的聚集
配置yarn-site.xml
[atguigu@hadoop102 hadoop]$ vim yarn-site.xml
yarn.log-aggregation-enable
true
yarn.log.server.url
http://hadoop102:19888/jobhistory/logs
yarn.log-aggregation.retain-seconds
604800
分发配置文件
[atguigu@hadoop102 hadoop]$ xsync yarn-site.xml
启动日志聚集
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryServer。
关闭历史服务器
[atguigu@hadoop102 hadoop]$ mapred --daemon stop historyserver
关闭单个服务
关闭yarn服务
[atguigu@hadoop103 hadoop-3.3.4]$ sbin/stop-yarn.sh
重新开启yarn和历史服务器
删除HDFS上已经存在的输出文件
[atguigu@hadoop102 hadoop-3.3.4]$ hadoop fs -rm -r /ss
执行WordCount程序
[atguigu@hadoop102 hadoop-3.3.4]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar wordcount /wcinput /output2
#7.集群启动/停止方式总结
各个模块分开启动/停止(配置ssh是前提)常用
(1)整体启动/停止HDFS
start-dfs.sh/stop-dfs.sh
(2)整体启动/停止YARN
start-yarn.sh/stop-yarn.sh
2)各个服务组件逐一启动/停止
(1)分别启动/停止HDFS组件
hdfs --daemon start/stop namenode/datanode/secondarynamenode
(2)启动/停止YARN
yarn --daemon start/stop resourcemanager/nodemanager
8. Hadoop集群启停脚本(包含HDFS,Yarn,Historyserver):myhadoop.sh
切换到家目录下的bin目录,并创建myhadoop.sh文件
[atguigu@hadoop102 bin]$ pwd
/home/atguigu/bin
[atguigu@hadoop102 bin]$ vim myhadoop.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
ficase $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="echo " --------------- 启动 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.3.4/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.3.4/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.3.4/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="echo " --------------- 关闭 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.3.4/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.3.4/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.3.4/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
赋予脚本执行权限
[atguigu@hadoop102 bin]$ chmod 777 myhadoop.sh
测试结果
[atguigu@hadoop102 hadoop-3.3.4]$ myhadoop.sh start
=================== 启动 hadoop集群 ===================
--------------- 启动 hdfs ---------------
Starting namenodes on [hadoop102]
Starting datanodes
Starting secondary namenodes [hadoop104]
--------------- 启动 yarn ---------------
Starting resourcemanager
Starting nodemanagers
--------------- 启动 historyserver ---------------
[atguigu@hadoop102 hadoop-3.3.4]$ jps
2465 DataNode
2970 JobHistoryServer
2796 NodeManager
2333 NameNode
3071 Jps
9.查看三台服务器Java进程脚本:jpsall
切换到家目录下的bin目录,并创建jpsall文件
[atguigu@hadoop102 bin]$ pwd
/home/atguigu/bin
[atguigu@hadoop102 bin]$ vim jpsall
#!/bin/bash
for host in hadoop102 hadoop103 hadoop104
do
echo =============== $host ===============
ssh $host jps
done
赋予脚本执行文件
[atguigu@hadoop102 bin]$ chmod 777 jpsall
分发脚本
[atguigu@hadoop102 ~]$ xsync bin/
*面试题 10. 常用端口号

11.配置时间服务器
切换到root用户
[atguigu@hadoop102 ~]$ su root
密码:
查看ntp服务是否开启与自启动
[root@hadoop102 atguigu]# systemctl status ntpd
[root@hadoop102 atguigu]# systemctl is-enabled ntpd
配置hadoop102的ntp.conf配置文件
[root@hadoop102 atguigu]# vim /etc/ntp.conf
(a)修改1(授权192.168.10.0-192.168.10.255网段上的所有机器可以从这台机器上查询和同步时间)
#restrict 192.168.10.0 mask 255.255.255.0 nomodify notrap
为restrict 192.168.10.0 mask 255.255.255.0 nomodify notrap
(b)修改2(集群在局域网中,不使用其他互联网上的时间)
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst
为
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
(c)添加3(当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步)
server 127.127.1.0
fudge 127.127.1.0 stratum 10
修改hadoop102的/etc/sysconfig/ntpd 文件
[root@hadoop102 atguigu]# vim /etc/sysconfig/ntpd
添加:
SYNC_HWCLOCK=yes
开启/关闭ntp服务,开启/关闭自启
[root@hadoop102 atguigu]# systemctl start ntpd
[root@hadoop102 atguigu]# systemctl stop ntpd
[root@hadoop102 atguigu]# systemctl enable ntpd
[root@hadoop102 atguigu]# systemctl disable ntpd
关闭hadoop103和hadoop104上的ntp服务和自启动
[atguigu@hadoop103 ~]$ sudo systemctl stop ntpd
[atguigu@hadoop103 ~]$ sudo systemctl disable ntpd
在其他机器配置1分钟与时间服务器同步一次
[atguigu@hadoop103 ~]$ sudo crontab -e
编写定时任务如下:
*/1 * * * * /usr/sbin/ntpdate hadoop102