mybatis
1.前言
1.1.总体技术体系
1.1.1.单一架构
一个项目,一个工程,导出为一个war包,在一个Tomcat上运行。也叫all in one。

1.1.2.分布式架构
一个项目,拆分成很多个模块,每个模块是一个工程。每一个工程都是运行在自己的Tomcat上。模块之间可以互相调用。每一个模块内部可以看成是一个单一架构的应用。

1.2.框架的概念
框架=jar包+配置文件

1.3.Mybatis历史

MyBatis最初是Apache的一个开源项目iBatis, 2010年6月这个项目由Apache Software Foundation迁移到了Google Code。随着开发团队转投Google Code旗下, iBatis3.x正式更名为MyBatis。代码于2013年11月迁移到Github。
iBatis一词来源于“internet”和“abatis”的组合,是一个基于Java的持久层框架。 iBatis提供的持久层框架包括SQL Maps和Data Access Objects(DAO)。
1.4.Mybatis下载地址
https://github.com/mybatis/mybatis-3


1.5.Mybatis特性
MyBatis支持定制化SQL、存储过程以及高级映射
MyBatis避免了几乎所有的JDBC代码和手动设置参数以及结果集解析操作
MyBatis可以使用简单的XML或注解实现配置和原始映射;将接口和Java的POJO(Plain Ordinary Java Object,普通的Java对象)映射成数据库中的记录
Mybatis是一个半自动的ORM(Object Relation Mapping)框架
1.6.与其它持久化层技术对比
-
JDBC
-
SQL 夹杂在Java代码中耦合度高,导致硬编码内伤
-
维护不易且实际开发需求中 SQL 有变化,频繁修改的情况多见
-
代码冗长,开发效率低
-
-
Hibernate 和 JPA
-
操作简便,开发效率高
-
程序中的长难复杂 SQL 需要绕过框架
-
内部自动生产的 SQL,不容易做特殊优化
-
基于全映射的全自动框架,大量字段的 POJO 进行部分映射时比较困难。
-
反射操作太多,导致数据库性能下降
-
-
MyBatis
-
轻量级,性能出色
-
SQL 和 Java 编码分开,功能边界清晰。Java代码专注业务、SQL语句专注数据
-
开发效率稍逊于HIbernate,但是完全能够接收
-
2.Mybatis基本用法
2.1.HelloWorld
2.1.1.物理建模
CREATE DATABASE `mybatis-example`;
USE `mybatis-example`;
CREATE TABLE `t_emp`(
emp_id INT AUTO_INCREMENT,
emp_name CHAR(100),
emp_salary DOUBLE(10,5),
PRIMARY KEY(emp_id)
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `t_emp`(emp_name,emp_salary) VALUES("tom",200.33);
2.1.2.逻辑建模
2.1.2.1.创建Maven module

2.1.2.2.引入MyBatis及其他相关依赖
<dependencies>
<dependency>
<groupId>org.mybatisgroupId>
<artifactId>mybatisartifactId>
<version>3.5.7version>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.12version>
<scope>testscope>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.3version>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<version>1.18.6version>
dependency>
dependencies>
2.1.2.3.创建Java实体类
实体类是和现实世界中某一个具体或抽象的概念对应,是软件开发过程中,为了管理现实世界中的数据而设计的模型。
实体类的多个不同的叫法:
domain:领域模型
entity:实体
POJO:Plain Old Java Object
Java bean:一个Java类
/**
* 和数据库表t_emp对应的实体类
* emp_id INT AUTO_INCREMENT
* emp_name CHAR(100)
* emp_salary DOUBLE(10,5)
*
* Java的实体类中,属性的类型不要使用基本数据类型,要使用包装类型。因为包装类型可以赋值为null,表示空,而基本数据类型不可以。
*/
@NoArgsConstructor
@AllArgsConstructor
@Data
@ToString
public class Emp {
private Long empId;
private String empName;
private Double empSalary;
}
2.1.3.搭建框架开发环境
主要操作就是创建全局配置文件和Mybatis映射文件
2.1.3.1.Mybatis全局配置文件
习惯上命名为mybatis-config.xml,这个文件名仅仅只是建议,并非强制要求。将来整合Spring之后,这个配置文件可以省略,所以大家操作时可以直接复制、粘贴。
mybatis-config.xml
DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/mybatis-example?useUnicode=true&characterEncoding=utf-8"/>
<property name="username" value="root"/>
<property name="password" value="123456"/>
dataSource>
environment>
environments>
<mappers>
<mapper resource="mappers/EmployeeMapper.xml"/>
mappers>
configuration>
-
environments表示配置Mybatis的开发环境,可以配置多个环境,在众多具体环境中,使用default属性指定实际运行时使用的环境。default属性的取值是environment标签的id属性的值。environment表示配置Mybatis的一个具体的环境。
配置Mybatis的内置的事务管理器。dataSource数据源类型,在里面设置具体的数据库连接的具体信息 -
在mappers标签中进行Mapper注册:指定Mybatis映射文件的具体位置,在mapper文件写sql语句。
- mapper标签:配置一个具体的Mapper映射文件
- resource属性:指定Mapper映射文件的实际存储位置,这里需要使用一个以类路径根目录为基准的相对路径
对Maven工程的目录结构来说,resources目录下的内容会直接放入类路径,所以这里我们可以以resources目录为基准
-
配置url时在xml配置文件中,需要将’&‘符号转义,所以这里要写成’&’。如果关联外部配置文件jdbc.proerties中在properties类型问可以写&。
注意:配置文件存放的位置是src/main/resources目录下。

2.1.3.2.Mybatis映射文件
相关概念:ORM(Object Relationship Mapping)对象关系映射。
- 对象:Java的实体类对象
- 关系:关系型数据库
- 映射:二者之间的对应关系
| Java概念 | 数据库概念 |
|---|---|
| 类 | 表 |
| 属性 | 字段/列 |
| 对象 | 记录/行 |

DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.stonebridge.myBatis.dao.EmployeeMapper">
<select id="selectEmpById" resultType="com.stonebridge.myBatis.domain.Emp">
select emp_id empId,emp_name empName,emp_salary empSalary from t_emp where emp_id=#{empId}
select>
mapper>
-
namespace
在Java程序中,必须找到当前的Mapper配置文件,才能进一步找到这里配置的SQL语句。Java程序就是通过mapper标签的namespace属性找到当前Mapper配置文件。将来为了让一个Java接口,直接对应这个Mapper配置文件,通常使用Java接口的全类名作为这个namespace属性的值。以前我们叫dao,现在叫mapper,本质上都是持久化层的类型,只是命名习惯的区别。
-
sql类型的定义
- select语句使用select标签
- insert语句使用insert标签
- update语句使用update标签
- delete语句使用delect标签
-
在select标签中编写一条select语句实现查询效果
id属性:这条SQL语句的唯一标识
resultType属性:Mybatis负责解析结果集,将解析得到的数据封装到Java类型中。resultType属性就是指定这个Java类型
如果查出表的字段和Java类型的字段不一致,例如数据库字段含有下划线,大小写和java不一致。可以通过取别名的方式实现
注意:EmployeeMapper.xml所在的目录要和mybatis-config.xml中使用mapper标签配置的一致。
2.1.4.junit测试代码
public class Mybatis {
@Test
public void TestSelect() throws IOException {
// 1.使用Mybatis的Resources类读取Mybatis全局配置文件
InputStream inputStream = Resources.getResourceAsStream("mybatis-config.xml");
// 2.创建SqlSessionFactoryBuilder对象。主要用于创建SqlSessionFactory
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
// 3.调用builder对象的build方法创建SqlSessionFactory对象
SqlSessionFactory sessionFactory = builder.build(inputStream);
// 4.通过SqlSessionFactory对象开启一个从Java程序到数据库的会话
SqlSession session = sessionFactory.openSession();
// 5.通过SqlSession对象找到Mapper配置文件中可以执行的SQL语句
// statement参数的格式:Mapper配置文件的namespace属性.SQL标签的id属性
// parameter参数:给SQL语句传入的参数
Object object = session.selectOne("com.stonebridge.myBatis.dao.EmployeeMapper.selectEmpById", "1");
// 6.直接打印查询结果
System.out.println("object = " + object);
// 7.提交事务
session.commit();
// 8.关闭SqlSession
session.close();
}
}
执行测试代码:

2.1.5.Mybatis执行流程说明
2.1.5.1.执行回顾
@Test
public void testHelloWorldReview() throws IOException {
//1.借助Mybatis的Resource类将Mybatis全局配置文件读取到内存中
//这里使用的路径仍然是一个以类路径目录为基准的相对路径
InputStream inputStream = Resources.getResourceAsStream("mybatis-config.xml");
//2.创建SqlSessionFactoryBuilder对象。SqlSessionFactoryBuilder对象主要用于创建SqlSessionFactory,SqlSessionFactory又是生产SqlSession的
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
//3.调用builder对象的build()方法读取《全局配置文件的输入流》来创建SqlSessionFactory
SqlSessionFactory factory = builder.build(inputStream);
//4.调用工厂对象的方法开启一个会话,从java程序的持久层到数据库的会话
SqlSession session = factory.openSession();
//5.执行Mapper配置文件中准备好sql语句。找到sql语句的过程:通过namespace找到mapper映射文件的sql语句标签
//备注:此时执行的查找操作的sql已经不是到xml配置文件中找了,因为xml配置文件中的信息已经读取到内存中封装成了对象,
//所以此时其实是到已经封装的对象中查找,查找的依据是:mapper配置文件namespace值,sql语句标签的id
String statement = "com.stonebridge.myBatis.dao.EmployeeMapper.selectEmpById";
Long empId = 1L;
Object object = session.selectOne(statement, empId);
// 6.直接打印查询结果
System.out.println("object = " + object);
// 7.提交事务
session.commit();
// 8.关闭SqlSession
session.close();
}
流程说明:
- 借助Mybatis的Resource类将Mybatis全局配置文件读取到内存中
- 创建SqlSessionFactoryBuilder对象。
- SqlSessionFactoryBuilder对象使用build()方法读取<全局配置文件的输入流>来创建SqlSessionFactory对象。
- SqlSessionFactory对象调用工厂对象的方法开启一个会话SqlSession,代表java程序的持久层和数据库之间的会话。(HttpSession是Java程序和浏览器之间的会话)
如果创建某一个对象,使用的过程基本固定,那么我们就可以把创建这个对象的相关代码封装到一个“工厂类”中,以后都使用这个工厂类来“生产”我们需要的对象。
刚开始接触框架,我们会认为Java程序会转入XML配置文件中执行,但其实框架会在初始化时将XML文件读取进来,封装到对象中,再然后就都是Java代码的执行了,XML中的配置是没法执行的。
2.1.5.2.图解

2.1.5.3.源码
-
封装Configuration对象

-
准备去获取已映射的指令

-
正式获取已映射的指令

-
mappedStatements对象结构
mappedStatements对象的类型:Configuration类中的一个静态内部类:StrictMap

2.2.HelloWorld强化
2.2.1.加入日志
2.2.1.1.目的
在Mybatis工作过程中,通过打印日志的方式,将要执行的SQL语句打印出来。
2.2.1.2.操作
-
加入依赖
<dependency> <groupId>log4jgroupId> <artifactId>log4jartifactId> <version>1.2.17version> dependency> -
加入log4j的配置文件

支持XML和properties属性文件两种形式。无论使用哪种形式,文件名是固定的:
- log4j.xml
- log4j.properties
DOCTYPE log4j:configuration SYSTEM "log4j.dtd"> <log4j:configuration xmlns:log4j="http://jakarta.apache.org/log4j/"> <appender name="STDOUT" class="org.apache.log4j.ConsoleAppender"> <param name="Encoding" value="UTF-8"/> <layout class="org.apache.log4j.PatternLayout"> <param name="ConversionPattern" value="%-5p %d{MM-dd HH:mm:ss,SSS} %m (%F:%L) \n"/> layout> appender> <logger name="java.sql"> <level value="debug"/> logger> <logger name="org.apache.ibatis"> <level value="info"/> logger> <root> <level value="debug"/> <appender-ref ref="STDOUT"/> root> log4j:configuration> -
日志的级别
FATAL(致命)>ERROR(错误)>WARN(警告)>INFO(信息)>DEBUG(调试)
从左到右打印的内容越来越详细
-
STDOUT
是standard output的缩写,意思是标准输出。对于Java程序来说,打印到标准输出就是打印到控制台。
-
打印效果
DEBUG 10-26 22:02:51,877 ==> Preparing: select emp_id empId,emp_name empName,emp_salary empSalary from t_emp where emp_id=? (BaseJdbcLogger.java:137) DEBUG 10-26 22:02:51,910 ==> Parameters: 1(String) (BaseJdbcLogger.java:137) DEBUG 10-26 22:02:51,936 <== Total: 1 (BaseJdbcLogger.java:137) object = Emp(empId=1, empName=tom, empSalary=200.33)
2.2.2.关联外部配置文件
2.2.2.1.需求
在实际开发时,同一套代码往往会对应多个不同的具体服务器环境。使用的数据库连接参数也不同。为了更好的维护这些信息,我们建议把数据库连接信息提取到Mybatis全局配置文件外边。
2.2.2.2.操作
创建jdbc.properties配置文件

wechat.dev.driver=com.mysql.jdbc.Driver
wechat.dev.url=jdbc:mysql://localhost:3306/mybatis-example?useUnicode=true&characterEncoding=UTF-8
wechat.dev.username=root
wechat.dev.password=123456
wechat.test.driver=com.mysql.jdbc.Driver
wechat.test.url=jdbc:mysql://192.168.198.150:3306/mybatis-example?useUnicode=true&characterEncoding=UTF-8
wechat.test.username=root
wechat.test.password=123456
wechat.product.driver=com.mysql.jdbc.Driver
wechat.product.url=jdbc:mysql://192.168.198.200:3306/mybatis-example?useUnicode=true&characterEncoding=UTF-8
wechat.product.username=root
wechat.product.password=123456
配置url时在xml配置文件中,需要将’&‘符号转义,所以这里要写成’&’。如果关联外部配置文件jdbc.proerties中在properties类型问可以写&。
在Mybatis全局配置文件中指定外部jdbc.properties文件的位置
<properties resource="jdbc.properties"/>
在需要具体属性值的时候使用${key}格式引用属性文件中的键
<dataSource type="POOLED">
<property name="driver" value="${wechat.dev.driver}"/>
<property name="url" value="${wechat.dev.url}"/>
<property name="username" value="${wechat.dev.username}"/>
<property name="password" value="${wechat.dev.password}"/>
dataSource>
2.2.3.使用Mapper接口
Mybatis中的Mapper接口相当于以前的Dao。但是区别在于,Mapper仅仅是接口,我们不需要提供实现类。
2.2.3.1.实现流程

2.2.3.2.项目结构

2.2.3.3.Mapper接口
声明这个接口是为了上层代码调用Mybatis的具体功能。就整个接口及其中的方法而言
-
接口的全类名要和Mapper配置文件的namespace一致,这样才能通过接口找到Mapper配置信息。
-
接口中的方法名要和mapper配置中sql语句所在标签的id一致,这样才能通过方法名找到具体的sql语句。
-
mapper配置文件的id属性值是唯一,所以对应mapper接口中的方法名也是唯一,当前接口的方法不允许重载。
方法对应Mapper配置文件配置的标签,就方法而言。
- 方法的参数对应sql中#{XXXX}声明的参数
- 方法的返回值类型和resultType属性指定的类型一致
public interface EmployeeMapper {
/**
* 通过这个方法对应Mapper配置文件的sql语句
*
* @param empId 当前方法的参数对应sql中#{empId}声明的参数
* @return 当前方法的返回值类型和resultType属性指定的类型一致
*/
Emp selectEmpById(Long empId);
Integer insertEmp(Emp emp);
Integer deleteEmp(Long empId);
Integer updateEmp(Emp emp);
}
2.2.3.4.在mapper.xml中的标签写sql语句
在select标签中编写一条select语句实现查询效果。
- id属性:这条SQL语句的唯一标识
- resultType属性:Mybatis负责解析结果集,将解析得到的数据封装到Java类型中。resultType属性就是指定这个Java类型。如果查出表的字段和Java类型的字段不一致,可以通过取别名的方式实现。
SQL语句参数接收
-
#{empId}这里是为了方便接收Java程序传过来的参数数据
-
如果参数是基本类型,Mybatis负责将#{empId}部分转换为"?"占位符。用empId去填充占位符。
-
如果参数类型需要从Bean中解析
以insertEmp(Emp emp);为例
现在在这条SQL语句中,#{}中的表达式需要被用来从Emp emp实体类中获取emp_name的值、emp_salary的值。
而我们从实体类中获取值通常都是调用getter()方法。而getter()方法、setter()方法定义了实体类的属性。
定义属性的规则是:把get、set去掉,剩下部分首字母小写。
所以我们在#{}中使用getXxx()方法、setXxx()方法定义的属性名即可。
DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.stonebridge.myBatis.dao.EmployeeMapper">
<select id="selectEmpById" resultType="com.stonebridge.myBatis.domain.Emp">
select emp_id empId,emp_name empName,emp_salary empSalary from t_emp where emp_id=#{empId}
select>
<insert id="insertEmp">
INSERT INTO t_emp(emp_name,emp_salary) VALUES (#{empName},#{empSalary})
insert>
<delete id="deleteEmp">
DELETE
FROM t_emp
WHERE emp_id = #{empId}
delete>
<update id="updateEmp">
UPDATE t_emp
SET emp_name=#{empName},
emp_salary=#{empSalary}
where emp_id = #{empId}
update>
mapper>
2.2.3.5.Junit测试环境准备环境
@Before标注的方法会在会在每个@Test方法执行前执行。init()方法读取配置文件,准备环境。
@After标注的方法会在会在每个@Test方法执行前执行。clear()方法关闭资源。
public class MyBastisTestImprove {
private SqlSession session;
//junit会在每个@Test方法执行前执行
@Before
public void init() throws IOException {
session = new SqlSessionFactoryBuilder().build(Resources.getResourceAsStream("mybatis-config.xml")).openSession();
}
@Test
public void testUserMapperInterface() {
//TODD
}
@After
public void clear() {
session.commit();
session.close();
}
}
2.2.3.6.调用Mapper接口实现增删改查
public class MyBastisTestImprove {
private SqlSession session;
//junit会在每个@Test方法执行前执行
@Before
public void init() throws IOException {
session = new SqlSessionFactoryBuilder().build(Resources.getResourceAsStream("mybatis-config.xml")).openSession();
}
//执行查询
@Test
public void testUserMapperInterface() {
EmployeeMapper employeeMapper = session.getMapper(EmployeeMapper.class);
System.out.println("employeeMapper.getClass().getName():" + employeeMapper.getClass().getName());
//调用employeeMapper的方法去完成对数据库的操作
Emp emp = employeeMapper.selectEmpById(1L);
System.out.println(emp.toString());
}
//执行插入方法
@Test
public void TestInsert() {
EmployeeMapper employeeMapper = session.getMapper(EmployeeMapper.class);
Integer row = employeeMapper.insertEmp(new Emp(null, "网", 112.333));
System.out.println(row);
}
//执行删除方法
@Test
public void TestDelete() {
EmployeeMapper employeeMapper = session.getMapper(EmployeeMapper.class);
Integer row = employeeMapper.deleteEmp(2l);
System.out.println(row);
}
//执行更新方法
@Test
public void TestUpdate() {
EmployeeMapper employeeMapper = session.getMapper(EmployeeMapper.class);
Integer row = employeeMapper.updateEmp(new Emp(3l, "张三", 222.33));
System.out.println(row);
}
@After
public void clear() {
session.commit();
session.close();
}
}
2.3.给SQL语句传参
2.3.1.#{}方式
Mybatis会在运行过程中,把配置文件中的SQL语句里面的#{}转换为“?”占位符,发送给数据库执行。
配置文件中的SQL:
<delete id="deleteEmployeeById">
delete from t_emp where emp_id=#{empId}
delete>
实际执行的SQL:
delete from t_emp where emp_id=?
2.3.2.${}方式
根据${}拼字符串
示例:
-
Mapper接口
public interface EmployeeMapper { Emp selectEmpByName(String name); } -
在mapper.xml配置文件配置sql
<select id="selectEmpByName" resultType="com.stonebridge.myBatis.domain.Emp"> select emp_id empId, emp_name empName, emp_salary empSalary from t_emp where emp_name like "%${name}%" select> -
调用
@Test public void testDollar() { EmployeeMapper employeeMapper = session.getMapper(EmployeeMapper.class); Emp emp = employeeMapper.selectEmpByName("r"); System.out.println(emp.toString()); } -
拼接sql效果
select emp_id empId, emp_name empName, emp_salary empSalary from t_emp where emp_name like "%r%"
2.4.数据输入
2.4.1.Mybatis总体机制概括

2.4.2.概念说明
这里数据输入具体是指上层方法(例如Service方法)调用Mapper接口时,数据传入的形式。
- 简单类型:只包含一个值的数据类型
- 基本数据类型:int、byte、short、double、……
- 基本数据类型的包装类型:Integer、Character、Double、……
- 字符串类型:String
- 复杂类型:包含多个值的数据类型
- 实体类类型:Employee、Department、……
- 集合类型:List、Set、Map、……
- 数组类型:int[]、String[]、……
- 复合类型:List
、实体类中包含集合……
2.4.3.单个简单类型参数
2.4.3.1.Mapper接口中抽象方法的声明
Integer deleteEmp(Long empId);
2.4.3.2.Mapper配置文件
<delete id="deleteEmp">
DELETE
FROM t_emp
WHERE emp_id = #{empId}
delete>
2.4.4.实体类类型参数
2.4.4.1.Mapper接口中抽象方法的声明
Integer insertEmp(Emp emp);
2.4.4.2.mapper配置文件
<insert id="insertEmp">
INSERT INTO t_emp(emp_name,emp_salary) VALUES (#{empName},#{empSalary})
insert>
2.4.4.3.关系流程
Mybatis会根据#{}中传入的数据,加工成getXxx()方法,通过反射在实体类对象中调用这个方法,从而获取到对应的数据。填充到#{}这个位置。

2.4.5.零散的简单类型数据
2.4.5.1.Mapper接口中抽象方法的声明
Integer createEmp(@Param("empId") Long empId, @Param("name") String name, @Param("salary") Double salary);
2.4.5.2.Mapper配置文件
如果我们有在接口声明抽象方法时使用@Param注解给参数命名,那么就可以在#{}中使用我们指定的名称
void updateSalaryById(@Param(“empId”) Long empId, @Param(“empSalary”) Double salary);
如果我们没有在接口声明抽象方法时给参数命名,那么Mybatis会要求使用默认参数名
BindingException: Parameter ‘salary’ not found. Available parameters are [arg1, arg0, param1, param2]
<insert id="createEmp">
INSERT INTO t_emp(emp_id, emp_name, emp_salary)
VALUES (#{empId}, #{name}, #{salary})
insert>
2.4.5.3.Junit测试
@Test
public void TestMultiParama() {
EmployeeMapper employeeMapper = session.getMapper(EmployeeMapper.class);
Long empId = 24L;
Double salary = Double.parseDouble("12345.67");
String name = "stonebridge";
Integer row = employeeMapper.createEmp(empId, name, salary);
System.out.println(row); //1
}
2.4.5.4.测试效果
INSERT INTO t_emp(emp_id, emp_name, emp_salary) VALUES (?, ?, ?) (BaseJdbcLogger.java:137)
Parameters: 24(Long), stonebridge(String), 12345.67(Double) (BaseJdbcLogger.java:137)
DEBUG 10-28 21:13:38,791 <== Updates: 1 (BaseJdbcLogger.java:137)
2.4.5.5.对应关系

2.4.6.Map类型参数
2.4.6.1.Mapper接口中抽象方法的声明
int updateEmployeeByMap(Map<String, Object> paramMap);
2.4.6.2.Mapper配置文件
<update id="updateEmployeeByMap">
update t_emp
set emp_salary=#{empSalaryKey}
where emp_id = #{empIdKey}
update>
2.4.6.3.Junit测试
@Test
public void testUpdateEmpNameByMap() {
EmployeeMapper mapper = session.getMapper(EmployeeMapper.class);
Map<String, Object> paramMap = new HashMap<>();
paramMap.put("empSalaryKey", 999.99);
paramMap.put("empIdKey", 3);
int result = mapper.updateEmployeeByMap(paramMap);
System.out.println("result = " + result);
}
2.4.6.4.对应关系
#{}中写Map中的key
2.4.6.5.使用场景
有很多零散的参数需要传递,但是没有对应的实体类类型可以使用。使用@Param注解一个一个传入又太麻烦了,可以都封装到Map中。
2.5.数据输出
2.5.1.返回单个简单类型数据
2.5.1.1.Mapper接口中的抽象方法
int selectEmpCount();
2.5.1.2.Mapper配置文件
<select id="selectEmpCount" resultType="int">
select count(*) from t_emp
select>
2.5.1.3.Junit测试
@Test
public void testEmpCount() {
EmployeeMapper employeeMapper = session.getMapper(EmployeeMapper.class);
int count = employeeMapper.selectEmpCount();
System.out.println("count = " + count);
}

2.5.2.返回实体类对象
2.5.2.1.Mapper接口的抽象方法
Employee selectEmployee(Integer empId);
2.5.2.2.Mapper配置文件
<select id="selectEmployee" resultType="com.atguigu.mybatis.entity.Employee">
select emp_id empId,emp_name empName,emp_salary empSalary from t_emp where emp_id=#{maomi}
select>
通过给数据库表字段加别名,让查询结果的每一列都和Java实体类中属性对应起来。如果所有查询的字段和实体类中的字段都对不上,就会返回null,而不是空的实体类对象。
2.5.2.3.Junit测试
@Test
public void testSelectEmployee() {
EmployeeMapper employeeMapper = session.getMapper(EmployeeMapper.class);
Emp emp = employeeMapper.selectEmployee(23);
System.out.println(emp);
}

2.5.2.4.补充:增加全局配置自动识别对应关系
在mybatis的主配置文件mybatis-config.xml开启增加全局配置自动识别对应关系。
将mapUnderscoreToCamelCase属性配置为true,表示开启自动映射驼峰式命名规则
规则要求如下:
- 数据库表字段命名方式:单词_单词 ;例如depart_name
- Java实体类属性名命名方式:首字母小写的驼峰式命名;例如departName
<settings>
<setting name="mapUnderscoreToCamelCase" value="true"/>
settings>
开启该配置后,Mapper配置文件。
<select id="selectEmployee" resultType="com.atguigu.mybatis.entity.Employee">
select emp_id,emp_name,emp_salary from t_emp where emp_id=#{maomi}
select>
2.5.3.返回Map类型
适用于SQL查询返回的各个字段综合起来并不和任何一个现有的实体类对应,没法封装到实体类对象中。能够封装成实体类类型的,就不使用Map类型。
2.5.3.1.Mapper接口的抽象方法
Map<String,Object> selectEmpNameAndMaxSalary();
2.5.3.2.Mapper配置文件
<select id="selectEmpNameAndMaxSalary" resultType="map">
SELECT emp_name 员工姓名,
emp_salary 员工工资,
(SELECT AVG(emp_salary) FROM t_emp) 部门平均工资
FROM t_emp
WHERE emp_salary = (
SELECT MAX(emp_salary)
FROM t_emp
)
select>
2.5.3.3.Junit测试
@Test
public void testQueryEmpNameAndSalary() {
EmployeeMapper employeeMapper = session.getMapper(EmployeeMapper.class);
Map<String, Object> resultMap = employeeMapper.selectEmpNameAndMaxSalary();
Set<Map.Entry<String, Object>> entrySet = resultMap.entrySet();
for (Map.Entry<String, Object> entry : entrySet) {
String key = entry.getKey();
Object value = entry.getValue();
System.out.println(key + "=" + value);
}
}

2.5.4.返回List类型
查询结果返回多个实体类对象,希望把多个实体类对象放在List集合中返回。此时不需要任何特殊处理,在resultType属性中还是设置实体类类型即可。
2.5.4.1.Mapper接口的抽象方法
List<Emp> selectAll();
2.5.4.2.Mapper配置文件
<select id="selectAll" resultType="com.stonebridge.myBatis.domain.Emp">
select emp_id empId, emp_name empName, emp_salary empSalary
from t_emp
select>
2.5.4.3.Junit测试
@Test
public void testSelectAll() {
EmployeeMapper employeeMapper = session.getMapper(EmployeeMapper.class);
List<Emp> employeeList = employeeMapper.selectAll();
for (Emp employee : employeeList) {
System.out.println("employee = " + employee);
}
}
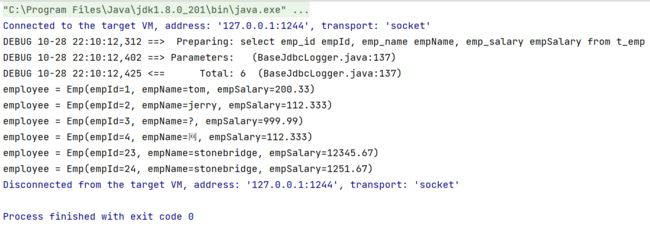
2.5.5.返回自增主键
2.5.5.1.使用场景
例如:保存订单信息。需要保存Order对象和List
在保存List
insert into t_order_item(item_name,item_price,item_count,order_id) values(...)
这里需要用到的order_id,是在保存Order对象时,数据库表以自增方式产生的,需要特殊办法拿到这个自增的主键值。至于,为什么不能通过查询最大主键的方式解决这个问题,参考下图:

2.5.5.2.在Mapper配置文件中设置方式
-
Mapper接口中的抽象方法
int insertEmployee(Employee employee); -
SQL语句
<insert id="insertEmployee" useGeneratedKeys="true" keyProperty="empId"> insert into t_emp(emp_name,emp_salary) values(#{empName},#{empSalary}) insert> -
Junit测试
@Test public void testSaveEmp() { EmployeeMapper employeeMapper = session.getMapper(EmployeeMapper.class); Emp employee = new Emp(); employee.setEmpName("john"); employee.setEmpSalary(666.66); employeeMapper.insertEmployee(employee); System.out.println("employee.getEmpId() = " + employee.getEmpId()); } -
注意
Mybatis是将自增主键的值设置到实体类对象中,而不是以Mapper接口方法返回值的形式返回。
2.5.5.3.不支持自增主键的数据库
而对于不支持自增型主键的数据库(例如 Oracle),则可以使用 selectKey 子元素:selectKey 元素将会首先运行,id 会被设置,然后插入语句会被调用。
<insert id="insertEmployee" parameterType="com.atguigu.mybatis.beans.Employee" databaseId="oracle">
<selectKey order="BEFORE" keyProperty="id" resultType="integer">
select employee_seq.nextval from dual
selectKey>
insert into orcl_employee(id,last_name,email,gender) values(#{id},#{lastName},#{email},#{gender})
insert>
2.5.6.数据库表字段和实体类属性对应关系
2.5.6.1.别名
将字段的别名设置成和实体类属性一致。
<select id="selectEmployee" resultType="com.atguigu.mybatis.entity.Employee">
select emp_id empId,emp_name empName,emp_salary empSalary from t_emp where emp_id=#{maomi}
select>
关于实体类属性的约定:getXxx()方法、setXxx()方法把方法名中的get或set去掉,首字母小写。
2.5.6.2.全局配置自动识别驼峰式命名规则
在Mybatis全局配置文件加入如下配置:
<settings>
<setting name="mapUnderscoreToCamelCase" value="true"/>
settings>
SQL语句中可以不使用别名
<select id="selectEmployee" resultType="com.atguigu.mybatis.entity.Employee">
select emp_id,emp_name,emp_salary from t_emp where emp_id=#{empId}
select>
2.5.6.3.使用resultMap
使用resultMap标签定义对应关系,再在后面的SQL语句中引用这个对应关系
-
Mapper接口中的抽象方法
List<Emp> selectWithResultMap(); -
映射文件
<resultMap id="selectWithResultMapResultMap" type="com.stonebridge.myBatis.domain.Emp"> <id column="emp_id" property="empId"/> <result column="emp_name" property="empName"/> <result column="emp_salary" property="empSalary"/> resultMap> <select id="selectWithResultMap" resultMap="selectWithResultMapResultMap"> select emp_id, emp_name, emp_salary from t_emp select> -
测试
@Test public void testSelectWithResultMap() { EmployeeMapper employeeMapper = session.getMapper(EmployeeMapper.class); List<Emp> empList = employeeMapper.selectWithResultMap(); for (Emp emp : empList) { System.out.println("emp = " + emp); } }
3.关联关系
3.1.概念
3.1.1.关联关系概念说明
3.1.1.1.数量关系
主要体现在数据库表中
-
一对一
夫妻关系,人和身份证号
-
一对多
用户和用户的订单,锁和钥匙
-
多对多
老师和学生,部门和员工
3.1.1.2.关联关系的方向
主要体现在Java实体类中
- 双向:双方都可以访问到对方
- Customer:包含Order的集合属性
- Order:包含单个Customer的属性
- 单向:双方中只有一方能够访问到对方
- Customer:不包含Order的集合属性,访问不到Order
- Order:包含单个Customer的属性
3.1.2.创建模型
3.1.2.1.创建实体类
@Data
@NoArgsConstructor
@AllArgsConstructor
@ToString
public class Customer {
private long customerId;
private String customerName;
// 体现对多关系
private List<Order> orderList;
}
@Data
@NoArgsConstructor
@AllArgsConstructor
@ToString
public class Order {
private long orderId;
private String orderName;
private long customerId;
// 体现对一关系
private Customer customer;
}
3.1.2.2.创建数据库表插入测试数据
CREATE TABLE `t_customer` (
`customer_id` INT NOT NULL AUTO_INCREMENT,
`customer_name` CHAR(100),
PRIMARY KEY (`customer_id`)
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `t_order` (
`order_id` INT NOT NULL AUTO_INCREMENT,
`order_name` CHAR(100),
`customer_id` INT,
PRIMARY KEY (`order_id`)
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `t_customer` (`customer_name`) VALUES ('c01');
INSERT INTO `t_order` (`order_name`, `customer_id`) VALUES ('o1', '1');
INSERT INTO `t_order` (`order_name`, `customer_id`) VALUES ('o2', '1');
INSERT INTO `t_order` (`order_name`, `customer_id`) VALUES ('o3', '1');
实际开发时,一般在开发过程中,不给数据库表设置外键约束。
原因是避免调试不方便。
一般是功能开发完成,再加外键约束检查是否有bug。
3.2.一对一
3.2.1.JavaBean
@Data
@NoArgsConstructor
@AllArgsConstructor
@ToString
public class Customer {
private Integer customerId;
private String customerName;
}
@Data
@NoArgsConstructor
@AllArgsConstructor
@ToString
public class Order {
private long orderId;
private String orderName;
private long customerId;
// 体现对一关系
private Customer customer;
}
3.2.2.创建OrderMapper接口
public interface OrderMapper {
Order selectOrderWithCustomer(Integer orderId);
}
3.2.3.创建OrderMapper.xml配置文件
配置关联关系和SQL语句
DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.stonebridge.mybatis.mapper.OrderMapper">
<resultMap id="selectOrderWithCustomerResultMap" type="com.stonebridge.mybatis.entity.Order">
<id column="order_id" property="orderId">id>
<result column="order_name" property="orderName">result>
<result column="customer_id" property="customerId">result>
<association property="customer" javaType="com.stonebridge.mybatis.entity.Customer">
<id column="customerId" property="customer_id">id>
<result column="customerName" property="customer_name">result>
association>
resultMap>
<select id="selectOrderWithCustomer" resultMap="selectOrderWithCustomerResultMap">
select order_id, order_name, a.customer_id
from t_order a
left join t_customer b on a.customer_id = b.customer_id
where order_id = #{orderId};
select>
mapper>
3.2.4.在MyBatis全局配置文件中注册配置文件
mybatis-config.xml
<mappers>
<mapper resource="mappers/OrderMapper.xml"/>
mappers>
3.2.5.Junit测试
@Test
public void testQueryOrderWithCustomer() {
OrderMapper orderMapper = session.getMapper(OrderMapper.class);
Order order = orderMapper.selectOrderWithCustomer(1);
System.out.println(order);
}
DEBUG 10-30 22:52:25,155 ==> Preparing: select order_id, order_name, a.customer_id from t_order a left join t_customer b on a.customer_id = b.customer_id where order_id = ?; (BaseJdbcLogger.java:137)
DEBUG 10-30 22:52:25,244 ==> Parameters: 1(Integer) (BaseJdbcLogger.java:137)
DEBUG 10-30 22:52:25,272 <== Total: 1 (BaseJdbcLogger.java:137)
Order(orderId=1, orderName=o1, customerId=1, customer=null)
3.2.6.对应关系参考

在“对一”关联关系中,我们的配置比较多,但是关键词就只有:association和javaType
3.3.一对多
3.3.1.JavaBean
@Data
@NoArgsConstructor
@AllArgsConstructor
@ToString
public class Customer {
private Integer customerId;
private String customerName;
// 声明order的List集合类型的属性,建立『对多(对方是多的一端)』关联关系
private List<Order> orderList;
}
@Data
@NoArgsConstructor
@AllArgsConstructor
@ToString
public class Order {
private Integer orderId;
private String orderName;
private Integer customerId;
}
3.3.2.创建CustomerMapper接口
public interface CustomerMapper {
Customer selectCustomerWithOrderList(int i);
}
3.3.3.创建OrderMapper.xml配置文件
配置关联关系和SQL语句
DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.stonebridge.mybatis.mapper.CustomerMapper">
<resultMap id="selectCustomerWithOrderLisResultMap" type="com.stonebridge.mybatis.entity.Customer">
<id column="customer_id" property="customerId">id>
<result column="customer_name" property="customerName">result>
<collection property="orderList" ofType="com.stonebridge.mybatis.entity.Order">
<id column="order_id" property="orderId">id>
<result column="order_name" property="orderName">result>
<result column="customer_id" property="customerId">result>
collection>
resultMap>
<select id="selectCustomerWithOrderList" resultMap="selectCustomerWithOrderLisResultMap">
select c.customer_id, customer_name, order_id, order_name
from t_customer c
left join t_order o on c.customer_id = o.customer_id
where c.customer_id = #{customerId}
select>
mapper>
3.3.4.在MyBatis全局配置文件中注册配置文件
mybatis-config.xml
<mappers>
<mapper resource="mappers/OrderMapper.xml"/>
mappers>
3.3.5.Junit测试
@Test
public void testQueryCustomerWithOrderList() {
CustomerMapper customerMapper = session.getMapper(CustomerMapper.class);
Integer customerId = 1;
// 执行查询
Customer customer = customerMapper.selectCustomerWithOrderList(customerId);
// 打印Customer本身
System.out.println("customer = " + customer);
// 从Customer中获取Order集合数据
List<Order> orderList = customer.getOrderList();
for (Order order : orderList) {
System.out.println("order = " + order);
}
}
3.3.6.对应关系参考

在“对多”关联关系中,同样有很多配置,但是提炼出来最关键的就是:collection和ofType
3.4.分步查询
3.4.1.概念和需求
在执行一对一查询关联查询时,查询Order表作为主表,其中的Customer数据不管用不用都会查出来,如果查询的数据不用就浪费资源,完全不查需要的时候又要单独查询,此时也没有必要考虑关联关系了。
希望即能维持关联关系,用的时候又可以查询出来。
为了实现延迟加载,对Customer和Order的查询必须分开,分成两步来做,才能够实现(分步查询是懒加载的基础)。为此,我们需要单独查询Order,也就是需要在Mapper配置文件中,单独编写查询Order集合数据的SQL语句。
3.4.2.一对一分步查询
3.4.2.1.创建OrderMapper接口
public interface OrderMapper {
Order selectOrderWithOrderTwoStep(Integer orderId);
}
3.4.2.2.在映射文件配置sql
OrderMapper.xml
DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.stonebridge.mybatis.mapper.OrderMapper">
<resultMap id="selectOrderWithCustomerTwoStepResultMap" type="com.stonebridge.mybatis.entity.Order">
<id column="order_id" property="orderId"/>
<result column="order_name" property="orderName"/>
<result column="customer_id" property="customerId"/>
<association
property="customer"
column="customer_id"
select="com.stonebridge.mybatis.mapper.CustomerMapper.selectCustomerById"/>
resultMap>
<select id="selectOrderWithOrderTwoStep" resultMap="selectOrderWithCustomerTwoStepResultMap">
select order_id, order_name, customer_id
from t_order
where order_id = #{orderId}
select>
mapper>
CustomerMapper.xml
配置分步查询中对com.stonebridge.mybatis.mapper.CustomerMapper.selectCustomerById进行定义
DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.stonebridge.mybatis.mapper.CustomerMapper">
<select id="selectCustomerById" resultType="com.stonebridge.mybatis.entity.Customer">
select customer_id, customer_name
from t_customer
where customer_id = #{customerId}
select>
mapper>
3.4.2.3.Junit测试
@Test
public void testQueryOrderWithOrderList() {
OrderMapper orderMapper = session.getMapper(OrderMapper.class);
Integer orderId = 1;
// 查询Order对象
Order order = orderMapper.selectOrderWithOrderTwoStep(orderId);
// 打印Order对象本身信息
System.out.println("order = " + order);
// 通过Order对象获取关联的Customer对象
Customer customer = order.getCustomer();
System.out.println("customer = " + customer);
}

3.4.3.一对多分布查询
3.4.3.1.创建CustomerMapper接口
public interface CustomerMapper {
Customer selectCustomerWithOrderList(Integer customerId);
}
3.4.3.2.在映射文件配置sql
CustomerMapper.xml
DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.stonebridge.mybatis.mapper.CustomerMapper">
<resultMap id="selectCustomerWithOrderListResultMap" type="com.stonebridge.mybatis.entity.Customer">
<id column="customer_id" property="customerId"/>
<result column="customer_name" property="customerName"/>
<collection property="orderList"
column="customer_id"
select="com.stonebridge.mybatis.mapper.OrderMapper.selectOrderListByCustomerId"/>
resultMap>
<select id="selectCustomerWithOrderList" resultMap="selectCustomerWithOrderListResultMap">
select customer_id, customer_name
from t_customer
where customer_id = #{customerId}
select>
mapper>
OrderMapper.xml
配置分步查询中对com.stonebridge.mybatis.mapper.CustomerMapper.selectCustomerById进行定义
DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.stonebridge.mybatis.mapper.OrderMapper">der_id = #{orderId}
select>
<select id="selectOrderListByCustomerId" resultType="com.stonebridge.mybatis.entity.Order">
select order_id, order_name, customer_id
from t_order
where customer_id = #{customerId}
select>
mapper>
3.4.3.3.Junit测试
@Test
public void testQueryCustomerWithOrderList() {
CustomerMapper customerMapper = session.getMapper(CustomerMapper.class);
Integer customerId = 1;
// 查询Order对象
Customer customer = customerMapper.selectCustomerWithOrderList(customerId);
// 打印Order对象本身信息
System.out.println("customer = " + customer);
// 通过Order对象获取关联的Customer对象
List<Order> list = customer.getOrderList();
for (Order order : list) {
System.out.println("order=" + order);
}
}

3.4.3.4.各个要素之间的对应关系

3.5.延迟加载
3.5.1.概念
查询到Customer的时候,不一定会使用Order的List集合数据。如果Order的集合数据始终没有使用,那么这部分数据占用的内存就浪费了。对此,我们希望不一定会被用到的数据,能够在需要使用的时候再去查询。
例如:对Customer进行1000次查询中,其中只有15次会用到Order的集合数据,那么就在需要使用时才去查询能够大幅度节约内存空间。
延迟加载的概念:对于实体类关联的属性到需要使用时才查询。也叫懒加载。
3.5.2.在Mybatis全局配置文件中配置settings

3.5.2.1.低版本
在Mybatis全局配置文件中配置settings
<settings>
<setting name="lazyLoadingEnabled" value="true"/>
<setting name="aggressiveLazyLoading" value="false"/>
settings>
官方文档中对aggressiveLazyLoading属性的解释:
When enabled, an object with lazy loaded properties will be loaded entirely upon a call to any of the lazy properties.Otherwise, each property is loaded on demand.
3.5.2.2.较高版本
<settings>
<setting name="lazyLoadingEnabled" value="true"/>
settings>
3.5.2.3.Junit测试
不要先打印customer整体
@Test
public void testQueryCustomerWithOrderList() throws InterruptedException {
CustomerMapper customerMapper = session.getMapper(CustomerMapper.class);
Integer customerId = 1;
// 查询Order对象
Customer customer = customerMapper.selectCustomerWithOrderList(customerId);
// 打印Order对象本身信息
// System.out.println("customer = " + customer);
System.out.println("customerId:" + customer.getCustomerId());
System.out.println("customerName:" + customer.getCustomerName());
TimeUnit.SECONDS.sleep(3);
// 通过Order对象获取关联的Customer对象
List<Order> list = customer.getOrderList();
for (Order order : list) {
System.out.println("order=" + order);
}
}
效果:刚开始先查询Customer本身,需要用到OrderList的时候才发送SQL语句去查询

3.5.2.4.关键词总结
我们是在“对多”关系中举例说明延迟加载的,在“对一”中配置方式基本一样。
| 关联关系 | 配置项关键词 | 所在配置文件 |
|---|---|---|
| 对一 | association标签/javaType属性 | Mapper配置文件中的resultMap |
| 对多 | collection标签/ofType属性 | Mapper配置文件中的resultMap |
| 对一分步 | association标签/select属性 | Mapper配置文件中的resultMap |
| 对多分步 | collection标签/select属性 | Mapper配置文件中的resultMap |
| 延迟加载[低] | lazyLoadingEnabled设置为true aggressiveLazyLoading设置为false | Mybatis全局配置文件中的settings |
| 延迟加载[高] | lazyLoadingEnabled设置为true | Mybatis全局配置文件中的settings |
3.6.多对多关联关系需要中间表
3.7.1.如果不使用中间表

在某一个表中,使用一个字段保存多个“外键”值,这将导致无法使用SQL语句进行关联查询。
3.7.2.使用中间表

这样就可以使用SQL进行关联查询了。只是有可能需要三张表进行关联。
3.7.3.中间表设置主键
3.7.3.1.另外设置一个专门的主键字段

3.7.3.2.使用联合主键


使用联合主键时,只要多个字段的组合不重复即可,单个字段内部是可以重复的。
4.动态SQL
4.1.简介
Mybatis框架的动态SQL技术是一种根据特定条件动态拼装SQL语句的功能,它存在的意义是为了解决拼接SQL语句字符串时的痛点问题。
One of the most powerful features of MyBatis has always been its Dynamic SQL capabilities. If you have any experience with JDBC or any similar framework, you understand how painful it is to conditionally concatenate strings of SQL together, making sure not to forget spaces or to omit a comma at the end of a list of columns. Dynamic SQL can be downright painful to deal with.
MyBatis的一个强大的特性之一通常是它的动态SQL能力。如果你有使用JDBC或其他相似框架的经验,你就明白条件地串联SQL字符串在一起是多么的痛苦,确保不能忘了空格或在列表的最后省略逗号。动态SQL可以彻底处理这种痛苦。
4.2.if和where标签
-
使用where标签动态生成SQL语句中的where子句
- 如果where标签内没有有效的条件,那么最终的SQL语句中,不会出现where关键词
- 能够去除查询条件中前后多余的and或or
-
使用if标签可以让SQL语句的片段,在满足条件时才加入最终的SQL语句
test属性:if标签中的判断条件。在test属性中能直接访问接口抽象方法传入的数据。
test属性:在条件判断语句中,难免会用到大于号、小于号。此时需要将大于号(>)、小于号(<)转义
XML转义字符
< < 小于号 > > 大于号 <= <= 小于等于号 >= >= 大于等于号 & & 和 ' ’ 单引号 " " 双引号
<select id="selectEmpByCondition" resultType="com.stonebridge.MyBatis.domain.Emp">
select emp_id, emp_name, emp_salary
from t_emp
<where>
<if test="empName!=null">
or emp_name=#{empName}
if>
<if test="empSalary > 100">
or emp_salary=#{empSalary}
if>
where>
select>
测试:
@Test
public void testQueryEmp() {
EmployeeMapper customerMapper = session.getMapper(EmployeeMapper.class);
Map<String, Object> map = new HashMap<>();
map.put("empName",null);
map.put("empSalary",999.99);
List<Emp> list = customerMapper.selectEmpByCondition(map);
for (Emp emp : list) {
System.out.println("emp:" + emp.toString());
}
}

@Test
public void testQueryEmp() {
EmployeeMapper customerMapper = session.getMapper(EmployeeMapper.class);
Map<String, Object> map = new HashMap<>();
map.put("empName","stonebridge");
map.put("empSalary",200000);
List<Emp> list = customerMapper.selectEmpByCondition(map);
for (Emp emp : list) {
System.out.println("emp:" + emp.toString());
}
}

4.3.set标签
4.3.1.相关业务需求举例
实际开发时,对一个实体类对象进行更新。往往不是更新所有字段,而是更新一部分字段。此时页面上的表单往往不会给不修改的字段提供表单项。
<form action="" method="">
<input type="hidden" name="userId" value="5232" />
年 龄:<input type="text" name="userAge" /><br/>
性 别:<input type="text" name="userGender" /><br/>
坐 标:<input type="text" name="userPosition" /><br/>
<button type="submit">修改button>
form>
例如上面的表单,如果服务器端接收表单时,使用的是User这个实体类,那么userName、userBalance、userGrade接收到的数据就是null。
如果不加判断,直接用User对象去更新数据库,在Mapper配置文件中又是每一个字段都更新,那就会把userName、userBalance、userGrade设置为null值,从而造成数据库表中对应数据被破坏。
此时需要我们在Mapper配置文件中,对update语句的set子句进行定制,此时就可以使用动态SQL的set标签,没有set子句的update语句会导致SQL语法错误。
4.3.2.实际配置方式
<update id="updateEmployeeDynamic">
update t_emp
<set>
<if test="empName != null">
emp_name=#{empName},
if>
<if test="empSalary < 3000">
emp_salary=#{empSalary},
if>
set>
where emp_id=#{empId}
update>
@Test
public void testUpadteEmpCondition() {
EmployeeMapper customerMapper = session.getMapper(EmployeeMapper.class);
Map<String, Object> map = new HashMap<>();
map.put("empName", "stonebridge");
map.put("empSalary", 20000);
Integer row = customerMapper.updateEmpConditional(map);
}

4.4.trim标签
4.4.1.基本概念
使用trim标签控制条件部分两端是否包含某些字符
- prefix属性:指定要动态添加的前缀
- suffix属性:指定要动态添加的后缀
- prefixOverrides属性:指定要动态去掉的前缀,使用“|”分隔有可能的多个值
- suffixOverrides属性:指定要动态去掉的后缀,使用“|”分隔有可能的多个值
<select id="selectEmployeeByConditionByTrim" resultType="com.atguigu.mybatis.entity.Employee">
select emp_id,emp_name,emp_age,emp_salary,emp_gender
from t_emp
<trim prefix="where" suffixOverrides="and|or">
<if test="empName != null">
emp_name=#{empName} and
if>
<if test="empSalary > 3000">
emp_salary>#{empSalary} and
if>
<if test="empAge <= 20">
emp_age=#{empAge} or
if>
<if test="empGender=='male'">
emp_gender=#{empGender}
if>
trim>
select>
4.4.2.示例
<select id="selectEmpByConditionByTrim" resultType="com.stonebridge.MyBatis.domain.Emp">
select emp_id, emp_name, emp_salary from t_emp
<trim prefix="where" prefixOverrides="and|or">
<if test="empName != null">
or emp_name=#{empName}
if>
<if test="empSalary > 2000">
and emp_salary>#{empSalary}
if>
trim>
select>
@Test
public void testSelectEmpByConditionByTrim() {
EmployeeMapper customerMapper = session.getMapper(EmployeeMapper.class);
Map<String, Object> map = new HashMap<>();
map.put("empName", "stonebridge");
// map.put("empSalary", 2000);
List<Emp> list = customerMapper.selectEmpByConditionByTrim(map);
for (Emp emp : list) {
System.out.println(emp);
}
}

4.5.choose/when/otherwise标签
多个分支条件中,仅执行一个
- 从上到下依次执行条件判断
- 遇到的第一个满足条件的分支就会被采纳
- 被采纳分支后面的分支都将不被考虑
- 如果所有的when分支都不满足,那么就执行otherwise分支
<select id="selectEmployeeByConditionByChoose" resultType="com.atguigu.mybatis.entity.Employee">
select emp_id,emp_name,emp_salary from t_emp
where
<choose>
<when test="empName != null">emp_name=#{empName}when>
<when test="empSalary < 3000">emp_salary < 3000when>
<otherwise>1=1otherwise>
choose>
select>
4.6.foreach标签
4.6.1.基本用法
用批量插入举例
<foreach collection="empList" item="emp" separator="," open="values" index="myIndex">
(#{emp.empName},#{myIndex},#{emp.empSalary},#{emp.empGender})
foreach>
4.6.2.批量更新时需要注意
上面批量插入的例子本质上是一条SQL语句,而实现批量更新则需要多条SQL语句拼起来,用分号分开。也就是一次性发送多条SQL语句让数据库执行。此时需要在数据库连接信息的URL地址中设置:allowMultiQueries=true
atguigu.dev.url=jdbc:mysql://192.168.198.100:3306/mybatis0922?allowMultiQueries=true
对应的foreach标签如下:
<update id="updateEmployeeBatch">
<foreach collection="empList" item="emp" separator=";">
update t_emp set emp_name=#{emp.empName} where emp_id=#{emp.empId}
foreach>
update>
4.6.3.关于foreach标签的collection属性
如果没有给接口中List类型的参数使用@Param注解指定一个具体的名字,那么在collection属性中默认可以使用collection或list来引用这个list集合。这一点可以通过异常信息看出来:
Parameter 'empList' not found. Available parameters are [collection, list]
在实际开发中,为了避免隐晦的表达造成一定的误会,建议使用@Param注解明确声明变量的名称,然后在foreach标签的collection属性中按照@Param注解指定的名称来引用传入的参数。
4.6.4.示例
<insert id="batchInsert">
insert into t_emp(emp_name, emp_salary)
<foreach collection="empList" item="emp" separator="," open="values">
(#{emp.empName},#{emp.empSalary})
foreach>
insert>
@Test
public void testBatchInsert() {
EmployeeMapper customerMapper = session.getMapper(EmployeeMapper.class);
List<Emp> list = new ArrayList<>();
for (int i = 0; i < 10; i++) {
Emp emp = new Emp(null, "tiger_" + i, i * 1000.00);
list.add(emp);
}
customerMapper.batchInsert(list);
}

4.7.sql标签
4.7.1.抽取重复的SQL片段
<sql id="mySelectSql">
select emp_id,emp_name,emp_age,emp_salary,emp_gender from t_emp
sql>
4.7.2.引用已抽取的SQL片段
<include refid="mySelectSql"/>
5.缓存机制
5.1.简介
理解缓存的工作机制和缓存的用途。
5.1.1.缓存机制介绍
为了节约时间,节约性能,一个数据集查出来后把他放在缓存里面,下次需要的时候直接获取。
缓存一定是用在查询过程中的,增删改后数据库数据和缓存不一致,很多情况执行增删改后会清空缓存。

5.1.2.一级缓存和二级缓存
5.1.2.1.使用顺序

查询的顺序是:
- 先查询二级缓存,因为二级缓存中可能会有其他程序已经查出来的数据,可以拿来直接使用。
- 如果二级缓存没有命中,再查询一级缓存
- 如果一级缓存也没有命中,则查询数据库
- SqlSession关闭之前,一级缓存中的数据会写入二级缓存
5.1.2.2.效用范围
- 一级缓存:SqlSession级别,一级缓存占用的内存很小,默认存在
- 二级缓存:SqlSessionFactory级别,只要应用在运行,二级缓存就一直存在,二级缓存为整个应用服务,内存占用规模比较大。需要配置。

它们之间范围的大小参考下面图:

5.2.一级缓存
5.2.1.验证一级缓存
@Test
public void testFirstLevelCache() {
SqlSession session = factory.openSession();
EmployeeMapper mapper = session.getMapper(EmployeeMapper.class);
Integer empId = 1;
Emp emp01 = mapper.selectEmpById(empId);
System.out.println("第一次查询emp01=" + emp01.toString());
Emp emp02 = mapper.selectEmpById(empId);
System.out.println("第二次查询emp02=" + emp02.toString());
session.commit();
session.close();
}
打印结果:

5.2.2.一级缓存失效的情况
一级缓存的应用范围就是在同一个事务中,连续两次相同的查询操作才会用到,故一级缓存应用范围不大。
- 不是同一个SqlSession
- 同一个SqlSession但是查询条件发生了变化
- 同一个SqlSession两次查询期间执行了任何一次增删改操作
- 同一个SqlSession两次查询期间手动清空了缓存
- 同一个SqlSession两次查询期间提交了事务
5.3.二级缓存
这里使用的是Mybatis自带的二级缓存。
5.3.1.代码测试二级缓存
5.3.1.1.开启二级缓存功能
在想要使用二级缓存的Mapper配置文件中加入cache标签
<mapper namespace="com.stonebridge.MyBatis.dao.EmployeeMapper">
<cache/>
mapper>
5.3.1.2.让实体类支持序列化
public class Emp implements Serializable {
……
}
5.3.1.3.Junit测试
-
未启用二级缓存
查询后SqlSession关闭时,一级缓存中的数据会写入二级缓存。此时后续相同查询才会使用二级缓存。如果未关闭SqlSession则不会将一级缓存写入二级缓存。
示例:
@Test public void testSecondLevelCache() { // 测试二级缓存存在:使用两个不同SqlSession执行查询 // 说明:SqlSession提交事务时才会将查询到的数据存入二级缓存 // 所以本例并没有能够成功从二级缓存获取到数据 SqlSession session01 = factory.openSession(); SqlSession session02 = factory.openSession(); EmployeeMapper mapper01 = session01.getMapper(EmployeeMapper.class); EmployeeMapper mapper02 = session02.getMapper(EmployeeMapper.class); Integer empId = 1; // DEBUG 11-01 16:59:15,933 Cache Hit Ratio [com.stonebridge.MyBatis.dao.EmployeeMapper]: 0.0 Emp emp01 = mapper01.selectEmpById(empId); // DEBUG 11-01 16:59:16,630 Cache Hit Ratio [com.stonebridge.MyBatis.dao.EmployeeMapper]: 0.0 Emp emp02 = mapper02.selectEmpById(empId); System.out.println("emp01 = " + emp01); System.out.println("emp02 = " + emp02); session01.commit(); session01.close(); session02.commit(); session02.close(); }
-
启用二级缓存
@Test public void testSecondLevelCacheWork() { SqlSession session = factory.openSession(); EmployeeMapper employeeMapper = session.getMapper(EmployeeMapper.class); Integer empId = 1; // 第一次查询 Emp emp01 = employeeMapper.selectEmpById(empId); System.out.println("emp01 = " + emp01); // 提交事务 session.commit(); // 关闭旧SqlSession session.close(); // 开启新SqlSession session = factory.openSession(); // 第二次查询 employeeMapper = session.getMapper(EmployeeMapper.class); Emp emp02 = employeeMapper.selectEmpById(empId); System.out.println("emp02 = " + emp02); session.commit(); session.close(); session = factory.openSession(); employeeMapper = session.getMapper(EmployeeMapper.class); employeeMapper.selectEmpById(empId); session.commit(); session.close(); }
5.3.2.查询结果存入二级缓存的时机
结论:SqlSession关闭的时候,一级缓存中的内容会被存入二级缓存
// 1.开启两个SqlSession
SqlSession session01 = factory.openSession();
SqlSession session02 = factory.openSession();
// 2.获取两个EmployeeMapper
EmployeeMapper employeeMapper01 = session01.getMapper(EmployeeMapper.class);
EmployeeMapper employeeMapper02 = session02.getMapper(EmployeeMapper.class);
// 3.使用两个EmployeeMapper做两次查询,返回两个Employee对象
Employee employee01 = employeeMapper01.selectEmployeeById(2);
Employee employee02 = employeeMapper02.selectEmployeeById(2);
// 4.比较两个Employee对象
System.out.println("employee02.equals(employee01) = " + employee02.equals(employee01));
上面代码打印的结果是:
DEBUG 12-01 10:10:32,209 Cache Hit Ratio [com.atguigu.mybatis.EmployeeMapper]: 0.0 (LoggingCache.java:62)
DEBUG 12-01 10:10:32,570 ==> Preparing: select emp_id,emp_name,emp_salary,emp_gender,emp_age from t_emp where emp_id=? (BaseJdbcLogger.java:145)
DEBUG 12-01 10:10:32,624 ==> Parameters: 2(Integer) (BaseJdbcLogger.java:145)
DEBUG 12-01 10:10:32,643 <== Total: 1 (BaseJdbcLogger.java:145)
DEBUG 12-01 10:10:32,644 Cache Hit Ratio [com.atguigu.mybatis.EmployeeMapper]: 0.0 (LoggingCache.java:62)
DEBUG 12-01 10:10:32,661 ==> Preparing: select emp_id,emp_name,emp_salary,emp_gender,emp_age from t_emp where emp_id=? (BaseJdbcLogger.java:145)
DEBUG 12-01 10:10:32,662 ==> Parameters: 2(Integer) (BaseJdbcLogger.java:145)
DEBUG 12-01 10:10:32,665 <== Total: 1 (BaseJdbcLogger.java:145)
employee02.equals(employee01) = false
修改代码:
// 1.开启两个SqlSession
SqlSession session01 = factory.openSession();
SqlSession session02 = factory.openSession();
// 2.获取两个EmployeeMapper
EmployeeMapper employeeMapper01 = session01.getMapper(EmployeeMapper.class);
EmployeeMapper employeeMapper02 = session02.getMapper(EmployeeMapper.class);
// 3.使用两个EmployeeMapper做两次查询,返回两个Employee对象
Employee employee01 = employeeMapper01.selectEmployeeById(2);
// ※第一次查询完成后,把所在的SqlSession关闭,使一级缓存中的数据存入二级缓存
session01.close();
Employee employee02 = employeeMapper02.selectEmployeeById(2);
// 4.比较两个Employee对象
System.out.println("employee02.equals(employee01) = " + employee02.equals(employee01));
// 5.另外一个SqlSession用完正常关闭
session02.close();
打印结果:
DEBUG 12-01 10:14:06,804 Cache Hit Ratio [com.atguigu.mybatis.EmployeeMapper]: 0.0 (LoggingCache.java:62)
DEBUG 12-01 10:14:07,135 ==> Preparing: select emp_id,emp_name,emp_salary,emp_gender,emp_age from t_emp where emp_id=? (BaseJdbcLogger.java:145)
DEBUG 12-01 10:14:07,202 ==> Parameters: 2(Integer) (BaseJdbcLogger.java:145)
DEBUG 12-01 10:14:07,224 <== Total: 1 (BaseJdbcLogger.java:145)
DEBUG 12-01 10:14:07,308 Cache Hit Ratio [com.atguigu.mybatis.EmployeeMapper]: 0.5 (LoggingCache.java:62)
employee02.equals(employee01) = false
5.3.3.二级缓存相关配置
在Mapper配置文件中添加的cache标签可以设置一些属性:
-
eviction属性:缓存回收策略
LRU(Least Recently Used) – 最近最少使用的:移除最长时间不被使用的对象。
FIFO(First in First out) – 先进先出:按对象进入缓存的顺序来移除它们。
SOFT – 软引用:移除基于垃圾回收器状态和软引用规则的对象。
WEAK – 弱引用:更积极地移除基于垃圾收集器状态和弱引用规则的对象。
默认的是 LRU。
-
flushInterval属性:刷新间隔,单位毫秒
默认情况是不设置,也就是没有刷新间隔,缓存仅仅调用语句时刷新
-
size属性:引用数目,正整数
代表缓存最多可以存储多少个对象,太大容易导致内存溢出
-
readOnly属性:只读,true/false
true:只读缓存;会给所有调用者返回缓存对象的相同实例。因此这些对象不能被修改。这提供了很重要的性能优势。
false:读写缓存;会返回缓存对象的拷贝(通过序列化)。这会慢一些,但是安全,因此默认是 false。
5.4.整合EHCache
5.4.1.EHCache简介
官网地址:https://www.ehcache.org/

Ehcache is an open source, standards-based cache that boosts performance, offloads your database, and simplifies scalability. It’s the most widely-used Java-based cache because it’s robust, proven, full-featured, and integrates with other popular libraries and frameworks. Ehcache scales from in-process caching, all the way to mixed in-process/out-of-process deployments with terabyte-sized caches.
5.4.2.整合操作
5.4.2.1.Mybatis环境
在Mybatis环境下整合EHCache,前提当然是要先准备好Mybatis的环境。
5.4.2.2.添加依赖
-
依赖信息
<dependency> <groupId>org.mybatis.cachesgroupId> <artifactId>mybatis-ehcacheartifactId> <version>1.2.1version> dependency> <dependency> <groupId>ch.qos.logbackgroupId> <artifactId>logback-classicartifactId> <version>1.2.3version> dependency> -
依赖传递情况

-
各主要jar包作用
jar包名称 作用 mybatis-ehcache Mybatis和EHCache的整合包 ehcache EHCache核心包 slf4j-api SLF4J日志门面包 logback-classic 支持SLF4J门面接口的一个具体实现
5.4.2.3.整合EHCache
-
创建EHCache配置文件
ehcache.xml

-
文件内容
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="../config/ehcache.xsd"> <diskStore path="D:\atguigu\ehcache"/> <defaultCache maxElementsInMemory="1000" maxElementsOnDisk="10000000" eternal="false" overflowToDisk="true" timeToIdleSeconds="120" timeToLiveSeconds="120" diskExpiryThreadIntervalSeconds="120" memoryStoreEvictionPolicy="LRU"> defaultCache> ehcache>引入第三方框架或工具时,配置文件的文件名可以自定义吗?
- 可以自定义:文件名是由我告诉其他环境
- 不能自定义:文件名是框架内置的、约定好的,就不能自定义,以避免框架无法加载这个文件
-
指定缓存管理器的具体类型
还是到查询操作所的Mapper配置文件中,找到之前设置的cache标签:

<cache type="org.mybatis.caches.ehcache.EhcacheCache"/>
5.4.2.4.加入logback日志
存在SLF4J时,作为简易日志的log4j将失效,此时我们需要借助SLF4J的具体实现logback来打印日志。
-
各种Java日志框架简介
-
门面:
名称 说明 JCL(Jakarta Commons Logging) 陈旧 SLF4J(Simple Logging Facade for Java)★ 适合 jboss-logging 特殊专业领域使用 -
实现:
名称 说明 log4j★ 最初版 JUL(java.util.logging) JDK自带 log4j2 Apache收购log4j后全面重构,内部实现和log4j完全不同 logback★ 优雅、强大
注:标记★的技术是同一作者。
-
-
Logback配置文件

<configuration debug="true"> <appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"> <encoder> <pattern>[%d{HH:mm:ss.SSS}] [%-5level] [%thread] [%logger] [%msg]%npattern> encoder> appender> <root level="DEBUG"> <appender-ref ref="STDOUT"/> root> <logger name="com.atguigu.crowd.mapper" level="DEBUG"/> configuration>
5.4.2.5.Junit测试
正常按照二级缓存的方式测试即可。因为整合EHCache后,其实就是使用EHCache代替了Mybatis自带的二级缓存。
@Test
public void testSecondLevelCacheWork() {
SqlSession session = factory.openSession();
EmployeeMapper employeeMapper = session.getMapper(EmployeeMapper.class);
Integer empId = 1;
// 第一次查询
Emp emp01 = employeeMapper.selectEmpById(empId);
System.out.println("emp01 = " + emp01);
// 提交事务
session.commit();
// 关闭旧SqlSession
session.close();
// 开启新SqlSession
session = factory.openSession();
// 第二次查询
employeeMapper = session.getMapper(EmployeeMapper.class);
Emp emp02 = employeeMapper.selectEmpById(empId);
System.out.println("emp02 = " + emp02);
session.commit();
session.close();
session = factory.openSession();
employeeMapper = session.getMapper(EmployeeMapper.class);
employeeMapper.selectEmpById(empId);
session.commit();
session.close();
}

5.4.3.EHCache配置文件说明
当借助CacheManager.add(“缓存名称”)创建Cache时,EhCache便会采用
defaultCache标签各属性说明:
| 属性名 | 是否必须 | 作用 |
|---|---|---|
| maxElementsInMemory | 是 | 在内存中缓存的element的最大数目 |
| maxElementsOnDisk | 是 | 在磁盘上缓存的element的最大数目,若是0表示无穷大 |
| eternal | 是 | 设定缓存的elements是否永远不过期。 如果为true,则缓存的数据始终有效, 如果为false那么还要根据timeToIdleSeconds、timeToLiveSeconds判断 |
| overflowToDisk | 是 | 设定当内存缓存溢出的时候是否将过期的element缓存到磁盘上 |
| timeToIdleSeconds | 否 | 当缓存在EhCache中的数据前后两次访问的时间超过timeToIdleSeconds的属性取值时, 这些数据便会删除,默认值是0,也就是可闲置时间无穷大 |
| timeToLiveSeconds | 否 | 缓存element的有效生命期,默认是0.,也就是element存活时间无穷大 |
| diskSpoolBufferSizeMB | 否 | DiskStore(磁盘缓存)的缓存区大小。默认是30MB。每个Cache都应该有自己的一个缓冲区 |
| diskPersistent | 否 | 在VM重启的时候是否启用磁盘保存EhCache中的数据,默认是false。 |
| diskExpiryThreadIntervalSeconds | 否 | 磁盘缓存的清理线程运行间隔,默认是120秒。每个120s, 相应的线程会进行一次EhCache中数据的清理工作 |
| memoryStoreEvictionPolicy | 否 | 当内存缓存达到最大,有新的element加入的时候, 移除缓存中element的策略。 默认是LRU(最近最少使用),可选的有LFU(最不常使用)和FIFO(先进先出) |
5.5.缓存的基本原理
5.5.1.Cache接口
5.5.1.1.Cache接口的重要地位
org.apache.ibatis.cache.Cache接口:所有缓存都必须实现的顶级接口
org.apache.ibatis.cache.impl.PerpetualCache:mybatis一级缓存和二级缓存都需要的用到的类

5.5.1.2.Cache接口中的方法

缓存基本都是键值对结构,查询条件不同,去的值不同。根据Cache接口中方法的声明我们能够看到,缓存的本质是一个Map。
| 方法名 | 作用 |
|---|---|
| putObject() | 将对象存入缓存 |
| getObject() | 从缓存中取出对象 |
| removeObject() | 从缓存中删除对象 |
5.5.2.PerpetualCache

org.apache.ibatis.cache.impl.PerpetualCache是Mybatis的默认缓存,也是Cache接口的默认实现。Mybatis一级缓存和自带的二级缓存都是通过PerpetualCache来操作缓存数据的。但是这就奇怪了,同样是PerpetualCache这个类,怎么能区分出来两种不同级别的缓存呢?
其实很简单,调用者不同。
- 一级缓存:由BaseExecutor调用PerpetualCache
- 二级缓存:由CachingExecutor调用PerpetualCache,而CachingExecutor可以看做是对BaseExecutor的装饰
5.5.3.一级缓存机制

org.apache.ibatis.executor.BaseExecutor类中的关键方法:
BaseExecutor实现org.apache.ibatis.executor.Executor接口
5.5.3.1.query()方法
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
// 尝试从本地缓存中获取数据
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
// 如果本地缓存中没有查询到数据,则查询数据库
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (org.apache.ibatis.executor.BaseExecutor.DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
5.5.3.2.queryFromDatabase()方法
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
// 从数据库中查询数据
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
// 将数据存入本地缓存
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
5.5.4.二级缓存机制

5.5.4.1.未开启二级缓存

5.5.4.2.使用自带二级缓存

5.5.4.3.使用EHCache

6.逆向工程
6.1.概念与机制
6.1.1.概念
正向工程:先创建Java实体类,由框架负责根据实体类生成数据库表。Hibernate是支持正向工程的。
逆向工程:先创建数据库表,由框架负责根据数据库表,反向生成如下资源:
- Java实体类
- Mapper接口
- Mapper配置文件
6.1.2.基本原理

6.2.具体实现
6.2.1.配置POM
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>MyBatis-ProartifactId>
<groupId>org.stonebridgegroupId>
<version>1.0-SNAPSHOTversion>
parent>
<modelVersion>4.0.0modelVersion>
<artifactId>mybatis-MBGartifactId>
<properties>
<maven.compiler.source>8maven.compiler.source>
<maven.compiler.target>8maven.compiler.target>
properties>
<dependencies>
<dependency>
<groupId>org.mybatisgroupId>
<artifactId>mybatisartifactId>
<version>3.5.7version>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.mybatis.generatorgroupId>
<artifactId>mybatis-generator-maven-pluginartifactId>
<version>1.3.0version>
<dependencies>
<dependency>
<groupId>org.mybatis.generatorgroupId>
<artifactId>mybatis-generator-coreartifactId>
<version>1.3.2version>
dependency>
<dependency>
<groupId>com.mchangegroupId>
<artifactId>c3p0artifactId>
<version>0.9.2version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.8version>
dependency>
dependencies>
plugin>
plugins>
build>
project>
6.2.2.MBG配置文件
文件名必须是:generatorConfig.xml

注意数据库的链接信息和目录名称
DOCTYPE generatorConfiguration
PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN"
"http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd">
<generatorConfiguration>
<context id="DB2Tables" targetRuntime="MyBatis3">
<jdbcConnection driverClass="com.mysql.jdbc.Driver"
connectionURL="jdbc:mysql://localhost:3306/mybatis-example"
userId="root"
password="123456">
jdbcConnection>
<javaModelGenerator targetPackage="com.stonebridge.mybatis.entity" targetProject=".\src\main\java">
<property name="enableSubPackages" value="true"/>
<property name="trimStrings" value="true"/>
javaModelGenerator>
<sqlMapGenerator targetPackage="com.stonebridge.mybatis.mapper" targetProject=".\src\main\java">
<property name="enableSubPackages" value="true"/>
sqlMapGenerator>
<javaClientGenerator type="XMLMAPPER" targetPackage="com.stonebridge.mybatis.mapper"
targetProject=".\src\main\java">
<property name="enableSubPackages" value="true"/>
javaClientGenerator>
<table tableName="t_emp" domainObjectName="Employee"/>
<table tableName="t_customer" domainObjectName="Customer"/>
<table tableName="t_order" domainObjectName="Order"/>
context>
generatorConfiguration>
6.2.3.执行MBG插件的generate目标

6.2.4.生成效果

6.3.QBC查询
6.3.1.概念
QBC:Query By Criteria

QBC查询最大的特点就是将SQL语句中的WHERE子句进行了组件化的封装,让我们可以通过调用Criteria对象的方法自由的拼装查询条件。
6.3.2.示例
@Test
public void testQBC() {
// 目标:组装查询条件WHERE (xxx and xxx) or (xxx and xxx)
// 1.创建Example对象
EmployeeExample example = new EmployeeExample();
// 2.根据Example对象创建Criteria对象
EmployeeExample.Criteria criteria01 = example.createCriteria();
EmployeeExample.Criteria criteria02 = example.or();
// 3.在Criteria对象中添加查询条件
// ①emp_name like %o% and emp_salary > 6000.00
criteria01.andEmpNameLike("%o%").andEmpSalaryGreaterThan(6000.00);
// ②emp_name like %t% and emp_salary < 3000.00
criteria02.andEmpNameLike("%t%").andEmpSalaryLessThan(3000.00);
// 4.根据Example对象执行查询
EmployeeMapper employeeMapper = session.getMapper(EmployeeMapper.class);
List<Employee> employeeList = employeeMapper.selectByExample(example);
for (Employee employee : employeeList) {
System.out.println("employee = " + employee);
}
// 最终运行的结果:WHERE ( emp_name like %o% and emp_salary > 6000.00) or( emp_name like %t% and emp_salary < 3000.00 )
}
// 1.创建EmployeeExample对象
EmployeeExample example = new EmployeeExample();
// 2.通过example对象创建Criteria对象
EmployeeExample.Criteria criteria01 = example.createCriteria();
EmployeeExample.Criteria criteria02 = example.or();
// 3.在Criteria对象中封装查询条件
criteria01.andEmpAgeBetween(9, 99).andEmpNameLike("%o%").andEmpGenderEqualTo("male").andEmpSalaryGreaterThan(500.55);
criteria02.andEmpAgeBetween(9, 99).andEmpNameLike("%o%").andEmpGenderEqualTo("male").andEmpSalaryGreaterThan(500.55);
SqlSession session = factory.openSession();
EmployeeMapper mapper = session.getMapper(EmployeeMapper.class);
// 4.基于Criteria对象进行查询
List<Employee> employeeList = mapper.selectByExample(example);
for (Employee employee : employeeList) {
System.out.println("employee = " + employee);
}
session.close();
// 最终SQL的效果:
// WHERE ( emp_age between ? and ? and emp_name like ? and emp_gender = ? and emp_salary > ? ) or( emp_age between ? and ? and emp_name like ? and emp_gender = ? and emp_salary > ? )
7.其他
7.1.实体类类型别名
7.1.1.目标
让Mapper配置文件中使用的实体类类型名称更简洁。让Mapper配置文件中使用的实体类类型名称更简洁。
7.1.2.Mybatis全局配置文件
<typeAliases>
<package name="com.atguigu.mybatis.entity"/>
typeAliases>
7.1.3.Mapper配置文件
在Mapper文件中配置对应的resultType时就不需要,配置全限定名。只需要使用简单类名即可。
<select id="selectEmployeeById" resultType="Employee">
select emp_id,emp_name,emp_salary,emp_gender,emp_age from t_emp
where emp_id=#{empId}
select>
7.2.类型处理器
7.2.1.Mybatis内置类型处理器
无论是 MyBatis 在预处理语句(PreparedStatement)中设置一个参数时,还是从结果集中取出一个值时,都会用类型处理器将获取的值以合适的方式转换成 Java 类型。
| 类型处理器 | Java类型 | JDBC类型 |
|---|---|---|
| BooleanTypeHandler | Boolean,boolean | 任何兼容的布尔值 |
| ByteTypeHandler | Byte,byte | 任何兼容的数字或字节类型 |
| ShortTypeHandler | Short,short | 任何兼容的数字或短整型 |
| IntegerTypeHandler | Integer,int | 任何兼容的数字和整型 |
| LongTypeHandler | Long,long | 任何兼容的数字或长整型 |
| FloatTypeHandler | Float,float | 任何兼容的数字或单精度浮点型 |
| DoubleTypeHandler | Double,double | 任何兼容的数字或双精度浮点型 |
| BigDecimalTypeHandler | BigDecimal | 任何兼容的数字或十进制小数类型 |
| StringTypeHandler | String | CHAR和VARCHAR类型 |
| ClobTypeHandler | String | CLOB和LONGVARCHAR类型 |
| NStringTypeHandler | String | NVARCHAR和NCHAR类型 |
| NClobTypeHandler | String | NCLOB类型 |
| ByteArrayTypeHandler | byte[] | 任何兼容的字节流类型 |
| BlobTypeHandler | byte[] | BLOB和LONGVARBINARY类型 |
| DateTypeHandler | Date(java.util) | TIMESTAMP类型 |
| DateOnlyTypeHandler | Date(java.util) | DATE类型 |
| TimeOnlyTypeHandler | Date(java.util) | TIME类型 |
| SqlTimestampTypeHandler | Timestamp(java.sql) | TIMESTAMP类型 |
| SqlDateTypeHandler | Date(java.sql) | DATE类型 |
| SqlTimeTypeHandler | Time(java.sql) | TIME类型 |
| ObjectTypeHandler | 任意 | 其他或未指定类型 |
| EnumTypeHandler | Enumeration类型 | VARCHAR。任何兼容的字符串类型,作为代码存储(而不是索引) |
7.3.Mapper映射
Mybatis允许在指定Mapper映射文件时,只指定其所在的包:
<mappers>
<package name="com.atguigu.mybatis.dao"/>
mappers>
此时这个包下的所有Mapper配置文件将被自动加载、注册,比较方便。
但是,要求是:
- Mapper接口和Mapper配置文件名称一致
- Mapper配置文件放在Mapper接口所在的包内
如果工程是Maven工程,那么Mapper配置文件还是要放在resources目录下:

7.4.总结

- Mybatis环境所需依赖 ★
- 配置
- Mybatis全局配置
- Mapper配置 ★
- Mapper接口 ★
- API
- SqlSessionFactory
- SqlSession
- MBG ★
- 缓存
- 一级缓存
- 二级缓存
- 自带
- EHCache ☆
- 原理
- 把配置文件信息封装到Java对象中
- 缓存底层机制
- 四大接口
- Mybatis底层是JDBC
7.5.脑图脉络
7.5.1.MyBatis所需要的依赖

7.5.2.Mybatis全局配置

7.5.3.Mapper配置


7.5.4.mapper接口

7.5.5.逆向工程

7.5.6.缓存

7.5.7.原理
