和鲸社区数据分析每周挑战【第九十八期:企业贷款审批分析】
和鲸社区数据分析每周挑战【第九十八期:企业贷款审批分析】
文章目录
- 和鲸社区数据分析每周挑战【第九十八期:企业贷款审批分析】
-
- 一、背景描述
- 二、数据说明
- 三、问题描述
- 四、数据加载
- 五、数据清洗和预处理
- 六、数据探索与分析
-
- 1、贷款金额分布
- 2、各州的贷款数量分布
- 3、贷款批准日期分布
- 4、非营利组织和营利组织的贷款数量比较
- 5、各种银行的贷款数量分布
- 七、总结

一、背景描述
本数据集为美国PPP计划的贷款数据集,包含了贷款金额为15万美元及以上的贷款记录信息。
工资保障计划(PPP)
美国的Paycheck Protection Program法案是一项旨在帮助美国中小企业度过新冠疫情的经济援助计划。该法案额度为美国GDP的10%(约2-2.2万亿美元),3490亿美元面向500人以下中小企业,即PPP项目。
PPP全称为“Paycheck Protection Program”,即薪资保护项目。 它通过美国中小企业署SBA(Small Business Agency)贷款的形式来发放补助,而非以现金或拨款形式发放。 该法案旨在帮助企业留住员工,不至于他们被裁员,PPP的借款利率非常低,还款条件优惠。 如果公司保持员工数量以及工资水平,符合条件的企业可以免除部分或全部的利息和本金。
二、数据说明
| 字段 | 翻译 | 说明 |
|---|---|---|
| LoanRange | 贷款金额 | 获批准的贷款金额范围 |
| BusinessName | 公司名称 | |
| Address | 地址 | |
| City | 城市 | |
| State | 州 | |
| Zip | 邮政编码 | |
| NAICSCode | NAICS编号 | NAICS: 北美行业分类系统 |
| BusinessType | 企业类型 | |
| RaceEthnicity | 种族 | |
| Gender | 性别 | |
| Veteran | 退伍军人 | 申请者是否为退伍军人 |
| NonProfit | 非营利组织 | 是否是非营利组织 |
| JobsRetained | 保留岗位 | 有多少工作岗位获得了贷款批准 |
| DateApproved | 批准日期 | 贷款批准的日期 |
| Lender | 银行 | 贷款银行 |
| CD | CD | 企业对应国会选区 |
三、问题描述
- 中小企业贷款需求EDA
- 贷款获批企业数据分析
四、数据加载
import pandas as pd
data_path = "PPP_data_150k_plus.csv"
df = pd.read_csv(data_path)
df.head()
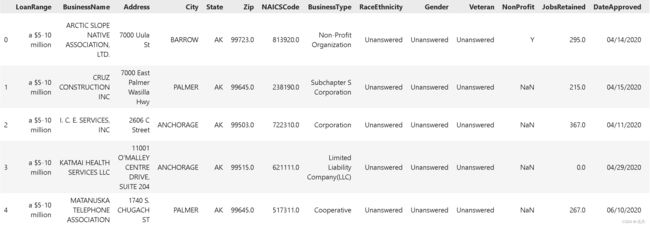
数据集包括以下字段:
LoanRange:获批准的贷款金额范围BusinessName:公司名称Address:地址City:城市State:州Zip:邮政编码NAICSCode:NAICS编号(北美行业分类系统)BusinessType:企业类型RaceEthnicity:种族Gender:性别Veteran:申请者是否为退伍军人NonProfit:是否是非营利组织JobsRetained:有多少工作岗位获得了贷款批准DateApproved:贷款批准的日期Lender:贷款银行CD:企业对应国会选区
接下来,我们将进一步探索这些数据。
五、数据清洗和预处理
在进行数据分析之前,我们需要先进行数据清洗和预处理,包括处理缺失值、错误值、异常值等,让我们先查看数据的概况。
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 661218 entries, 0 to 661217
Data columns (total 16 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 LoanRange 661218 non-null object
1 BusinessName 661210 non-null object
2 Address 661201 non-null object
3 City 661203 non-null object
4 State 661218 non-null object
5 Zip 661202 non-null float64
6 NAICSCode 654435 non-null float64
7 BusinessType 659789 non-null object
8 RaceEthnicity 661218 non-null object
9 Gender 661218 non-null object
10 Veteran 661218 non-null object
11 NonProfit 42462 non-null object
12 JobsRetained 620712 non-null float64
13 DateApproved 661218 non-null object
14 Lender 661218 non-null object
15 CD 661218 non-null object
dtypes: float64(3), object(13)
memory usage: 80.7+ MB
数据集中有661218条记录,16个字段。其中,有一些字段存在缺失值,比如 BusinessName、Address、City、Zip、NAICSCode、BusinessType 和 JobsRetained。特别是 NonProfit 字段,只有42462个非空值,这可能是因为只有非营利组织才在这个字段中填写了信息。
接下来我们需要决定如何处理这些缺失值。一种可能的策略是对于数值型字段(如 JobsRetained),我们可以使用平均值或中位数进行填充。对于类别型字段(如 BusinessType),我们可以选择使用最常见的类别进行填充。然而,对于 NonProfit 字段,由于缺失值过多,我们可能需要更深入地研究如何处理。
此外我们还需要注意到 DateApproved 字段目前是对象类型,为了后续的时间序列分析,我们需要将其转换为日期类型。
下面让我们先处理 DateApproved 字段,将其转换为日期类型,然后再处理其他的缺失值。
# 将 DateApproved 转换为日期类型
df['DateApproved'] = pd.to_datetime(df['DateApproved'])
# 使用中位数填充 JobsRetained 字段的缺失值
df['JobsRetained'] = df['JobsRetained'].fillna(df['JobsRetained'].median())
# 使用最常见的值填充 BusinessType 字段的缺失值
df['BusinessType'] = df['BusinessType'].fillna(df['BusinessType'].mode()[0])
# 将 NonProfit 字段的缺失值视为非非营利组织,填充为 'N'
df['NonProfit'] = df['NonProfit'].fillna('N')
# 检查处理后的数据
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 661218 entries, 0 to 661217
Data columns (total 16 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 LoanRange 661218 non-null object
1 BusinessName 661210 non-null object
2 Address 661201 non-null object
3 City 661203 non-null object
4 State 661218 non-null object
5 Zip 661202 non-null float64
6 NAICSCode 654435 non-null float64
7 BusinessType 661218 non-null object
8 RaceEthnicity 661218 non-null object
9 Gender 661218 non-null object
10 Veteran 661218 non-null object
11 NonProfit 661218 non-null object
12 JobsRetained 661218 non-null float64
13 DateApproved 661218 non-null datetime64[ns]
14 Lender 661218 non-null object
15 CD 661218 non-null object
dtypes: datetime64[ns](1), float64(3), object(12)
memory usage: 80.7+ MB
现在大部分字段的缺失值已经被填充。然而对于 BusinessName、Address、City、Zip 和 NAICSCode,这些字段缺失的数据相对较少,我们可以选择删除这些含有缺失值的记录,因为它们对整个数据集的影响较小。
我们将删除这些含有缺失值的记录,然后再次查看数据的概况。
# 删除含有缺失值的记录
df = df.dropna()
# 检查处理后的数据
df.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 654411 entries, 0 to 661209
Data columns (total 16 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 LoanRange 654411 non-null object
1 BusinessName 654411 non-null object
2 Address 654411 non-null object
3 City 654411 non-null object
4 State 654411 non-null object
5 Zip 654411 non-null float64
6 NAICSCode 654411 non-null float64
7 BusinessType 654411 non-null object
8 RaceEthnicity 654411 non-null object
9 Gender 654411 non-null object
10 Veteran 654411 non-null object
11 NonProfit 654411 non-null object
12 JobsRetained 654411 non-null float64
13 DateApproved 654411 non-null datetime64[ns]
14 Lender 654411 non-null object
15 CD 654411 non-null object
dtypes: datetime64[ns](1), float64(3), object(12)
memory usage: 84.9+ MB
现在数据集中的所有字段都不再包含缺失值。
六、数据探索与分析
1、贷款金额分布
首先让我们看一下贷款金额的分布情况。由于 LoanRange 字段给出的是贷款金额的范围,我们无法得到精确的贷款金额,但我们可以通过计数每个范围的数量来获取一些大致的信息。
import cufflinks as cf
# 设置cufflinks为离线模式
cf.go_offline()
# 设置主题
cf.set_config_file(theme='pearl')
# 贷款金额范围的计数
loan_range_counts = df['LoanRange'].value_counts()
loan_range_counts = loan_range_counts.sort_values(ascending=False)
loan_range_counts.iplot(kind='bar', title='贷款金额范围分布', color='blue', xTitle='贷款金额范围', yTitle='数量')
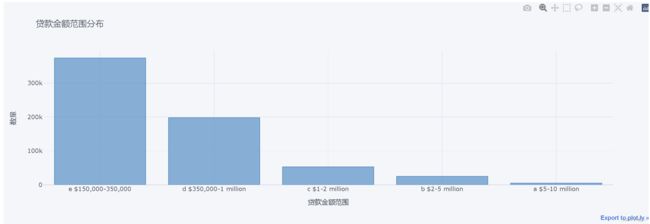
从上图可以看出,不同范围的贷款数量有显著的差异。具体来说,150,000-350,000美元的贷款数量最多,其次是350,000-1,000,000美元的贷款。这可能反映了大多数公司的贷款需求较小,只有少数公司需要较大的贷款。
2、各州的贷款数量分布
我们再来看一下各州的贷款数量分布,这可以帮助我们了解哪些州的公司更多地利用了PPP贷款。
# 各州的贷款数量
state_counts = df['State'].value_counts()
state_counts = state_counts.sort_values(ascending=False)
state_counts.iplot(kind='bar', title='各州的贷款数量分布', color='blue', xTitle='州', yTitle='数量')
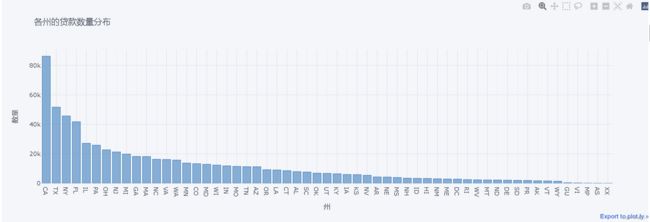
从上图可以看出,各州的贷款数量差异较大。具体来说,加利福尼亚州、德克萨斯州、纽约州的贷款数量最多。这可能与这些州的经济规模和企业数量有关。
3、贷款批准日期分布
我们再来看一下贷款批准日期的分布,这可以帮助我们了解贷款批准的时间趋势。我们将按月统计贷款批准的数量。
# 贷款批准日期分布
df['DateApproved'] = pd.to_datetime(df['DateApproved'])
df['YearMonth'] = df['DateApproved'].dt.to_period('M')
date_counts = df['YearMonth'].value_counts().sort_index()
date_counts.iplot(kind='line', title='贷款批准日期分布', color='blue', xTitle='年月', yTitle='数量')
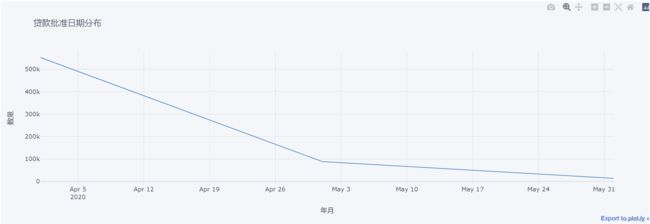
从上图可以看出,贷款批准的日期主要集中在2020年的4月和5月,这可能是因为PPP计划在2020年春季开始实施,许多公司在这个时期提交了贷款申请。
4、非营利组织和营利组织的贷款数量比较
我们再来看一下非营利组织和营利组织的贷款数量比较。这可以帮助我们了解这两类组织在利用PPP贷款方面的差异。
# 非营利组织和营利组织的贷款数量比较
nonprofit_counts = df['NonProfit'].value_counts()
nonprofit_counts = nonprofit_counts.sort_values(ascending=False)
nonprofit_counts.iplot(kind='bar', title='非营利组织和营利组织的贷款数量比较', color='blue', xTitle='是否为非营利组织', yTitle='数量')
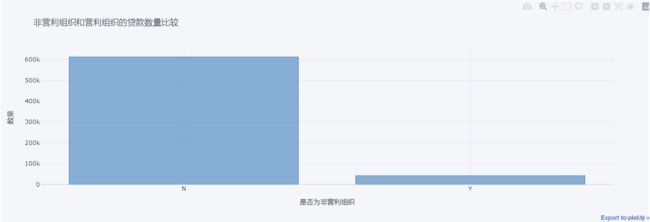
从上图可以看出,获得PPP贷款的大部分是营利组织,非营利组织的数量较少,这可能反映了PPP计划的主要目标是帮助营利组织,尤其是中小企业。
5、各种银行的贷款数量分布
最后让我们看一下各种银行的贷款数量分布。这可以帮助我们了解哪些银行在PPP计划中扮演了主要角色。由于银行数量可能较多,我们只查看贷款数量最多的前10个银行。
# 贷款数量最多的前10个银行
lender_counts = df['Lender'].value_counts()
lender_counts = lender_counts.sort_values(ascending=False)
lender_counts[:10].iplot(kind='bar', title='贷款数量最多的前10个银行', color='blue', xTitle='银行', yTitle='数量')
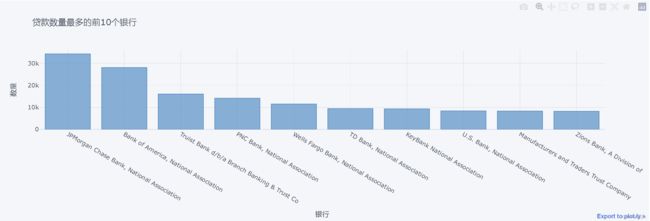
从上图可以看出,贷款数量最多的前10个银行中,JPMorgan Chase Bank和Bank of America等大型银行处于领先地位,这可能反映了这些大型银行在PPP计划中扮演了重要的角色。
七、总结
在这个项目中,我们对美国PPP计划的贷款数据集进行了一系列的探索和分析,我们查看了贷款金额、保留的工作岗位数量、各州的贷款数量、贷款批准日期、非营利组织和营利组织的贷款数量,以及各种银行的贷款数量等各个方面。
我们发现,大部分的贷款金额在150,000-350,000美元之间,贷款批准主要在2020年的4月和5月,贷款数量最多的是营利组织,以及JPMorgan Chase Bank和Bank of America等大型银行在贷款数量上处于领先地位。
这些发现可以帮助我们理解PPP计划的实施情况,以及哪些因素可能影响到贷款的批准和分配。这对于政策制定者和公司来说都有重要的参考价值。