【TensorFlow2.0】(7) 张量排序、填充、复制、限幅、坐标选择
各位同学好,今天和大家分享一下TensorFlow2.0中的一些操作。内容有:
(1)排序 tf.sort()、tf.argsort()、top_k();(2)填充 tf.pad();(3)复制 tf.tile();(4)限幅 tf.clip_by_value()、tf.maximum()、tf.nn.relu()、tf.clip_by_norm();(5)根据坐标选择 tf.where()
那我们开始吧。
1. 张量排序
1.1 tf.sort() 和 tf.argsort()
按升序或降序对张量进行排序,返回排序后的结果:
tf.sort(tensor, direction)
direction 指降序还是升序,默认升序排序。降序:direction='DESCENDING' ;升序:direction='ASCENDING'
按升序或降序对张量进行排序,返回索引:排序后的当前位置在原始位置中的索引:
tf.argsort(tensor, direction)
参数设置和tf.sort()相同
# 生成一维tensor,打乱顺序
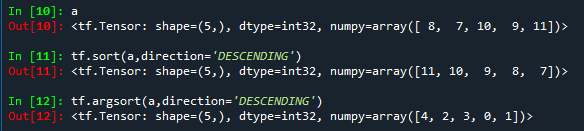
a = tf.random.shuffle(tf.constant([7,8,9,10,11]))
# 排序,返回值为降序排序的结果
tf.sort(a,direction='DESCENDING')
# 返回降序排序后的索引
tf.argsort(a,direction='DESCENDING')首先我们定义一个tensor为 [8, 7, 10, 9, 11],通过降序排序,返回结果为 [11,10,9,8,7],得到降序排序的索引为 [4,2,3,0,1]。返回结果11在原数据中的索引为4,返回结果10在原数据中索引位置为2,返回结果9在原数据中索引位置为3。
我们也可以通过返回的索引坐标利用tf.gather()函数来获取排序后的结果,idx中保存的是降序排序后的索引位置,gather函数针对给定的索引位置对tensor中的值进行搜集,返回降序排序好了的结果。
a = tf.random.shuffle(tf.constant([7,8,9,10,11]))
# 有了排序索引之后,我们可以通过索引来获取原tensor中的值
# idx保存降序后的值在原数据中的索引
idx = tf.argsort(a,direction='DESCENDING')
# 使用tf.gather()按照指定索引获取数据
tf.gather(a,idx)
我们看一下对于二维的tensor如何排序
# 创建一个3行3列每个元素在0-9之间的tensor
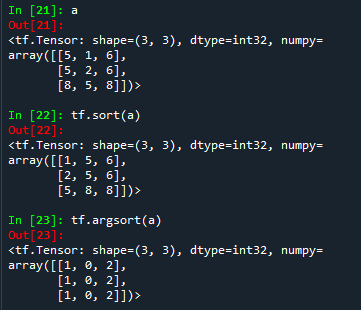
a = tf.random.uniform([3,3],maxval=10,dtype=tf.int32)
# 对a升序排序
tf.sort(a) # 返回排序后结果
tf.argsort(a) # 获取改变后的元素,在原位置的索引对最内层维度进行升序排序,每一行返回列排序结果
1.2 top_k()
tf.math.top_k(tensor, k)
sort()方法和argsort()方法都是对给定Tensor的所有元素排序,在某些情况下如果我们只是要获取排序的前几个元素,这时候可以使用top_k()方法,指定获取前k个元素。top_k()方法只能对最后一维进行排序
top_k()方法的返回值由两部分构成,一部分是获取的数据,另一部分是在原数据中的索引位置
# 创建3行3列的tensor,每个元素在0-9之间
a = tf.random.uniform([3,3],maxval=10,dtype=tf.int32)
# 返回前2个最大的值和索引
res = tf.math.top_k(a,2)
# 查看前两个最大的值
res.values
# 查看前两个最大值在原数据中的索引位置
res.indices以第一行为例,返回最大的两个数是 [9,3],9在原数据中的索引是1,而3在原数据中的索引为0。

2. 填充
tf.pad( tensor, paddings )
tensor指需要填充的张量,paddings指出要给tensor的哪个维度进行填充,以及填充方式,要注意的是paddings的rank必须和tensor的rank相同
# 生成0-8的tensor,重新塑形变成3行3列
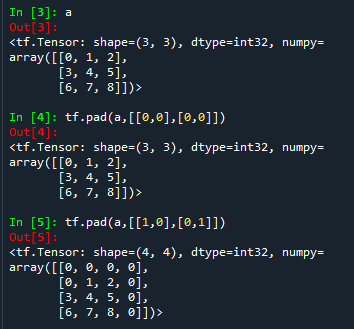
a = tf.reshape(tf.range(9),[3,3])
# 填充该tensor
# 行的上下都不填充,列的上下也不填充,不改变
tf.pad(a,[[0,0],[0,0]])
# 行的上边填充1行,下边不填充;列的左边不填充,右边填充一列
tf.pad(a,[[1,0],[0,1]])对于一个二维的tensor,tf.pad( a, [ [1,0], [0,1] ] ) 中的paddings的左边的括号代表第0个维度,即行维度,右边的括号代表第1个维度,即列维度。[1,0] 是指对行维度上的上侧填充一行,下侧不填充。[0,1] 是指对列维度上的左侧不填充,右侧填充一列。用0填充。
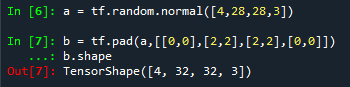
对于一个四维的tensor,shape为[4,28,28,3],即有4张图像,有28行28列,3个通道,对行列填充,shape变成[4,32,32,3]
# 4张图像28行28列3通道
a = tf.random.normal([4,28,28,3])
# 扩宽图像的行列,左右上下边都填充
b = tf.pad(a,[[0,0],[2,2],[2,2],[0,0]])
b.shape
第0个维度图像维度[0,0]不填充;第1个维度行维度[2,2],行的上侧和下侧都填充2行;第2个维度列维度[2,2],列维度的左右侧都填充2列;最后一个维度[0,0]不改变
3. 复制
tf.tile(input, multiples)
用于对张量进行扩张,将前面的数据进行复制然后直接接在原数据后面。input代表输入的tensor变量,multiples代表在同一个维度上复制的次数。
# 创建一个3行3列的tensor
a = tf.reshape(tf.range(9),[3,3])
# 1代表第一个维度复制的次数,2代表第二个维度复制的次数
tf.tile(a,[1,2])
# 第一个维度变成了原来的2倍,把原来的复制了2遍。第二个维度变成2倍
tf.tile(a,[2,2])
复制时先对小维度复制,再对大维度复制。tf.tile(a,[1,2])中,2代表新tensor的第二个维度(列维度) 是原tensor第二个维度的2倍。1代表新tensor的第一个维度(行维度) 是原tensor第一个维度的1倍,即,没有扩张第一个维度,只是把它一模一样复制过来。

4. 张量限幅
4.1 tf.clip_by_value()
tf.clip_by_value(tensor, min, max)
对tensor限幅,将一个张量的值限制在指定的最大值和最小值之间。
# 根据数值来限幅
a = tf.range(10)
# 把数据值限制在2-7之间,张量a中的值小于2的都返回2,大于7的都返回7
tf.clip_by_value(a,2,7)
变量a的值为[0,1,2,3,4,5,6,7,8,9],将a中的值限制在2到7之间,所有小于2的值都返回2,所有大于7的值都返回7。

4.2 tf.maximum() 和 tf.minimum()
tf.maximum(x, y) 指定下限,返回所有x>y的值,小于y的值变成y
tf.minimum(x, y) 指定上限,返回所有x
通过 tf.minimum(tf.maxmum(x, a), b) 把x的值限制在a到b之间
a = tf.range(10)
# 限制最小值为2
tf.maximum(a,2)
# 限制最大值为7
tf.minimum(a,7)
# 限制在两个区间内
tf.minimum(tf.maximum(a,2),7)

4.3 tf.nn.relu()
tf.nn.relu(tensor)
用于限制下限幅。输入小于0的值,幅值为0,输入大于0的值则不变
# 创建一个-5到4的一维tensor
a = tf.range(-5,5)
# 限制下限幅,小于0都返回是0
tf.nn.relu(a)
该方法相当于使用 tf.maximum(a,0) 来限制下限。
4.4 tf.clip_by_norm()
根据范数来限幅: tf.clip_by_norm(tensor, 指定范数大小)
对梯度进行裁剪,通过控制梯度的最大范数,防止梯度爆炸的问题
不改变tensor的方向,只改变tensor模的大小,使限幅后的数值的二范数为指定的范数值。计算方法是,将所有元素都乘上 指定范数/原范数。
# 根据范数来限幅
a = tf.constant([[1,2],[3,4]],dtype=tf.float32)
# 求tensor变量的二范数
tf.norm(a)
# 指定新的范数,使改变后的数值计算后得到这个新范数
a = tf.clip_by_norm(a,4)
# 计算二范数
tf.norm(a)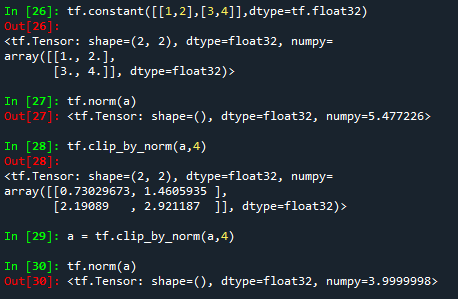
5. 根据坐标选择值
tf.where(condition, x, y)
condition 是一个tensor,是布尔类型的数据;如果x、y均为空,那么返回condition中的值为True的位置的Tensor;如果x、y均存在,那么如果condition为True,就选择x,condition为False,就选择y。
(1)使用tf.boolean_mask()获取元素
# 生成一个-4到4的tensor,变成3行3列
a = tf.reshape(tf.range(-4,5),[3,3])
# 与0比较,返回布尔类型的tensor,返回的shape和原来的shape相同
mask = a>0
# 获取元素对应位置是True的元素
tf.boolean_mask(a,mask)
mask = a>0,是指mask将tensor中元素大于0的元素返回True,否则返回False,返回值的shape和原tensor的shape一致。
使用tf.boolean_mask(),mask是指定位置的布尔索引,变量a和mask相互对应,函数返回mask中索引为True所对应变量a中的值。

(2)使用tf.where()记录元素坐标
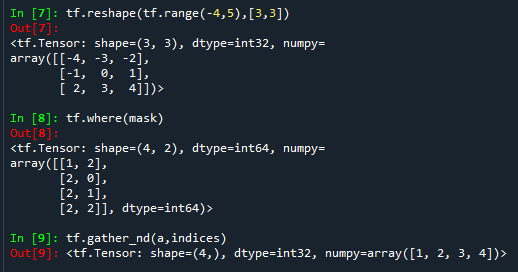
a = tf.reshape(tf.range(-4,5),[3,3])
# 使用where函数结合mask标记,返回所有为True元素的坐标,获取对应元素
mask = a>0
# 返回所有指定mask的坐标
indices = tf.where(mask)
# 通过indices指定的坐标来获取所要的值
tf.gather_nd(a,indices)indices存放的是所有mask为True的坐标,使用tf.gather_nd()方法通过坐标来获取tensor中的值。
(3)当where()中有两个tensor时
# 两个相同shape的tensor
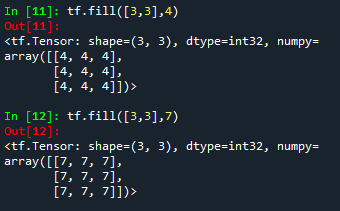
a = tf.fill([3,3],4)
b = tf.fill([3,3],7)
# 获取布尔索引,已经定义好了,如下图
mask
# 根据布尔索引筛选a和b中的值
tf.where(mask,a,b)mask中第一个值时False,返回值变量b中的第一个元素,mask中的值是True,对应位置就返回变量a中的元素