sparksql自定义数据源
sparksql自定义数据源

Spark SQL开放了一系列接入外部数据源的接口,来让开发者可以实现,接口在 org.apache.spark.sql.sources 包下:interfaces.scala 。
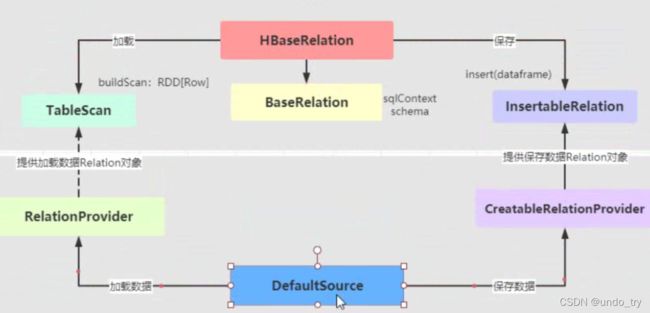
(1)DefaultSource
package com.yyds.tags.spark.hbase
import org.apache.spark.sql.{DataFrame, SQLContext, SaveMode}
import org.apache.spark.sql.sources.{BaseRelation, CreatableRelationProvider, DataSourceRegister, RelationProvider}
import org.apache.spark.sql.types.{StringType, StructField, StructType}
/**
* 默认数据源提供Relation对象,分别为加载数据和保存提供Relation对象
*/
class DefaultSource extends RelationProvider with CreatableRelationProvider with DataSourceRegister{
val SPERATOR: String = ","
val HBASE_TABLE_SELECT_FIELDS: String = "selectFields"
// 使用简称
override def shortName(): String = {
"hbase"
}
/**
* 返回BaseRelation实例对象,提供加载数据功能
* @param sqlContext SQLContext实例对象
* @param parameters 参数信息
* @return
*/
override def createRelation(
sqlContext: SQLContext,
parameters: Map[String, String]
): BaseRelation = {
// 1. 定义Schema信息
val schema: StructType = StructType(
parameters(HBASE_TABLE_SELECT_FIELDS)
.split(SPERATOR)
.map{
field => StructField(field, StringType, nullable = true)
})
// 2. 创建HBaseRelation对象
val relation = new HbaseRelation(sqlContext, parameters, schema)
// 3. 返回对象
relation
}
/*** 返回BaseRelation实例对象,提供保存数据功能
* @param sqlContext SQLContext实例对象
* @param mode 保存模式
* @param parameters 参数
* @param data 数据集
* @return
*/
override def createRelation(
sqlContext: SQLContext,
mode: SaveMode,
parameters: Map[String, String],
data: DataFrame
): BaseRelation = {
// 1. 创建HBaseRelation对象
val relation = new HbaseRelation(sqlContext, parameters, data.schema)
// 2.保存数据
relation.insert(data,true)
// 3.返回
relation
}
}
(2)HbaseRelation
package com.yyds.tags.spark.hbase
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.client.{Put, Result, Scan}
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.{TableInputFormat, TableOutputFormat}
import org.apache.hadoop.hbase.protobuf.ProtobufUtil
import org.apache.hadoop.hbase.util.{Base64, Bytes}
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row, SQLContext}
import org.apache.spark.sql.sources.{BaseRelation, InsertableRelation, TableScan}
import org.apache.spark.sql.types.StructType
/**
* 自定义 HBaseRelation 类,继承 BaseRelation 、 TableScan 和 InsertableRelation ,
* 此外实现序列化接口 Serializable ,所有类声明如下,其中实
* 现 Serializable 接口为了保证对象可以被序列化和反序列化。
*
* 自定义外部数据源:从HBase表加载数据和保存数据值HBase表
*/
case class HbaseRelation(context: SQLContext,
params: Map[String, String],
userSchema: StructType)
extends BaseRelation
with TableScan
with InsertableRelation
with Serializable {
// 连接HBase数据库的属性名称
val HBASE_ZK_QUORUM_KEY: String = "hbase.zookeeper.quorum"
val HBASE_ZK_QUORUM_VALUE: String = "zkHosts"
val HBASE_ZK_PORT_KEY: String = "hbase.zookeeper.property.clientPort"
val HBASE_ZK_PORT_VALUE: String = "zkPort"
val HBASE_TABLE: String = "hbaseTable"
val HBASE_TABLE_FAMILY: String = "family"
val SPERATOR: String = ","
val HBASE_TABLE_SELECT_FIELDS: String = "selectFields"
val HBASE_TABLE_ROWKEY_NAME: String = "rowKeyColumn"
/**
* sparksql 加载数据和保存程序入口,相当于spark session
* @return
*/
override def sqlContext: SQLContext = context
/**
* 在sparksql中数据封装在DataFrame或者DataSet中schema信息
* @return
*/
override def schema: StructType = userSchema
/**
* 从数据源中加载数据,封装在RDD中,每条数据在Row中,和schema信息,转换为DataFrame
* @return
*/
override def buildScan(): RDD[Row] = {
// 读取数据
/*def newAPIHadoopRDD[K, V, F <: NewInputFormat[K, V]](
conf: Configuration = hadoopConfiguration,
fClass: Class[F], kClass: Class[K], vClass: Class[V]
): RDD[(K, V)]
*/
// 1. 读取配置信息,加载HBaseClient配置(主要ZK地址和端口号)
val conf = HBaseConfiguration.create()
conf.set(HBASE_ZK_QUORUM_KEY, params(HBASE_ZK_QUORUM_VALUE))
conf.set(HBASE_ZK_PORT_KEY, params(HBASE_ZK_PORT_VALUE))
conf.set("zookeeper.znode.parent", "/hbase")
// 2. 设置表的名称
conf.set(TableInputFormat.INPUT_TABLE, params(HBASE_TABLE))
//设置读取列簇和列名称
val scan: Scan = new Scan()
scan.addFamily(Bytes.toBytes(params(HBASE_TABLE_FAMILY)))
val fields = params(HBASE_TABLE_SELECT_FIELDS)
.split(SPERATOR)
fields.foreach{
field => {
scan.addColumn(Bytes.toBytes(params(HBASE_TABLE_FAMILY)),Bytes.toBytes(field))
}
}
conf.set(TableInputFormat.SCAN,Base64.encodeBytes(ProtobufUtil.toScan(scan).toByteArray) )
// 3. 从HBase表加载数据
val hbaseRDD: RDD[(ImmutableBytesWritable, Result)] =
sqlContext.sparkContext.newAPIHadoopRDD(conf,
classOf[TableInputFormat],
classOf[ImmutableBytesWritable],
classOf[Result])
// 将RDD转换为Schema
// DataFrame = RDD[ROW] + Schema
val rowsRDD: RDD[Row] = hbaseRDD.map{
case (_,result) =>
// 基于列名称获取对应的值
val values: Seq[String] = fields.map{
field =>
val value: Array[Byte] = result.getValue(Bytes.toBytes(params(HBASE_TABLE_FAMILY)),Bytes.toBytes(field))
// 转换为字符串
Bytes.toString(value)
}
// 将序列转换为Row对象
Row.fromSeq(values)
}
// 返回
rowsRDD
}
/**
* 将DataFrame保存到数据源
* @param data 数据集
* @param overwrite 是否覆写
*/
override def insert(data: DataFrame, overwrite: Boolean): Unit = {
// 1. 设置HBase中Zookeeper集群信息
val conf: Configuration = new Configuration()
conf.set(HBASE_ZK_QUORUM_KEY, params(HBASE_ZK_QUORUM_VALUE))
conf.set(HBASE_ZK_PORT_KEY, params(HBASE_ZK_PORT_VALUE))
// 2. 设置读HBase表的名称
conf.set(TableOutputFormat.OUTPUT_TABLE, params(HBASE_TABLE))
// 3. 数据转换
val columns: Array[String] = data.columns
val putsRDD: RDD[(ImmutableBytesWritable, Put)] =
data.rdd.map { row =>
// 获取RowKey
val rowKey: String = row.getAs[String](params(HBASE_TABLE_ROWKEY_NAME))
// 构建Put对象
val put = new Put(Bytes.toBytes(rowKey))
// 将每列数据加入Put对象中
val familyBytes = Bytes.toBytes(params(HBASE_TABLE_FAMILY))
columns.foreach { column =>
put.addColumn(
familyBytes, //
Bytes.toBytes(column), //
Bytes.toBytes(row.getAs[String](column)) //
)
}
// 返回二元组
(new ImmutableBytesWritable(put.getRow), put)
}
// 4. 保存数据到表
putsRDD.saveAsNewAPIHadoopFile(
s"/apps/hbase/output-" + System.currentTimeMillis(),
classOf[ImmutableBytesWritable], //
classOf[Put], //
classOf[TableOutputFormat[ImmutableBytesWritable]], //
conf //
)
}
}
(3)注册数据源
所以在项目【 resources 】目录下创建库目录【 META-INF/services 】,并且创建文件
【 org.apache.spark.sql.sources.DataSourceRegister 】,内容为数据源主类

com.yyds.tags.spark.hbase.DefaultSource
(4)测试
package com.yyds.tags.hbase.read
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
/**
* 测试自定义外部数据源实现从HBase表读写数据接口
*/
object HBaseSQLTest {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[4]")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.getOrCreate()
// 读取数据
val usersDF: DataFrame = spark.read
.format("hbase")
.option("zkHosts", "192.168.42.7")
.option("zkPort", "2181")
.option("hbaseTable", "tbl_users")
.option("family", "detail")
.option("selectFields", "id,gender")
.load()
usersDF.printSchema()
usersDF.cache()
usersDF.show(10, truncate = false)
// 保存数据
usersDF.write
.mode(SaveMode.Overwrite)
.format("hbase")
.option("zkHosts", "192.168.42.7")
.option("zkPort", "2181")
.option("hbaseTable", "tbl_users")
.option("family", "info")
.option("rowKeyColumn", "id")
.save()
spark.stop()
}
}