Tip | Notepad++正则表达式替换
Notepad++ | 正则表达式替换
- 引言
- 正则化
-
- 入门
- 进阶(换行符)
- 再进阶(提取)
引言
我们在用各种文本编辑器,比如word、txt、vscode等时,有时候都会通过查找以及替换方便批操作。比如,去掉所有:符号,这些简单操作可以用于许多简单问题。但是对于更复杂的问题则比较难解决了,比如我想将所有[***]的[]去掉,留下***,而且不希望其他地方的[]被改动,这个时候就要用到正则化了。
Notepad++的替换操作支持正则表达式替换。结合正则化的背景也能完成一些基本操作,但是更复杂的时候就需要更多技巧了,这里列一下,放遗忘
P.S 这里默认掌握基本正则化知识,如有不懂,可以先去补充相关知识,比如菜鸟教程,欢迎提问~
正则化
Ctrl + H进入替换界面

入门
以该数据为例:
‘Albania’: 2878549,
‘Austria’: 8857960,
‘Belgium’: 11449656,
‘Bosnia & Herzegovina’: 3511372,
‘Bulgaria’: 7000039,
‘Croatia’: 4105493,
‘Czechia’: 10627794,
‘Denmark’: 5837213,
‘Estonia’: 1328976,
‘Hungary’: 9771000
比如我想去除所有数字:
F: \d+
L:
效果:

如果想把后面的,也去掉,注意最后一行没有,
F: [\d,]+
L:
同理,想去掉数字前面的那一串:
F: '[\S ]+':
L:

进阶(换行符)
介绍下换行符,制表符这些操作,notepad++的换行符不太一样,是\r\n,值得注意。
比如我们想将这些都放在一行,即去掉换行符:
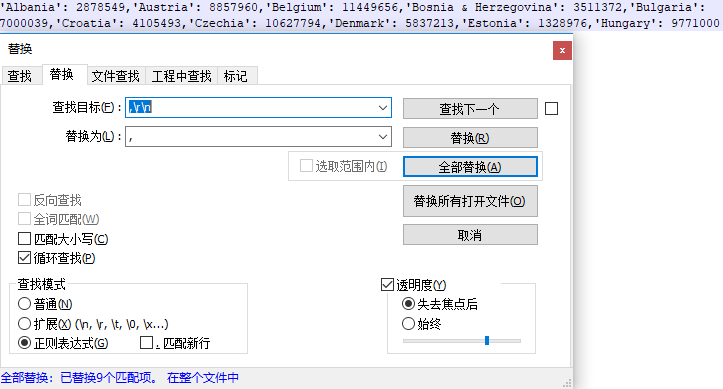
F: ,\r\n
L: ,
效果如下
 再来一个,比如我们不想让这个空行:
再来一个,比如我们不想让这个空行:
Albania
Austria
Belarus
Belgium
Bosnia and Herzegovina
Bulgaria
Croatia
F: \r\n\r\n
L: \r\n
效果如下:

再进阶(提取)
上面这些可以满足一定量的需求,但是可以发现它的功能都集中在找到某个模块,然后剔除,或者替换成某个固定模块。
当我想找到某个模块,然后想对里面进行某些操作,就需要进一步技巧了。
还是第一个例子:
‘Albania’: 2878549,
‘Austria’: 8857960,
‘Belgium’: 11449656,
‘Bosnia & Herzegovina’: 3511372,
‘Bulgaria’: 7000039,
‘Croatia’: 4105493,
‘Czechia’: 10627794,
‘Denmark’: 5837213,
‘Estonia’: 1328976,
‘Hungary’: 9771000
我们想去掉所有符号,保留符号里的字母和文字
当然我们可以:
F: ['']
L:
我们也可以找到'***'这块,然后提取,这在很多数据清理中有着很大的作用:
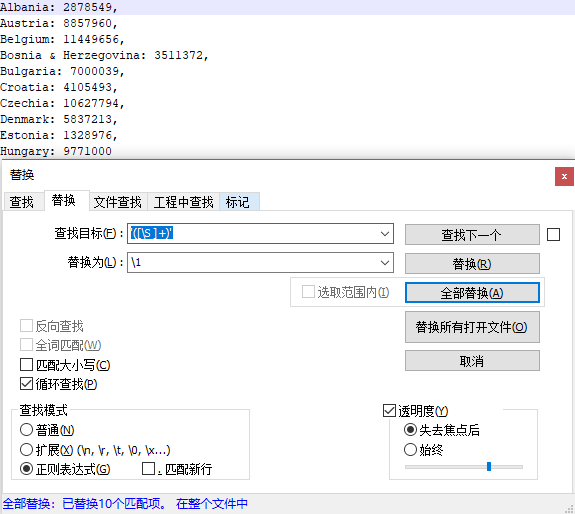
F: '([\S ]+)'
L: \1 或者$1
其中,()里的内容表示要提取的,\1 或者$1表示目标中第一个圆括号匹配的内容。该方法特别适合处理大量数据,包括文件名,数字字母混杂数据等。
效果如下:
如果有多个()就\1,\2类推~
比如我们只想保留字母和数字
剔除其他方法:
F: ['':,]
L:
提取方法:
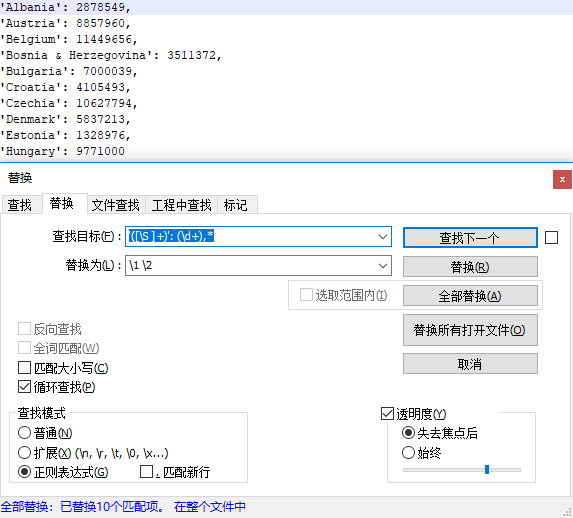
F: '([\S ]+)': (\d+),*
L: \1 \2
这个学会了,用多还是挺方便好玩的~