深入学习 Redis - 全局命令、过期策略如何实现、高效定时器原理
目录
Redis 基础命令
get 和 set
Redis 全局命令
keys
keys 使用注意事项
exists
exists 使用注意事项
del
del 使用注意事项
expire
【面试经典】redis 中 key 的过期策略是怎么实现的?
定时器实现原理(非 Redis 实现,拓展)
1.基于 优先级队列/堆 实现
2.基于 时间轮 实现定时器
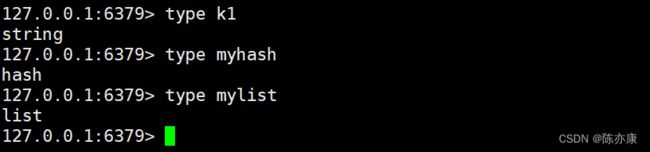
type
Redis 基础命令
get 和 set

get 是根据 key 来取 value ,若 key 不存在,则返回 nil (nil 和 null 是一个意思)
set 把 key 和 value 存储进去
其中, key 和 value 都是字符串
Ps:key 和 value 都不需要加上引号,就是表示字符串类型,当然,如果要给 key 和 value 加上引号也是可以的(单双引号都可以)
Redis 全局命令
Redis 是支持很多种数据结构的,整体上来说, Redis 是键值对结构, key 固定就是字符串,value 是会有很多类型的,例如 字符串、哈希表、列表、集合、有序集合... 这里每一个数据结构的操作都会用到不同的命令~
全局命令就是能够搭配任意一个数据结构来使用的命令
keys
用来查询当前服务器上匹配的 key,并且可以通过一些特殊号(通配符)来描述 key 的模样,匹配这个模样的 key 就可以被查询出来~
keys patternpattern 具体怎么写呢,往下看~
1)? 匹配任意一个字符
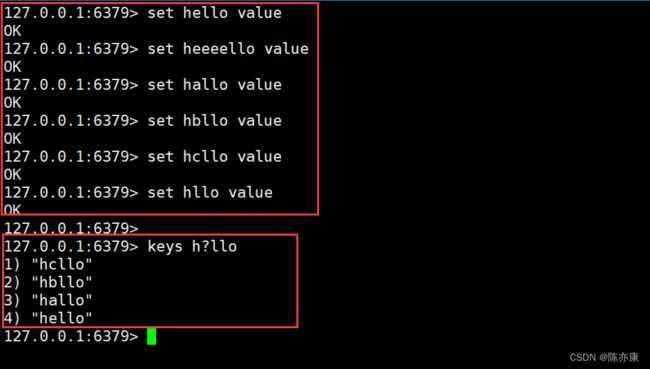
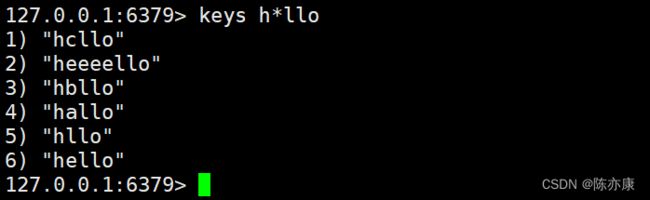
2)* 匹配 0 个或 多个 任意字符
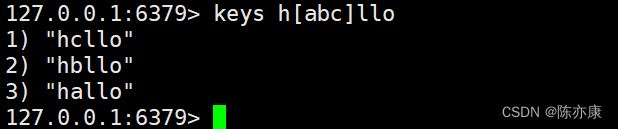
3)[abcde] 只能匹配到 a b c d e ,(他们之间是 "或" 的关系)别的不行
4)[^e] 排除 e ,只有 e 匹配不了,其他的都可以匹配

Ps:注意这里 a 或 e 都不能出现
5)[a-e] 匹配 a ~ e 这个范围内的字符,(他们之间是 "或" 的关系)包含两侧边界

keys 使用注意事项
keys 命令时间复杂度为 O(N) ,在生产环境上的 key 可能会非常多,因此一般都会禁止使用 keys 命令,尤其是 keys *,这个命令就是来查询 redis 中所有的 key,执行后可能会带来以下两种严重的后果:
- 因为 redis 是一个单线程的服务器,执行 keys * 时间过长,可能会导致无法给其他客户端提供服务!
- redis 经常作为缓存挡在 mysql 前面,一旦 redis 被一个 keys * 阻塞住了,此时其他查询 redis 的命令超时了,此时这些请求就会直接去查询数据库,而 mysql 措手不及,就很容易挂掉,如果你要是没有能够及时发现和修复,可能会导致这个服务宕机,年终奖妥妥的就没了~
举个例子,假如我是一个妹子,长得好看又有才华,追求者又多,因此我的要求就会很高,如以下三点:
- 有钱
- 帅
- 会舔(不是你想象中的,是会哄人开心)
然后我同时交往了三个 男朋友,他们分别当不全具有以上优点:
- 男朋友 A ,有钱
- 男朋友 B ,帅
- 男朋友 C ,会舔
万一 C 对我纠缠不休,就有可能导致我对其他男朋友就照顾不周,难以应付 AB
exists
exists 用来判定 key 是否存在.
exists key [key ...]返回值:key 存在的个数(对于多个 key 来说,是非常有用的)。
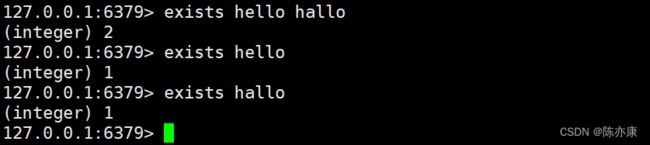
Ps:exists 使用的时间复杂度是 O(1),因为 redis 组织这些 key 就是按照 哈希表 的方式来组织的.
exists 使用注意事项
"exists hello hallo" 和 "exists hello" "exists hallo" 这两种写法有什么区别?
最好写在一起,因为分开的写法会产生更多的轮次的网络通信.
redis 是一个客户端 服务器结构的程序,客户端和服务器之间是需要通过网络来进行通信的!!!
也就是说需要经过一个封装和分用的过程,网络通信时,发送方发送数据后,这个数据就要从应用层到物理层,层层封装,中途还需要经过交换机和路由器进行转发,最后接收方接收到数据,这个数据就要从 物理层到应用层,层层分用,更何况,如果你的客户端和服务器不在一个主机上,中间隔的很远~
redis 自身也很清除这个问题,因此很多命令都是支持一次就能操作多个 key 的.
del
del(delete)删除指定的 key,可以一次删除一个或多个.
del key [key ...]操作的时间复杂度为 O(1).
返回值:删除掉的 key 的个数.
del 使用注意事项
不小心使用 del 删除 redis 某个数据,影响大吗?
redis 主要是作为缓存,因此 redis 只是用来存储热点数据,全量数据在 mysql 数据库中,此时,如果把 redis 种的 key 删除了几个,一般来说,问题不大~(这是相比较 mysql 误删一两个数据而言的!!!)
但是如果把所有的数据或者一大半的数据都删除了,这种影响会很大,因为 redis 本来就是帮 mysql 负重前行,redis 没数据了,大部分请求就会直接打给 mysql ,就容易把 mysql 搞挂.
如果是把 redis 作为数据库,误删的影响就大了~
如果是把 redis 作为消息队列,这种情况影响大不大,就需要具体问题具体分析了~
归根结底,还是不要乱删数据.
expire
expire 的作用是给指定的 key 设置过期时间,单位是秒, 但是对于计算机来说,秒是一个很长的时间,因此也可以使用 pexpire ,这是毫秒级别的,超过这个时间的值,就会被自动删除.
expire key seconds时间复杂度:O(1).
设置成功返回 1,失败返回 0.
Ps:基于 redis 实现的分布式锁,就是为了避免出现不能正常解锁的情况,通常都会在加锁的时候设置一下过期时间(所谓的 redis 分布式锁,就是给 redis 里写了一个特殊的 key value).
expire 通常会搭配 ttl(time to live) 来使用,可以查看当前 key 的过期时间还剩多少,如果是秒级别,就使用pttl.
当 key 不存在时,返回 -2 。 当 key 存在但没有设置剩余生存时间时,返回 -1 。 否则,以秒为单位,返回 key 的剩余生存时间。
注意:在 Redis 2.8 以前,当 key 不存在,或者 key 没有设置剩余生存时间时,命令都返回 -1 。
Ps:网络原理的 IP 协议报头中,就有一个字段是 TTL,IP 中的 TTL 不是用时间衡量的,而是次数.
【面试经典】redis 中 key 的过期策略是怎么实现的?
问题:一个 redis 中可能同时存在很多很多 key,并且有很大一部分 key 都是有过期时间的,此时 redis 怎么知道哪些 key 已经过期要被删除了,哪些还没过期?
如果直接遍历所有的 key ,显然是行不通的,效率很低,因此 redis 整体的策略有如下两点:
- 定期删除:每次抽取一部分,进行过期时间的验证,并且要保证这个抽取检查的过程足够快,为什么要要求足够快呢(对定期删除时间有明确规定)? 因为 redis 是单线程的程序,主要任务是处理每一个命令任务,扫描过期的 key,如果扫描过期的 key 小号的时间太多了,就可能导致正常处理请求的命令阻塞了(类似于 keys * 这样的效果)。
- 惰性删除:假设这个 key 已经到过期时间了,但暂时不会删除他,如果后面再一次访问到这个 key ,就会让 redis 服务器触发删除 key 的操作,同时再返回一个 nil 。
Ps:网上经常有种错误的说法:" redis 中采用定时器的方式来实现过期 key 删除",实际上是没有的,这也很难考证,个人猜测是:"基于定时器实现,势必就要引入多线程了(基于优先级队列或者时间轮实现),而 redis 早期版本就是奠定了点线程的基调,多线程的引入就打破了作者的初衷~"
定时器实现原理(非 Redis 实现,拓展)
Ps:虽然早期 redis 并没有使用定时器来删除过期 key,但是如果面试的时候问道我们如何拓展 redis 动态链接库实现一个定时器相关的问题时,我也要能灵活应对~
定时器,就是在某个时间到达之后,执行指定的任务,高效的实现方法有以下两种:
1.基于 优先级队列/堆 实现
在优先级队列中,优先级高的先出队,而这个优先级是由我们自定义的~ 因此对于 redis 过期的 key 使用场景中,我们就可以通过 “过期时间越早,优先级越高” 的方式来删除过期 key.
具体做法如下:
假设有很多 key 设置了过期时间,就可以把 key 加入到优先级队列中,自定义优先级规则时过期时间早的先出队,此时队首元素就是最早要过期的 key,假设有以下 key :
- key1 : 12:00 过期
- key2 : 13:00 过期
- key3 : 14:00 过期
那么只需要创建一个线程,让这个线程不断的去检查队首元素是否过期,若队首元素没有过期,那么后续的元素一定没有过期,值得注意的是,扫描线程检查队首元素过期时间时,也不能过于频繁,最佳做法就是根据当时时刻和队首元素的过期时间,设置一个等待时间,当时间差不多的时候,系统再来唤醒这个线程,这样就很好的把 cpu 资源节省下来了~
若线程休眠的时候又来了一个新的任务,那么此时就可以唤醒以下线程,重新检查以下队首元素的阻塞时间.
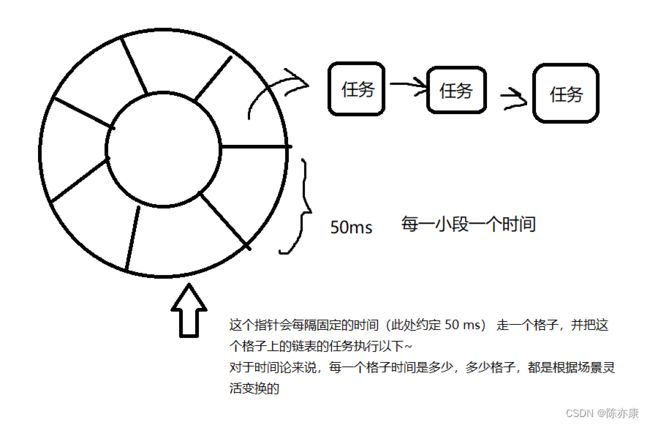
2.基于 时间轮 实现定时器
时间轮,就是把时间划分成很多小段,每一个小段上都挂着一个链表,链表的每一个结点都代表一个要执行的任务,如下图
type
返回 key 对应的 value 的数据类型. 此处因为 redis 中所有的 key 都是 string 类型,而 key 对应的 value 可能存在很多类型,如 none、string、list、set、zset、hash、stream(消息队列).
操作的时间复杂度为 O(1).