自回归模型--PixelCNN
PixclCNN一次生成一个像素,并使用该像素生成下一个像素,然后使用前两个像素生成第三个像素。在 PixelCNN中,有一个概率密度模型,该模型可以学习所有图像的密度分布并根据该分布生成图像。也试图通过使用之前所有预测的联合概率来限制在所有先前生成的像素的基础上生成的每个像素。
假设图像被遮挡住一般,那PixelCNN需要生成剩下的一半图像,这是通过掩膜卷积进行的。
下图展示了如何对像素集应用卷积运算来预测中心像素。与其他模型相比,自回归模型的主要优点是:联合概率学习技术易于处理,并且可以用梯度下降法进行学习。这里没有近似计算,只是尝试在给定所有先前像素值的情况下预测每个像素值,并且训练过程完全由反向传播来支持。但是,由于生成始终是按顺序进行的,所以无法使用自回归模型来扩展。PixelCNN是一个结构良好的模可以将单个概率的乘积作为所有先前像素的联合概率,同时生成新像素。
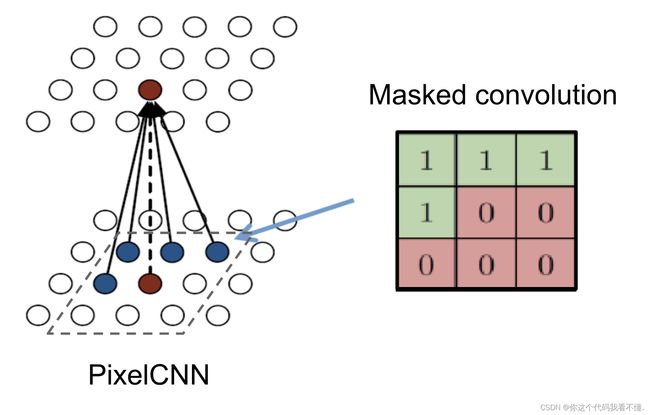
PixelCNN捕获参数中像素之间的依存关系分布,这与其他方法不同。VAE通过生成隐藏的隐向量来学习此分布,它引入了独立的假设。在 PixelCNN中,不仅学习先前像素之间的依赖关系,还学习不同通道之间的依赖关系(在标准的彩色图像中,通道指红、绿和蓝(RGB))。
原论文实现了两种方式的掩膜。A 和 B.A 型掩膜卷积只能看到以前生成的像素,而 B 型允许考虑预测像素的值。在A掩膜之后应用B掩膜卷积可以保留因果关系并解决它。在 3 个数据通道的情况下,此图像上描绘了掩码的类型:

使得 PixelCNN在与其他传统CNN模型的比较中脱颖而出的主要架构差异之一是其缺少池化层。由于PixelCNN的目的不是以缩小尺寸的形式捕获图像的本质,而且其不能承担通过池化而丢失上下文的风险,所以其作者故意删除了池化层。
下面说明下代码:
(1)train.py
import torch
import torch.optim as optim
import torch.nn.functional as F
from torch.nn.utils import clip_grad_norm_
import numpy as np
import argparse
import os
from utils import str2bool, save_samples, get_loaders
from tqdm import tqdm
import wandb
from pixelcnn import PixelCNN
TRAIN_DATASET_ROOT = '.data/train/'
TEST_DATASET_ROOT = '.data/test/'
MODEL_PARAMS_OUTPUT_DIR = 'model'
MODEL_PARAMS_OUTPUT_FILENAME = 'params.pth'
TRAIN_SAMPLES_DIR = 'train_samples'
def train(cfg, model, device, train_loader, optimizer, scheduler, epoch):
model.train()
for images, labels in tqdm(train_loader, desc='Epoch {}/{}'.format(epoch + 1, cfg.epochs)):
optimizer.zero_grad()
images = images.to(device, non_blocking=True)
labels = labels.to(device, non_blocking=True)
normalized_images = images.float() / (cfg.color_levels - 1)
outputs = model(normalized_images, labels)
loss = F.cross_entropy(outputs, images)
loss.backward()
clip_grad_norm_(model.parameters(), max_norm=cfg.max_norm)
optimizer.step()
scheduler.step()
def test_and_sample(cfg, model, device, test_loader, height, width, losses, params, epoch):
test_loss = 0
model.eval()
with torch.no_grad():
for images, labels in test_loader:
images = images.to(device, non_blocking=True)
labels = labels.to(device, non_blocking=True)
normalized_images = images.float() / (cfg.color_levels - 1)
outputs = model(normalized_images, labels)
test_loss += F.cross_entropy(outputs, images, reduction='none')
test_loss = test_loss.mean().cpu() / len(test_loader.dataset)
wandb.log({
"Test loss": test_loss
})
print("Average test loss: {}".format(test_loss))
losses.append(test_loss)
params.append(model.state_dict())
samples = model.sample((3, height, width), cfg.epoch_samples, device=device)
save_samples(samples, TRAIN_SAMPLES_DIR, 'epoch{}_samples.png'.format(epoch + 1))
def main():
parser = argparse.ArgumentParser(description='PixelCNN')
parser.add_argument('--epochs', type=int, default=25,
help='Number of epochs to train model for')
parser.add_argument('--batch-size', type=int, default=32,
help='Number of images per mini-batch')
parser.add_argument('--dataset', type=str, default='mnist',
help='Dataset to train model on. Either mnist, fashionmnist or cifar.')
parser.add_argument('--causal-ksize', type=int, default=7,
help='Kernel size of causal convolution')
parser.add_argument('--hidden-ksize', type=int, default=7,
help='Kernel size of hidden layers convolutions')
parser.add_argument('--color-levels', type=int, default=2,
help='Number of levels to quantisize value of each channel of each pixel into')
parser.add_argument('--hidden-fmaps', type=int, default=30,
help='Number of feature maps in hidden layer (must be divisible by 3)')
parser.add_argument('--out-hidden-fmaps', type=int, default=10,
help='Number of feature maps in outer hidden layer')
parser.add_argument('--hidden-layers', type=int, default=6,
help='Number of layers of gated convolutions with mask of type "B"')
parser.add_argument('--learning-rate', '--lr', type=float, default=0.0001,
help='Learning rate of optimizer')
parser.add_argument('--weight-decay', type=float, default=0.0001,
help='Weight decay rate of optimizer')
parser.add_argument('--max-norm', type=float, default=1.,
help='Max norm of the gradients after clipping')
parser.add_argument('--epoch-samples', type=int, default=25,
help='Number of images to sample each epoch')
parser.add_argument('--cuda', type=str2bool, default=True,
help='Flag indicating whether CUDA should be used')
cfg = parser.parse_args()
wandb.init(project="PixelCNN")
wandb.config.update(cfg)
torch.manual_seed(42)
EPOCHS = cfg.epochs
model = PixelCNN(cfg=cfg)
device = torch.device("cuda" if torch.cuda.is_available() and cfg.cuda else "cpu")
model.to(device)
train_loader, test_loader, HEIGHT, WIDTH = get_loaders(cfg.dataset, cfg.batch_size, cfg.color_levels, TRAIN_DATASET_ROOT, TEST_DATASET_ROOT)
optimizer = optim.Adam(model.parameters(), lr=cfg.learning_rate, weight_decay=cfg.weight_decay)
scheduler = optim.lr_scheduler.CyclicLR(optimizer, cfg.learning_rate, 10*cfg.learning_rate, cycle_momentum=False)
wandb.watch(model)
losses = []
params = []
for epoch in range(EPOCHS):
train(cfg, model, device, train_loader, optimizer, scheduler, epoch)
test_and_sample(cfg, model, device, test_loader, HEIGHT, WIDTH, losses, params, epoch)
print('\nBest test loss: {}'.format(np.amin(np.array(losses))))
print('Best epoch: {}'.format(np.argmin(np.array(losses)) + 1))
best_params = params[np.argmin(np.array(losses))]
if not os.path.exists(MODEL_PARAMS_OUTPUT_DIR):
os.mkdir(MODEL_PARAMS_OUTPUT_DIR)
MODEL_PARAMS_OUTPUT_FILENAME = '{}_cks{}hks{}cl{}hfm{}ohfm{}hl{}_params.pth'\
.format(cfg.dataset, cfg.causal_ksize, cfg.hidden_ksize, cfg.color_levels, cfg.hidden_fmaps, cfg.out_hidden_fmaps, cfg.hidden_layers)
torch.save(best_params, os.path.join(MODEL_PARAMS_OUTPUT_DIR, MODEL_PARAMS_OUTPUT_FILENAME))
if __name__ == '__main__':
main()
(2)sample.py
import torch
from pixelcnn import PixelCNN
import argparse
from utils import str2bool, save_samples
OUTPUT_DIRNAME = 'samples'
def main():
parser = argparse.ArgumentParser(description='PixelCNN')
parser.add_argument('--causal-ksize', type=int, default=7,
help='Kernel size of causal convolution')
parser.add_argument('--hidden-ksize', type=int, default=7,
help='Kernel size of hidden layers convolutions')
parser.add_argument('--color-levels', type=int, default=2,
help='Number of levels to quantisize value of each channel of each pixel into')
parser.add_argument('--hidden-fmaps', type=int, default=30,
help='Number of feature maps in hidden layer')
parser.add_argument('--out-hidden-fmaps', type=int, default=10,
help='Number of feature maps in outer hidden layer')
parser.add_argument('--hidden-layers', type=int, default=6,
help='Number of layers of gated convolutions with mask of type "B"')
parser.add_argument('--cuda', type=str2bool, default=True,
help='Flag indicating whether CUDA should be used')
parser.add_argument('--model-path', '-m',
help="Path to model's saved parameters")
parser.add_argument('--output-fname', type=str, default='samples.png',
help='Name of output file (.png format)')
parser.add_argument('--label', '--l', type=int, default=-1,
help='Label of sampled images. -1 indicates random labels.')
parser.add_argument('--count', '-c', type=int, default=64,
help='Number of images to generate')
parser.add_argument('--height', type=int, default=28, help='Output image height')
parser.add_argument('--width', type=int, default=28, help='Output image width')
cfg = parser.parse_args()
OUTPUT_FILENAME = cfg.output_fname
model = PixelCNN(cfg=cfg)
model.eval()
device = torch.device("cuda" if torch.cuda.is_available() and cfg.cuda else "cpu")
model.to(device)
model.load_state_dict(torch.load(cfg.model_path))
label = None if cfg.label == -1 else cfg.label
samples = model.sample((3, cfg.height, cfg.width), cfg.count, label=label, device=device)
save_samples(samples, OUTPUT_DIRNAME, OUTPUT_FILENAME)
if __name__ == '__main__':
main()
(3) utils.py
import numpy as np
import argparse
import os
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
def quantisize(image, levels):
return np.digitize(image, np.arange(levels) / levels) - 1
def str2bool(s):
if isinstance(s, bool):
return s
if s.lower() in ('yes', 'true', 't', 'y', '1'):
return True
elif s.lower() in ('no', 'false', 'f', 'n', '0'):
return False
else:
raise argparse.ArgumentTypeError('Boolean value expected')
def nearest_square(num):
return round(np.sqrt(num))**2
def save_samples(samples, dirname, filename):
if not os.path.exists(dirname):
os.mkdir(dirname)
count = samples.size()[0]
count_sqrt = int(count ** 0.5)
if count_sqrt ** 2 == count:
nrow = count_sqrt
else:
nrow = count
save_image(samples, os.path.join(dirname, filename), nrow=nrow)
def get_loaders(dataset_name, batch_size, color_levels, train_root, test_root):
normalize = transforms.Lambda(lambda image: np.array(image) / 255)
discretize = transforms.Compose([
transforms.Lambda(lambda image: quantisize(image, color_levels)),
transforms.ToTensor()
])
to_rgb = transforms.Compose([
discretize,
transforms.Lambda(lambda image_tensor: image_tensor.repeat(3, 1, 1))
])
dataset_mappings = {'mnist': 'MNIST', 'fashionmnist': 'FashionMNIST', 'cifar': 'CIFAR10'}
transform_mappings = {'mnist': to_rgb, 'fashionmnist': to_rgb, 'cifar': transforms.Compose([normalize, discretize])}
hw_mappings = {'mnist': (28, 28), 'fashionmnist': (28, 28), 'cifar': (32, 32)}
try:
dataset = dataset_mappings[dataset_name]
transform = transform_mappings[dataset_name]
train_dataset = getattr(datasets, dataset)(root=train_root, train=True, download=True, transform=transform)
test_dataset = getattr(datasets, dataset)(root=test_root, train=False, download=True, transform=transform)
h, w = hw_mappings[dataset_name]
except KeyError:
raise AttributeError("Unsupported dataset")
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, pin_memory=True, drop_last=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, pin_memory=True, drop_last=True)
return train_loader, test_loader, h, w
生成的效果:
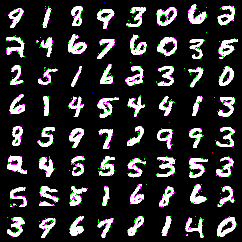
效果其实一般,有更复杂的模型可以去训练和改进。