【TiDB理论知识 05】TiKV-Raft协议
目录
一 概念
二 raft共识算法对于TiKV的几个重要功能
1 Raft日志复制
1 Raft日志复制流程
2 名词解释
分层次理解TIKV
2 Raft Leader选举
集群初始状态时Leader选举流程
数据正在复制时Leader选举流程
初始化时的特殊情况
raft 参数与Tidb 参数对应关系
一 概念

leader :数据在TiKV中是以region为单位存储的,每个region默认有三个副本,其中一个副本的角色为leader,所有客户端的读写流量都是走leader的,follower是不参加读写的,leader会周期性的向follower发出心跳通知信息,同时也会把自己写的数据以日志的方式传递给其他follower
follower:被管理者,对其他服务作出相应,同时接受leader的日志并进行复制,如果长时间接收不到leader的通知信息,follower的角色就会转变为candidate(候选者),候选者会发起投票,告诉大家,leader不在了 ,你们要选我。candidate是由follower转变而来 ,转变的前提是leader长时间没有通知信息了
TiDB写数据的只写leader ,然后通过日志的方式,向其他follower进行复制。
数据在region中的存储:region是一个逻辑概念,是键值对的集合,region中是以key的排序的。region 中存储的kv达到96M后,会写下一个region。初始的region中的key连续的,region是一个左闭右开的区间。当region的大小达到144M之后,就会发生分裂split。当对region的数据进行大量删除时,region的大小过小时(可以自己设定这个值),也可以进行合并。
raft group:多个region 构成raft goup
multi raft :多个raft group构成multi raft
region中key数量过多的性能问题
当region的数量太多时,比如一个TiKV node中超过5w个region时 ,随之而来的就是管理成本很高,因为每个region需要定期的向PD进心跳的汇报。
二 raft共识算法对于TiKV的几个重要功能
1 Raft日志复制

1 Raft日志复制流程
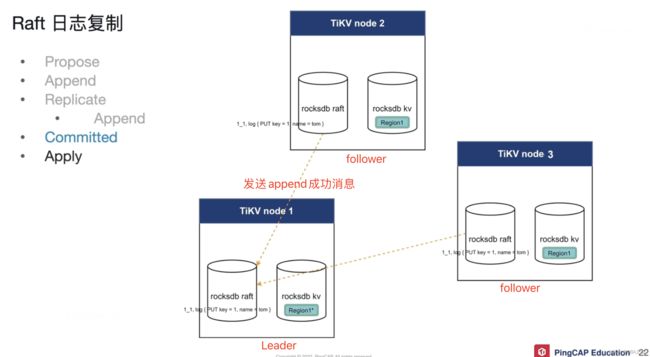
当客户端TiDB server需要写入数据时,会把数据发送给TiKV中某个region 的leader角色,
第一步是 propose,会把写入请求转换为写入日志 Raft log。Raft log的格式:region号_日志序号.log,例如4_2.log { put key=3,name = nico}, 通过raft log的这种格式,可以明确确认操作的region以及日志的先后顺序。
第二步是 append, 然后就把raft log 存储在leader本地的Rocksdb中,进行持久化
第三步是 replicate,通过raft算法将日志发送给其他follower ,follower收到日志后也会持久化到本地RocksDB中,然后follower会返回append成功的消息,当大多数follower返回消息后,leader就会认为这条日志持久化成功,leader就会就行committed
每个TiKV node 中有两个RocksDB 一个存储KV 一个存储Raft log。
2 名词解释
通过名词再次理解

Propose:当客户端比如TIDB server,或者你自己开发的可以写入TiKV的客户端,写入的是一条日志Raft log

Append:Propose之后接收到Raft log,leader将Raft log持久化到rocksdb。目前之后leader的Raft log持久化了。

Repicate:将Leader的raft log复制到其他的副本所在的节点上。其他副本接受到日志后进行append
Committed: 超过半数的节点进行了append 并返回消息给follower ,就可以进行这条Raft log 进行了持久化不会丢失。这里的Committed是指的是raft log的Committed。这里的Committed不是事务中的,现在用户还是看不到这次日志所涉及的数据的修改。
Apply :将Raft log 转换 并写到 RocksDB KV中
分层次理解TIKV
为了实现持久化 :使用了开源单机数据存储引擎Rocksdb,可以理解为一个巨大的key-value map。
为了实现数据高可用,避免单机故障:持久化之后要做数据多副本,数据多副本的一致性算法使用Raft 协议。
为了实现存储水平扩展:引入了Region
为了提高系统并发 写不阻塞读:引入MVCC层 ,数据多版本。
为了实现事务:引入Tranaction层
2 Raft Leader选举
Raft 共识算法中term:
term:时间时期的概念,官方定义 将时间分为一小段,每个Termd的长度不确定,他代表一段稳定的关系.举个例子:每个term就是一个恋爱关系,A和B 关系很好很稳定,这个term的长度就很长,如果A和B关系破裂了,A就进入下一个term。
集群初始状态时Leader选举流程

集群在刚开始创建的时候,没有leader ,每个region都是follower 。
每个region有个计时器 叫做 election timeout,假设为10秒,当超过这个时间,没有收到leader的心跳信息,就会认为集群中没有leader,那么这时候某个follower率先突破了election timeout这个时间(一般是150ms -300ms),要打破这种没有leader的关系。自己的角色转换为candidate,term 也加1。
然后想其他的follow发送投票的请求,其他的follower的term 比较小,会投票给term大。这样就产生了leader,进入下一段关系。
数据正在复制时Leader选举流程

此时的raft group中的region处于一种稳定的复制关系中 ,突然出现了宕机或者网络中断。当follower 超过某个时间没有收到leader的心跳信息时 ,这个时间为heartbeat time interval,就会认为leader挂了,然后就要起义,角色变为candidate,同时term +1 ,然后发起选举 ,term 小的会投投票给term比较大的region。
初始化时的特殊情况

多个region 都成为了candidate ,系统会重新发起投票,直到产生leader ,但是也有可能出现多次投票的状况,为了解决这个问题 Raft 共识算法引入了参数 random election timeout ,指定一个范围,比如100ms ~ 300ms ,这样大家都成为candidate的概率会降低很多。
raft 参数与Tidb 参数对应关系
ticks 代表多少个raft-base-tick-interval参数设置的时间单位
Election timeout 对应 raft-election-time-ticks * raft-base-tick-interval
Heartbeat time interval 对应 raft-heartbead-ticks * raft-base-tick-interval
raft-base-tick-interval 默认是1秒 raft-election-time-ticks = 5 ,则Election timeout 为5秒
参考
三篇文章了解 TiDB 技术内幕 - 说存储 | PingCAP