Android输入子系统
Android输入子系统
1.Android输入子系统简介
用户操作输入设备时,Linux内核收到相应的硬件中断,然后将中断加工成原始的输入事件数据并写入其对应的设备节点中,在用户空间可以通过read函数将事件数据读出。
Andriod输入系统的工作原理概括来说,就是监控/dev/input/下的所有设备节点,当某个节点有数据可读时,将数据读出并进行一系列的翻译加工,然后在所有的窗口中寻找合适的事件接收者,并派发给它。
2.Android输入系统简介
输入系统的总体流程

3.Android用户输入系统的层次结构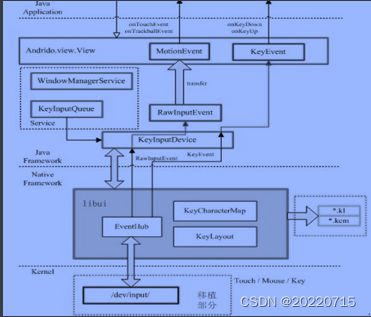
4.getevevnt与sendevent工具
Android系统提供了getevent与sendevent两个工具供开发者从设备节点中直接读取输入事件或写入输入事件。
adb shell getevent [-选项] [device_path]
其中device_path是可选参数,用以指明需要监听的设备节点路径。如果省略此参数,则监听所有设备节点的事件。
打开终端,执行adb shell getevent –t(-t参数表示打印事件的时间戳),并按一下电源键(不要松手),可以得到以下一条输出,输出的部分数值会因机型的不同而有所差异,但格式一致:
[1262.443489] /dev/input/event0: 0001 0074 00000001
松开电源键时,又会产生以下一条输出:
[1262.557130] /dev/input/event0: 0001 0074 00000000
这两条输出便是按下和抬起电源键时由内核生成的原始事件。注意其输出是十六进制的。
每条数据有五项信息:
产生事件时的时间戳([ 1262.443489])
产生事件的设备节点(/dev/input/event0)
事件类型(0001)
事件代码(0074)
事件的值(00000001)
其中时间戳、类型、代码、值便是原始事件的四项基本元素。除时间戳外,其他三项元素的实际意义依照设备类型及厂商的不同而有所区别。在本例中,类型0x01表示此事件为一条按键事件,代码0x74表示电源键的扫描码,值0x01表示按下,0x00则表示抬起。这两条原始数据被输入系统包装成两个KeyEvent对象,作为两个按键事件派发给Framework中感兴趣的模块或应用程序
输入设备的节点不仅在用户空间可读,而且是可写的,因此可以将将原始事件写入到节点中,从而实现模拟用户输入的功能。sendevent工具的作用正是如此。其用法如下:
sendevent <节点路径> <类型><代码> <值>
可以看出,sendevent的输入参数与getevent的输出是对应的,只不过sendevent的参数为十进制。电源键的代码0x74的十进制为116,因此可以通过快速执行如下两条命令实现点击电源键的效果:
adb shell sendevent /dev/input/event0 1 116 1 #按下电源键
adb shell sendevent /dev/input/event0 1 116 0 #抬起电源键
执行完这两条命令后,可以看到设备进入了休眠或被唤醒,与按下实际的电源键的效果一模一样。另外,执行这两条命令的时间间隔便是用户按住电源键所保持的时间,所以如果执行第一条命令后迟迟不执行第二条,则会产生长按电源键的效果——关机对话框出现了
代码示例
#include 5.Inotify机制
Inotify 是一个 Linux 内核特性,它监控文件系统,并且及时向专门的应用程序发出相关的事件警告,比如删除、读、写和卸载操作等。您还可以跟踪活动的源头和目标等细节。
Android输入系统监控/dev/input/下的所有设备节点,通过inotify机制实现
inotify机制可用于监控文件或目录。当监控目录时,与该目录自身以及该目录下面的文件都会被监控,其上有事件发生时都会通知给应用程序
2)inotify监控机制为非递归,若应用程序有意监控整个目录子树内的事件,则需对该树中的每个目录发起inotify_add_watch()调用
3)可使用select(),poll(),epoll()以及由信号驱动的I/O来监控inotify文件描述符
5.1Inotify API
inotify_init()系统调用可创建一新的inotify实例
#include •该函数的返回值为一个文件描述符,我们可以简单的理解为该文件描述符所指代的文件中将会保存类似所监控的目录所发生的事件集
针对fd所指的inotify实例的监控列表,系统调用inotify_add_watch()可以追加新的监控项
#include 参数pathname为想要创建的监控项所对应的文件,特别注意调用该接口必须要对该文件有读权限,该函数只对文件做一次检查,如果在监控时修改了所监控的文件读权限,则不会影响继续监控此文件
参数mask为一位掩码,针对pathname定义了想要监控的事件,此函数的返回值为一个用于唯一指代此监控项的描述符
5.2Inotify事件
IN_ACCESS 文件被访问
IN_ATTRIB 文件源数据改变
IN_CREATE 在受监控目录下创建了文件或目录
IN_DELETE 在受监控目录内删除了文件或目录
IN_DELETE_SELF 删除了受监控目录/文件本身
IN_MODIFY 文件被修改
IN_OPEN 文件被打开
IN_ALL_EVENTS 以上所有输出事件的统称
当文件的源数据(比如,权限,所有权,链接计数,扩展属性,用户ID,或组ID等)改变时,会发生IN_ATTRIB事件
删除受监控对象时会发生IN_DELETE_SELF
重命名对象时会发生IN_MORE_SELF事件
ONE_SHOT允许只监控pathname的一个事件,事件发生后,监控项会自动从监控列表消失
5.3读取Inotify事件
将监控项项在监控列表中登记后,应运程序可用read()从inotify的文件描述符中读取事件,以判定发生了那些事件。若读取之时还没有发生任何事件,则read()会阻塞,直至有事件产生,事件发生后,每次调用read()会返回一个缓存区,内含一个或多个如下类型的结构体
struct inotify_event{
int wd; /* Watch descriptor. */
uint32_t mask; /* Watch mask. */uint32_t cookie; /*
uint32_t len; /* Length (including NULs) of name. */
char name __flexarr; /* Name. */
}
.字段wd指名发生事件的是哪个监控描述符,该字段值由之前对inotify_add_watch()的调用返回。因为用read()读到的是inotify文件中的所有事件,可是当inotify同时监控多个目录或文件时我们应该如何区分读到的内容呢,这是wd就派上了用场,我们可以用wd来做区分
.mask字段返回了描述该事件的位掩码
.cookie字段将相关事件联系到一起,目前只有对重命名时才会用到
.len字段表示实际分配给name字段的字节数
.name字段则是标示该文件
6.Epoll机制
epoll同样只告知那些就绪的文件描述符,而且当我们调用epoll_wait()获得就绪文件描述符时,返回的不是实际的描述符,而是一个代表就绪描述符数量的值,你只需要去epoll指定的一个数组中依次取得相应数量的文件描述符即可,这里也使用了内存映射(mmap)技术,这样便彻底省掉了这些文件描述符在系统调用时复制的开销。
另一个本质的改进在于epoll采用基于事件的就绪通知方式。在select/poll中,进程只有在调用一定的方法后,内核才对所有监视的文件描述符进行扫描,而epoll事先通过epoll_ctl()来注册一个文件描述符,一旦基于某个文件描述符就绪时,内核会采用类似callback的回调机制,迅速激活这个文件描述符,当进程调用epoll_wait()时便得到通知。
6.1Epoll相关API
创建epoll句柄
int epoll_create(int size);
创建一个epoll的句柄。自从linux2.6.8之后,size参数是被忽略的。需要注意的是,当创建好epoll句柄后,它就是会占用一个fd值,在linux下如果查看/proc/进程id/fd/,是能够看到这个fd的,所以在使用完epoll后,必须调用close()关闭,否则可能导致fd被耗尽
注册事件
int epoll_ctl(int epfd, int op,int fd, struct epoll_event *event);
epoll的事件注册函数,它不同于select()是在监听事件时告诉内核要监听什么类型的事件,而是在这里先注册要监听的事件类型。
第一个参数是epoll_create()的返回值。
第二个参数表示动作,用三个宏来表示:
EPOLL_CTL_ADD:注册新的fd到epfd中;
EPOLL_CTL_MOD:修改已经注册的fd的监听事件;
EPOLL_CTL_DEL:从epfd中删除一个fd;
第三个参数是需要监听的fd。
第四个参数是告诉内核需要监听什么事,struct epoll_event结构如下:
struct epoll_event {
__uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
typedef union epoll_data {
void *ptr;
int fd;
__uint32_t u32;
__uint64_t u64;
} epoll_data_t;
events可以是以下几个宏的集合:
EPOLLIN :表示对应的文件描述符可以读(包括对端SOCKET正常关闭);
EPOLLOUT:表示对应的文件描述符可以写;
EPOLLPRI:表示对应的文件描述符有紧急的数据可读(这里应该表示有带外数据到来;
EPOLLERR:表示对应的文件描述符发生错误;
EPOLLHUP:表示对应的文件描述符被挂断;
EPOLLET: 将EPOLL设为边缘触发(Edge Triggered)模式。
EPOLLONESHOT:只监听一次事件,当监听完这次事件之后,如果还需要继续监听这个socket的话,需要再次把这个socket加入到EPOLL队列里
收集epoll监控的事件
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout,
const sigset_t *sigmask);
参数events是分配好的epoll_event结构体数组,epoll将会把发生的事件赋值到events数组中(events不可以是空指针,内核只负责把数据复制到这个events数组中,不会去帮助我们在用户态中分配内存)。maxevents告之内核这个events有多大,这个 maxevents的值不能大于创建epoll_create()时的size,参数timeout是超时时间(毫秒,0会立即返回,-1将不确定,也有说法说是永久阻塞)。如果函数调用成功,返回对应I/O上已准备好的文件描述符数目,如返回0表示已超时。
7.代码实例
#include