yolov5(v7.0)网络修改实践一:集成YOLOX的backbone(CSPDarknet和Pafpn)到yolov5(v7.0)框架中
yolov5太好用了,无论是实际做工程还是学习研究,yolov5都比较好上手,而且现在工业界yolov5也应用广泛。但是,作为学习研究,有不少在yolov5之后提出的涨点算法,还是有价值进行研究的,也便于跟进当下研究进展。于是打算在yolov5框架上集成一些优秀算法进行学习研究。
这次选的是在 yolov5后面提出的YOLOX,具体算法内容就不进行分析解读了,yolox是旷世提出的yolo系列的目标检测算法,应用的tricks比较多,采用了Darknet骨干网络,pafpn网络的特征融合方式,decoupledhead的双分支解耦合头,无锚框的anchor-free算法,还有mosaic等数据增强方式。这里先把yolox的特征提取阶段网络,及backbone和neck对应的CSPDarknet和Pafpn集成到yolov5中。
1、首先是yolox的网络配置
如下是GitHub下载的yolox的官方代码,可以依次看到,yolox的backbone和head分别默认使用YOLOPAFPN和YOLOXHead,这里先看backbone 部分

如下是YOLOPAFPN的代码,通过这个代码可以了解这个模块是怎么定义的,包含什么结构,输入输出信息等
包含的结构内容看__init__()函数,这些结构如何组成YOLOPAFPN看forward函数
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Copyright (c) Megvii Inc. All rights reserved.
import torch
import torch.nn as nn
from .darknet import CSPDarknet
from .network_blocks import BaseConv, CSPLayer, DWConv
class YOLOPAFPN(nn.Module):
"""
YOLOv3 model. Darknet 53 is the default backbone of this model.
"""
def __init__(
self,
depth=1.0,
width=1.0,
in_features=("dark3", "dark4", "dark5"),
in_channels=[256, 512, 1024],
depthwise=False,
act="silu",
):
super().__init__()
self.backbone = CSPDarknet(depth, width, depthwise=depthwise, act=act)
self.in_features = in_features
self.in_channels = in_channels
Conv = DWConv if depthwise else BaseConv
self.upsample = nn.Upsample(scale_factor=2, mode="nearest")
self.lateral_conv0 = BaseConv(
int(in_channels[2] * width), int(in_channels[1] * width), 1, 1, act=act
)
self.C3_p4 = CSPLayer(
int(2 * in_channels[1] * width),
int(in_channels[1] * width),
round(3 * depth),
False,
depthwise=depthwise,
act=act,
) # cat
self.reduce_conv1 = BaseConv(
int(in_channels[1] * width), int(in_channels[0] * width), 1, 1, act=act
)
self.C3_p3 = CSPLayer(
int(2 * in_channels[0] * width),
int(in_channels[0] * width),
round(3 * depth),
False,
depthwise=depthwise,
act=act,
)
# bottom-up conv
self.bu_conv2 = Conv(
int(in_channels[0] * width), int(in_channels[0] * width), 3, 2, act=act
)
self.C3_n3 = CSPLayer(
int(2 * in_channels[0] * width),
int(in_channels[1] * width),
round(3 * depth),
False,
depthwise=depthwise,
act=act,
)
# bottom-up conv
self.bu_conv1 = Conv(
int(in_channels[1] * width), int(in_channels[1] * width), 3, 2, act=act
)
self.C3_n4 = CSPLayer(
int(2 * in_channels[1] * width),
int(in_channels[2] * width),
round(3 * depth),
False,
depthwise=depthwise,
act=act,
)
def forward(self, input):
# backbone
out_features = self.backbone(input)
features = [out_features[f] for f in self.in_features]
[x2, x1, x0] = features
fpn_out0 = self.lateral_conv0(x0) # 1024->512/32
f_out0 = self.upsample(fpn_out0) # 512/16
f_out0 = torch.cat([f_out0, x1], 1) # 512->1024/16
f_out0 = self.C3_p4(f_out0) # 1024->512/16
fpn_out1 = self.reduce_conv1(f_out0) # 512->256/16
f_out1 = self.upsample(fpn_out1) # 256/8
f_out1 = torch.cat([f_out1, x2], 1) # 256->512/8
pan_out2 = self.C3_p3(f_out1) # 512->256/8
p_out1 = self.bu_conv2(pan_out2) # 256->256/16
p_out1 = torch.cat([p_out1, fpn_out1], 1) # 256->512/16
pan_out1 = self.C3_n3(p_out1) # 512->512/16
p_out0 = self.bu_conv1(pan_out1) # 512->512/32
p_out0 = torch.cat([p_out0, fpn_out0], 1) # 512->1024/32
pan_out0 = self.C3_n4(p_out0) # 1024->1024/32
outputs = (pan_out2, pan_out1, pan_out0)
return outputs
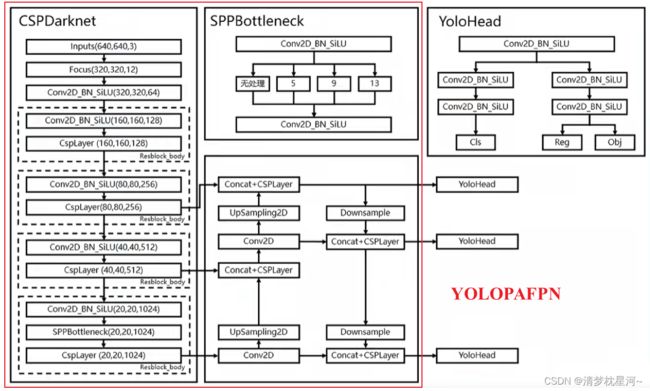
forward函数决定定义模块的结构。从上forward函数可以发现,YOLOPAFPN还需先经过一个backbone:CSPDarknet得到输出后再进入特征融合阶段,从forward函数也就可以了解到YOLOPAFPN的整体结构了。如下是找的YOLOX的网络结构图,红框内即是YOLOPAFPN的结构
根据导入的库可以找到CSPDarknet和相关基础模块的定义代码,分别在models文件夹下的darknet.py和network_blocks.py下

2、模块迁移,匹配yolov5框架
在了解清楚yolox的YOLOPAFPN的结构后,接下来就可以进行模块的迁移。其实我们已经获得YOLOPAFPN的代码了,直接调过来用不就可以吗?可能有人会有这种疑问,其实我也想这么操作,这样多省事啊,一旦有什么新的开源算法直接拿过来调用就行了。
鉴于yolov5的优越性,作者实在是喜欢yolov5的框架,且为了直观的对比所谓的先进算法带来的涨点,就打算迁移到yolov5框架。另一方面,如果yolov5本身就支持这种直接调用的网络构建那也可以很省事。事实上是yolov5有自己的网络构建方式,我们需要根据yolov5框架的标准来把网络迁移进来。
前面我已经分析过yolov5的网络构建方法和训练过程,这里就不细述了,主要是通过配置参数cfg传入网络的结构参数,如yolov5s.yaml,再通过models/yolo.py中的parse_model()函数来串联网络结构。
**backbone的前3个C3数量对应yolov5s.yaml的配置3,6,9分别除了3,变为1/3后的1,2,3,和模型深度参数有关depth_multiple: 0.33 model depth multiple**
层数,第几层 from n params module arguments
ch[-1] 数量 参数量 模块名称(m) 网络结构参数,输入维度,输出维度,卷积核大小,卷积步长
0 -1 1 3520 models.common.Conv [3, 32, 6, 2, 2]
1 -1 1 18560 models.common.Conv [32, 64, 3, 2]
2 -1 1 18816 models.common.C3 [64, 64, 1]
3 -1 1 73984 models.common.Conv [64, 128, 3, 2]
4 -1 2 115712 models.common.C3 [128, 128, 2]
5 -1 1 295424 models.common.Conv [128, 256, 3, 2]
6 -1 3 625152 models.common.C3 [256, 256, 3]
7 -1 1 1180672 models.common.Conv [256, 512, 3, 2]
8 -1 1 1182720 models.common.C3 [512, 512, 1]
9 -1 1 656896 models.common.SPPF [512, 512, 5]
10 -1 1 131584 models.common.Conv [512, 256, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 1 361984 models.common.C3 [512, 256, 1, False]
14 -1 1 33024 models.common.Conv [256, 128, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 90880 models.common.C3 [256, 128, 1, False]
18 -1 1 147712 models.common.Conv [128, 128, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 1 296448 models.common.C3 [256, 256, 1, False]
21 -1 1 590336 models.common.Conv [256, 256, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 1 1182720 models.common.C3 [512, 512, 1, False]
24 [17, 20, 23] 1 16182 models.yolo.Detect [1, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
从上可见,yolov5的网络构建是基于一个个基础模块(如Conv、C3等)串联起来实例化得到网络结构,一层层模块标识层数来使首尾相连的模块的输入输出参数变换一致。我改了一个对应yolov5s的版本:
与yolov5s类似,yolox-s也有控制网络参数量的参数,在网络构建的时候可以一同考虑。

如上是我构建好的YOLOPAFPN网络训练时打印出来的模块信息,最终成功训练上了
如下是我的yaml配置文件:
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8 anchor_height,anchor_width,每个尺度设置三种锚框,使用时除以下采样倍数
- [30,61, 62,45, 59,119] # P4/16 anchor_height,anchor_width,每个尺度设置三种锚框,使用时除以下采样倍数
- [116,90, 156,198, 373,326] # P5/32 anchor_height,anchor_width,每个尺度设置三种锚框,使用时除以下采样倍数
# YOLOX backbone
backbone:
# [from, number, module, args]
[[-1, 1, XFocus, [64, 3]], #3,32 0表示输入、输出以及当前网络层数
[-1, 1, Dark2, [128,3,2]], #32 64 1
[-1, 1, Dark3, [256,3,2]], #64 128 2
[-1, 1, Dark4, [512,3,2]], #128 256 3
[-1, 1, Dark5, [1024,3,2]], #256 512 4
[-1, 1, LarConv0, [512]], #512 256 5
[-1, 1, nn.Upsample, [None, 2, 'nearest']], #256 256 6
[[-1, 3], 1, Concat, [1]], # 256 512 7
[-1, 1, C3_p4, [512]], #512 256 8
[-1, 1, RedConv1,[256]], #256 128 9
[-1, 1, nn.Upsample, [None, 2, 'nearest']], #128, 128 10
[[-1, 2], 1, Concat, [1]], #128 256 11
[-1, 1, C3_p3, [256]], #256, 128 12
[-1, 1, ButConv2, [256]], #128 128 13
[[-1, 9], 1, Concat, [1]], #128 256 14
[-1, 1, C3_n3, [512]], # 256 256 15
[-1, 1, ButConv1, [512]], #256 256 16
[[-1, 5], 1, Concat, [1]], #256 512 17
[-1, 1, C3_n4, [1024]], #512 512 18
]
head:
# yolov5 head
[
[[12, 15, 18], 1, Detect, [nc, anchors]],
]
以上模块XFocus、Dark2-Dark5、LarConv0、C3_p4、RedConv1、ButConv1等的py代码,建议加在common.py中
######################### YOLOX ###########################
def get_activation(name="silu", inplace=True):
if name == "silu":
module = nn.SiLU(inplace=inplace)
elif name == "relu":
module = nn.ReLU(inplace=inplace)
elif name == "lrelu":
module = nn.LeakyReLU(0.1, inplace=inplace)
else:
raise AttributeError("Unsupported act type: {}".format(name))
return module
class BottleneckX(nn.Module):
# Standard bottleneck
def __init__(
self,
in_channels,
out_channels,
shortcut=True,
expansion=0.5,
depthwise=False,
act="silu",
):
super().__init__()
hidden_channels = int(out_channels * expansion)
Conv = DWConv if depthwise else BaseConv
self.conv1 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=act)
self.conv2 = Conv(hidden_channels, out_channels, 3, stride=1, act=act)
self.use_add = shortcut and in_channels == out_channels
def forward(self, x):
y = self.conv2(self.conv1(x))
if self.use_add:
y = y + x
return y
class BaseConv(nn.Module):
"""A Conv2d -> Batchnorm -> silu/leaky relu block"""
def __init__(
self, in_channels, out_channels, ksize, stride, groups=1, bias=False, act="silu"
):
super().__init__()
# same padding
pad = (ksize - 1) // 2
self.conv = nn.Conv2d(
in_channels,
out_channels,
kernel_size=ksize,
stride=stride,
padding=pad,
groups=groups,
bias=bias,
)
self.bn = nn.BatchNorm2d(out_channels)
self.act = get_activation(act, inplace=True)
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
class DWConv(nn.Module):
"""Depthwise Conv + Conv"""
def __init__(self, in_channels, out_channels, ksize, stride=1, act="silu"):
super().__init__()
self.dconv = BaseConv(
in_channels,
in_channels,
ksize=ksize,
stride=stride,
groups=in_channels,
act=act,
)
self.pconv = BaseConv(
in_channels, out_channels, ksize=1, stride=1, groups=1, act=act
)
def forward(self, x):
x = self.dconv(x)
return self.pconv(x)
class CSPLayer(nn.Module):
"""C3 in yolov5, CSP Bottleneck with 3 convolutions"""
def __init__(
self,
in_channels,
out_channels,
n=1,
shortcut=True,
expansion=0.5,
depthwise=False,
act="silu",
):
"""
Args:
in_channels (int): input channels.
out_channels (int): output channels.
n (int): number of Bottlenecks. Default value: 1.
"""
# ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
hidden_channels = int(out_channels * expansion) # hidden channels
self.conv1 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=act)
self.conv2 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=act)
self.conv3 = BaseConv(2 * hidden_channels, out_channels, 1, stride=1, act=act)
module_list = [
BottleneckX(
hidden_channels, hidden_channels, shortcut, 1.0, depthwise, act=act
)
for _ in range(n)
]
self.m = nn.Sequential(*module_list)
def forward(self, x):
x_1 = self.conv1(x)
x_2 = self.conv2(x)
x_1 = self.m(x_1)
x = torch.cat((x_1, x_2), dim=1)
return self.conv3(x)
class SPPBottleneck(nn.Module):
"""Spatial pyramid pooling layer used in YOLOv3-SPP"""
def __init__(
self, in_channels, out_channels, kernel_sizes=(5, 9, 13), activation="silu"
):
super().__init__()
hidden_channels = in_channels // 2
self.conv1 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=activation)
self.m = nn.ModuleList(
[
nn.MaxPool2d(kernel_size=ks, stride=1, padding=ks // 2)
for ks in kernel_sizes
]
)
conv2_channels = hidden_channels * (len(kernel_sizes) + 1)
self.conv2 = BaseConv(conv2_channels, out_channels, 1, stride=1, act=activation)
def forward(self, x):
x = self.conv1(x)
x = torch.cat([x] + [m(x) for m in self.m], dim=1)
x = self.conv2(x)
return x
class XFocus(nn.Module):
"""Focus width and height information into channel space."""
def __init__(self, in_channels, out_channels, ksize=1, stride=1, act="silu"):
super().__init__()
self.conv = BaseConv(in_channels * 4, out_channels, ksize, stride, act=act)
def forward(self, x):
# shape of x (b,c,w,h) -> y(b,4c,w/2,h/2)
patch_top_left = x[..., ::2, ::2]
patch_top_right = x[..., ::2, 1::2]
patch_bot_left = x[..., 1::2, ::2]
patch_bot_right = x[..., 1::2, 1::2]
x = torch.cat(
(
patch_top_left,
patch_bot_left,
patch_top_right,
patch_bot_right,
),
dim=1,
)
return self.conv(x)
class Dark2(nn.Module):
def __init__(self, in_channels, out_channels, ksize=1, stride=1, act="silu", depthwise=False):
super().__init__()
Conv = DWConv if depthwise else BaseConv
dep_mul = 0.33
base_depth = max(round(dep_mul * 3), 1)
self.dark2 = nn.Sequential(
Conv(in_channels, in_channels * 2, 3, 2, act=act),
CSPLayer(
in_channels * 2,
in_channels * 2,
n=base_depth,
depthwise=depthwise,
act=act,
),
)
def forward(self, x):
return self.dark2(x)
class Dark3(nn.Module):
# def __init__(self, in_channels, out_channels, ksize=1, stride=1, act="silu", depthwise=False):
def __init__(self, in_channels, out_channels, ksize, stride, act="silu", depthwise=False):
super().__init__()
Conv = DWConv if depthwise else BaseConv
dep_mul = 0.33
base_depth = max(round(dep_mul * 3), 1)
self.dark3 = nn.Sequential(
Conv(in_channels, in_channels * 2, 3, 2, act=act),
CSPLayer(
in_channels * 2,
in_channels * 2,
n=base_depth * 3,
depthwise=depthwise,
act=act,
),
)
def forward(self, x):
return self.dark3(x)
class Dark4(nn.Module):
def __init__(self, in_channels, out_channels, ksize=1, stride=1, act="silu", depthwise=False):
super().__init__()
Conv = DWConv if depthwise else BaseConv
dep_mul = 0.33
base_depth = max(round(dep_mul * 3), 1)
self.dark4 = nn.Sequential(
Conv(in_channels , in_channels * 2, 3, 2, act=act),
CSPLayer(
in_channels * 2,
in_channels * 2,
n=base_depth * 3,
depthwise=depthwise,
act=act,
),
)
def forward(self, x):
return self.dark4(x)
class Dark5(nn.Module):
def __init__(self, in_channels, out_channels, ksize=1, stride=1, act="silu", depthwise=False):
super().__init__()
Conv = DWConv if depthwise else BaseConv
dep_mul = 0.33
base_depth = max(round(dep_mul * 3), 1)
self.dark5 = nn.Sequential(
Conv(in_channels , in_channels * 2, 3, 2, act=act),
SPPBottleneck(in_channels * 2, in_channels * 2, activation=act),
CSPLayer(
in_channels * 2,
in_channels * 2,
n=base_depth,
shortcut=False,
depthwise=depthwise,
act=act,
),
)
def forward(self, x):
return self.dark5(x)
class LarConv0(nn.Module):
def __init__(self, in_channels, out_channels, ksize=1, stride=1, act="silu", depthwise=False):
super().__init__()
self.lateral_conv0 = BaseConv(
int(in_channels), int(out_channels), 1, 1, act=act
)
def forward(self, x):
return self.lateral_conv0(x)
class C3_p4(nn.Module):
def __init__(self, in_channels, out_channels, ksize=1, stride=1, act="silu", depthwise=False):
super().__init__()
depth = 0.33
self.c3_p4 = CSPLayer(
int(in_channels),
int(out_channels),
round(3 * depth),
False,
depthwise=depthwise,
act=act,
) # cat
def forward(self, x):
return self.c3_p4(x)
class RedConv1(nn.Module):
def __init__(self, in_channels, out_channels, ksize=1, stride=1, act="silu", depthwise=False):
super().__init__()
self.reduce_conv1 = BaseConv(
int(in_channels), out_channels, 1, 1, act=act
)
def forward(self, x):
return self.reduce_conv1(x)
class C3_p3(nn.Module):
def __init__(self, in_channels, out_channels, ksize=1, stride=1, act="silu", depthwise=False):
super().__init__()
depth = 0.33
self.c3_p3 = CSPLayer(
int(in_channels),
int(out_channels),
round(3 * depth),
False,
depthwise=depthwise,
act=act,
)
def forward(self, x):
return self.c3_p3(x)
class ButConv2(nn.Module):
def __init__(self, in_channels, out_channels, ksize=1, stride=1, act="silu", depthwise=False):
super().__init__()
self.bu_conv2 = BaseConv(
int(in_channels), int(in_channels), 3, 2, act=act
)
def forward(self, x):
return self.bu_conv2(x)
class C3_n3(nn.Module):
def __init__(self, in_channels, out_channels, ksize=1, stride=1, act="silu", depthwise=False):
super().__init__()
depth = 0.33
self.c3_n3 = CSPLayer(
int(in_channels),
int(in_channels),
round(3 * depth),
False,
depthwise=depthwise,
act=act,
)
def forward(self, x):
return self.c3_n3(x)
class ButConv1(nn.Module):
def __init__(self, in_channels, out_channels, ksize=1, stride=1, act="silu", depthwise=False):
super().__init__()
self.bu_conv1 = BaseConv(
int(in_channels), int(in_channels), 3, 2, act=act
)
def forward(self, x):
return self.bu_conv1(x)
class C3_n4(nn.Module):
def __init__(self, in_channels, out_channels, ksize=1, stride=1, act="silu", depthwise=False):
super().__init__()
depth = 0.33
self.c3_n4 = CSPLayer(
int(in_channels),
int(in_channels),
round(3 * depth),
False,
depthwise=depthwise,
act=act,
)
def forward(self, x):
return self.c3_n4(x)
这样基本把yolox的backbone的相关模块在yolov5s中实现了,适用于yolov5的网络构建方式。里面主要需要注意模块之间的输入输出对应。
或者你想要验证复现的YOLOPAFPN是否与yolox一致,可以单独把YOLOPAFPN()拎出来,实例化输入输出看网络结构,本人验证后,发现是一致的。
"""
YOLOPAFPN(
(backbone): CSPDarknet(
(stem): Focus(
(conv): BaseConv(
(conv): Conv2d(12, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
)
(dark2): Sequential(
(0): BaseConv(
(conv): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(1): CSPLayer(
(conv1): BaseConv(
(conv): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(conv2): BaseConv(
(conv): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(conv3): BaseConv(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(m): Sequential(
(0): Bottleneck(
(conv1): BaseConv(
(conv): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(conv2): BaseConv(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
)
)
)
)
(dark3): Sequential(
(0): BaseConv(
(conv): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(1): CSPLayer(
(conv1): BaseConv(
(conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(conv2): BaseConv(
(conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(conv3): BaseConv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(m): Sequential(
(0): Bottleneck(
(conv1): BaseConv(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(conv2): BaseConv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
)
(1): Bottleneck(
(conv1): BaseConv(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(conv2): BaseConv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
)
(2): Bottleneck(
(conv1): BaseConv(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(conv2): BaseConv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
)
)
)
)
(dark4): Sequential(
(0): BaseConv(
(conv): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(1): CSPLayer(
(conv1): BaseConv(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(conv2): BaseConv(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(conv3): BaseConv(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(m): Sequential(
(0): Bottleneck(
(conv1): BaseConv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(conv2): BaseConv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
)
(1): Bottleneck(
(conv1): BaseConv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(conv2): BaseConv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
)
(2): Bottleneck(
(conv1): BaseConv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(conv2): BaseConv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
)
)
)
)
(dark5): Sequential(
(0): BaseConv(
(conv): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(1): SPPBottleneck(
(conv1): BaseConv(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(m): ModuleList(
(0): MaxPool2d(kernel_size=5, stride=1, padding=2, dilation=1, ceil_mode=False)
(1): MaxPool2d(kernel_size=9, stride=1, padding=4, dilation=1, ceil_mode=False)
(2): MaxPool2d(kernel_size=13, stride=1, padding=6, dilation=1, ceil_mode=False)
)
(conv2): BaseConv(
(conv): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
)
(2): CSPLayer(
(conv1): BaseConv(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(conv2): BaseConv(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(conv3): BaseConv(
(conv): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(m): Sequential(
(0): Bottleneck(
(conv1): BaseConv(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(conv2): BaseConv(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
)
)
)
)
)
(upsample): Upsample(scale_factor=2.0, mode=nearest)
(lateral_conv0): BaseConv(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(C3_p4): CSPLayer(
(conv1): BaseConv(
(conv): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(conv2): BaseConv(
(conv): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(conv3): BaseConv(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(m): Sequential(
(0): Bottleneck(
(conv1): BaseConv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(conv2): BaseConv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
)
)
)
(reduce_conv1): BaseConv(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(C3_p3): CSPLayer(
(conv1): BaseConv(
(conv): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(conv2): BaseConv(
(conv): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(conv3): BaseConv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(m): Sequential(
(0): Bottleneck(
(conv1): BaseConv(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(conv2): BaseConv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
)
)
)
(bu_conv2): BaseConv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(C3_n3): CSPLayer(
(conv1): BaseConv(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(conv2): BaseConv(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(conv3): BaseConv(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(m): Sequential(
(0): Bottleneck(
(conv1): BaseConv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(conv2): BaseConv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
)
)
)
(bu_conv1): BaseConv(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(C3_n4): CSPLayer(
(conv1): BaseConv(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(conv2): BaseConv(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(conv3): BaseConv(
(conv): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(m): Sequential(
(0): Bottleneck(
(conv1): BaseConv(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(conv2): BaseConv(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
)
)
)
)
"""
3、成功训练,完成YOLOPAFPN复现
在成功训练前,还有一步,即把新加入的模块加入到网络构建函数中,不然无法识别构建的网络模块导致无法训练,网络构建函数在yolo.py中的parse_model(),修改如下:
def parse_model(d, ch): # model_dict, input_channels(3)
# Parse a YOLOv5 model.yaml dictionary
LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")
anchors, nc, gd, gw, act = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple'], d.get('activation')
if act:
Conv.default_act = eval(act) # redefine default activation, i.e. Conv.default_act = nn.SiLU()
LOGGER.info(f"{colorstr('activation:')} {act}") # print
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
m = eval(m) if isinstance(m, str) else m # eval strings
for j, a in enumerate(args):
with contextlib.suppress(NameError):
args[j] = eval(a) if isinstance(a, str) else a # eval strings
n = n_ = max(round(n * gd), 1) if n > 1 else n # depth gain
if m in {
Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x, XFocus, Dark2, Dark3, Dark4, Dark5, LarConv0, C3_p4,RedConv1, C3_p3,ButConv2,C3_n3,C3_n4,ButConv1}:
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in {BottleneckCSP, C3, C3TR, C3Ghost, C3x}:
args.insert(2, n) # number of repeats
n = 1
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum(ch[x] for x in f)
# TODO: channel, gw, gd
elif m in {Detect, Segment}:
args.append([ch[x] for x in f])
if isinstance(args[1], int): # number of anchors
args[1] = [list(range(args[1] * 2))] * len(f)
if m is Segment:
args[3] = make_divisible(args[3] * gw, 8)
# import ipdb;ipdb.set_trace()
elif m in {DetectDcoupleHead}:
"""args是yaml配置文件的字典中每行的列表里模块后的参数"""
# import ipdb;ipdb.set_trace()
args.append([ch[x] for x in f])#append导致输入维度参数在最后一个位置
if isinstance(args[1], int): # 锚框 number of anchors
args[1] = [list(range(args[1] * 2))] * len(f)
# import ipdb;ipdb.set_trace()
args[2] = gw
elif m in {DetectXHead}:
# args.append([int(ch[x] * gw) for x in f])
# print(args)
args.append([ch[x] for x in f])
args[1] = gw
# print(args)
# xx = args
# import ipdb;ipdb.set_trace()
elif m is Contract:
c2 = ch[f] * args[0] ** 2
elif m is Expand:
c2 = ch[f] // args[0] ** 2
else:
c2 = ch[f]
m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
t = str(m)[8:-2].replace('__main__.', '') # module type
np = sum(x.numel() for x in m_.parameters()) # number params
m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
LOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f} {t:<40}{str(args):<30}') # print
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
layers.append(m_)
if i == 0:
ch = []
ch.append(c2)
return nn.Sequential(*layers), sorted(save)
基于上述工作,再完善一下相关模块的引用,就完成了在yolov5中复现yolox的backbone:YOLOPAFPN模块
