【Linux】文件描述符(下篇)
文章目录
- 前言
- 1. 文件描述符fd的分配规则
- 2. 重定向的本质
- 3. 缓冲区的理解
-
- 3.1 感受缓冲区的存在:
- 3.2 正式认识缓冲区:
-
- 综合例题:
- 4. 模拟实现C语言的文件操作
- 5. 完善之前实现的shell
-
- 5.1 程序替换,会影响曾经子进程打开的文件吗?
- 6. 标准错误
前言
紧接着上篇的文件描述符,我们要继续讲解文件描述符,通过文件描述符讲解重定向的原理,再用所学的知识自己模拟实现一下C语言中fopen等文件操作,讲解一下缓冲区,最后再完善一下我们之前实现的shell。目标已经确定,接下来就要搬好小板凳,准备开讲了…
1. 文件描述符fd的分配规则
上一篇我们已经讲述了文件操作的内核中实现的映射关系,并且画了图理解了一遍。
创建struct file,初始化内部属性,函数指针指向对应方法,将这个对象的struct file地址填到,进程对应的文件描述表里面,分配一个指针数组没有被占用的下标,将数字下标返回。
那么这些下标fd都是如何分配的呢?
我们接下来做个小实验,将1号文件关掉,再创建一个文件,看其文件的fd是什么:
#include 我们显示一开始关闭了0号文件:

我们看到了fd为0,这就说明了,内核中struct file* fd array[]数组中0号下标是log.txt的文件的fd。
我们关闭了0号,关了之后0号又被打开,指向了别的文件。
结论:
从头遍历数组fd array[],找到一个最小的,没有被使用的下标,分配给新的文件!!
2. 重定向的本质
在之前学习Linux基础指令时,我们学过重定向操作,向指定文本中写入或追加文件内容。
而现在我们在了解文件内核基本结构之后,我们就可以理解重定向的本质了。
- 重定向是一种通过修改标准输入、标准输出和标准错误流的方式来改变程序的输入和输出方向的技术~
- 以我们现在所学的知识,完全可以实现,只需要将stdout关掉。
- 再将1号位置存的指针改成要被写入的文件的 files_struct 结构体的指针即可,这样写入就是往该文件写入了。
- 先close是先将1号描述符对应的对象设置成空,然后将新文件的文件对象的地址填入。
- 但是重定向可不用这么麻烦,有接口可供我们使用。
一堆的数据,都是内核数据结构,只有OS有权限,必定提供对应的接口~
dup函数:
dup函数的作用是创建一个新的文件描述符,该描述符是原始文件描述符的副本。

返回值:
![]()
dup函数返回新的文件描述符,如果复制成功,则返回的文件描述符与oldfd具有相同的值和属性。如果复制失败,则返回-1,并设置errno来指示错误的原因。
我们要弄清楚谁是谁的一份拷贝,一定是oldfd拷贝给了newfd(newfd的内容是oldfd的一份拷贝),最后两个都是oldfd,别弄反了~

输出重定向:
#include 追加重定向:


输入重定向:
int main()
{
int fd = open("log.txt", O_RDONLY);
if(fd < 0)
{
perror("open");
return 1;
}
char line[64];
//输入定向
dup2(fd, 0);
while(fgets(line, sizeof(line), stdin) != NULL)
{
printf("%s", line);
}
close(fd);
return 0;
}
从log.txt文件内容通过fgets按行读取,读取完之后再用循环体将内容打印出来。
注意:
- 文件地址的拷贝,拷贝的是指向。
- 拷贝的是指针(file*)
- 是将数组下标对应的内容做拷贝,拷贝的是里面的内容,不是拷贝整数。
总结:
如果我们要进行重定向,上层只认0, 1, 2, 3, 4, 5这样的fd,我们可以在OS内部, 通过一定的方式调整数组的特定下标的内容(指向),我们就可以完成重定向操作!
3. 缓冲区的理解
3.1 感受缓冲区的存在:
上述代码结果我们已经看了,如果我们关闭的是1号文件呢?
int main()
{
close(1);
//根据fd的分配规则,新的fd值一定是1
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
if(fd < 0)
{
perror("open");
return 1;
}
//printf -> stdout -> 1 -> 虽然不再指向对应的显示器了,但是已经指向了log.txt的底层struct file对象!
printf("fd : %d\n", fd);
fflush(stdout);
close(fd);
return 0;
}
printf -> stdout -> 1 -> 虽然不再指向对应的显示器了,但是已经指向了log.txt的底层struct file对象!
既然是向log.txt写入,我们运行之后,来看一下log.txt中的结果:

文件中并没有内容,这就是因为缓冲区的存在,我们需要用到fflush(stdout);来刷新一下缓冲区,不然就不会显示。
有个疑问:
- 为什么在进程结束之后缓冲区的内容没有直接刷新到 log.txt 文件当中呢?
- 在我们之前的学习中知道,进程结束就会将缓冲区的内容刷新到显示器上。
- 因为之前都是向显示器刷新,stdout并没有被关闭,1号没有分配新的fd。
- 对于标准输出流 stdout,当进程正常结束时,缓冲区的内容通常会被刷新到1号文件中。
- 没有刷新到 log.txt 文件的原因:
- 当进程正常终止时,操作系统会负责清理和关闭打开的文件描述符,包括标准输出流。
- 所以最后一行的close(fd)会关闭文件描述符1,导致标准输出流被关闭。
- 在关闭之前,操作系统会尝试将缓冲区中的内容刷新到对应的文件中。
- 在进程结束之前,缓冲区的内容会被刷新到 stdout(标准输出流)中。
- 然而在关闭标准输出流之前,缓冲区的内容并没有被刷新到文件中,因此最终没有将内容写入文件。
- 而将close(fd)去掉则会刷新到log.txt这个文件里,因为在关闭文件之前就刷新了。
正确做法:
为了确保缓冲区的内容被正确刷新到文件中,可以在关闭文件描述符之前进行一次输出操作,或者显式地使用
fflush(stdout)函数来手动刷新缓冲区。这样可以保证在关闭文件描述符之前,缓冲区的内容会被刷新到文件中。
总之,在进程正常终止前,操作系统会尽力将缓冲区的内容刷新到stdout,但不能保证一定成功。因此,最好使用fflush函数或其他相关函数来确保缓冲区的内容被刷新到文件中。
3.2 正式认识缓冲区:
- 什么是缓冲区?
- 缓冲区的本质,就是一段内存。
- 为什么要有缓冲区?
- 解放使用缓冲区的进程时间。
- 缓冲区的存在可以集中处理数据刷新,减少IO的次数。
- 从而达到提高整机的效率的目的。
- 缓冲区在哪里?
FILE指针是一个指向 FILE 结构体的指针,该结构体包含了有关文件的信息和状态。- 通过
FILE指针,程序可以对文件进行读取、写入和定位等操作。 - 所以这个结构体中封装了文件的很多属性。
- 例如fd,还有该
FILE对应的语言级别的缓冲区!
既然缓冲区在
FILE内部,在C语言中,而我们每一次打开一个文件,都要有一个FILE*会返回!
是不是意味着,每一个文件都有一个fd和属于它自己的与语言级别缓冲区!是的!!
#include 
![]()

因为这些函数底层调用
write函数就失败了。
- 首先printf内部就是封装了write。
- 立刻刷新,所以sleep的时候数据并没有立刻显示出来。
- 不带缓冲区代表数据没法立即刷新。加上fflush就可以立即刷新出来了。
- fprintf、fputs和printf一样都是等待再刷新,等到进程退出的时候刷新。
- 这几个接口底层都封装了write。
为什么会出现等几秒钟才刷新出来的现象?
- 不是直接调用write接口,写到操作系统最后刷到硬件上的。
- 而是直接把数据写到了cache里面。
- 当数据量积累到一定程度,会定期的通过fd去调用write把数据刷新到内存中。
那么这个缓冲区在哪里??
- 只能是C语言提供的,是个语言级别的缓冲区。
那么这个缓冲区不在那里??
- 一定不在write内部!
- 那么我们曾经谈论的缓冲区,不是内核级别的。
fprintf、fputs和printf这三个接口都是C语言提供的,都有一个公共参数 — stdout。printf也有只是没有写出来而已。stdout是FILE结构体的指针。
- 缓冲区刷新策略:
- 什么时候刷新?
- 常规:
-
- 无缓冲(立即刷新)
-
- 行缓冲(逐行刷新),显示器文件。
-
- 全缓冲(缓冲区满,刷新),块设备对应的文件,磁盘文件。
- 特殊:
-
- 进程退出
-
- 用户强制刷新
根据文件类型来决定刷新策略。
综合例题:
下面程序的可执行程序test,重定向到log.txt文件中,那么log.txt文件中的内容是什么?
#include 
- 因为此时已经重定向到了
log.txt所以不会立即刷新而变成了全缓冲。 - 缓冲方式变化了,从行缓冲变成了全缓冲。
- 父子进程结束,代码父子进程共享,数据要以写时拷贝的形式各自有一份。
- 最终父进程刷一份,子进程刷一份,就会出现上述结果。
- 缓冲区,是自己的
FILE内部维护的,属于父进程内部的数据区域! - 写时拷贝,子进程内部缓冲区也有一份。
4. 模拟实现C语言的文件操作
有了之前的知识储备,我们可以封装系统调用接口,模拟一个缓冲区,来模拟实现C语言的文件操作接口的:
#include 把数据写到内核里,并不代表就是把数据写到硬件上了。 如果非要写到硬件上就要加上一个接口sync。
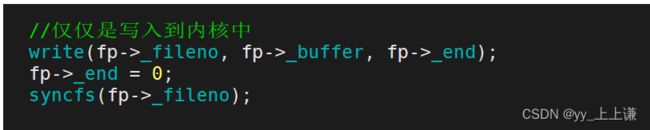
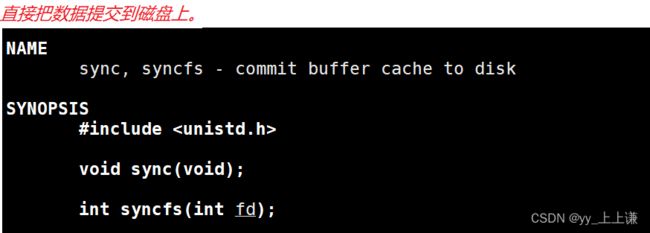
通过监控脚本,我们来观察一下:

5. 完善之前实现的shell
之前在学习进程程序替换的时候,我们模拟实现过一个shell【实现简易shell-复习传送门】。
没改进之前会出现的情况:

我们要对输入的命令做检查,对重定向操作符做单独处理。
单独加一个函数:
void CheckDir(char* commands)
{
assert(commands);
//[start, end)
char* start = commands;
//指向的是字符串最后的那个'\0'
char* end = commands + strlen(commands);
//ls -a -l>log.txt
while(start < end)
{
if(*start == '>')
{
if(*(start + 1) == '>')
{
//ls -a -l>>log.txt -- 追加
*start = '\0';
start += 2;
g_redir_flag = APPEND_REDIR;
DROP_SPACE(start);
g_redir_filename = start;
break;
}
else
{
//ls -a -l > log.txt -- 输出重定向
*start = '\0';
start++;
DROP_SPACE(start);
g_redir_flag = OUTPUT_REDIR;
g_redir_filename = start;
break;
}
}
else if(*start == '<')
{
//输入重定向
*start = '\0';
start++;
DROP_SPACE(start);
g_redir_flag = INPUT_REDIR;
g_redir_filename = start;
break;
}
else
{
start++;
}
}
}
其他的一些操作:


5.1 程序替换,会影响曾经子进程打开的文件吗?
—— 不影响!!
- 程序替换只影响该进程对应的代码和数据
- 曾经打开的文件,以及维护进程和文件之间映射关系的文件描述符表
- 都叫做内核数据结构,和
PCB一样不受程序替换的影响
6. 标准错误
标准输出和标准错误对应的都是显示器,虽然大家都是打印的是在一个显示器上,但是依旧是通过不同文件描述符打印的,要做到互不干扰。
#include 
上述重定向的指令是将往显示器中打印的数据重定向到
stdout.txt中去,但是我们可以看到依旧有内容显示在了显示器上。原因是虽然stdout和stderr都是向显示器打印但是,他们是有着不同的文件描述符,重定向只是重定向了一个文件而已。
当重定向的时候,只是对1号文件描述符重定向了,和2号没关系。
这样做的意义是什么:
- 可以区分哪些是程序日常正常输出
- 哪些是错误
补充:
- C++源文件的后缀可以是.cpp或者是.cc或者是.cxx
- 这三者都可以是C++源文件的后缀
连续重定向:
![]()
做了两次重定向:
- 第一次是将标准输出重定向到
stdout. txt当中。 - 第二次是把标准错误重定向到
stderr.txt文件当中。

既然有了上面的写法,那么我们就不禁思考原来我们的写法是否也可以改一下:
./a. out 1> stdout.txt 2> stderr.txt
其实这才是标准写法,只是我们之前将1给省略了。
将所有东西混合打印:
./a.out > all.txt 2>&1
“./a.out > all.txt 2>&1” 是一个用于命令行的重定向语法,它表示将程序 “./a.out” 的标准输出和标准错误输出都重定向到文件 “all.txt” 中。
具体解释如下:
>:表示重定向符号,用于将输出重定向至指定文件。- “all.txt”:是重定向输出的目标文件名,这里是指定为 “all.txt”。
2>&1:是将标准错误输出重定向到标准输出的语法。“2” 表示标准错误输出的文件描述符,“&1” 则表示标准输出的文件描述符。所以,2>&1的意思是将标准错误输出重定向到与标准输出相同的位置。
综上所述,“./a.out > all.txt 2>&1” 执行的效果是将程序 “./a.out” 的标准输出和标准错误输出都追加到文件 “all.txt” 中。注意,如果 “all.txt” 文件不存在,会自动创建;如果存在,则会将输出内容追加到文件末尾。
这种方式在日志记录和调试时很常见,可以将程序的所有输出信息保存到一个文件中,方便查看和分析。

原因是,在我们之前学习C语言的时候,就学过C语言有一个全局变量,记录最近一次C库函数调用失败的原因!
当库函数使用的时候,发生错误会把errno这个全局的错误变量设置成为本次执行库函数产生的错误码,errno是C语言提供的一个全局变量,可以直接使用放在errno. h的文件中。
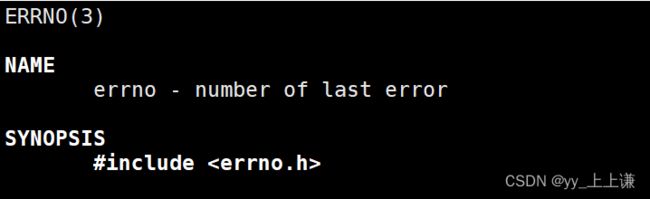
代码演示:
#include 上述打开文件肯定是错误的。
![]()