yolo
目标检测
导言:目标检测的任务表述
如何从图像中解析出可供计算机理解的信息,是机器视觉的中心问题。深度学习模型由于其强大的表示能力,加之数据量的积累和计算力的进步,成为机器视觉的热点研究方向。
那么,如何理解一张图片?根据后续任务的需要,有三个主要的层次。

一是分类(Classification),即是将图像结构化为某一类别的信息,用事先确定好的类别(string)或实例ID来描述图片。这一任务是最简单、最基础的图像理解任务,也是深度学习模型最先取得突破和实现大规模应用的任务。其中,ImageNet是最权威的评测集,每年的ILSVRC催生了大量的优秀深度网络结构,为其他任务提供了基础。在应用领域,人脸、场景的识别等都可以归为分类任务。
二是检测(Detection)。分类任务关心整体,给出的是整张图片的内容描述,而检测则关注特定的物体目标,要求同时获得这一目标的类别信息和位置信息。相比分类,检测给出的是对图片前景和背景的理解,我们需要从背景中分离出感兴趣的目标,并确定这一目标的描述(类别和位置),因而,检测模型的输出是一个列表,列表的每一项使用一个数据组给出检出目标的类别和位置(常用矩形检测框的坐标表示)。
三是分割(Segmentation)。分割包括语义分割(semantic segmentation)和实例分割(instance segmentation),前者是对前背景分离的拓展,要求分离开具有不同语义的图像部分,而后者是检测任务的拓展,要求描述出目标的轮廓(相比检测框更为精细)。分割是对图像的像素级描述,它赋予每个像素类别(实例)意义,适用于理解要求较高的场景,如无人驾驶中对道路和非道路的分割。
发展历程:

介绍:
目标检测,也叫目标提取,是一种基于目标几何和统计特征的图像分割,它将目标的分割和识别合二为一,其准确性和实时性是整个系统的一项重要能力。尤其是在复杂场景中,需要对多个目标进行实时处理时,目标自动提取和识别就显得特别重要。
传统的目标检测一般使用滑动窗口的框架,主要包括三个步骤:
1.利用不同尺寸的滑动窗口框出图中的某一部分作为候选区域
2.提取候选区域相关的视觉特征。比如人脸检测常用的Harr特征,行人检测常用HOG特征等
3.利用分类器进行识别,比如常用的SVM模型。
在传统目标检测算法中,多尺度形变部件模型DPM的效果相对是比较优秀的;在DPM中将物体看成是多个不同组件的结合,其效果不错,但是检测速度相对比较慢。
随着深度学习模型效果的优化,基于深度学习的目标检测算法盖过了传统计算机视觉中的目标检测算法(DPM),从而导致很多之前研究传统目标检测算法的人员转向深度学习,并且现在工业界中应用最多的目标检测方式以深度学习为主。
其中R-CNN是奠定深度学习方向发展目标检测的的基础算法,是第一个真正可以工业级应用的目标检测解决方案,是结合区域提名(Region Proposal)和卷积神经网络(CNN)的一种目标检测算法。
目前主流的目标检测算法主要是基于深度学习模型,主要可以分为两大类:two-stage检测算法和one-stage检测算法。
two-stage检测算法将检测问题划分为两个阶段,首先产生候选区域(region proposals), 然后对候选区域进行分类(一般需要进行位置精修),这类算法实现主要有:R-CNN、SPPNET、Fast R-CNN、Faster R-CNN等。 (首先由算法(algorithm)生成一系列作为样本的候选框,再通过卷积神经网络进行样本(Sample)分类。)
one-stage检测算法是一种极端的检测算法,直接进行区域定位与分类,这类算法实现主要有:SSD、YOLO、FPN等(不需要产生候选框,直接将目标框定位的问题转化为回归问题处理)
目标检测的基本思路和步骤:

目标检测的基本思路:同时解决定位(localization) + 识别(Recognition)。
多任务学习,带有两个输出分支。一个分支用于做图像分类,即全连接+softmax判断目标类别,和单纯图像分类区别在于这里还另外需要一个“背景”类。另一个分支用于判断目标位置,即完成回归任务输出四个数字标记包围盒位置(例如中心点横纵坐标和包围盒长宽),该分支输出结果只有在分类分支判断不为“背景”时才使用。详细结构如下图所示

基于候选区的算法:
基于候选区域(Region Proposal)的,如R-CNN、SPP-net、Fast R-CNN、Faster R-CNN、R-FCN;
使用候选区域方法(region proposal method)创建目标检测的感兴趣区域(ROI)。在选择性搜索(selective search,SS)中,首先将每个像素作为一组。然后,计算每一组的纹理,并将两个最接近的组结合起来。但是为了避免单个区域吞噬其他区域,首先对较小的组进行分组。继续合并区域,直到所有区域都结合在一起。
基于端到端的算法:
端到端指的是输入是原始数据,输出是最后的结果,原来输入端不是直接的原始数据,而是在原始数据中提取的特征,这一点在图像问题上尤为突出,因为图像像素数太多,数据维度高,会产生维度灾难,所以原来一个思路是手工提取图像的一些关键特征,这实际就是就一个降维的过程。基于端到端(End-to-End),无需候选区域(Region Proposal)的,如YOLO、SSD。
总结
对于上述两种方式,基于候选区域的方法在检测准确率和定位精度上占优,基于端到端的算法速度占优。相对于R-CNN系列的“看两眼”(候选框提取和分类),YOLO只需要“看一眼”。总之,目前来说,基于候选区域的方法依然占据上风,但端到端的方法速度上优势明显。
介绍一下yolo算法
其实从yolov1到至今已经发展到了yolov8,但是它的功能不稳定,我个人是比较喜欢用yolov5的,因为yolo就是在出了yolov5之后才开始火的,之前我们都是
用ssd或者fater-rcnn。因为之前的yolo仅仅是速度快,精准度上没有另外的2种算法比较好,yolov7其实基本上和yolov5是一样的,只是在它的基础上改进了一些点,
比如增加了一个辅助头检测,这个概念其实借鉴了Googlenet,重参数化卷积其实就是对bn和卷积层进行融合,形成一个卷积模块,使用elan网络。
但是我个人还是喜欢yolov5的版本。
稍微聊一下一个点,就是yolo的作者在论文发的一些东西,和它给的源码有出入,可能是因为每年都更新的原因。所以我在讲的时候其实是以它的源码解析的
yolov5 可以精简成4部分 输入端,backbone,neck,输出端。
输入端的操作:
yolov5沿用了yolov4的mosaic和mixup的数据增强操作,在yolov5中存在2种mosaic的方式,一个是传统的mosaic使用一张图片加3张随机图片,另外一种
是mosaic9,一张原本的图片加8张随机的图片拼凑在一起,对这些拼接的图片进行,角度,旋转,缩放,剪切和透视的操作进行拼接。在完成数据增强后,它
会从随机从数据集中抽取一张图片,将这个图片与之前mosaic图片进行mixup,生成一个新的图像和标签。达到提高模型鲁棒性和泛化的特性
如果不用mosaic 只需要修改mosaic的超参数为0,就会走letterbox的自适应图片缩放操作,如果图片大于我们的目标尺寸,就让它进行等比例缩放,然后边缘用
黑边做最小填充,如果图片小于我们设定的目标尺寸就直接做边框填充。然后在做一些数据增强的操作,例如上下翻转,左右翻转,随便透视变换,随机hsv变换
自适应边框:
在yolov5的配置文件中是存在3行不同的特征图,每行数值有9个。一般我们希望大的特征图去检测小的目标。
yolov5 中不是只使用默认锚定框,在开始训练之前会对数据集中标注信息进行核查,
计算此数据集标注信息针对默认锚定框的最佳召回率,当最佳召回率大于或等于0.98,则不需要更新锚定框;
如果最佳召回率小于0.98,则需要重新计算符合此数据集的锚定框
重新计算是通过kmean聚类的方法实现的,如果训练效果不好也可以自己手动训练,就是自己统计一下训练数据集的标签框宽高比看看主要分布在哪个范围
最大宽高比多少
backbone:
默认结构中取消了Focus结构,直接替换为: kernel=6, stride=2, padding=2的卷积
CSP1结构更改为C3结构(内部是残差),CSP2结构更改为C3结构(内部没有残差)
将SPP池化更改为SPPF池化
默认激活函数: nn.SiLU
neck:
都采用FPN+PAN的结构
PAN是一种自下而上的特征金字塔结构,是在FPN的基础上进行的改进,相对于FPN有着更好的特征融合效果。
输出端:
采用ciou做边框损失函数
采用diou-nms
分类损失函数使用sigmoid交叉熵损失函数
Yolov3 之所以不使用softmax对每个框进行分类的主要原因:
1.softmax会使得每个框分类一个最大置信度类别,但是实际情况下,目标可能会重复,所以softmax不适合多标签分类
难负样本:
难负样本来平衡正负样本(采用focal loss)。具体地,基于分类损失对负样本抽样,选择较大的top-k作为训练的负样本,以保证正负样本比例接近1:3
map:
对于目标检测来说,每一个类都可以计算出Precision和Recall,
每个类都可以得到一条P-R曲线(P-R曲线,顾名思义,就是P-R的关系曲线图,表示了召回率和准确率之间的关系),
曲线下的面积就是AP(平均精确度)的值。对所有AP的值求平均就是map
Focal loss焦点损失
主要是为了解决一阶段正负比例严重失衡的一个情况,主要是的提出了一种交叉熵加系数的情况,可以使得背景类的交叉熵会相应减少
二分类交叉熵损失和交叉熵损失:sigmoid+bce softmax+ce
维度聚类:
Anchor box 的宽高需要通过先验框来给定,然后通过网络学习转换系数,得到目标检测候选框,如果可以一开始就给定框的维度,网络会更容易预测它
使用k-means的聚类方法来训练回归框,采用iou为kmeans聚类的距离公式
位置预测:
Anchor box中模型不是很稳定,模型的位置预测值可能会发现偏移。导致模型收敛速度很慢,因此在yolov2中不使用offset的方法,
使用预测相对于单元格坐标位置的方法,真实值通过回归限制在0-1之间
迁移学习和微调的区别:
迁移学习我们只优化了我们添加的新分类的权重,保留了原始的模型权重,而微调,2者都改变
空同卷积的核心就是在卷积核中填0,扩大感受野
kj散度一般用于度量2个概率分布函数之间的距离
5.深度卷积核深度可分离卷积:
深度可分离卷积主要分为两个过程,分别为逐通道卷积和逐点卷 一个卷积核负责一个通道,一个通道只被一个卷积核卷积,
逐点卷积用1×1的卷积进行不同通道间的信息融合
优化器
一般企业用最多的是sgd
Yolo模型中定义了一个smart_optimizer函数,用来创建一个优化器,首先定义了3组参数用一个列表代表,分别是,权重带权重衰减的参数/权重不带权重衰减的参数 和 偏置量不带权重衰减的参数。然后加入了4组优化器[adam,amsprop,adamw,sgd]基于torch-optim
库,该函数会根据模型的参数将它们分成三组,并根据优化器名称选择相应的优化器。然后,将三组参数添加到优化器的参数组中.
我们做神经网络的时候,就是求解y=f(wx+b),如何找到w和b呢? (从山上到山下,寻求一种最快的方式)
主要有2个方法,一个是随机搜索,一个是梯度下降算法.随机搜索是指通过加入不同的权重,在对它们进行随机采样,融合把它们输入到损失函数看效果怎么样.梯度下降是初始化W和B.然后根据学习率对W和B进行更新.
SGD+动能+nag(nesterov):
SGD是一种基于随机梯度下降的算法,它的本质是小批次的梯度下降,通过每次的迭代计算当前批次的梯度,然后对参数更新.
它的优点:
1.训练速度块,避免了梯度更新过程中产生计算冗余的物体,对于大数据可以较快收敛
它的缺点
Sgd具有较高的方差,造成数据波动很大
可能会产生误差,导致不能很好的反馈真实梯度,因为它每一次迭代受抽样影响大
对于所有参数都使用一样的学习率,当遇到不常出现迭代特征,就会更新很慢
选择合适的初始learning rate比较困难
SGD优化方向不一定是全局最优的,容易收敛到局部最优。在某些情况下可能被困在鞍点【但是在合适的初始化和学习率设置下,鞍点的影响其实没这么大】
NAG算法相对于Momentum的改进在于,NAG算法相对于Momentum多了一个本次梯度相对上次梯度的变化量,NAG算法才会比Momentum具有更快的收敛速度。
动量法:
动量法是一类从物理中的动量获得启发的优化方法,可以简单理解为:当我们将一个小球从山上滚下来时,没有阻力的话,它的动量会越来越大,但是如果遇到了阻力,速度就会变小
Adam:
Adam 是一种自适应矩估计,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率. 是RMSprop的动能版
对内存需求少
参数的更新不受梯度的伸缩变换影响
超参数具有很好的解释性,且通常无需调整或仅需很少的微调
为不同的参数计算不同的自适应学习率
很适合应用于大规模的数据及参数的场景
适用于不稳定目标函数
适用于梯度稀疏或梯度存在很大噪声的问题
Adam的泛化性没有SGD+动能效果好
RMSprop
RMSprop是一种自适应学习率方法,依旧是基于梯度对位置进行更新。为了消除梯度下降中的摆动,加入了梯度平方的指数加权平均。梯度大的指数加权平均就大,梯度小的指数加权平均就小,保证各维度的梯度都在一个良机,进而减少摆动。
Adamw:
是在Adam+L2正则化的基础上进行改进的算法,加入了权重衰减
经验之谈
对于稀疏数据,尽量使用学习率可自适应的优化方法,不用手动调节,而且最好采用默认值
SGD通常训练时间更长,但是在好的初始化和学习率调度方案的情况下,结果更可靠
如果在意更快的收敛,并且需要训练较深较复杂的网络时,推荐使用学习率自适应的优化方法。
Adadelta,RMSprop,Adam是比较相近的算法,在相似的情况下表现差不多。
在想使用带动量的RMSprop,或者Adam的地方,大多可以使用Adamw取得更好的效果
人脸识别
人脸检测:从待检测的图像获取人脸所在的位置
人脸匹配:从定位出人脸上五官关键点坐标的一项技术
MTCNN(多任务级联卷积神经网络):将人脸区域检测和人脸关键点放到一起,主要由三个子网络p-net,r-net以及o-net构成
P-net:候选框快速生成
R-net:高精度候选框过滤
O-net:边框生成和人脸关键点检测
图像金字塔,边框回归,非极大值抑制
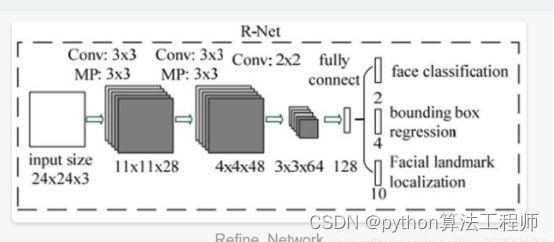

图像进来之后做图像金字塔,缩放图像增强,然后做p-net产生边框,然后做r-net边框精修,最后在做个o-net产生人脸关键点检测
P-net:基本结构就是一个全卷积网络,对于上一步构建的图像金字塔,通过fcn进行初步特征提取和边框标定,然后通过边框回归调整边框位置以及nms过滤多余边框。 它是一个浅层网络,它是为了快速的产生人脸候选框
R-net: 也属于简单的卷积网络,相对于p-net来说增加了一个全连接层,因此对于输入数据的筛选会更加严格,在图片经过p-net之后,会预留多个预测窗口,将所有预测窗口输入到r-net中,进一步过滤比较差的候选框,最终对选定的候选框使用边框回归和极大值抑制
O-net:是一个比较复杂的卷积神经网络,相对于前者而言,使用更复杂的网络结构来保留更改特征信息,从而获得人脸区域定位以及最终的关键点坐标
对于cnn网络结构,影响网络性能因素的主要原因
样本多样性缺失影响网络鉴别能力
相比于其它分类检测网络,人脸检测属于一个二分类,每一层不需要太多过滤
因此作者设计了每层的过滤数量,将5x5的卷积换成2个3x3的卷积核,可以显著的减少计算量,同时将网络中的激活函数改成PRelu
边框回归:直接预测边框坐标,然后采用mse距离损失函数
Mtccn模型中的损失函数是由分类,回归以及定位三部分损失线性组合而来
每个网络都会有三个损失函数:分类使用的是交叉熵损失函数,bbox回归使用的是平方差损失函数、landmark回归使用的也是平方差损失函数
alpha是表示不同网络结构det、box、landmark的损失函数的权重不一,由于Onet要输出landmark,所以Onet的landmark损失权重会比前面两个网络要大。
Face net
通过cnn将人脸映射到欧式空间的特征向量上,计算不同图片人脸特征的距离。使得空间距离直接核图片相似度相关
模型
对于整个FaceNet结构,这里的特征提取可以当作一个黑盒子,可以采用各式各样的网络。最早的FaceNet采用两种深度卷积网络:经典Zeiler&Fergus架构和Google的Inception v1。最新的FaceNet进行了改进,主体模型采用一个极深度网络Inception ResNet -v2,由3个带有残差连接的Inception模块和1个Inception v4模块组成。

三元损失函数:
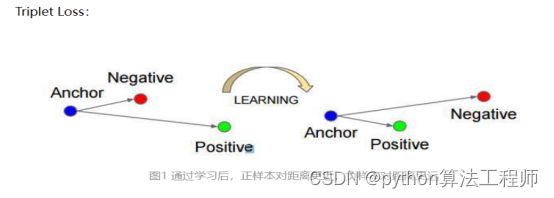
triplet_loss来衡量训练过程中样本之间的距离误差。在训练前或者在线学习中不断给神经网络制造“困难”,即一直在寻找与样本最不像的“自己”,同时寻找与自己最像的“他人”。通过随机梯度下降法,不断缩短自身所有样本的差距,同时尽可能拉大与其他人的差距,最终达到一个最优。通过这样一种嵌入学习(Embedding learing),能对原始的特征提取网络输出层再进一步学习,从而改善特征的表达
三元组的选择
当然最暴力的方法就是对于每个样本,从所有样本中找出离他最近的反例和离它最远的正例,然后进行优化。这种方法有两个弊端:
耗时,基本上选三元组要比训练还要耗时了,且等着吧。
容易受不好的数据的主导,导致得到的模型会很差。
所以,为了解决上述问题,论文中提出了两种策略。
每N步线下在数据的子集上生成一些triplet
在线生成triplet,在每一个mini-batch中选择hard pos/neg 样例。
为了使mini-batch中生成的triplet合理,生成mini-batch的时候,保证每个mini-batch中每个人平均有40张图片。然后随机加一些反例进去。在生成triplet的时候,找出所有的anchor-pos对,然后对每个anchor-pos对找出其hard neg样本。这里,并不是严格的去找hard的anchor-pos对,找出所有的anchor-pos对训练的收敛速度也很快。
与传统的softmax loss相比,triplet_loss直接对距离进行度量和优化,效果更明显。根据其他工程人员经验,实际训练中,可以对softmax loss和triplet_loss进行加权,在线调整权值,达到最优。
网络
新一代的FaceNet采用Inception-ResNet-v2网络,在原有的Google的Inception系列网络的基础上结合了微软的残差网络ResNet思想。其中,残差连接(Residual connections )允许模型中存在shortcuts,可以让研究学者成功地训练更深的神经网络,同时还能明显地简化Inception块
训练策略
训练策略:
残差不是训练极深度神经网络的必要条件,但能明显提升训练速度。
为了防止陷入局部最优,防止训练过程中网络突然“死亡”(梯度都接近于0),一味地下调学习率或者外加batch-normaliztion不是长久之计,因此这里采用了在原来的激活层外连接残差块
Annoy(近似最近邻搜索算法)
在搜索的业务场景下,基于一个现有的数据候选集,需要对新来的一个或者多个数据进行查询,返回在数据候选集中与该查询最相似的 Top K 数据
最朴素的想法就是,每次来了一个新的查询数据,都遍历一遍数据候选集里面的所有数据,计算出该查询的数据 与 数据集中所有元素的相似度或者距离的指标,然后精准地返回 前 K个 相似的数据即可,但是当数据候选集特别大的时候,遍历一遍数据候选集中的元素就会消耗特别多的时间,因此科学家们就开发了各种各样的近似最近邻搜索方法来加快搜索速度,虽然在准确率和召回率上会做出一定的牺牲,但是搜索速度对于暴力搜索会有很大的提高。
用 n 表示现有的文档个数,如果采用暴力搜索的方式,那么每次查询的耗时是 O(n), 采用合适的数据结构可以有效地减少查询的耗时,在 annoy 算法中,作者采用了二叉树这个数据结构来提升查询的效率,目标是把查询的耗时减少至 O(ln(n)).
刚开始的时候,在数据集中随机选择两个点,然后用它们的中垂线来切分整个数据集,于是数据集就被分成了蓝绿两个部分

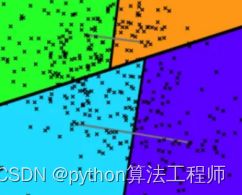
然后再随机两个平面中各选出一个顶点,再用中垂线进行切分,于是,整个平面就被切成了四份。
用一颗二叉树来表示:

后续继续采用同样的方式进行切分,直到每一个平面区域最多拥有 K 个点为止。
全连接网络

全链接一般有3层,输入层,隐藏层和输出层,通过线性转化和激活函数提取图片特征.
CNN网络将卷积、池化后的图像先进行扁平化处理,得到一维的4×4×512向量,将其送入全连接层中进行训练,通过softmax激活函数 得到分类结果
全连接层
全连接层在整个卷积神经网络中起到“分类器”的作用。如果说卷积层、池化层和激活函数等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的“分布式特征表示”映射到样本标记空间的作用。
理解全链接层:
假设你是一只小蚂蚁,你的任务是找小面包。你的视野还比较窄,只能看到很小一片区域。当你找到一片小面包之后,你不知道你找到的是不是全部的小面包,所以你们全部的蚂蚁开了个会,把所有的小面包都拿出来分享了。全连接层就是这个蚂蚁大会~
全链接层通过全链接层之前的卷积,通过线性转化提取图片特征,之后通过全链接的激活函数完成图片分类
为什么要用全局池化替换全链接层,它有什么好处?
我们都知道卷积层后的全连接目的是将卷积输出的二维特征图(feature map)转化成(N*1)一维的一个向量.
根据全连接的目的,我们完全可以利用卷积层代替全连接层,在输入端使用M×M大小的卷积核将数据“扁平化处理”,在使用1×1卷积核对数据进行降维操作,最终卷积核的通道数即是我们预测数据的维度。这样在输入端不将数据进行扁平化处理,还可以使得图片保留其空间信息。
其次卷积层可以兼容不同大小的尺寸输入,类似于全局池化,可以减少参数
早停法(early stopping)
可以达到当训练集上的loss不在减小(即减小的程度小于某个阈值)的时候停止继续训练。
Dropout
Dropout可以比较有效的缓解过拟合的发生,在一定程度上达到正则化的效果
Dropout其实是一个模型瘦身的过程,训练阶段不断的丢失一些节点,对没丢失的节点进行训练,Dropout丢失率的选择策略,在比较深的网络设置丢失率为0.5让它的正则项效果最佳,在浅层网络,可以设丢失率为0.2,因为过多的丢失,可能导致数据对模型的影响过大
Dropout在训练和测试时的区别:Dropout只在训练时产⽣作⽤,是为了减少神经元对部分上层神经元的依赖,类似将多个不同⽹络结构的模型集成起来,减少过拟合⻛险。⽽在测试时,应该⽤整个训练好的模型,因此不需要Dropout
不同层次的卷积都提取什么类型的特征?
Ñ. 浅层卷积 提取边缘特征
Ò. 中层卷积 提取局部特征
Ó. 深层卷积 提取全局特征
卷积层+全局平均池化替代卷积层+全链层
而GAP的思路是使用GAP来替代该全连接层(即使用池化层的方式来降维),更重要的一点是保留了前面各个卷积层和池化层提取到的空间信息\语义信息,所以在实际应用中效果提升也较为明显!,另外,GAP去除了对输入大小的限制!
极大的减少了网络的参数量(原始网络中全连接层参数量占到整个网络参数总量的80%作用)
相当于在网络结构上做正则,防止模型发生过拟合
为什么使用全局平均池化代替全连接层后,网络的收敛速度会变慢?
CNN+FC结构的模型,对于训练过程而言,整个模型的学习压力主要集中在FC层(FC层的参数量占整个模型参数量的80%),此时CNN层学习到的特征更倾向于低层的通用特征,即使CNN层学习到的特征比较低级,强大的FC层也可以通过学习调整参数做到很好的分类
CNN+GAP结构的模型,因为使用GAP代替了FC,模型的参数量骤减,此时模型的学习压力全部前导到CNN层,相比于CNN+FC层,此时的CNN层不仅仅需要学习到低层的通用特征,还要学习到更加高级的分类特征,学习难度变大,网络收敛变慢
综上所述,全局平均池化代替全连接层虽然可以减少模型的参数量,防止模型发生过拟合,但不利于模型的迁移学习,因为CNN+GAP的结构使得很多参数“固化”在卷积层中,增加新的分类时,意味着相当数量的卷积层特征需要重新进行调整(学习难度较大)
而全连接层则可以更好的进行迁移学习,因为它的参数调整很大一部分是在全连接层中,迁移的时候虽然卷积层的参数也会调整,但是相对来说要小很多
目标追踪
目标追踪
目前主流的目标跟踪算法都是基于Tracking-by-Detecton策略,即基于目标检测的结果来进行目标跟踪。DeepSORT运用的就是这个策略,上面的视频是DeepSORT对人群进行跟踪的结果,每个bbox左上角的数字是用来标识某个人的唯一ID号。
这里就有个问题,视频中不同时刻的同一个人,位置发生了变化,那么是如何关联上的呢?答案就是匈牙利算法和卡尔曼滤波。
匈牙利算法可以告诉我们当前帧的某个目标,是否与前一帧的某个目标相同。
卡尔曼滤波可以基于目标前一时刻的位置,来预测当前时刻的位置,并且可以比传感器(在目标跟踪中即目标检测器,比如Yolo等)更准确的估计目标的位置。
匈牙利算法(https://zhuanlan.zhihu.com/p/459758723):
首先,先介绍一下什么是分配问题(Assignment Problem):假设有N个人和N个任务,每个任务可以任意分配给不同的人,已知每个人完成每个任务要花费的代价不尽相同,那么如何分配可以使得总的代价最小。
在DeepSORT中,匈牙利算法用来将前一帧中的跟踪框tracks与当前帧中的检测框detections进行关联,通过外观信息(appearance information)和马氏距离(Mahalanobis distance),或者IOU来计算代价矩阵
什么是马氏距离
马氏距离(Mahalanobis Distance)是一种距离的度量,可以看作是欧氏距离的一种修正,修正了欧式距离中各个维度尺度不一致且相关的问题
欧式距离近就一定相似?
先举个比较常用的例子,身高和体重,这两个变量拥有不同的单位标准,也就是有不同的scale。比如身高用毫米计算,而体重用千克计算,显然差10mm的身高与差10kg的体重是完全不同的。但在普通的欧氏距离中,这将会算作相同的差距。
归一化后欧氏距离近就一定相似?
当然我们可以先做归一化来消除这种维度间scale不同的问题,但是样本分布也会影响分类
匈牙利算法可以帮助您匹配由cost metric计算后的两组元素
跟踪边界框时,成本可以是 IOU、欧几里德距离、卷积相似度或您自己的损失函数(可结合)
该算法分 5 步工作:我们首先对矩阵进行缩减,然后交叉 0,最后再次缩减,直到我们可以对元素进行配对
如果你有一个最大化问题,比如 IOU,你总是可以把它变成一个最小化问题
如果您有 NxM 矩阵,则可以通过添加具有最大值的列来使其成为 NxN 矩阵
编码时,可以通过矩阵调用sklearn中的函数linear_assignment(),直接得到算法的输出
卡尔曼滤波
卡尔曼滤波被广泛应用于无人机、自动驾驶、卫星导航等领域,简单来说,其作用就是基于传感器的测量值来更新预测值,以达到更精确的估计。
假设我们要跟踪小车的位置变化,如下图所示,蓝色的分布是卡尔曼滤波预测值,棕色的分布是传感器的测量值,灰色的分布就是预测值基于测量值更新后的最优估计
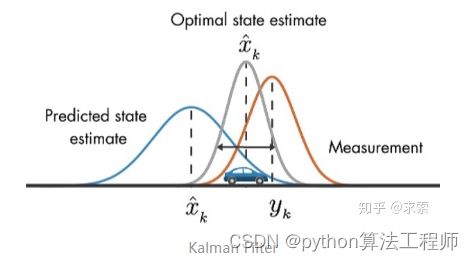
在目标跟踪中,需要估计track的以下两个状态:
均值(Mean):表示目标的位置信息,由bbox的中心坐标 (cx, cy),宽高比r,高h,以及各自的速度变化值组成,由8维向量表示为 x = [cx, cy, r, h, vx, vy, vr, vh],各个速度值初始化为0。
协方差(Covariance ):表示目标位置信息的不确定性,由8x8的对角矩阵表示,矩阵中数字越大则表明不确定性越大,可以以任意值初始化。
卡尔曼滤波分为两个阶段:(1) 预测track在下一时刻的位置,(2) 基于detection来更新预测的位置。
DeepSort工作流程
DeepSORT对每一帧的处理流程如下:
检测器得到bbox → 生成detections → 卡尔曼滤波预测→ 使用匈牙利算法将预测后的tracks和当前帧中的detecions进行匹配(级联匹配和IOU匹配) → 卡尔曼滤波更新
Frame 0:检测器检测到了3个detections,当前没有任何tracks,将这3个detections初始化为tracks
Frame 1:检测器又检测到了3个detections,对于Frame 0中的tracks,先进行预测得到新的tracks,然后使用匈牙利算法将新的tracks与detections进行匹配,得到(track, detection)匹配对,最后用每对中的detection更新对应的track
目标检测评估指标
 混淆矩阵
混淆矩阵
Roc曲线 auc
Ap的概念,所有被预测的物体会根据它们的置信度排名,然后如果它们的真实值大于等于iou 0.5表明预测正确
NMS即non maximum suppression即非极大抑制,顾名思义就是抑制不是极大值的元素,搜索局部的极大值
Fps:每秒处理图像的帧数
Flops:每秒浮点运算次数、每秒峰值速度
GOPS:衡量处理器计算能力的指标单位
目标分割
- u-net
前言
图像的语义分割是将输入图像中的每个像素分配一个语义类别,以得到像素化的密集分类。
U-Net是比较早的使用全卷积网络进行语义分割的算法之一,论文中使用包含压缩路径和扩展路径的对称U形结构在当时非常具有创新性,且一定程度上影响了后面若干个分割网络的设计,该网络的名字也是取自其U形形状。
算法详解
一般的语义分割架构可以被认为是一个编码器-解码器网络。编码器通常是一个预训练的分类网络,像 VGG、ResNet,然后是一个解码器网络。这些架构不同的地方主要在于解码器网络。解码器的任务是将编码器学习到的可判别特征(较低分辨率)从语义上投影到像素空间(较高分辨率),以获得密集分类。
不同于分类任务中网络的最终结果(对图像分类的概率)是唯一重要的事,语义分割不仅需要在像素级有判别能力,还需要有能将编码器在不同阶段学到的可判别特征投影到像素空间的机制。不同的架构采用不同的机制(跳跃连接、金字塔池化等)作为解码机制的一部分
1.1u-net的网络结构
它是一个全卷积网络,网络的输入是一张 572×572 的边缘经过镜像操作的图片(input image tile),网络的左侧(红色虚线)是由卷积和Max Pooling构成的一系列降采样操作,论文中将这一部分叫做压缩路径。压缩路径由4个block组成,每个block使用了3个有效卷积和1个Max Pooling降采样,每次降采样之后Feature Map的个数乘2,因此有了图中所示的Feature Map尺寸变化。最终得到了尺寸为 32×32 的Feature Map。
网络的右侧部分(绿色虚线)在论文中叫做扩展路径(expansive path)。同样由4个block组成,每个block开始之前通过反卷积将Feature Map的尺寸乘2,同时将其个数减半(最后一层略有不同),然后和左侧对称的压缩路径的Feature Map合并,由于左侧压缩路径和右侧扩展路径的Feature Map的尺寸不一样,U-Net是通过将压缩路径的Feature Map裁剪到和扩展路径相同尺寸的Feature Map进行归一化。扩展路径的卷积操作依旧使用的是有效卷积操作,最终得到的Feature Map的尺寸是 388×388 。由于该任务是一个二分类任务,所以网络有两个输出Feature Map。
- deeplabv1
Deeplab是一个专门做语义分割的模型
Deeplab v1 是基于vgg16网络进行修改。

首先,将5个池化层的最后两个池化层的步长为2改成步长为1核为3,使得卷积层整体输出的步长从32降到8
为什么要修改pooling,实际上池化层是神经网络中的一个经典结构
1.特征不变性:可以容忍一些特征微小的位移
2.特征降维:缩小特征层的尺寸
3.在一定层度上防止过拟合
池化层还有另一个重要作用,快速扩大感受野。为什么要扩大感受野呢?为了利用更多的上下文信息进行分析
既然pooling这么好用,为什么要去掉俩呢?这个问题需要从头捋。先说传统(早期)DCNN,主要用来解决图片的分类问题,举个栗子,对于下边这张语义分割的图,传统模型只需要指出图片中有没有小轿车,至于小轿车在哪儿,不care。这就需要网络网络具有平移不变性。我们都知道,卷积本身就具有平移不变性,而pooling可以进一步增强网络的这一特性,因为pooling本身就是一个模糊位置的过程。所以pooling对于传统DCNN可以说非常nice了。
再来说语义分割。语义分割是一个端对端的问题,需要对每个像素进行精确的分类,对像素的位置很敏感,是个精细活儿。这就很尴尬了,pooling是一个不断丢失位置信息的过程,而语义分割又需要这些信息,矛盾就产生了。没办法,只好去掉pooling喽。全去掉行不行,理论上是可行的,实际使用嘛,一来显卡没那么大的内存,二来费时间。所以只去掉了两层。
(PS:在DeepLab V1原文中,作者还指出一个问题,使用太多的pooling,特征层尺寸太小,包含的特征太稀疏了,不利于语义分割。)
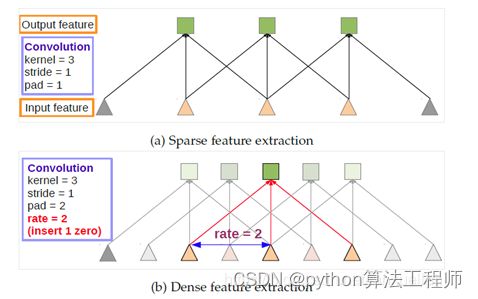
由于修改后的2个池化层影响了其后面的卷积层,为了保持原来的感受野。将其改成空洞卷积,它相比于传统卷积,可以在不增加计算量的情况下扩大感受野
空洞卷积与传统卷积的区别在于,传统卷积是三连抽,感受野是3,空洞卷积是跳着抽,也就是使用图中的rate,感受野一下扩大到了5(rate=2),相当于两个传统卷积,而通过调整rate可以自由选择感受野。这样感受野的问题就解决了。
另外,原文指出,空洞卷积的优势在于增加了特征的密度。盯着上边这张图我想了很久这个问题,虽然你画的密,但是卷积都是一对一的输入多大输出多大,怎么空洞卷积的特征就密了呢。~~一道闪电划过后,~~我终于想明白了,这张图你不能单独看,上边的传统卷积是经过pooling以后的第一个卷积层,而下边卷积输入的浅粉色三角正是被pooling掉的像素。所以,下边的输出是上边的两倍,特征多出了一倍当然密啦
它也是一个全卷积网络,因此将全连接层替换成1x1的卷积层
使用双线性插值上采样
使用条件随机场CRF使得最后分类结果边缘更加精细
为了得到更好的边界信息,在输入图像和前四个最大池化层的后添加128x3x3和128x1x1,然后拼接到主网络的最后一层(相对于多了128x5=650跟通道),达到 多尺度预测 效果
- deeplabv2
在DeepLab V2中,可能是觉得VGG16表达能力有限,于是大神换用了更复杂,表达能力更强的ResNet-101
在V2中,大神同样对ResNet动了刀,刀法和V1相同。V2的贡献在于更加灵活的使用了空洞卷积,提出了空洞空间金字塔池化ASPP

虽然名字挺复杂,但是看图就能轻易理解ASPP作用,说白了就是利用空洞卷积的优势,从不同的尺度上提取特征。这么做的原因也很简单,因为相同的事物在同一张图或不同图像中存在尺度上的差异。还是以这张图为例,图中的树存在多种尺寸,使用ASPP就能更好的对这些树进行分类。
至于ASPP如何融合到ResNet中,看图说话。将VGG16的conv6,换成不同rate的空洞卷积,再跟上conv7,8,最后做个大融合(对应相加或1*1卷积)就OK了,在模型最后进行像素分类之前增加一个类似 Inception 的结构,包含不同 rate(空洞间隔) 的 空洞卷积,增强模型识别不同尺寸的同一物体的能力:

- deeplabv3
什么是deeplapv3 模型
DeeplabV3+被认为是语义分割的新高峰,主要是因为这个模型的效果非常的好呀。
DeepLabv3+主要在模型的架构上作文章,为了融合多尺度信息,其引入了语义分割常用的encoder-decoder形式。在 encoder-decoder 架构中,引入可任意控制编码器提取特征的分辨率,通过空洞卷积平衡精度和耗时。
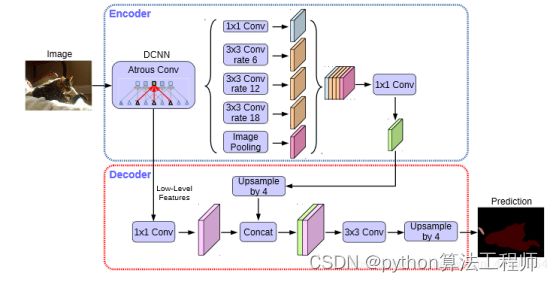
网络骨架还是基于v2 使用renet101,同时,v3也做了三个贡献,先来说最后一个,舍弃了CRF,因为分类结果精度已经提高到不需要CRF了。在残差块中使用多网格方法(MultiGrid),从而引入不同的空洞率

另外,改进了ASPP,将bn加入了ASPP模块:在空洞卷积之后使用batch normalization
我们发现增加了1*1卷积分支和池化分支出现了一系列问题。增加这两个分支是为了解决使用空洞卷积带来的问题,随着rate的增大,一次空洞卷积覆盖到的有效像素(特征层本身的像素,相应的补零像素为非有效像素)会逐渐减小到1。这就与我们的初衷(获取更大范围的特征)相背离了。所以为了解决这个问题,aspp加入了全局池化层+卷积1x1+双线性插值上采样的模块

使用11的卷积,也就是当rate增大以后出现极端情况,当空洞卷积的rate和feature map大小一致时,33卷积会退化成1x1
增加image pooling,可以叫做全局池化,来补充全局特征。具体做法是对每一个通道的像素取平均,之后再上采样到原来的分辨率
卷积神经网络的特性
卷积核就是图像处理时,给定输入图像,输入图像中一个小区域中像素加权平均后成为输出图像中的每个对应像素,其中权值由一个函数定义,这个函数称为卷积核。又称滤波器。
输入矩阵格式:四个维度,依次为:样本数、图像高度、图像宽度、图像通道数
输出矩阵格式:与输出矩阵的维度顺序和含义相同,但是后三个维度(图像高度、图像宽度、图像通道数)的尺寸发生变化。
权重矩阵(卷积核)格式:同样是四个维度,但维度的含义与上面两者都不同,为:卷积核高度、卷积核宽度、输入通道数、输出通道数(卷积核个数)
输入矩阵、权重矩阵、输出矩阵这三者之间的相互决定关系
卷积核的输入通道数(in depth)由输入矩阵的通道数所决定。(红色标注)
输出矩阵的通道数(out depth)由卷积核的输出通道数所决定。(绿色标注)
输出矩阵的高度和宽度(height, width)这两个维度的尺寸由输入矩阵、卷积核、扫描方式所共同决定
卷积神经网络的2个特性
局部连接:每个神经元仅与输入的一块神经元连接,这块局部地区我们称为”感受野”
权重共享:同层的每个神经元具有相同的权重

Padding:填充 H: 图片高度 W: 图片宽度 dilation:膨胀卷积 kernel_size: 核大小 stride: 步长
多通道+多卷积模式:
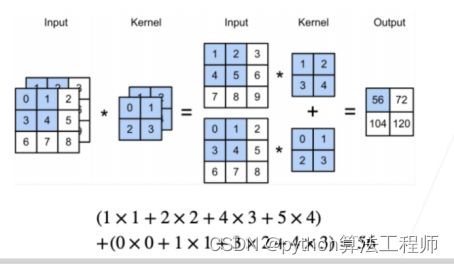
输入一3个通道,有2个卷积, 对于每个卷积核,先输入3个给通道分别核2个卷积核相乘,在将2个卷积的结果相加
输出图像通道数等于卷积核数量
1x1 卷积:
1.降维和升维:由于1x1不会改变图片的宽和高,最直观的变化就是改变通道,可以将原本的数据量增加或者减少,其实就是改变了通道数的维度
2.现了跨通道的信息组合,并增加了非线性特征
3.减少参数 (192 × (1×1×64) +192 × (3×3×128) + 192 × (5×5×32) = 387072
192 × (1×1×64) +(192×1×1×96+ 96 × 3×3×128)+(192×1×1×16+16×5×5×32)= 157184)
感受野计算

k=1 1+3-1
k=5 10+(3-1)1X2X1x2
池化层的特点
1.池化层不会更新参数
2.通道数不发生变化,是独立进行的
3.对微小的位置变化具有鲁棒性, 当数据发生微小的变化,池化任然保持不变
池化的好处
a.鲁棒性
b.下采样减少计算量
c.扩大感受野
d.抑制过拟合,降低参数数量
池化有那些操作,它们是怎么运行的
平均池化:计算图像区域的平均值,并以此作为该区域池化后的值
全局平均池化:对于输出的每一个通道的特征图的所有像素计算一个 平均 值,经过 全局平均池化 之后就得到一个 维度
自适应池化:自适应池化Adaptive Pooling会根据输入的参数来控制输出output_size
最大池化:就是让四个像素格子中,选择保留一个最大的像素,舍弃其余三个
批归一化
在模型训练的时候,利用小批量的均值和标准差,不断的调整神经网络的中间输出,使得神经网络各层的中间输出的数值趋于平稳
感受野和膨胀卷积

膨胀卷积是把感受野放大了

和drop out的区别
Droup是随机的,这个是固定的,它一定是某几个位置为0,它可能有点噪声,但是周边是局部的。你合并的时候其实可以把这些噪声可以过滤掉,类似与drop-out
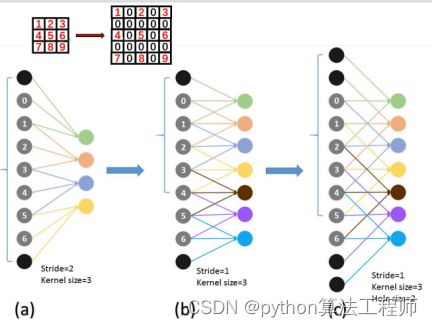
膨胀卷积核尺寸=膨胀系数*(原始卷积核尺寸-1)+1
膨胀卷积(Dilated Convolution)的存在是为了解决一下几个问题的:
普通的数据上采样层参数不可学习;
内部数据结构丢失,空间层级化信息丢失;
小物体信息无法重建。
yolov1
Yolov1:
从现在看可能不是很好,但是其实在哪个年代,其实还可以,因为哪个年代都两阶段目标检测为主,而且哪个时候,faster-rcnn还没太火,它等于是从0开始的。它的思路是直接预测边框,在yolov1 没有anchor的概念,他这个候选框的概念和我们在ssd和rpn不一样,我们说的anchor一定是有,位置和大小比例的。我们把anchor称为先验框,你只需要告诉我feature map的大小和anchor的尺度信息,可以画出任意一层先验框的位置,但是在yolov1中,你没办法画的。因为没有anchor的概念,实际上,它处于一种摸索的阶段,它直接回归和预测。 因为没有anchor的概念导致这些计算都没了,所以它贼快。
它在整个网络之间,会把背景认为物体,我们为什么会把背景认为物体呢,为什么会把噪声认为物体呢,实际上在某个局部区域,这个噪声信息比较重,所以它认为是个物体,但是从全局的角度来讲,局部信息可能不是物体,就是背景。所以我们如果想背景认为物体减少,我们就可以从局部信息下手,我们就可以预测的时候加一点非局部信息,比如说我们增加更大感受野的信息,提取合并在这,一起去看,膨胀卷积,另外我们也可以用全链接,全链接的本质是全局特征的融合。 yolov1 里面用的就是全链接的思路,ssd里用是的是膨胀卷积,把周围体系加强,yolo的其它体系用的是fpn体系,就是把大的局部特征和小的局部特征融合,这样我们判断的会更精准。(比如一个图片上有一只鸟,然后天空中有一群鸟,那么这个是鸟的信息就会局部增加) 针对小物体实际上是这种方式。
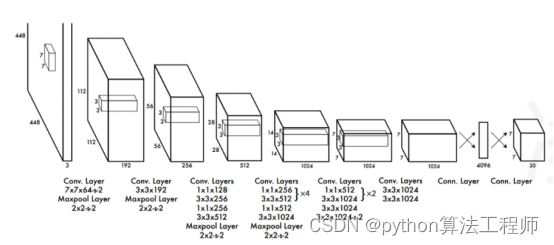
第二个就是泛化能力还可以,输入448x448,然后运行一个卷积神经网络在图片上。第三步,输出坐标值做nms
它有边框的概念实际上,它有网格的概念,它会把图片分成很多个网格区域。就是把feature map上映射很多个点,然后这些点对应图片上的一个区域。
它是做多分枝网格,通过不同颜色区分类别,然后做边框加置信度,它认为每个网格中有2个边框。但是它又不属于anchor,位置都不知,只知道在网格交叉的边缘存在2个网格,它是这样构建先验框的。他是之间回归预测这些框,然后在分类回归合并。 这种思想叫统一检测,效果很差。但是实时性很好。
1.将图像划分为nxn个网格单元,如果一个物体的中心位于这个网格单元内,这个网格单元就负责检测这个物体。
2.中心点坐标相当于图片的宽高比,置信度(是否包含物体)
3.每个单元格还需要预测c个类别的概率
4.每个单元的类别信息 和每个边框置信度信息相乘 就得到置信度类别分数
网络架构(YOLO网络借鉴了GoogleLeNet图像分类模型(也就是Inception v1)。不同的是,YOLO并没有采用Inception模块,而是简单采用1x1 下采样层后跟3x3卷积层)
Yolo的存在漏检问题,因为它的框限死了,其实很少,如果物体重叠或者很小是检测不出来的,漏捡会非常严重,但是它速度非常快
它的结果输出之后
用全局特征信息去辅助局部特征的预测,这是后续网络发展的趋势
这样可以兼顾达到,我可以做局部特征的同时还会考虑到全局的影响。
YolV1的最大优点就是 运行快,背景预测错误情况少
缺点 实际效果差,小物体预测效果不好,漏检很严重,特别是小物体。不是特征不够纯粹是框不够,它不是每个框对应每个特征。 ssd检测小物体不好是因为,它的特征不好,它有可能小物体的特征提取不到,有可能会把小物体的特征当成噪音过滤掉了。
Yolov1的回归预测 非常不合理 它只考虑了局部特征,直接预测物体中心点和单元格边框的高度和宽度百分比。
yolov2
olov2 和 yolov1是同年出来的,yoloV2 没有太多新的东西,主要是对yoloV1做了改进
1.从精度上改变,基本上和faster-rcnn和ssd持平 2.更快:网络结构方面做了调整 3.对损失函数做了一个改变

1.加入了批归一化 2.yolov1中是448x448,骨干迁移过来的,goglenet本来是24x24的,迁移过来分辨率是偏低的,采用更高分辨率的分类模型 3和4.把全链接换成全卷积神经网络和 瞄框 5.网络结构新的改进 6.维度处理 7.位置处理 8.残差 9.多尺度训练 10 更高分辨率的目标检测
归一化:
每一层卷积加入batch nor,有助于规范化模型,防止过拟合
高分辨率的分类模型:
一般的目标检测方法中,会用imagenet预训练模型提取特征,比如VGG和alexnet,但是输入的图片会被resize到256x256,这样会导致分辨率不够,目标检测困难
Yolov2中定义了darknet网络,它是直接将图片输入的分辨率改成448x448,然后在imagenet上在训练,训练后的网络可以适应高分辨的图像,应用检测时,对部分网络进行微调
全链接换卷积:
借鉴 faster r-cnn中的anchor思想,产生多个目标候选框,通过这种方式提升模型的召回率
删除全部的全链接层,去掉最后的池化层,确保图形有更高的分辨率,然后缩减网络让图片分辨率达到416x416,这样最后的特征图为13x13
维度聚类:
Anchor box 的宽高需要通过先验框来给定,然后通过网络学习转换系数,得到目标检测候选框,如果可以一开始就给定框的维度,网络会更容易预测它
使用k-means的聚类方法来训练回归框,采用iou为kmeans聚类的距离公式
位置预测:
Anchor box中模型不是很稳定,模型的位置预测值可能会发现偏移。导致模型收敛速度很慢,因此在yolov2中不使用offset的方法,使用预测相对于单元格坐标位置的方法,真实值通过回归限制在0-1之间
细粒度特征
加入了转移层,把浅层特征和深层特征直接融合,类似resnet的网络结构
其实就是特征按行和列分特征进行采样,有点类似膨胀卷积,然后做特征融合。
多尺度训练
小尺度学习上,借鉴上大尺度学的,动态调整,每个10 epach后随机选新的图片size训练。
速度的接近ssd速度的3倍,很大的收益来自它的骨干网络

检测网络的训练,将分类网络的最后一个卷积层去掉,换成3个3x3x1024的卷积层,每个卷积层后跟一个1x1的卷积层,输出维度为检测需要的数目
我们训练160个epoch之后损失率就不下降了,可能是因为学习率太大了出现抖动不下降,我们可以调小学习率。 如果模型不抖动,就收敛在哪个位置了,我们可以调大学习率, 我们也可以做一些,它学习到这个位置之后,呈现某种趋势,学习率没有收敛,但是又抖动的很大,有可能数据分布不太好。我们可以考虑把数据打乱一下,或者把批次打乱。(小批次学习会导致不收敛)
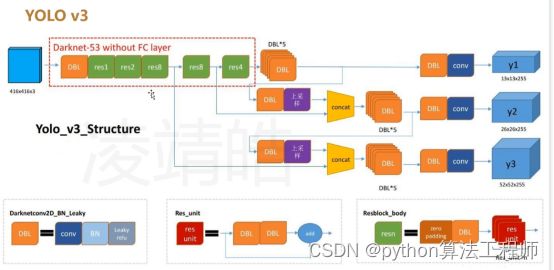
yolov3
Yolov3对yolov1和yolov2的内容即有保留又有改进
从yolov1 开始 yolo算法都是通过划分单元格的方式来检测的,只是划分数量不同
全部采用leaky relu激活函数
采用端到端
从yolov2 开始将bn和leaky relu放到每个卷积层后
从yolov2 开始,多尺度训练,在速度和准确率之间达到平衡
从yolov2 开始,位置信息的预测全都是对位于单元格的位置信息
Yolov3 借鉴了大量的其它网络结构优点
主要改进就是骨干网络的提升,从v2的darknet-19 到v3的-53,还提供轻量高速的网络tiny-darknet
借鉴ssd/fpn在不同尺度的feature map上提取特征信息,相比于v2仅通过多尺度图像训练,v3对于小目标的检测效果更好
Anchor box 从v2的5个变成 9个
将线性分类器换成softmax
对损失函数进行了修改
是在yolov2基础上改动的,最大的变动是分类损失换成了二分交叉熵,这是由于yolov3中剔除了softmax改用logistic。

将池化换成卷积,然后加了一点残差结构
多尺度的业务场景:
图像金字塔。人为输入尺度大小不同的图像,让模型去学
局部特征:期望网络自己去学会
等级制度特征金字塔:用浅层的去预测小的特征,中层去预测中的图片大小,深层去预测大物体
特征金字塔网络(fpn):把周边区域做辅助判断局部特征
刚开始的时候是ssd,为什么yolo比ssd好呢,因为ssd没有一个主线 dssd其实用了,但是不是一个作者
Yolov3 之所以不使用softmax对每个框进行分类的主要原因:
1.softmax会使得每个框分类一个最大置信度类别,但是实际情况下,目标可能会重复,所以softmax不适合多标签分类
2.Softmax可以被多个独立的逻辑回归分类器替代,而且效果不会下降
yolov4
Yolov4的改进点:
输入端:数据增强,主干网络(dtopout 改进),neck指:特征的融合和提取/ head:模型的决策,PAN和SPP
边框的回归
数据增强:
mixup:把2张图片合并成一张
cutmix:截取图片粘贴到主头像
Mosaic(马赛克):选4张图像上左上右下左下右,过程中可以做旋转,随机缩放,排布, 马赛克是参考cutmix数据增强的方式,但是cutmix只使用2张图片。
Blur: 将图片锐化
Yolov4对coco数据做了分析,将像素32x32的为小,中等是32x96 大的是大于96

小样本的量蛮大的,但是在真正的模型学习中,没有大和中的多。这种不均衡导致很难学。
Cspdarknet53 是在yolov3 darknet53的基础上,借鉴了cspnet,主要从网络结构设计的角度解决推理过程中计算量大的问题。计算量过高的主要问题是网络结构的梯度重复导致的,所以在csp结构中,采取输入层特征划分为2部分,一部分做普通特征提取,另外一个直接略过
连接网络类似 shufflenet V2
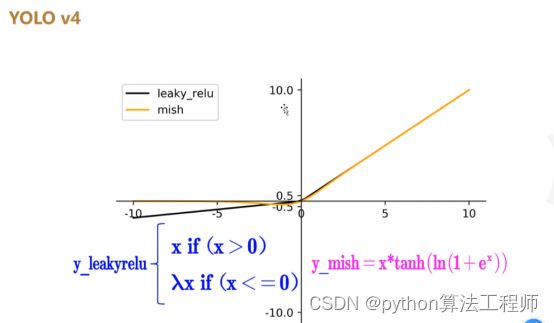
将darnet53中的激活函数leakyrelu更换为Mish激活函数
将dropout更改为dropBlock结构缓解过拟合(借鉴cutout数据增强方式-随机剪贴后把该地区置于灰色)
当值比较很大的时候基本可以匹配,当为负数的时候,相对缓和一些不是直接是0,缺点计算量很大,太复杂。
图片有空间概念所以我们用dropblock,作用在所有特征上。
借鉴panet 在fpn的基础上做一个下采样融合
边框转换存在一个边缘密度的问题针对中心点落在单元格边缘位置的物体不好预测
使用了c-iou和d-iou-nms
yolov5
20年开始,我们用的最多的模型
输入端:数据增强,自适应瞄框计算,自适应图像缩放
主干网络:focus结构,csp+darkNet
Neck:FPN+PAN,SPP
更换giou损失
v4和v5差不多 为什么v5比v4火,主要是作者原因,v5 比v4 更简单一点点,小了一点卷积
激活函数还是用leakyrelu
Focus 和膨胀卷积 和在yolov2中提到的把浅层特征合并到深层特征一致,一种特征划分的方式,现在基本不用了,这里用主要是降低featmap的大小,主要就是做下采样但是不会丢失信息的大小。
Csp1 和 csp2
倍数的关系,csp1中用的是残差,csp2中用的是普通卷积,细节点在与bn,批归一化 激活在拼接,这里放后面了,减少计算量。
自适应瞄框计算:将先验框高宽比的程序代码集成到整个训练过程中
自适应图片缩放:一般情况下,我们会将图像缩放到常用尺寸,然后在进行后续的网络执行,但是如果填充的比较多,会出现较多的冗余信息,影响推理速度。因此在yoloV5中做了自适应的处理,以希望添加最少像素的黑边。 yolov5里面填充的是灰色,仅在推理预测的时候添加。

标签平滑是一个在分类问题中防止过拟合的方法
多分类任务中,神经网络会输出一个当前数据对应于各个类别的置信度分数,将这些分数通过softmax进行归一化处理,最终会得到当前数据属于每个类别的概率,然后计算交叉熵损失函数,神经网络会促使自身往正确标签和错误标签差值最大的方向学习,在训练数据较少,不足以表征所有的样本特征的情况下,会导致网络过拟合。label smoothing可以解决上述问题,这是一种正则化策略,主要是通过soft one-hot来加入噪声,减少了真实样本标签的类别在计算损失函数时的权重,最终起到抑制过拟合的效果
YOLOv5更新部分内容(相比于ppt所讲的v5版本以及其它版本):
-1. 默认激活函数: nn.SiLU
-2. 默认结构中取消了Focus结构,直接替换为: kernel=6, stride=2, padding=2的卷积
-3. CSP1结构更改为C3结构(内部是残差),CSP2结构更改为C3结构(内部没有残差)
-4. 将SPP池化更改为SPPF池化
-5. 边框坐标映射关系发生了更改(xy类似v4版本, wh改成(2*sigmoid(tw))**2 * Pw, 原始是: e^tw * Pw
-6. 分类概率计算方式更改为sigmoid
-7. 训练过程中,数据增强:mosaic、mixup(可选)、随机HSV增强、随机垂直方向翻转、随机水平方向翻转、cutout(可选)、OpenCV矩阵增强(平移、旋转、剪切、缩放、透视)
-8. 训练过程中,学习率使用warmup的方式,先增加学习率(随着批次增加),然后降低学习率(随着epoch降低)
-9. 训练过程中,多尺度训练是每个batch一个尺度,尺度范围:[320,960] – 640
-10. 边框回归转换公式发生了变化,cx = grid_x + px.sigmoid() * 2 - 0.5, w = pw * (pw.sigmoid() * 2) ** 2
-11. 回归损失函数使用CIoU Loss
-12. 分类损失函数使用sigmoid交叉熵损失函数
SSD
SSD(单步多框目标检测)
一.简介

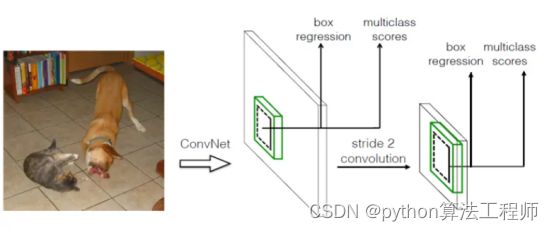
本文讲解的是SSD算法,SSD算法属于one-stage方法,MultiBox指明了SSD是多框预测。从上图也可以看到,SSD算法在准确度和速度(除了SSD512)上都比Yolo要好很多。下图给出了不同算法的基本框架图,对于Faster R-CNN,其先通过CNN得到候选框,然后再进行图片分类与候选框回归损失,而Yolo与SSD可以一步到位完成检测。相比Yolo,SSD采用CNN来直接进行检测,而不是像Yolo那样在全连接层之后做检测。其实采用卷积直接做检测只是SSD相比Yolo的其中一个不同点,另外还有两个重要的改变,一是SSD提取了不同尺度的特征图来做检测,大尺度特征图(较靠前的特征图)可以用来检测小物体,而小尺度特征图(较靠后的特征图)用来检测大物体;二是SSD采用了不同尺度和长宽比的先验框(Prior boxes, Default boxes,在Faster R-CNN中叫做锚,Anchors)。Yolo算法缺点是难以检测小目标,而且定位不准,但是这几点重要改进使得SSD在一定程度上克服这些缺点。

1.One-Stage
2.均匀的密集抽样
瞄框(anchors boxs)
不同尺度抽样
3.不同scale(规模)尺度特征图抽样
4.对于小目标检测效果不错
5.预测速度快
6.训练快(正负样本不均衡)
二.设计理念
SSD和Yolo一样都是采用一个CNN网络来进行检测,但是却采用了多尺度的特征图。下面将SSD核心设计理念总结为以下三点
(1)重用Faster R-CNN的Anchors机制
在feature map上提取各种不同尺度大小的default box,也就是类似Anchor的一系列大小固定的框。不同feature map上尺度是一样的(在feature map上的尺度大小是一样的,但是映射到原始图中,大小是不一样的)
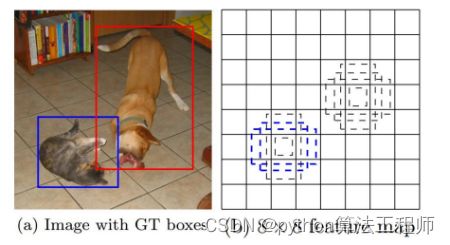
(2)采用多尺度特征图用于检测
所谓多尺度采用大小不同的特征图,CNN网络一般前面的特征图比较大,后面比较小,会逐渐采用步长为2的卷积或者池化来降低特征图大小,一个比较大的特征图和一个比较小的特征图,它们都用来做检测。这样做的好处是比较大的特征图来用来检测相对较小的目标,而小的特征图负责检测大目标,如图所示,8x8的特征图可以划分更多的单元,但是其每个单元的先验框尺度比较小。
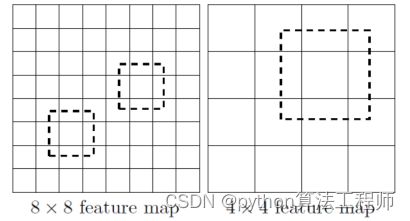
这样做的好处:
1.减少计算与内存的需求;
2.最终提取的feature map在某种程度上具备平移和尺度不变性,契合分类的业务场景要求。
在目标检测场景中,经常需要处理不同尺度的物体,在某些网络中,会通过将图像转换为不同尺度大小的图像独立的通过网络处理,然后将这些不同尺度的图像结果合并,但是实际上,在同一个网络中,对不同层次上的feature maps进行特征的处理实际上效果是一样的,并且所有尺度的物体处理参数是共享的,计算会更快
 SSD提取多尺度特征来进行检测,所以需要在VGG16模型基础上修改和增加一些额外的模块。VGG16模型主体包括5个maxpool层,每个maxpool层后特征图尺度降低1/2,可以看成5个stage,每个stage都是3x3的卷积层,比如最后一个stage包含3个3x3卷积层,分别记为Conv5_1,Conv5_2,Conv5_3(5是stage编号,而后面数字表示卷积层编号)。图上所示的Conv4_3对应的就是第4个stage的第3个卷积层的输出(第4个maxpool层前面一层),对应的特征图大小为38x38.这是提取的第一个特征.
SSD提取多尺度特征来进行检测,所以需要在VGG16模型基础上修改和增加一些额外的模块。VGG16模型主体包括5个maxpool层,每个maxpool层后特征图尺度降低1/2,可以看成5个stage,每个stage都是3x3的卷积层,比如最后一个stage包含3个3x3卷积层,分别记为Conv5_1,Conv5_2,Conv5_3(5是stage编号,而后面数字表示卷积层编号)。图上所示的Conv4_3对应的就是第4个stage的第3个卷积层的输出(第4个maxpool层前面一层),对应的特征图大小为38x38.这是提取的第一个特征.
对于Con4_3的数据提取的时候,会先对feature map做一个L2 norm的操作,因为层次比较靠前,防止出现数据值过大的情况.
相比原来的VGG16,这里将第5个maxpool层的大小从2x2-s2变化为3x3-s1,这样pooling5操作后feature map还是保持较大的尺寸,重要可以保证每个区域提取出重要特征。此时maxpool后特征图大小是19x19(没有降采样)
为什么使用L2 norm?
对于CNN的输出,各个特征的模长均不一样, l2 norm是强行把同个维度的特征归一化。经过L2 norm的数据都处于0到1之间,距离就变得有一个上界了,显然样本间差异变小了.
什么时候用到L2 norm?
在人脸识别,行人重识别等图像分类的任务中,经常使用到该函数。尤其是对于triplet loss这种基于欧式距离的损失函数,若没有对特征进行L2 norm,使用不同尺度的特征计算则会低效。当然也有使用batchnorm对数据处理的方法。
因为尺度不一,由于每次选择的anchor也不一样,所以每次计算优化的方向不一致,导致效率低下。
若联合交叉熵损失函数联合训练,会导致两个损失函数的优化方向不一致
(3)采用全卷积网络结构进行检测
在基础网络之后,使用不同层次卷积的feature map来分别提取anchor box,对于每层的feature map使用两个并行的3x3卷积分别来提取位置信息(offset box)和置信度信息;结合锚框和真实框构建损失函数。
与Yolo最后采用的2个全连接层的网络结构不同,SSD结合fater Rcnn- FCN网络的优点,将所有的全连接网络全部更改为全卷积网络结构。
在基础网络之后,模型中的2层(FC6和FC7)全连接网络转化为两个卷积层:3x3的Conv6和1x1的Conv7。为了保障感受野以及利用到原来的FC6和FC7的模型参数。使用膨胀卷积/空洞卷积的方式来增大感受野。(感受野:卷积神经网络每一层输出的特征图(feature map)上的像素点映射回输入图像上的区域大小
膨胀卷积/空洞卷积:膨胀卷积其实是通过扩大卷积核尺寸的方式来增大感受野,同时既没有增大计算量,也没有降低特征图的分辨率)
Conv6(fc6)中卷积核kernel为3,pad为6, dilation为6,所以相当于真实的卷积核大小为13,pad为6是为了保障输出feature map大小尺度不变,仍为19x19,Conv7(FC7)是提取的第2个用来检测的特征图,其大小为19x19。

除此之外,SSD还在后面新增了4个模块来提取更多的特征,每个模块都包含两个卷积层:1x1 conv+3x3 conv,3x3卷积层后输出的特征将用于检测,分别记为Conv8_2,Conv9_2,Conv10_2和Conv11_2,它们对应的特征图大小分别是10x10,5x5,3x3和1x1。对于SSD512,其输入图像大小更大,所以还额外增加了一个模块来提取特征,即Conv12_2。
采用多尺度来检测是SSD的一个重要特性,多尺度特征能够适应不同尺度物体,不过自从FPN提出后,后面大部分的检测都采用FPN这样的结构来提取多尺度特征,相比SSD,FPN考虑了不同尺度特征的融合。
三.检测头
SSD的检测头比较简单:直接在每个特征图后接一个3x3卷积。这个卷积层的输出channels=A * (C+4),这里的A是每个位置预测的先验框数量,而C是检测类别数量(注意包括背景类,C=num_classes+1),除了类别外,还要预测box的位置,这里预测的是box相对先验框的4个偏移量。
需要注意的是,每个特征图的head是不共享的,毕竟存在尺度上的差异。相比之下,RetinaNet的head是采用4个中间卷积层+1个预测卷积层,head是在各个特征图上是共享的,而分类和回归采用不同的head。采用更重的head无疑有助于提高检测效果,不过也带来计算量的增加
四.先验框
SSD是基于anchor的单阶段检测模型,论文里的anchor称为default box。前面说过SSD300共提取了6个不同的尺度特征,大小分别是38x38,19x19,10x10,5x5,3x3和1x1,每个特征图的不同位置采用相同的anchor,即同一个特征图上不同位置的anchor是一样的;但不同特征图上设置的anchor是不同的,特征图越小,放置的anchor的尺度越大(论文里用一个线性公式来计算不同特征图的anchor大小)。在SSD中,anchor的中心点是特征图上单元的中心点,anchor的形状由两个参数控制:scale和aspect_ratio(大小和宽高比),每个特征图设置大小一样但宽高比不同的anchor,这里记sk为第k个特征图上anchor的大小,并记ar为anchor的宽高比,那么就可以计算出anchor的宽和高:
![]()
具体地,6个特征图采用的大小分别是0.07, 0.15, 0.33, 0.51, 0.69, 0.87, 1.05,这里的大小是相对图片尺寸的值,而不是绝对大小。每个特征图上都包含两个特殊的anchor,第一个是aspect_ratio=1而scale=sk的anchor,第2个是aspect_ratio=1而scale=√(sksk+1)的anchor。除了这两个特殊的anchor,每个特征图还包含其它aspect_ratio的anchor:[2, 1/2], [2, 1/2, 3, 1/3], [2, 1/2, 3, 1/3], [2, 1/2, 3, 1/3], [2, 1/2], [2, 1/2]
SSD每个anchor共回归4个值,这4个值是box相对于anchor的偏移量(offset),这其实涉及到box和anchor之间的变换,一般称为box的编码方式。SSD采用和Faster RCNN一样的编码方式
五.匹配策略
在训练阶段,首先要确定每个真实框由哪些anchor来预测才能计算损失,这就是anchor的匹配的策略,有些论文也称为label assignment策略。SSD的匹配策略是基于IoU的,首先计算所有真实框和所有anchor的IoU值,然后每个anchor取IoU最大对应的真实框(保证每个anchor最多预测一个真实框),如果这个最大IoU值大于某个阈值(SSD设定为0.5),那么anchor就匹配到这个真实框,即在训练阶段负责预测它。匹配到真实框的anchor一般称为正样本,而没有匹配到任何真实框的anchor称为负样本,训练时应该预测为背景类。对于一个真实框,与其匹配的anchor数量可能不止一个,但是也可能一个也没有,此时所有anchor与真实框的IoU均小于阈值,为了防止这种情况,对每个真实框,与其IoU最大的anchor一定匹配到它(忽略阈值),这样就保证每个真实框至少有一个anchor匹配到。
训练数据类别给定标准:
正样本:若先验框和Ground Truth框匹配, 那么认为当前先验框为正样本;
负样本:若先验框和所有Ground Truth框都不匹配,那么认为当前先验框为负样本。
NOTE: 采用hard negative mining(难负样本挖掘算法)选择loss大的样本作为负样本,正负样本比例1:3;
SSD的先验框与Ground Truth的匹配原则主要有几点。
- 首先计算所有真实框和瞄框的iou值,对于图片中每个真实框,如果某个先验框和多个Ground Truth的IoU值大于阈值或者是最大IoU的先验框,那么这个先验框仅和IoU最大的那个Ground Truth匹配
- 对于剩余的未匹配先验框,若某个真实框的 IoU 大于某个阈值(一般是0.5),那么该先验框也与这个Ground Truth进行匹配。这意味着某个Ground Truth可能与多个先验框匹配,也可能一个也匹配不到。
- 为了防止cnahor和真实框的iou都小于阀值。对每个真实框,找到与其IoU最大的先验框,该先验框与其匹配(保证每个anchor可以最多匹配一个真实框)
SSD的匹配策略和Faster RCNN有些区别,Faster RCNN采用双阈值(0.7,0.3),处于中间阈值的anchor既不是正样本也不是负样本,训练过程不计算损失。但在实现上,SSD的匹配策略可以继承复用Faster RCNN的逻辑
基于IoU的匹配策略属于设定好的规则,它的好处是可以控制正样本的质量,但坏处是失去了灵活性。目前也有一些研究提出了动态的匹配策略,即基于模型预测的结果来进行匹配,而不是基于固定的规则,如DETR和YOLOX
六.损失函数
根据匹配策略可以确定每个anchor是正样本还是负样本,对于为正样本的anchor也确定其要预测的ground truth,那么就比较容易计算训练损失。SSD损失函数包括两个部分:分类损失和回归损失。
SSD的分类采用的是softmax多分类,类别数量为要检测的类别加上一个背景类,对于正样本其分类的target就是匹配的ground truth的类别,而负样本其target为背景类。对于正样本,同时还要计算回归损失,这里采用的Smooth L1 loss。对于one-stage检测模型,一个比较头疼的问题是训练过程正样本严重不均衡,SSD采用hard negative mining(难负样本挖掘算法)来平衡正负样本(RetinaNet采用focal loss)。具体地,基于分类损失对负样本抽样,选择较大的top-k作为训练的负样本,以保证正负样本比例接近1:3
七.数据增强
水平翻转(horizontal flip)
随机剪裁加颜色扭曲(Random Crop & Color Distortion)
随机采集块域(Randomly sample a path)
八.训练
由于采用较strong的数据增强,SSD需要较长的训练时长:120 epochs(相比之下,其它检测器如Faster RCNN和RetinaNet往往只用12 epoch和36 epoch)
九.模型推理
SSD的推理过程比较简单:首先根据分类预测概率和阈值过滤掉低置信度预测框;然后每个类别选择top K个预测框;最后通过NMS去除重复框
十.总结
SSD简单总结
- 使用anchor box作为候选框,特定的anchor box的计算规则;
- 在不同层次的feature map上提取anchor box,用来预测不同尺度大小的图像;
- 在同一个feature map上,使用不同高宽比的anchor box;
- 使用膨胀卷积增大感受野;
- 正负样本的划分方式;
SSD模型对bounding box的尺寸非常的敏感。也就是说,SSD对小物体目标较为敏感,在检测小物体目标上表现较差。其实这也算情理之中,因为
1.ssd的最小边框是21x42,如果是正方形就是30x30的边框,这个物体呢不是很小其实,但是如果现在存在一个物体只有10个像素,其实是检测不出来的。
Yolo是可以检测出小物体的 比如yolov5,yolov7,这是因为它们之间的网络结构的差异性。
网络整体的差距,ssd里面用的vgg架构,里面加了一点点膨胀卷积。Yolo的网络结构不是用的vgg,vgg其实很笨重,vgg存在大量3x3卷积,而且通道数普遍比较大的,计算量比较高,速度就不行。实际上对于模型来讲我们一个模型的执行效率越高越好,就比如chatgpt,如果把它开源的api投放到市场的一些领域中去(在某些场景是可以的,但是在绝大多数场景,它是不适合的,哪怕就是能够解决这个问题也不适合),因为每回答一个问题要3-5s,这种耗时其实是不满足你的需求的,我们图像领域也是这样的,我们一定是速度越快越好,因此我网络能复杂嘛,我有一亿个参数,在怎么块也快不起来。所以我们要求的网络架构一定是简单的,其次另外一个点就是效果,比如我网络设个2层,贼快但是效果呢,就不一定,所以,实际上在企业上,我们需要的是2者的均衡,yolo的定位很直白,刚开始就是追求速度,它为了追求实时的目标效果,实时性,yolov1-yolov3. 在yolov4以后,它是在效果上发展。
2.对于小目标而言,经过多层卷积之后,就没剩多少信息了。虽然提高输入图像的size可以提高对小目标的检测效果,但是对于小目标检测问题,还是有很多提升空间的,
积极的看,SSD 对大目标检测效果非常好,SSD对小目标检测效果不好,但也比YOLO要好。另外,因为SSD使用了不同宽高比的default boxes,SSD 对于不同宽高比的物体检测效果也很好,使用更多的default boxes,结果也越好。膨胀卷积使得SSD又好又快 ,通常卷积过程中为了使特征图尺寸保持不变,都会在边缘打padding,但人为加入的padding值会引入噪声,而使用膨胀卷积能够在保持感受野不变的条件下,减少padding噪声,SSD训练过程中并没有使用膨胀卷积,但预训练过程使用的模型为VGG-16-atrous,意味着作者给的预训练模型是使用膨胀卷积训练出来的
from typing import List
import numpy as np
import torch
from PIL import Image
from torch import Tensor
from torchvision.models import detection
from torchvision import transforms
import cv2 as cv
from torchvision.models.detection.anchor_utils import DefaultBoxGenerator
from torchvision.models.detection.image_list import ImageList
def training(model):
images = torch.rand(4, 3, 300, 300)
boxes = torch.tensor(
[
[[8.8069e+01, 1.4674e+02, 5.6282e+02, 3.7051e+02],
[5.8338e+02, 2.6097e+02, 6.0366e+02, 3.3450e+02],
[1.6025e-01, 2.7076e+02, 1.7438e+01, 3.6145e+02],
[5.5874e+02, 2.7589e+02, 5.7230e+02, 3.3554e+02],
[6.0216e+02, 2.6434e+02, 6.2211e+02, 3.2958e+02],
[6.2616e+02, 2.6423e+02, 6.3996e+02, 3.2847e+02],
[1.7602e+02, 1.8451e+02, 1.9516e+02, 2.0253e+02],
[1.2418e+01, 2.8615e+02, 3.9832e+01, 3.1260e+02],
[1.4647e+02, 1.8438e+02, 1.6404e+02, 2.0427e+02],
[1.0756e+01, 2.2248e+02, 2.2998e+01, 2.5238e+02],
[3.0237e+02, 2.7734e+02, 3.1222e+02, 2.9777e+02],
[1.2737e+02, 1.9033e+02, 1.4161e+02, 2.0765e+02],
[2.4141e+02, 1.7469e+02, 2.6035e+02, 1.9441e+02],
[4.2691e+02, 2.6918e+02, 4.3745e+02, 2.8266e+02]],
[[8.8069e+01, 1.4674e+02, 5.6282e+02, 3.7051e+02],
[5.8338e+02, 2.6097e+02, 6.0366e+02, 3.3450e+02],
[1.6025e-01, 2.7076e+02, 1.7438e+01, 3.6145e+02],
[5.5874e+02, 2.7589e+02, 5.7230e+02, 3.3554e+02],
[6.0216e+02, 2.6434e+02, 6.2211e+02, 3.2958e+02],
[6.2616e+02, 2.6423e+02, 6.3996e+02, 3.2847e+02],
[1.7602e+02, 1.8451e+02, 1.9516e+02, 2.0253e+02],
[1.2418e+01, 2.8615e+02, 3.9832e+01, 3.1260e+02],
[1.4647e+02, 1.8438e+02, 1.6404e+02, 2.0427e+02],
[1.0756e+01, 2.2248e+02, 2.2998e+01, 2.5238e+02],
[3.0237e+02, 2.7734e+02, 3.1222e+02, 2.9777e+02],
[1.2737e+02, 1.9033e+02, 1.4161e+02, 2.0765e+02],
[2.4141e+02, 1.7469e+02, 2.6035e+02, 1.9441e+02],
[4.2691e+02, 2.6918e+02, 4.3745e+02, 2.8266e+02]],
[[8.8069e+01, 1.4674e+02, 5.6282e+02, 3.7051e+02],
[5.8338e+02, 2.6097e+02, 6.0366e+02, 3.3450e+02],
[1.6025e-01, 2.7076e+02, 1.7438e+01, 3.6145e+02],
[5.5874e+02, 2.7589e+02, 5.7230e+02, 3.3554e+02],
[6.0216e+02, 2.6434e+02, 6.2211e+02, 3.2958e+02],
[6.2616e+02, 2.6423e+02, 6.3996e+02, 3.2847e+02],
[1.7602e+02, 1.8451e+02, 1.9516e+02, 2.0253e+02],
[1.2418e+01, 2.8615e+02, 3.9832e+01, 3.1260e+02],
[1.4647e+02, 1.8438e+02, 1.6404e+02, 2.0427e+02],
[1.0756e+01, 2.2248e+02, 2.2998e+01, 2.5238e+02],
[3.0237e+02, 2.7734e+02, 3.1222e+02, 2.9777e+02],
[1.2737e+02, 1.9033e+02, 1.4161e+02, 2.0765e+02],
[2.4141e+02, 1.7469e+02, 2.6035e+02, 1.9441e+02],
[4.2691e+02, 2.6918e+02, 4.3745e+02, 2.8266e+02]],
[[8.8069e+01, 1.4674e+02, 5.6282e+02, 3.7051e+02],
[5.8338e+02, 2.6097e+02, 6.0366e+02, 3.3450e+02],
[1.6025e-01, 2.7076e+02, 1.7438e+01, 3.6145e+02],
[5.5874e+02, 2.7589e+02, 5.7230e+02, 3.3554e+02],
[6.0216e+02, 2.6434e+02, 6.2211e+02, 3.2958e+02],
[6.2616e+02, 2.6423e+02, 6.3996e+02, 3.2847e+02],
[1.7602e+02, 1.8451e+02, 1.9516e+02, 2.0253e+02],
[1.2418e+01, 2.8615e+02, 3.9832e+01, 3.1260e+02],
[1.4647e+02, 1.8438e+02, 1.6404e+02, 2.0427e+02],
[1.0756e+01, 2.2248e+02, 2.2998e+01, 2.5238e+02],
[3.0237e+02, 2.7734e+02, 3.1222e+02, 2.9777e+02],
[1.2737e+02, 1.9033e+02, 1.4161e+02, 2.0765e+02],
[2.4141e+02, 1.7469e+02, 2.6035e+02, 1.9441e+02],
[4.2691e+02, 2.6918e+02, 4.3745e+02, 2.8266e+02]]
],
)
labels = torch.randint(1, 91, (4, 14))
images = list(image for image in images)
targets = []
for i in range(len(images)):
d = {}
d['boxes'] = boxes[i]
d['labels'] = labels[i]
targets.append(d)
output = model(images, targets)
print(output)
def inference(model):
model.eval()
print(model)
# img0 = Image.open("../datas/images/a.jpeg")
img0 = Image.open("../datas/images/c.jpg")
ts = transforms.Compose([
transforms.ToTensor()
])
img = ts(img0)[None, ...]
r = model(img)
print(r)
r = r[0]
img0 = cv.cvtColor(np.asarray(img0).astype(np.uint8), cv.COLOR_RGB2BGR)
boxes = r['boxes'].detach().numpy()
labels = r['labels'].detach().numpy()
scores = r['scores'].detach().numpy()
print(f"总预测边框数目:{len(labels)}")
label_2_color = {}
for label in np.unique(labels):
try:
color = label_2_color[label]
except KeyError:
color = list(map(int, np.random.randint(255, size=(3,))))
label_2_color[label] = color
idx = labels == label
for box, score in zip(boxes[idx], scores[idx]):
box = list(map(int, box))
cv.rectangle(img0, pt1=(box[0], box[1]), pt2=(box[2], box[3]), color=color, thickness=2)
cv.putText(img0, text=f"{label}:{score:.3f}", org=(box[0], box[1]), color=(255, 255, 255), thickness=2,
fontFace=cv.FONT_HERSHEY_SIMPLEX, fontScale=0.5, lineType=cv.LINE_AA)
cv.imwrite("../datas/images/1.png", img0)
cv.imshow('x', img0)
cv.waitKey(0)
cv.destroyAllWindows()
def test_ssd():
# 模型类别对应COCO数据集
model = detection.ssd300_vgg16(
pretrained=True,
score_thresh=0.1, # 置信度阈值
nms_thresh=0.45, # NMS的IoU阈值
detections_per_img=100, # 每个图像最多多少个目标
topk_candidates=200 # 计算过程中topk的大小
)
training(model)
# inference(model)
def test_anchor_box():
anchor_generator = DefaultBoxGenerator([[2], [2, 3], [2, 3], [2, 3], [2], [2]],
scales=[0.07, 0.15, 0.33, 0.51, 0.69, 0.87, 1.05],
steps=[8, 16, 32, 64, 100, 300])
image_list: ImageList = ImageList(torch.randn(4, 3, 300, 300), [(300, 300), (300, 300), (300, 300), (300, 300)])
feature_maps: List[Tensor] = [
torch.randn(4, 8, 38, 38),
torch.randn(4, 8, 19, 19),
torch.randn(4, 8, 10, 10),
torch.randn(4, 8, 5, 5),
torch.randn(4, 8, 3, 3),
torch.randn(4, 8, 1, 1)
]
anchor_boxes = anchor_generator(image_list, feature_maps)
print(anchor_boxes)
if __name__ == '__main__':
test_ssd()
RPN
NMS
一.简介
Non-Maximum Suppression(NMS)非极大值抑制。从字面意思理解,抑制那些非极大值的元素,保留极大值元素。其主要用于目标检测,目标跟踪,3D重建,数据挖掘等。
目前NMS常用的有标准NMS, Soft-NMS, DIOU-NMS等
二.原始NMS
 在预测任务中,会出现很多冗余的预测框,通过NMS操作可以有效的删除冗余检测的结果。非极大值抑制(NMS)顾名思义就是抑制不是极大值的元素,搜索局部的极大值。这个局部代表的是一个邻域,邻域有两个参数可变,一是邻域的维数,二是邻域的大小.
在预测任务中,会出现很多冗余的预测框,通过NMS操作可以有效的删除冗余检测的结果。非极大值抑制(NMS)顾名思义就是抑制不是极大值的元素,搜索局部的极大值。这个局部代表的是一个邻域,邻域有两个参数可变,一是邻域的维数,二是邻域的大小.
例如在行人检测中,滑动窗口经提取特征,经分类器分类识别后,每个窗口都会得到一个分数。但是滑动窗口会导致很多窗口与其他窗口存在包含或者大部分交叉的情况。这时就需要用到NMS来选取那些邻域里分数最高(是行人的概率最大),并且抑制那些分数低的窗口。
三.算法流程
IoU 的阈值是一个可优化的参数,一般范围为0~0.5,可以使用交叉验证来选择最优的参数。
就像上面的图片一样,定位一个行人检测框,最后算法就找出了一堆的方框,我们需要判别哪些矩形框是没用的。
非极大值抑制的方法是:先假设有6个矩形框,根据分类器的类别分类概率做排序,假设从小到大属于人脸的概率 分别为A、B、C、D、E、F。
1.从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值;
2.假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
3.从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
4.就这样一直重复,找到所有被保留下来的矩形框
四.多类别-NMS
上面这种做法是把所有boxes放在一起做NMS,没有考虑类别。即某一类的boxes不应该因为它与另一类最大得分boxes的iou值超过阈值而被筛掉。对于多类别NMS来说,它的思想比较简单:每个类别内部做NMS就可以了。
实现方法:把每个box的坐标添加一个偏移量,偏移量由类别索引来决定。
五.Soft-NMS
上述NMS算法的一个主要问题是当两个真实值的目标的确重叠度很高时,NMS会将具有较低置信度的框去掉(置信度改成0),参见下图所示


Soft-nms和nms的差异在于:soft-nms的改进方法在于将置信度改为IoU的函数,这就导致那些具有较低的值而不至于从排序列表中删去。
延伸扩展:soft-nms的其实存在两种衰减方式,第一种:
 这种方式使用1-Iou与得分的乘积作为衰减后的值,但这种方式在略低于阈值和略高于阈值的部分,经过惩罚衰减函数后,很容易导致得分排序的顺序打乱,合理的惩罚函数应该是具有高iou的有高的惩罚,低iou的有低的惩罚,它们中间应该是逐渐过渡的。因此提出第二种高斯惩罚函数,具体如下:
这种方式使用1-Iou与得分的乘积作为衰减后的值,但这种方式在略低于阈值和略高于阈值的部分,经过惩罚衰减函数后,很容易导致得分排序的顺序打乱,合理的惩罚函数应该是具有高iou的有高的惩罚,低iou的有低的惩罚,它们中间应该是逐渐过渡的。因此提出第二种高斯惩罚函数,具体如下:

这样soft NMS可以避免阈值设置大小的问题
Soft NMS还有后续改进版Softer-NMS,其主要解决的问题是:当所有候选框都不够精确时该如何选择,当得分高的候选框并不更精确,更精确的候选框得分并不是最高时怎么选择。
六.NMS的缺陷
- 需要手动设置阈值,阈值的设置会直接影响重叠目标的检测,太大造成误检,太小达不到理想情况。
- 低于阈值的直接设置score为0,做法太hard。
- 只能在CPU上运行,成为影响速度的重要因素。
- 通过IoU来评估,IoU的做法对目标框尺度和距离的影响不同
七.NMS的改进
-
根据手动设置阈值的缺陷,通过自适应的方法在目标系数时使用小阈值,目标稠密时使用大阈值。例如Adaptive NMS
-
将低于阈值的直接置为0的做法太蠢,通过将其根据IoU大小来进行惩罚衰减,则变得更加soft。例如Soft NMS,Softer NMS。
-
只能在CPU上运行,速度太慢的改进思路有三个,一个是设计在GPU上的NMS,如CUDA NMS,一个是设计更快的NMS,如Fast NMS,最后一个是卷积,设计一个神经网络来实现NMS,如ConvNMS。
-
IoU的NMS存在一定缺陷,改进思路是将目标尺度、距离引进IoU的考虑中。如DIoU-nms
import torch
import torchvision
# NMS算法
# bboxes维度为[N,4],scores维度为[N,], 均为tensor
def nms(self, bboxes, scores, threshold=0.5):
x1 = bboxes[:,0]
y1 = bboxes[:,1]
x2 = bboxes[:,2]
y2 = bboxes[:,3]
areas = (x2-x1)*(y2-y1) # [N,] 每个bbox的面积
_, order = scores.sort(0, descending=True) # 降序排列
keep = []
while order.numel() > 0: # torch.numel()返回张量元素个数
if order.numel() == 1: # 保留框只剩一个
i = order.item()
keep.append(i)
break
else:
i = order[0].item() # 保留scores最大的那个框box[i]
keep.append(i)
# 计算box[i]与其余各框的IOU(思路很好)
xx1 = x1[order[1:]].clamp(min=x1[i]) # [N-1,]
yy1 = y1[order[1:]].clamp(min=y1[i])
xx2 = x2[order[1:]].clamp(max=x2[i])
yy2 = y2[order[1:]].clamp(max=y2[i])
inter = (xx2-xx1).clamp(min=0) * (yy2-yy1).clamp(min=0) # [N-1,]
iou = inter / (areas[i]+areas[order[1:]]-inter) # [N-1,]
idx = (iou <= threshold).nonzero().squeeze() # 注意此时idx为[N-1,] 而order为[N,]
if idx.numel() == 0:
break
order = order[idx+1] # 修补索引之间的差值
return torch.LongTensor(keep) # Pytorch的索引值为LongTensor
box = torch.tensor([[2,3.1,7,5],[3,4,8,4.8],[4,4,5.6,7],[0.1,0,8,1]])
score = torch.tensor([0.5, 0.3, 0.2, 0.4])
o=torchvision.ops.nms(boxes=box, scores=score, iou_threshold=0.3)#直接使用torchvision.ops.nms来实现。
print(o)
map
iou
一、前言
目标检测任务的损失函数由Classificition Loss和Bounding Box Regeression Loss两部分构成。
目标框的回归损失的演进路线是:
Smooth L1 Loss --> IoU Loss --> GIoU Loss --> DIoU Loss --> CIoU Loss -->EIoU Loss
1.L1 Loss

当假设 x 为预测框和真实框之间的数值差异时,公式变为:
L1=∣x∣ 导数: 特点:L1 loss在零点处不平滑,学习慢
特点:L1 loss在零点处不平滑,学习慢
L1 loss对 x 的导数为常数,训练后期,当x 很小时,如果学习率不变,损失函数会在稳定值附近波动,很难收敛到更高的精度
由于L1范数的天然性质,对L1优化的解是一个稀疏解, 因此L1范数也被叫做稀疏规则算子。 通过L1可以实现特征的稀疏,去掉一些没有信息的特征,例如在对用户的电影爱好做分类的时候,用户有100个特征,可能只有十几个特征是对分类有用的,大部分特征如身高体重等可能都是无用的,利用L1范数就可以过滤掉。
2.L2 Loss
L2范数是我们最常见最常用的范数了,我们用的最多的度量距离欧氏距离就是一种L2范数

当假设 x 为预测框和真实框之间的数值差异时,公式变为:
![]() 导数
导数 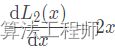
特点:L2 loss由于是平方增长,因此学习快
L 2 loss对 x 的导数为2x,当 x 很大的时候,导数也很大,使L 2 loss在 总loss 中占据主导位置,进而导致,训练初期不稳定
L2范数通常会被用来做优化目标函数的正则化项,防止模型为了迎合训练集而过于复杂造成过拟合的情况,从而提高模型的泛化能力
为什么使用L2 norm?
对于CNN的输出,各个特征的模长均不一样, l2 norm是强行把同个维度的特征归一化。经过L2 norm的数据都处于0到1之间,距离就变得有一个上界了,显然样本间差异变小了.
什么时候用到L2 norm?
在人脸识别,行人重识别等图像分类的任务中,经常使用到该函数。尤其是对于triplet loss这种基于欧式距离的损失函数,若没有对特征进行L2 norm,使用不同尺度的特征计算则会低效。当然也有使用批归一化对数据处理的方法。
因为尺度不一,由于每次选择的anchor也不一样,所以每次计算优化的方向不一致,导致效率低下。
若联合交叉熵损失函数联合训练,会导致两个损失函数的优化方向不一致
3.Smooth L1 Loss
是在fastRcnn中提出的思想

特点:Smooth L1 Loss 相比L1 loss 改进了零点不平滑问题
相比于L2 loss,在 x 较大的时候不像 L2 在总损失中占据主导位置,不稳定,它是一个缓慢变化的损失
4.损失对比分析
实际目标检测框回归位置任务中的损失loss为

存在的问题:
1.三种Loss用于计算目标检测的目标框损失时,需要将独立的4个点的损失先求出,然后进行相加得到最终的Bounding Box Loss,但是这种做法的前提是这4个点是相互独立的,但是实际上,它们是有一定相关性的
3.实际上,我们对目标框检测的指标通常是使用IoU,而IoU和Smooth L1是完全不同的概念,多个检测框可能有相同大小的Smooth L1 Loss,但IoU却可能差异很大,为了解决这个问题就引入了IoU-Loss
5.总结
我们通常要用L1或L2范数做正则化,从而限制权值大小,减少过拟合风险。特别是在使用梯度下降来做目标函数优化时,
L1和L2的区别
L1范数(L1 norm)是指向量中各个元素绝对值之和,也有个美称叫“稀疏规则算”(Lasso regularization)。
比如 向量A=[1,-1,3], 那么A的L1范数为 |1|+|-1|+|3|.
简单总结一下就是:
L1范数: 为x向量各个元素绝对值之和。
L2范数: 为x向量各个元素平方和的1/2次方,L2范数又称Euclidean范数或者Frobenius范数
Lp范数: 为x向量各个元素绝对值p次方和的1/p次方.
L1正则化产生稀疏的权值, L2正则化产生平滑的权值为什么会这样?
在支持向量机学习过程中,L1范数实际是一种对于成本函数求解最优的过程,因此,L1范数正则化通过向成本函数中添加L1范数,使得学习得到的结果满足稀疏化,从而方便提取特征。
L1范数可以使权值稀疏,方便特征提取。 L2范数可以防止过拟合,提升模型的泛化能力。
L1和L2正则先验分别服从什么分布
面试中遇到的,L1和L2正则先验分别服从什么分布,L1是拉普拉斯分布,L2是高斯分布。
二、简介
在目标检测任务中,常用到一个指标IoU,即交并比。目标检测任务的损失函数由两部分构成:Classification Loss(图片分类)和Bounding Box Regeression Loss(目标框的回归损失)。而IOU就是后者的评估指标。IoU可以很好的描述一个目标检测模型的好坏。在训练阶段IoU可以作为anchor-based(锚框)方法中,划分正负样本的依据;同时也可用作损失函数;在推理阶段,NMS中会用到IoU。同时IoU有着比较严重的缺陷,于是出现了GIoU、DIoU、CIoU、EIoU
三、IoU(Intersection over Union)
IoU的计算是用预测框(A)和真实框(B)的交集除以二者的并集,其公式为:
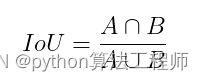 IoU的值越高也说明A框与B框重合程度越高,代表模型预测越准确。反之,IoU越低模型性能越差。
IoU的值越高也说明A框与B框重合程度越高,代表模型预测越准确。反之,IoU越低模型性能越差。
IoU优点:
(1)IoU具有尺度不变性
(2)结果非负,且范围是(0, 1)
IoU缺点:
(1)如果两个目标没有重叠,IoU将会为0,并且不会反应两个目标之间的距离,在这种无重叠目标的情况下,如果IoU用作于损失函数,梯度为0,无法优化。
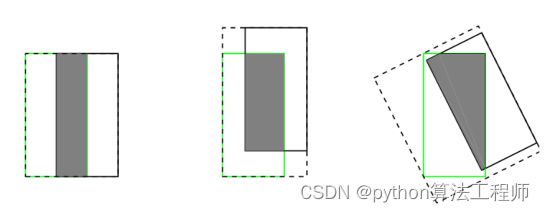
(2)IoU无法精确的反映两者的重合度大小。如下图所示,三种情况IoU都相等,但看得出来他们的重合度是不一样的,左边的图回归的效果最好,右边的最差
三、GIoU(Generalized IoU)
为了解决IoU作为损失函数时的两个缺点,有大神提出了GIoU,在IoU后面增加了一项,计算两个框的最小外接矩形,用于表征两个框的距离,从而解决了两个目标没有交集时梯度为零的问题,公式为:
 其中C是两个框的最小外接矩形的面积。
其中C是两个框的最小外接矩形的面积。
当IOU=0时:

当IOU为0时,意味着A与B没有交集,这个时候两个框离得越远,GIOU越接近-1;两框重合,GIOU=1,所以GIOU的取值为(-1, 1]


GIOU作为loss函数时:
当A、B两框不相交时不变,最大化GIoU就是最小化C,这样就会促使两个框不断靠近。
优点:
(1)当IoU=0时,仍然可以很好的表示两个框的距离。
(2)GIoU不仅关注重叠区域,还关注其他的非重合区域,能更好的反映两者的重合度。
缺点:
1.对每个预测框与真实框均要去计算最小外接矩形,计算及收敛速度受到限制
2.当预测框在真实框内部时,GIoU退化为IoU,也无法区分相对位置关系
(1)当两个框属于包含关系时,GIoU会退化成IoU,无法区分其相对位置关系,如下图:
 (2)由于GIoU仍然严重依赖IoU,因此在两个垂直方向,误差很大,很难收敛。两个框在相同距离的情况下,水平垂直方向时,此部分面积最小,对loss的贡献也就越小,从而导致在垂直水平方向上回归效果较差。
(2)由于GIoU仍然严重依赖IoU,因此在两个垂直方向,误差很大,很难收敛。两个框在相同距离的情况下,水平垂直方向时,此部分面积最小,对loss的贡献也就越小,从而导致在垂直水平方向上回归效果较差。
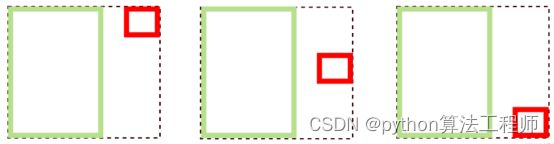
如下图,三种情况下GIoU的值一样,GIoU将很难区分这种情况。
四、DIoU(Distance-IoU)
针对上述GIoU的两个问题,有大神将GIoU中最小外接框来最大化重叠面积的惩罚项修改成最小化两个BBox中心点的标准化距离从而加速损失的收敛过程,这就诞生了DIoU。
DIoU要比GIou更加符合目标框回归的机制,将目标与预测之间的距离,重叠率以及尺度都考虑进去,使得目标框回归变得更加稳定,不会像IoU和GIoU一样出现训练过程中发散等问题。

其中![]() 分别代表了预测框和真实框的中心点,且 ρ 代表的是计算两个中心点间的欧式距离。 c 代表的是能够同时包含预测框和真实框的最小外接矩形的对角线长度。
分别代表了预测框和真实框的中心点,且 ρ 代表的是计算两个中心点间的欧式距离。 c 代表的是能够同时包含预测框和真实框的最小外接矩形的对角线长度。
优点:1)DIoU loss可以直接最小化两个目标框的距离,因此比GIoU loss收敛快得多。
(2)对于包含两个框在水平方向和垂直方向上这种情况,DIoU损失可以使回归非常快。
(3)DIoU还可以替换普通的IoU评价策略,应用于NMS中,使得NMS得到的结果更加合理和有效。
缺点:
虽然DIOU能够直接最小化预测框和真实框的中心点距离加速收敛,但是Bounding box的回归还有一个重要的因素纵横比暂未考虑。如下图,三个红框的面积相同,但是长宽比不一样,红框与绿框中心点重合,这时三种情况的DIoU相同,证明DIoU不能很好的区分这种情况

五、CIoU(Complete-IoU)
CIoU与DIoU出自同一篇论文,CIoU大多数用于训练。DIoU的作者考虑到,在两个框中心点重合时,Ciou与Diou的值都不变。所以此时需要引入框的宽高比:

优点:
考虑了框的纵横比,可以解决DIoU的问题。
缺点:
通过CIoU公式中的v反映的纵横比的差异,而不是宽高分别与其置信度的真实差异,所以有时会阻碍模型有效的优化相似性
六.DIOU-NMS(yoloV4 中将NMS换成DIOU-NMS 效果最佳)
NMS(非最大抑制)是目标检测算法后处理中常用的技术,用来将redundant检测框给过滤掉。
Diou-nms的前身是soft-nms
在经典的NMS中,得分最高的检测框和其它检测框逐一算出一个对应的IOU值,并将该值超过NMS预期的框全部过滤掉。可以看出,在经典NMS算法中,IOU是唯一考量的因素。
但是在实际应用场景中,当两个不同物体挨得很近时,由于IOU值比较大,往往经过NMS处理后,只剩下一个检测框,这样导致漏检的错误情况发生。
基于此,DIOU-NMS就不仅仅考虑IOU,还考虑两个框中心点之间的距离。如果两个框之间IOU比较大,但是两个框的距离比较大时,可能会认为这是两个物体的框而不会被过滤掉
在原始的NMS中,IoU指标用于抑制多余的检测框,但由于仅考虑了重叠区域,经常会造成错误的抑制,特别是在bbox包含的情况下。因此,可以使用DIoU作为NMS的标准,不仅考虑重叠区域,还考虑了中心点距离。(基于DIoU作为NMS标准,虽然多了距离这个维度去考虑问题,但和NMS面对的同样的情况是当两个不同的目标本身就靠的很近的时候还是会造成错误的抑制)
其中 s i 是分类置信度, ε 为NMS阈值, M 为最高置信度的框。DIoU-NMS倾向于中心点距离较远的box存在不同的对象,而且仅需改几行代码,DIoU-NMS就能够很简单地集成到目标检测算法中。
注意:有人会有疑问,这里为什么不用CIOU_nms,而用DIOU_nms?
答:因为前面讲到的CIOU_loss,是在DIOU_loss的基础上,添加的影响因子,包含真实标注框的信息,在训练时用于回归。但在测试过程中,并没有真实的信息,不用考虑影响因子,因此直接用DIOU_nms即可。
七、EIoU
为了解决CIoU的问题,有学者在CIOU的基础上将纵横比拆开,提出了EIOU Loss,并且加入Focal聚焦优质的预测框,与CIoU相似的,EIoU是损失函数的解决方案,只用于训练。
EIOU的惩罚项是在CIOU的惩罚项基础上将纵横比的影响因子拆开分别计算目标框和预测框的长和宽,该损失函数包含三个部分:重叠损失,中心距离损失,宽高损失,前两部分延续CIoU中的方法,但是宽高损失直接使目标框与预测框的宽度和高度之差最小,使得收敛速度更快。惩罚项公式如下

其中 Cw和Ch 是覆盖两个Box的最小外接框的宽度和高度。
通过整合EIoU Loss和FocalL1 loss,最终得到了最终的Focal-EIoU loss,其中 γ是一个用于控制曲线弧度的超参。
![]()
优点:
1)将纵横比的损失项拆分成预测的宽高分别与最小外接框宽高的差值,加速了收敛提高了回归精度。
2)引入了Focal Loss优化了边界框回归任务中的样本不平衡问题,即减少与目标框重叠较少的大量锚框对BBox 回归的优化贡献,使回归过程专注于高质量锚框。
七.总结

八.面试问题
1.解释一下什么是IOU,GIOU,DIOU,CIOU,EIOU,它们的差异是什么
IOU:其实是用预测框(A)和真实框(B)的交集除以二者的并集
拓展IoU的值越高也说明A框与B框重合程度越高,代表模型预测越准确。反之,IoU越低模型性能越差
Giou:其实是为了弥补IOU作为损失函数存在的2个缺陷(1.如果2个目标都没有重叠,iou作为损失函数,它的梯度是等于0的,无法进行模型优化 2.在iou都相等的情况下,无法精确的反映,二者的重合度的大小情况)而发明的,为了解决这个问题,Giou在iou的后面,给每个目标框加了一个最小外接矩形框,用于表示2个框的距离,从而解决了,当两个目标都重叠时,iou作为损失函数,梯度为0的问题。
优点:
(1)当IoU=0时,仍然可以很好的表示两个框的距离。
(2)GIoU不仅关注重叠区域,还关注其他的非重合区域,能更好的反映两者的重合度。
但是当检测框和目标框处于包含的现象,GIOU会退化成IOU,无法区分其相对位置关系。而且由于GIoU仍然严重依赖IoU,因此在两个垂直方向,误差很大,很难收敛。当giou都一样,预测框垂直方向不同的时候,GIOU无法识别,而且对每个预测框与真实框均要去计算最小外接矩形,计算及收敛速度受到限制
Diou:针对Giou的2个问题,Diou对Giou的最小外接矩形框,用于表示2个框的距离,改成了最小化两个BBox中心点的标准化距离(欧式距离)。
DIoU要比GIou更加符合目标框回归的机制,将目标与预测之间的距离,重叠率以及尺度都考虑进去,使得目标框回归变得更加稳定,不会像IoU和GIoU一样出现训练过程中发散等问题。
(1)DIoU loss可以直接最小化两个目标框的距离,因此比GIoU loss收敛快得多。
(2)对于包含两个框在水平方向和垂直方向上这种情况,DIoU损失可以使回归非常快。
(3)DIoU还可以替换普通的IoU评价策略,应用于NMS中,使得NMS得到的结果更加合理和有效。
虽然DIOU能够直接最小化预测框和真实框的中心点距离加速收敛,但是Bounding box的回归还有一个重要的因素纵横比暂未考虑。如果,三个预测框的面积相同,但是长宽比不一样,预测框与真实框中心点重合,这时三种情况的DIoU相同,但是DIoU不能很好的区分这种情况
Ciou:Ciou和Diou出自一篇论文,但是Ciou主要用于训练,DIoU的作者考虑到,在两个框中心点重合时,Ciou与Diou的值都不变。所以CIoU在DIoU的基础上增加了一个影响因子,此时需要引入框的宽高比。考虑了框的纵横比,解决了DIoU的问题
CIOU Loss虽然考虑了边界框回归的重叠面积、中心点距离、纵横比。但是通过其公式中的v反映的纵横比的差异,而不是宽高分别与其置信度的真实差异,所以有时会阻碍模型有效的优化相似性。
Diou-nms:在原始的NMS中,IoU指标用于抑制多余的检测框,但由于仅考虑了重叠区域,经常会造成错误的抑制,特别是在bbox包含的情况下。因此,可以使用DIoU作为NMS的标准,不仅考虑重叠区域,还考虑了中心点距离。(基于DIoU作为NMS标准,虽然多了距离这个维度去考虑问题,但和NMS面对的同样的情况是当两个不同的目标本身就靠的很近的时候还是会造成错误的抑制)
Eiou: 为了解决Ciou存在的问题,有学者在CIOU的基础上将纵横比拆开,提出了EIOU Loss,并且加入Focal聚焦优质的锚框,与CIoU相似的,EIoU是损失函数的解决方案,只用于训练。EIOU的惩罚项是在CIOU的惩罚项基础上将纵横比的影响因子拆开分别计算目标框和预测框的长和宽,该损失函数包含三个部分:重叠损失,中心距离损失,宽高损失,前两部分延续CIoU中的方法,但是宽高损失直接使目标框与预测框的宽度和高度之差最小
优点:
1)将纵横比的损失项拆分成预测的宽高分别与最小外接框宽高的差值,加速了收敛提高了回归精度。
2)引入了Focal Loss优化了边界框回归任务中的样本不平衡问题,即减少与目标框重叠较少的大量锚框对BBox 回归的优化贡献,使回归过程专注于高质量锚框。
2.讲述一下你在该项目中用的是什么损失函数,为什么
用Eiou,将NMS换成 Diou-nms
注意:有人会有疑问,这里为什么不用EIOU_nms,而用DIOU_nms?
答:因为前面讲到的EIOU_loss,是在CIOU_loss的基础上,而Clou是在Diou上添加的影响因子,包含真实标注框的信息,在训练时用于回归。但在测试过程中,并没有真实的信息,不用考虑影响因子,因此直接用DIOU_nms即可
3.你认为一个好的目标框回归损失应该考虑什么因素:
重叠面积、中心点距离、长宽比(纵横比)。
import torch
import math
import numpy as np
def bbox_iou(box1, box2, xywh=False, giou=False, diou=False, ciou=False, eiou=False, eps=1e-7):
"""
实现各种IoU
Parameters
----------
box1 shape(b, c, h, w,4)
box2 shape(b, c, h, w,4)
xywh 是否使用中心点和wh,如果是False,输入就是左上右下四个坐标
GIoU 是否GIoU
DIoU 是否DIoU
CIoU 是否CIoU
EIoU 是否EIoU
eps 防止除零的小量
Returns
-------
"""
# 获取边界框的坐标
if xywh:
# 将 xywh 转换成 xyxy
b1_x1, b1_x2 = box1[..., 0] - box1[..., 2] / 2, box1[..., 0] + box1[..., 2] / 2
b1_y1, b1_y2 = box1[..., 1] - box1[..., 3] / 2, box1[..., 1] + box1[..., 3] / 2
b2_x1, b2_x2 = box2[..., 0] - box2[..., 2] / 2, box2[..., 0] + box2[..., 2] / 2
b2_y1, b2_y2 = box2[..., 1] - box2[..., 3] / 2, box2[..., 1] + box2[..., 3] / 2
else:
# x1, y1, x2, y2 = box1
b1_x1, b1_y1, b1_x2, b1_y2 = box1[..., 0], box1[..., 1], box1[..., 2], box1[..., 3]
b2_x1, b2_y1, b2_x2, b2_y2 = box2[..., 0], box2[..., 1], box2[..., 2], box2[..., 3]
# 区域交集
inter = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \
(torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)
# 区域并集
w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + eps
w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + eps
union = w1 * h1 + w2 * h2 - inter + eps
# 计算iou
iou = inter / union
if giou or diou or ciou or eiou:
# 计算最小外接矩形的wh
cw = torch.max(b1_x2, b2_x2) - torch.min(b1_x1, b2_x1)
ch = torch.max(b1_y2, b2_y2) - torch.min(b1_y1, b2_y1)
if ciou or diou or eiou:
# 计算最小外接矩形角线的平方
c2 = cw ** 2 + ch ** 2 + eps
# 计算最小外接矩形中点距离的平方
rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 +
(b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4
if diou:
# 输出DIoU
return iou - rho2 / c2
elif ciou:
v = (4 / math.pi ** 2) * torch.pow(torch.atan(w2 / h2) - torch.atan(w1 / h1), 2)
with torch.no_grad():
alpha = v / (v - iou + (1 + eps))
# 输出CIoU
return iou - (rho2 / c2 + v * alpha)
elif eiou:
rho_w2 = ((b2_x2 - b2_x1) - (b1_x2 - b1_x1)) ** 2
rho_h2 = ((b2_y2 - b2_y1) - (b1_y2 - b1_y1)) ** 2
cw2 = cw ** 2 + eps
ch2 = ch ** 2 + eps
# 输出EIoU
return iou - (rho2 / c2 + rho_w2 / cw2 + rho_h2 / ch2)
else:
c_area = cw * ch + eps # convex area
# 输出GIoU
return iou - (c_area - union) / c_area
else:
# 输出IoU
return iou
if __name__ == '__main__':
box1 = torch.from_numpy(np.asarray([170, 110, 310, 370]))
box1 = box1.expand(1, 1, 1, 1, 4)
# 有交集
box2 = torch.from_numpy(np.asarray([250, 60, 375, 300]))
box2 = box2.expand(1, 1, 1, 1, 4)
# 无交集
box3 = torch.from_numpy(np.asarray([730, 420, 1000, 700]))
box3 = box3.expand(1, 1, 1, 1, 4)
print('iou有交集:', bbox_iou(box1, box2))
print('giou有交集:', bbox_iou(box1, box2, giou=True))
print('diou有交集:', bbox_iou(box1, box2, diou=True))
print('ciou有交集:', bbox_iou(box1, box2, ciou=True))
print('eiou有交集:', bbox_iou(box1, box2, eiou=True))
print("=" * 20)
print('iou无交集:', bbox_iou(box1, box3))
print('giou无交集:', bbox_iou(box1, box3, giou=True))
print('diou无交集:', bbox_iou(box1, box3, diou=True))
print('ciou无交集:', bbox_iou(box1, box3, ciou=True))
print('eiou无交集:', bbox_iou(box1, box3, eiou=True))
import numpy as np
import torch
import math
def Iou(box1, box2, wh=False):
if wh == False:
xmin1, ymin1, xmax1, ymax1 = box1
xmin2, ymin2, xmax2, ymax2 = box2
else:
xmin1, ymin1 = int(box1[0]-box1[2]/2.0), int(box1[1]-box1[3]/2.0)
xmax1, ymax1 = int(box1[0]+box1[2]/2.0), int(box1[1]+box1[3]/2.0)
xmin2, ymin2 = int(box2[0]-box2[2]/2.0), int(box2[1]-box2[3]/2.0)
xmax2, ymax2 = int(box2[0]+box2[2]/2.0), int(box2[1]+box2[3]/2.0)
# 获取矩形框交集对应的左上角和右下角的坐标(intersection)
xx1 = np.max([xmin1, xmin2])
yy1 = np.max([ymin1, ymin2])
xx2 = np.min([xmax1, xmax2])
yy2 = np.min([ymax1, ymax2])
# 计算两个矩形框面积
area1 = (xmax1-xmin1) * (ymax1-ymin1)
area2 = (xmax2-xmin2) * (ymax2-ymin2)
inter_area = (np.max([0, xx2-xx1])) * (np.max([0, yy2-yy1]))#计算交集面积
iou = inter_area / (area1+area2-inter_area+1e-6) #计算交并比
return iou
def Giou(rec1,rec2):
#分别是第一个矩形左右上下的坐标
x1,x2,y1,y2 = rec1
x3,x4,y3,y4 = rec2
iou = Iou(rec1,rec2)
area_C = (max(x1,x2,x3,x4)-min(x1,x2,x3,x4))*(max(y1,y2,y3,y4)-min(y1,y2,y3,y4))
area_1 = (x2-x1)*(y1-y2)
area_2 = (x4-x3)*(y3-y4)
sum_area = area_1 + area_2
w1 = x2 - x1 #第一个矩形的宽
w2 = x4 - x3 #第二个矩形的宽
h1 = y1 - y2
h2 = y3 - y4
W = min(x1,x2,x3,x4)+w1+w2-max(x1,x2,x3,x4) #交叉部分的宽
H = min(y1,y2,y3,y4)+h1+h2-max(y1,y2,y3,y4) #交叉部分的高
Area = W*H #交叉的面积
add_area = sum_area - Area #两矩形并集的面积
end_area = (area_C - add_area)/area_C #闭包区域中不属于两个框的区域占闭包区域的比重
giou = iou - end_area
return giou
def Diou(bboxes1, bboxes2):
rows = bboxes1.shape[0]
cols = bboxes2.shape[0]
dious = torch.zeros((rows, cols))
if rows * cols == 0:#
return dious
exchange = False
if bboxes1.shape[0] > bboxes2.shape[0]:
bboxes1, bboxes2 = bboxes2, bboxes1
dious = torch.zeros((cols, rows))
exchange = True
# #xmin,ymin,xmax,ymax->[:,0],[:,1],[:,2],[:,3]
w1 = bboxes1[:, 2] - bboxes1[:, 0]
h1 = bboxes1[:, 3] - bboxes1[:, 1]
w2 = bboxes2[:, 2] - bboxes2[:, 0]
h2 = bboxes2[:, 3] - bboxes2[:, 1]
area1 = w1 * h1
area2 = w2 * h2
center_x1 = (bboxes1[:, 2] + bboxes1[:, 0]) / 2
center_y1 = (bboxes1[:, 3] + bboxes1[:, 1]) / 2
center_x2 = (bboxes2[:, 2] + bboxes2[:, 0]) / 2
center_y2 = (bboxes2[:, 3] + bboxes2[:, 1]) / 2
inter_max_xy = torch.min(bboxes1[:, 2:],bboxes2[:, 2:])
inter_min_xy = torch.max(bboxes1[:, :2],bboxes2[:, :2])
out_max_xy = torch.max(bboxes1[:, 2:],bboxes2[:, 2:])
out_min_xy = torch.min(bboxes1[:, :2],bboxes2[:, :2])
inter = torch.clamp((inter_max_xy - inter_min_xy), min=0)
inter_area = inter[:, 0] * inter[:, 1]
inter_diag = (center_x2 - center_x1)**2 + (center_y2 - center_y1)**2
outer = torch.clamp((out_max_xy - out_min_xy), min=0)
outer_diag = (outer[:, 0] ** 2) + (outer[:, 1] ** 2)
union = area1+area2-inter_area
dious = inter_area / union - (inter_diag) / outer_diag
dious = torch.clamp(dious,min=-1.0,max = 1.0)
if exchange:
dious = dious.T
return dious
def bbox_overlaps_ciou(bboxes1, bboxes2):
rows = bboxes1.shape[0]
cols = bboxes2.shape[0]
cious = torch.zeros((rows, cols))
if rows * cols == 0:
return cious
exchange = False
if bboxes1.shape[0] > bboxes2.shape[0]:
bboxes1, bboxes2 = bboxes2, bboxes1
cious = torch.zeros((cols, rows))
exchange = True
w1 = bboxes1[:, 2] - bboxes1[:, 0]
h1 = bboxes1[:, 3] - bboxes1[:, 1]
w2 = bboxes2[:, 2] - bboxes2[:, 0]
h2 = bboxes2[:, 3] - bboxes2[:, 1]
area1 = w1 * h1
area2 = w2 * h2
center_x1 = (bboxes1[:, 2] + bboxes1[:, 0]) / 2
center_y1 = (bboxes1[:, 3] + bboxes1[:, 1]) / 2
center_x2 = (bboxes2[:, 2] + bboxes2[:, 0]) / 2
center_y2 = (bboxes2[:, 3] + bboxes2[:, 1]) / 2
inter_max_xy = torch.min(bboxes1[:, 2:],bboxes2[:, 2:])
inter_min_xy = torch.max(bboxes1[:, :2],bboxes2[:, :2])
out_max_xy = torch.max(bboxes1[:, 2:],bboxes2[:, 2:])
out_min_xy = torch.min(bboxes1[:, :2],bboxes2[:, :2])
inter = torch.clamp((inter_max_xy - inter_min_xy), min=0)
inter_area = inter[:, 0] * inter[:, 1]
inter_diag = (center_x2 - center_x1)**2 + (center_y2 - center_y1)**2
outer = torch.clamp((out_max_xy - out_min_xy), min=0)
outer_diag = (outer[:, 0] ** 2) + (outer[:, 1] ** 2)
union = area1+area2-inter_area
u = (inter_diag) / outer_diag
iou = inter_area / union
with torch.no_grad():
arctan = torch.atan(w2 / h2) - torch.atan(w1 / h1)
v = (4 / (math.pi ** 2)) * torch.pow((torch.atan(w2 / h2) - torch.atan(w1 / h1)), 2)
S = 1 - iou
alpha = v / (S + v)
w_temp = 2 * w1
ar = (8 / (math.pi ** 2)) * arctan * ((w1 - w_temp) * h1)
cious = iou - (u + alpha * ar)
cious = torch.clamp(cious,min=-1.0,max = 1.0)
if exchange:
cious = cious.T
return cious
googlenet
Inception 网络是CNN分类器发展史上一个重要的里程碑。在 Inception 出现之前,大部分流行 CNN 仅仅是把卷积层堆叠得越来越多,使网络越来越深,以此希望能够得到更好的性能
Incetion v1(2014 图片分类冠军)

主要的贡献使用1x1的卷积进行降维,然后在多尺度的基础上重新进行卷积聚合
首先通过1x1卷积来降低通道数把信息聚集一下,再进行不同尺度的特征提取以及池化,得到多个尺度的信息,最后将特征进行叠加输出
网络结构的改进,使用了9个incetion模块的堆叠,采用了2个辅助分类器(权重为0.3,但存在“第一个loss对网络无作用的说法”),没有用全链接采用平均池化层。 网络规模仅仅是alexnet的1/12。 辅助分类器用于辅助分类输出,用于在较低层注入额外的梯度
1 为什么要使用3×3卷积?
常见的卷积核大小有1×1、3×3、5×5、7×7,有时也会看到11×11,若在卷积层提取特征,我们通常选用3×3大小的卷积。
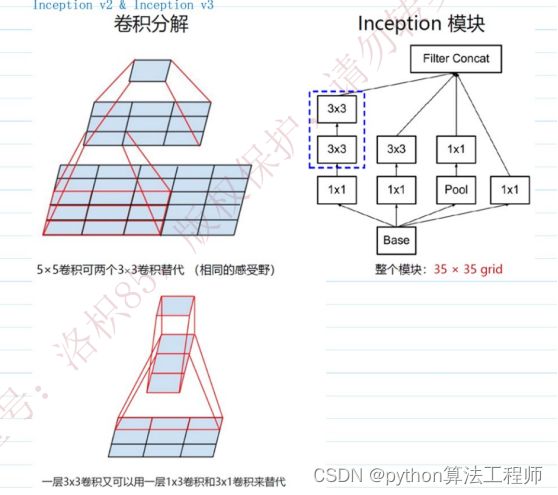
我们知道,两个3×3卷积核一个5×5卷积的感受野相同,三个3×3卷积和一个7×7卷积的感受野相同
可见在感受野相同的情况下,三个3×3卷积比一个7×7卷积所需参数要少很多,这无疑减少了模型的复杂度,加快了训练速度。
而且虽然感受野一样,但是3×3卷积的非线性程度更高,可以表示更复杂的函数;小的卷积核可以提取细小的特征,由小而大到比较抽象的特征。
但层数加深了,会产生有一串连锁效应,可能会效果提升,但也有可能变差,例如梯度消失。
3x3卷积可以由1x3和3x1来替代
BN-incetion(2015提出)
网络架构:引入了批归一化的概念,此外将5x5卷积换成2个3x3的卷积
为什么引用批归一化:1.降低内部协变量的影响,就是训练过程中网络参数的变化从而影响到网络激活分布的变化
2.可以优化损失,使得损失地貌更加平滑,同时使得梯度在预测的时候会更加稳定性和具有预测性,我们训练的速度会更快
批归一化的好处:可以使用较高的学习率降低参数初始化的敏感期
可以作为一种正则化的方法,但是有时候不能和drop-out一起用
使用RMSProp 优化器,
采用了标签平滑:我们在使用交叉熵损失函数的时候处理多分类任务,有时候会遇到因为训练数据过少,而导致的网络过拟合,因为神经网络会促使自身往正确标签和错误标签差值最大的方向学习。标签平滑这是一种正则化策略,主要是通过soft one-hot来加入噪声,减少了真实样本标签的类别在计算损失函数时的权重,最终起到抑制过拟合的效果
辅助器加了bn操作,可以达到正则化的效果
加入卷积池化并行,然后在依据深度拼接
深度可分离卷积:
深度可分离卷积主要分为两个过程,分别为逐通道卷积和逐点卷积。对卷积核的通道做卷积,一般只有3个,输出3个通道的属性。然后用1x1x3卷积对3个通道在做卷积,随着要提取的属性越多,可以节省更多的参数,其实就是用1x1的卷积对不同通道进行融合
Incetionv4

Incetion-resnet
引入残差块技术,这个概念来自与resnet网络,在block中,数据在经过第二次线性变换之后,并不直接输入非线性变换,而是与block的初始输入加和后,再进行非线性变换,这种结构直观上的解释就是,误差能一直向后传递,可以使训练过程更加容易

Scaling of the Residuals
在残差汇合之前,对残差进行缩减来稳定训练。当卷积核的数量超过1000时,那么残差网络就会变得不稳定,具体表现为几万次迭代之后,平均池化层之前的最后一层开始产生0的输出,使得网络崩溃坏死,这种现象通过降低学习率或者增加BN都无法解决。
因此作者决定采用residual scaling,取一个[ 0.1 , 0.3 ] [0.1,0.3][0.1,0.3]区间之内的缩减常数去减小Inception网络输出的方差,增加稳定性,一定程度上也可以避免模型过拟合。

关于BN的使用。Inception-ResNet为了减小BN带来的存储消耗,只在stem模块中使用,而不是像之前在每个Inception块中使用。
fastercnn
难负样本
难负样本
对分类器迷惑性大的样本,这类样本的实际标签是负的,但是分类器往往预测为正的。也可以说是容易将负样本看成正样本的那些样本,例如 region proposals 里没有物体,全是背景,这时候分类器很容易正确分类成背景
为了让模型正常训练,我们必须要通过某种方法抑制大量的简单负例,挖掘所有难例的信息,这就是难例挖掘的初衷。即在训练时,尽量多挖掘些难负例加入负样本集参与模型的训练