沙箱中的间谍——可行的 JavaScript 高速缓存区攻击
关于译者:王龑(龙天),男,89年出生,毕业于南京大学软件学院,认证敏捷教练。曾在英特尔亚太研发中心从事私有云系统的开发工作。现在OneAPM担任前端工程师,平时喜欢玩主机游戏,看剧,养鱼等。
以下为正文
偶然看到这篇文章美国发现新的浏览器攻击模式:可监控全球八成PC,非常惊讶便随手点开文章里的原文连接PDF,读完有种脑洞大开的感觉。论文知识点涉及计算机组成原理、虚拟化、性能分析、JavaScript、HTML5规范等,都是我所感兴趣的领域,再加上中招的是老东家的产品,因此虽然我是安全领域的小白,但还是尝试精读并且斗胆翻译一下,不足之处欢迎大家批评指正。任何意见和建议请猛戳issues。
论文译文
摘要
我们将展示首个完全运行在浏览器里的针对微架构的边信道攻击手段。与这个领域里的其它研究成果不同,这一手段不需要攻击者在受害者的电脑上安装任何的应用程序来展开攻击,受害者只需要打开一个由攻击者控制的恶意网页。这种攻击模型可伸缩性高,易于实施,贴近当今的网络环境,特别是由于绝大多数桌面浏览器连接到Internet因此几乎无法防御。这种攻击手段基于Yarom等人[23](PDF中,下同)提出的LLC攻击,可以让攻击者远程获得属于其它进程、用户甚至是虚拟机的信息,只要它们和受害者的浏览器运行在运行在同一台物理主机上。我们将阐述这种攻击背后的基本原理,然后用一种高带宽的隐藏通道验证它的效果,最后用它打造了一个覆盖整个系统的鼠标和网络活动记录器。抵御这种攻击是可能的,但是所需的反制措施对浏览器和电脑的正常使用所产生的代价有点不实际。
1 引言
边信道分析是一种非常强大的密码分析攻击。攻击者通过分析安全设备内部在进行安全运算时所产生的物理信号(功率、辐射、热量等)来取得秘密信息[15]。据说在二战中便有情报部门在使用,Kocher等人在1996年首次在学术情境下讨论了这个问题[14]。边信道分析被证实可以用来侵入无数现实世界中的系统,从汽车报警器到高安全性的密码协处理器[8][18]。缓存攻击(Cache Attack)是和个人电脑相关的一种边信道攻击,因为高速缓冲区被不同的进程和用户使用而导致了信息的泄露[17][11]。
虽然边信道攻击的能力无可置疑,但是要实际应用到系统上还是相对受限的。影响边信道攻击可行性的一个主要因素是对不确定的攻击模型的假设:除了基于网络的时序攻击,大部分的边信道攻击都要求攻击者非常接近受害者。缓存攻击一般会假设攻击者能够在受害者的机器上执行任意的二进制的代码。虽然这个假设适用于像Amazon云计算平台这样的IaaS或者PaaS环境,但是对于其它环境就不那么贴切了。
在这篇报告里,我们用一种约束更少、更可行的攻击者模型挑战了这一限制性的安全假设。在我们的攻击模型里,受害者只需要访问一个网页,该网页由攻击者所拥有。我们会展示,即使在这么简单的攻击者模型里,攻击者依然能够在可行的时间周期里,从被攻击的系统中提取出有意义的信息。为了和这样的计算设定保持一致,我们把注意力集中在了跟踪用户行为而不是获取密匙上。报告中的攻击方式因此是高度可行的:对于攻击者的假设和限定是实际的;运行的时间是实际的;给攻击者带来的好处也是实际的。据我们了解,这是首个可以轻松扩展至上百万个目标的边信道攻击方式。
我们假设攻击中受害者使用的个人电脑配备有较新型号的的Intel CPU,并进一步假设用户使用支持HTML5的浏览器访问网页。这覆盖了绝大部分连接到Internet的个人电脑,见章节5.1。用户被强迫访问一个页面,这个页面上有一个由攻击者控制的元素比如广告。攻击代码自己会执行基于JavaScript的缓存攻击,见章节2,持续地访问被攻击系统的LLC。因为所有的CPU内核、用户、进程、保护环等共享同一个高速缓存区,所以可为攻击者提供被攻击用户和系统的详细信息。
1.1 现代Intel CPU内存架构
现代的计算机系统通常会采用一个高速的中央处理器(CPU)和一个容量大但是速度较慢的随机存取器(RAM)。为了克服这两个模块的性能鸿沟,现代的计算机系统会采用高速缓存——一种容量小但是速度更快的内存结构,里面保存了RAM中最近被CPU访问过的子集。高速缓存通常会采用分层设计,即在CPU和RAM之间分层放置一些列逐渐变大和变慢的内存结构。图1取自文[22],展示了Intel Ivy Bridge的缓存结构,包括:较小的level 1(L1) cache,大一些的level 2 (L2) cache,最下方是最大的level 3 (L3) cache并和RAM相连。Intel 目前代号为Haswell的新一代CPU采用了另一种嵌入式的DRAM(eDRAM)设计,所以不在本文讨论范围内。如果CPU需要访问的数据当前不在缓存里,会触发一个未命中,当前缓存里的一项必须被淘汰来给新元素腾出空间。
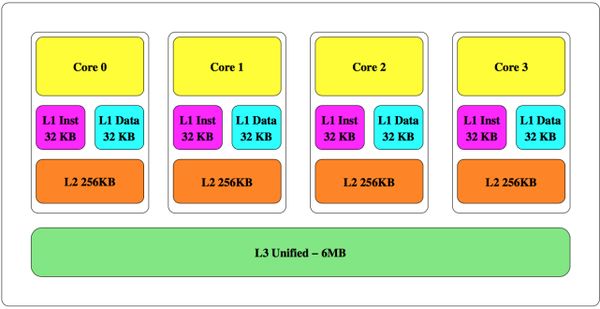
图1:Intel Ivy Bridge
Intel 的缓存微架构是嵌套的——所有一级缓存里的数据必须同时存在二级和三级缓存里。倒过来,如果某个元素在三级缓存里被淘汰,那它也会立刻从二级和一级缓存里移走。需要注意的是AMD缓存微架构的设计是非嵌套的,所以本文描述的方法并不能立刻应用到该平台上。
本文重点关注第三级缓存,通常也被称为 LLC。由于LLC较大,CPU访问内存的时候如果把整个LLC的内容都搜索一遍效率会很低。 为了避免这个问题,LLC通常被分成不同的组,每一组都对应者内存空间的一个固定的子集。每个组包含若干缓存线。例如,Intel Haswell系列中的Core i7-3720QM处理器拥有8192=2^13个组,每个组有12条64=2^6字节的缓存线,共同组成8192x12x64=6MB的高速缓存。CPU如果要检查一个给定的物理地址是否在三级缓存里,会先计算出组,然后只检查组内的缓存线。结果就是,某个物理地址的缓存未命中,会导致同一个组的为数不多的缓存线中的一条被淘汰,这个事实会被我们的攻击反复运用。由64比特长度的物理地址到13比特长度的组索引的映射方法已经被Hund等人在2013年通过逆向工程得出来 [12]。在表示物理地址的64个比特位里,5到0被忽略,16到6被直接用来作为组索引的低11位,63到17散列后得到组索引的高2位。LLC被所有的内核、线程、进程、用户,乃至运行在同一块CPU芯片上的虚拟机所共享,而不论特权环或其它类似的保护措施。
现代的个人电脑采用了一种虚拟内存机制,在这种机制里,用户进程一般无法直接得到或访问系统的物理内存。取而代之的是,进程会被分配不同的虚拟内存页。如果某个虚拟内存页被当前执行的进程访问,操作系统会在物理内存里动态地分配一个页框。CPU的内存管理单元(MMU)负责把不同进程对虚拟内存地址的访问映射到物理内存。Intel处理器的页和页框大小一般是4KB,并且页和页框的是按照页对齐的——每页的开始地址是页大小的倍数。这意味着,任何虚拟地址的低12位和对应的虚拟地址是一一对应的,这一事实也在我们的攻击中用到。
1.2 缓存攻击
缓存攻击是针对微架构的攻击手段中一个典型的代表,Aciamez在一篇出色的调查中将这类攻击定义为利用“信任架构边界下方的底层处理器结构”从不同的安全系统中获取秘密信息。缓存攻击基于这样的事实:尽管在上层有诸多像沙箱、虚拟内存、特权环,宿主这样的保障机制,安全和不安全进程通过高速缓存区的共用可以互相影响。攻击者构造一个“间谍”进程后可以通过被共用的缓存来测量和干扰其它安全进程的内部状态。Hu在1992年的首次发现[11],在随后的一些研究成果里显示了边信道攻击可被用来获取AES密匙[17][4],RSA密匙[19],甚至可以允许一台虚拟机侵入宿主上的其它机器。
我们的攻击建立在填充+探测模型的基础上,这个方法由Osvik在[17]中首次描述,不过是针对一级缓存的。之后由Yarom等人在[23]中扩展到启用了较大内存页系统的LLC。我们把这个方法扩展了一下支持更加常见的4K的页大小。总的来说,填充+探测有四个步骤。第一步,攻击者建立一个或多个移除集。移除集是内存中的一系列地址,这些地址被访问的时候会占据受害者进程使用的一条缓存线。第二步,攻击者通过访问移除集填充整个组。这会强制受害者的代码或指令被从组中淘汰,并使组进入一个已知的状态。第三步,攻击者触发或只是等待受害者执行和可能使用组。最后,攻击者通过再次访问移除集来探测组。如果访问的延迟比较低,意味着攻击者的指令或数据还在缓存里。否则,较高的访问延迟意味着受害者的代码用到了组,因此攻击者可以了解受害者的内部状态。实际的时间测量是用非特权的汇编指令RDTSC进行的,这个指令可以得到处理器非常准确的周期数。再次遍历链表还有第二个目的,那就是强制组进入 受攻击者控制的状态,为下一轮的测量做好准备。
1.3 Web运行环境
JavaScript是一种拥有动态类型、基于对象的运行时求值的脚本语言,它支撑着现代互联网的客户端。JavaScript代码以源码的形式传到浏览器端,由浏览器即时编译(JIT)机制来编译和优化。不同浏览器厂商之间的激烈竞争使不断改进JavaScript性能备受关注。结果就是,在某些场景下,JavaScript执行的效率已经可以和机器语言相媲美。
JavaScript语言的核心功能是由ECMA产业协会在ECMA-262标准中定义的。语言标准由万维网协会(W3C)定义的一系API所补充,因此适合开发Web内容。JavaScript API的集合是不断演进的,浏览器厂商依照自己的开发计划不断增加新的API支持。我们的工作中用到两个具体的API:第一个是类型数组的定义9,通过它可以高效地访问非结构化的二进制数组。第二个是高精度时间API16,让应用程序可以进行毫秒以下时间的测量。如章节5.1所示,大部分当今主流的浏览器都同时支持这两个API。
JavaScript代码运行在高度沙箱化的环境里——用JavaScript交付的代码对系统的访问非常受限。例如,JavaScript代码如果没有用户的允许不能打开和读取文件。JavaScript代码不能执行机器语言或者加载本地的代码库。最值得注意的是,JavaScript代码没有指针的概念,所以你连一个JavaScript变量虚拟地址都没法知道。
1.4 我们的工作
我们的目的是构造一个可以通过Web部署的LLC攻击。这个过程是充满挑战的,因为JavaScript代码没法加载共享库或者执行本机语言的程序,并且由于无法直接调用专用的汇编指令而被迫调用脚本语言的函数进行时间的测量。尽管有这些挑战,我们还是成功地把缓存攻击扩展到了基于Web环境:
•我们展示了一种用来在LLC上的建立非典型移除集特别方法。与[23]不同,我们的方法不要求系统配置成支持较大的内存页,所以能够很快的应用到广泛的桌面和服务器系统。我们展示了该方法虽然是使用JavaScript实现的,但是依然可以在实际的时间周期里完成。
•我们展示了一种功能完善的、无需特权的JavaScript发动LLC攻击的方法。我们用隐藏通道的方式,评估了它的性能,包括在同一个机器、不同进程之间和在虚拟机与它的主机之间。基于JavaScript的通道与[23]中用机器语言实现的方法类似,都可以达到每秒几百kb的速度。
•我们展示了怎么利用基于缓存的方法来有效地跟踪用户行为。缓存攻击的这一应用与我们的攻击模型更相关,这与密码分析在其它成果中的应用不同。
•最后,我们分析了针对攻击可能的反制措施和整个系统的代价。
2 攻击方法
正如前文所述,一次成功的填充+探测攻击包含几个步骤:为一个或多个相关组建立移除集,填充缓存,触发受害者的操作,最后再次探测组。虽然填充和探测实现起来很简单,但是要找到对应于某个系统操作的组并且为它建立移除集就不那么容易了。在本章里,我们描述了这几个步骤用JavaScript如何实现。
2.1 建立一个移除集
2.1.1 设计
正如[23]写到,填充+探测攻击方法的第一步是为某个与被攻击进程共享的组建立一个移除集。这个移除集包含一系列的变量,而且这些变量都被CPU映射到相同的组里。根据文[20]的建议,使用链表可以避免CPU的内存预读和流水线优化。我们首先展示如何为任意一个组建立一个移除集,然后解决寻找与受害者共享组的问题。
文[17]指出,一级缓存是依据虚拟地址的低位的比特来决定组分配的。假设攻击者知道变量的虚拟地址,那么在基于一级缓存的攻击模型里建立移除集很容易。但是,LLC里变量的组分配是依照物理内存的地址进行的,而且一般情况下,非特权进程无法知道。 文[23]的作者为了规避这个问题,假设系统用的是页较大的模型,在这个模型里,物理地址和虚拟地址的低21位是相同的,并通过迭代算法来获得组索引的高位。
在我们所考虑的攻击模型里,系统运行在4K的页大小模型下,物理地址和虚拟地址只有最低的12位是相同的。然而更大的难题是,JavaScript没有指针的概念,所以即使是自己定义的变量,虚拟地址也是不知道的。
从64位物理地址到13位的组索引的映射关系已经被Hund等人研究过[12]。他们发现,当访问物理内存里一段连续的、8MB大小的“淘汰缓冲区”时会让三级缓存里的所有组都失效。虽然我们在用户态下没有办法分配这样的一个“淘汰缓冲区”(实际上, 文[12]是通过内核模式的驱动实现的),我们用JavaScript在虚拟内存里分配了一个8MB大小的数组(这其实是由系统分配的随机、不连续的4K大小物理内存页的集合),然后测量遍历这个缓冲区在全系统造成的影响。我们发现在迭代访问了这个淘汰缓冲区后如果立即访问内存中其它不相关的变量,访问的延迟会显著的增加。另外一个发现是,即使不访问整个缓冲区而是每隔64字节去访问它,这个现象依然存在。但是,我们所访问的131K个偏移值到8192个可能的组的映射关系 并没有立刻清晰起来,因为我们不知道缓冲区里各个页在物理内存中的地址。
解决这个问题一个不太靠谱的做法是,给定一个任意的“受害者”在内存中的地址,通过暴力手段从131K个偏移值中找到12个与这个地址共享组的地址。要完成这点,我们可以从131K个偏移量中选取几个作为子集,在迭代了所有的偏移量后再测量下访问的延迟有没有变化。如果延迟增加了,意味着含有12个地址的子集与受害者地址共享相同的组。如果延迟没有变化,那子集里的12个地址中的任何一个都不在组里,这样受害者地址就还在缓存里。把这个过程重复8192遍,每次用一个不同的受害者地址,我们就可以识别每个组并且建立自己的数据结构。
受此启发而立刻写出来的程序会运行非常长的时间。幸运的是,Intel MMU的页帧大小(章节1.1)非常有帮助,因为虚拟地址是页对齐的,每个虚拟地址的低12位和每个物理地址的低12位是一致的。据Hund 等人所称,12个比特中的6个被用来唯一决定组索引。因此,淘汰缓冲区中的一个偏移会和其它 8K个偏移共享12到6位,而不是所有131K个。此外,只要找到一个组就能立刻知道其它的63个在相同页帧里的组的位置。再加上JavaScript分配大的数据缓存区的时是和页帧的边界对齐的,所以可以用算法1中的贪心算法。
算法1Profiling a cache set Let S be the set of unmapped pages, and address x be an arbitrary page-aligned address in memory
1. Repeat k times:
(a) Iteratively access all members of S
(b) Measure t1 , the time it takes to access x
(c) Select a random page s from S and remove it
(d) Iteratively access all members of S\s
(e) Measure t2 , the time it takes to access x
(f) If removing page s caused the memory access to speed up considerably (i.e., t1 − t2 > thres),
then this page is part of the same set as x. Place it back into S.
(g) If removing page s did not cause memory access to speed up considerably,
then this address is not part of the same set as x.
2. If |S| = 12, return S. Otherwise report failure.通过多次运行算法1,我们可以逐渐的建立一个移除集并覆盖大部分的缓存,除了那些被JavaScript运行时本身所使用的。我们注意到,与[23]中的算法建立的淘汰缓冲区不同,我们的移除集是非典型的——因为JavaScript没有指针的概念,所以如果我们发现了一个移除集,我们并没有办法知道它对应着 CPU高速缓存的哪个组。此外,在相同的机器上每次运行这个算法都会得到不同的映射。这也许是因为用了传统的4K页大小而不是2MB的页大小的原因,这个问题即使不用JavaScript用机器语言也存在。
2.1.2 验证
我们用JavaScript实现了算法1并且在安装了Ivy Bridge、Sandy Bridge、Haswell系列CPU的机器上进行验证,机器上装有Safari 和 Firefox对应运行在Mac OS Yosemite和Ubuntu 14.04 LTS操作系统上。系统并没有被配置使用大的页而是用默认的4K页大小。列表1显示了实现算法1.d和算法1.e的代码,展示了JavaScript下怎么遍历链表和测量时间。算法如果要运行在Chrome 和 Internet Explorer下,需要额外的几个步骤,在章节5.1中。
列表1
// Invalidate the cache set
var currentEntry = startAddress;
do {
currentEntry = probeView.getUint32(currentEntry);
} while (currentEntry != startAddress);
// Measure access time
var startTime = window.performance.now();
currentEntry = primeView.getUint32(variableToAccess);
var endTime = window.performance.now();通过多次运行算法1,我们可以逐渐的建立一个移除集并覆盖大部分的缓存,除了那些被JavaScript运行时本身所使用的。我们注意到,与[23]中的算法建立的淘汰缓冲区不同,我们的移除集是非典型的——因为JavaScript没有指针的概念,所以如果我们发现了一个移除集,我们并没有办法知道它对应着CPU高速缓存的哪个组。此外,在相同的机器上每次运行这个算法都会得到不同的映射。这也许是因为用了传统的4K页大小而不是2MB的页大小的原因,这个问题即使不用JavaScript用机器语言也存在。
2.1.2 验证
我们用JavaScript实现了算法1并且在安装了Ivy Bridge、Sandy Bridge、Haswell系列CPU的机器上进行验证,机器上装有Safari和Firefox 对应运行在Mac OS Yosemite 和 Ubuntu 14.04 LTS操作系统上。系统并没有被配置使用大的页而是用默认的4K页大小。列表1显示了实现算法1.d和算法1.e 的代码,展示了JavaScript下怎么遍历链表和测量时间。算法如果要运行在Chrome 和 Internet Explorer下,需要额外的几个步骤,在章节5.1中。
列表1
// Invalidate the cache set
var currentEntry = startAddress;
do {
currentEntry = probeView.getUint32(currentEntry);
} while (currentEntry != startAddress);
// Measure access time
var startTime = window.performance.now();
currentEntry = primeView.getUint32(variableToAccess);
var endTime = window.performance.now();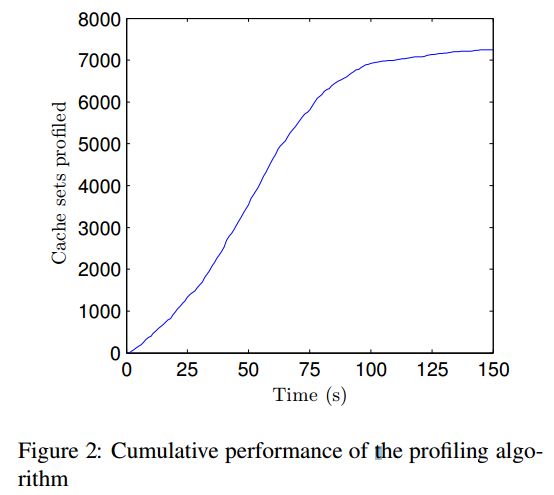
图2显示了性能分析的结果,运行在Intel i7-3720QM CPU上,装有Firefox 35.0.1和Mac OS 10.10.2。我们很高兴地发现在30秒内就映射了超过25%的组,1分钟内就达到了50%。这个算法想要并行运行是非常简单的,因为大部分的执行时间花在了数据结构的维护上,只有一小部分花在让缓存失效和测量上。整个算法用不到500行JavaScript代码就可以完成。

Figure 3: Probability distribution of access times for flushed vs. un-flushed variable (Haswell CPU)
为了验证我们的算法能够辨别不同的组,我们设计了一个实验来比较一个变量被flush前后的访问延迟。图3显示了两种方式访问变量的概率分布函数。灰色的代表用我们的方式从缓存中flush出去的变量的访问时间;而黑色是驻留在缓存里的变量的访问时间。时间的测量用到JavaScript的高精度计时器,所以还包括了JavaScript运行时的延迟。两者的不同是显而易见的。图4显示的是在较早版本的Sandy Bridge CPU上捕捉到的结果,该型号每个组有16个条目。
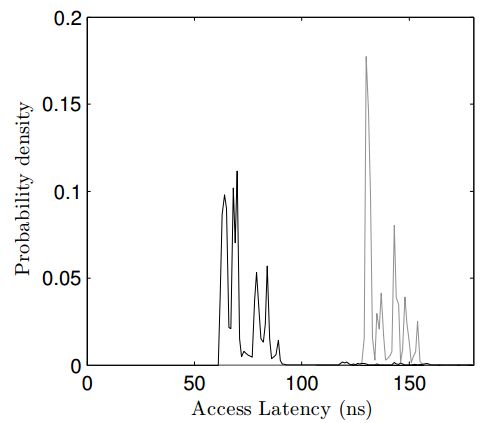
Figure 4: Probability distribution of access times for flushed vs. un-flushed variable (Sandy Bridge CPU)
通过选取一些列的组,并且不断的测量它们的访问延迟,攻击者可以获得缓存实时活动非常详细的图。我们把这种视觉呈现称作 “内存谱图”,因为它看起来很像声音的谱图。

图5显示的是每隔400ms抓取一次的内存谱图。其中X轴对应时间,Y轴对应不同的组。例子中的时间分辨率是250微秒,检测了一共128个组。每个点的密度代表了这个组在这个时间的访问延迟。黑色代表延迟较低,意味从上次测量到现在没有其它进程访问过这个组。白色意味着攻击者的数据在上次测量之后被淘汰了。
细看这个内存谱图可以得到几个显而易见的事实。首先,虽然没用机器语言指令而是用了JavaScript的计时器,测量的抖动很小,活跃和不活跃的组很容易被区分。图中有几条明显的垂直的线,意味着同一时间间隔里有多个相邻的组被访问。因为连续的组对应的物理内存的地址也是连续的,所以我们相信这个信号代表着一个超过64字节的汇编指令。还有一些聚在一起的组被同时访问。我们推断这代表着变量的访问。最后,横着的白线预示着一个变量被不断地访问。这个变量可能是属于测量代码的或属于当前的JavaScript运行时。从一个没有任何特权的网页能得到这么多信息真是太了不起了。
2.2 在缓存里识别意思的区域
移除集让攻击者能够监控任意一个组的活动。因为我们得到的移除集是非典型的,因此攻击者必须想办法把分析过的组和受害者的数据或是代码的地址关联起来。这个学习/分类的问题已经由Zhang和Yarom分别在 文[25]和文[23]里提出了,他们采用了不同的诸如SVM的机器学习的算法试图从缓存延迟的测量数据里找到规律。
为了有效地展开学习过程,攻击者需要诱导受害者做一些操作,然后检查哪些组被这个操作访问到,详见算法2。
Let Si be the data structure matched to eviction set i
1. For each set i:
(a) Iteratively access all members of Si to prime the cache set
(b) Measure the time it takes to iteratively access all members of Si
(c) Perform an interesting operation
(d) Measure once more the time it takes to iteratively access all members of Si
(e) If performing the interesting operation caused the access time to slow down considerably, then the operation was
associated with cache set i.因为JavaScript受到一系列的权限限制,实现步骤(c)是很有挑战的。与之形成对比的是Apecechea等人能够用一个空的sysenter调用来触发一次细小的内核操作。为了实现这个步骤,我们必须调查JavaScript的运行时来发现有哪些函数会触发有意思的行为,例如文件访问,网络访问,内存分配等等。我们还对那些运行时间相对较短,不会产生遗留的函数感兴趣。因为遗留可能导致垃圾回收,进而影响步骤(d)的测量。Ho等人在文章[10]中已经找到了这样的几个函数。另外一种方式是诱导用户代替攻击者执行一个特定的操作(比如在键盘上按一个键)。这个例子里的学习过程可能是结构化的(攻击者知道受害者将要执行的时机),也可能是非结构化的(攻击者只能假设系统一段时间内的响应缓慢是由受害者的操作导致的)。这两种方法都被使用,详见章节4。
因为我们的程序会一直检测到由JavaScript运行时产生的活动,比如高性能的计时器的代码,浏览器其它那些与当前执行调用无关的模块的代码,实际上我们通过调用两个相似的函数并对比它们两次活动性能分析的结果,以此来寻找相关的组。
3 基于高速缓存区的隐藏信道之JavaScript实现
3.1 动机
正如文[23]所示,LLC访问模式可被用来建立一个高带宽的隐藏信道,有效的用来在同一台宿主上的两个虚拟机之间渗透敏感的信息。在我们的攻击模型里,攻击者虽然不在同一台宿主上的虚拟机里,而是在一个网页中,隐藏信道的动机不一样,但是也很有意思。
经由动机,我们假设某个安全部门在追踪犯罪大师Bob的踪迹。该部门通过钓鱼项目在Bob的个人电脑上装了一个被称作APT(Advanced Persistent Threat)的软件。APT被设计用来记录Bob的犯罪记录并发送到部门的秘密服务器上。然而Bob非常的警觉,他使用了启用了强制信息流跟踪(Information Flow Tracking)[24]的操作系统。操作系统的这一功能阻止了APT在访问了可能含有用户隐私数据的文件后再连上网络。
在这种情况下,只要Bob能被诱导访问一个由安全部门控制的网页,这个部门就可以立刻采用基于JavaScript的高速缓存区攻击。APT可以利用基于高速缓存区的边信道和恶意网站通信,这样就不用通过网络传输用户的隐私数据,进而不会触发操作系统的信息流跟踪功能。
这个研究案例受到了来自某个安全部门的“RF retro-reflector”设计的启发,在这个设计里一台诸如麦克风的收集器,并不会把接收到的信号直接发送出去,而是把接受的信号调制到由一个外部”收集设备“发送给它的“照射信号”上去。
3.1.1 设计
隐藏信道的设计有两个需求:第一,保持发送端的简单,我们尤其不想让它执行章节2.1中的移除集算法。第二,因为接收端的移除集是非典型的,它应该足够简单,这样接收端就可以搜索到发送端的信号调制到了哪一个组。
为了满足这些需求,我们的发射器/APT在自己的内存中分配了4K大小的数组,并且不断地把收集到的数据转换成对与这个数组的内存访问的模式。这个4K大小的数组覆盖了缓存的64个组,这样APT在每个时间周期里就能传送64比特的数据。为了能保证内存访问能够被接收端定位,相同的访问模式被重复运用到数组的几个拷贝上。因此,高速缓冲区的大部分都会被执行到,与之形成对比的是文[23]中的方法使用了典型的移除集,因此只会激活两条缓存线。
接收端的代码会对操作系统的内存做一个性能分析,然后搜索含有被APT调制后的数据所在的页框。真正的数据会被从内存访问的模式里解调出来然后传回服务器,整个过程都不会违背操作系统对信息流跟踪的保护。
3.1.2 评估
我们的攻击模型假设发送端使用(相对较快的)机器语言编写,而接收端是用JavaScript编写。所以,我们假设整个系统性能的限制因素是恶意网站的采样速度。
为了评估隐藏信道的带宽,我们写了一个小程序用预先设定好的模式来遍历系统的内存(即含有单词”Usenix”的比特图)。接下来,我们用JavaScript高速缓存攻击来尝试寻找这一访问模式,并测量JavaScript代码所能达到的最大的频率。

图6显示的内存谱图捕捉到了这一隐藏信道的执行。隐藏信道的理论带宽通过测量大约是320kbps,这和文[23]中用机器语言实现的跨虚拟机的隐藏信道1.2Mbps的带宽比较吻合。

图7中的内存谱图比较相似,但并不是由运行在相同主机上的接收端代码得到的,而是在一台虚拟机上得到的(Firefox 34浏览器,Ubuntu 14.01 系统, VMWare Fusion 7.1.0)。尽管在这个场景下的高峰频率只能到大约8kbps,但是一个虚拟机中的网页竟然能够探测到底层的硬件,这着实让人惊讶。
4 利用高速缓存区攻击跟踪用户行为
绝大多数关于高速缓存区攻击的研究都假设攻击者和受害者位于云计算供应商数据中心里的同一台机器上。这样的机器一般不会配置成接收交互式的输入,所以该领域的大部分研究都聚焦于如何获得加密钥匙或其它保密的状态信息,譬如随机数生成器的状态[26]。本文将研究怎么利用高速缓存区攻击来跟踪用户的行为,这和我们的攻击模型更相关。我们注意到文[20]已经尝试了利用CPU的一级缓存对系统负载进行细粒度的度量,以此跟踪按键事件的方法。
本案例将演示一个恶意网站怎么用高速缓存区攻击去跟踪用户的活动。在接下来展示的的攻击里,我们会假设用户在一个背景标签页或窗口里打开了一个恶意网站的页面,并且在另一个标签页或是另外一个完全没有互联网连接的应用里执行了一些敏感的操作。
我们选择了把焦点集中在鼠标操作和网络活动上,因为操作系统负责处理它们的代码没有办法被忽略不计。所以,我们期待这些操作会在高速缓存区留下比较大的脚印。而且正如下文所述,它们也很容易被JavaScript处处受限的安全模型所触发。
4.1 设计
两种攻击的结构比较类似。首先,进行性能分析,攻击者用JavaScript探测每一个组。接着,在训练阶段,待检测的活动(网络活动或鼠标操作)被触发,伴随着对高速缓存区的高精度的采样。在训练阶段一方面通过测量脚本直接触发网络活动(执行一个网络请求),另一方面是不停地在网页上摇晃鼠标。
通过比较在训练阶段缓存区在闲时和忙时的活动,攻击者可以知道用户操作会对应激活哪部分的组,并且训练出一个关于组的分类器。最后,在分类阶段,攻击者不停地监视这些有意思的组从而掌握用户的活动。
我们用一个基本的非结构化的训练过程,即假设训练过程中系统进行的最集中的操作就是被测量的。为了利用这点,我们计算了随着时间的每次测量的Hamming权重(等于在某个周期内活跃组的个数),之后应用k-meas算法对测量数据做聚类。然后计算每个簇中每个组的平均访问延迟,从而算出每个簇的中心。遇到未知的测量矢量,我们会计算这个矢量和各个中心的欧几里得距离,并把它归到最近的那一类。
在分类阶段,我们用命令行工具wget生成网络流量,并且将鼠标移动到窗口以外。为了获得网络活动的真实数据,我们同时用tcp-dump来测量系统的流量,然后把tcp-dump记录的时间戳和分类器所检测到时间戳联系起来。为了获得鼠标操作的真实数据,我们写了一个页面记录所有鼠标事件及其时间戳。需要强调的是,记录鼠标活动的页面并不在运行着测量代码的浏览器(Firefox),而是运行在另一个浏览器里(Chrome)。
4.2 验证
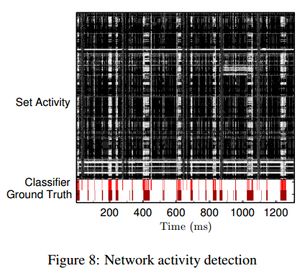
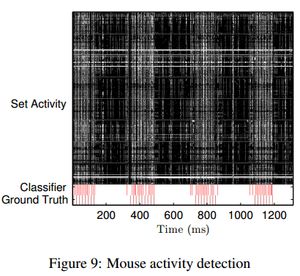
活动测量的结果见图8和图9。两个图片的顶端都显示了高速缓存区一个子集的实时活动。图片的底端是分类器的输出结果和外部收集的真实数据。正如图片展示的那样,我们异常简单的分类器在识别鼠标操作和网络活动方面非常有效。毫无疑问,使用更加高级的训练和分类技巧可以进一步提高攻击的效果。需要强调的是,鼠标操作的检测器并不会检测网络活动,反之亦然。
分类器的测量频率只有500Hz。结果就是,它没有办法统计单个的包,而只能说明在一个阶段里活跃还是不活跃。另一方面,检测鼠标活动的代码要比记录真实数据的代码采集到的事件多。这是因为Chrome浏览器对鼠标事件的频率做了限制,大约是60Hz。
Chen等人在一篇著名的文[5]中证明了对网络活动的监测可以作为深度挖掘用户行为的奠基石。虽然Chen等人假设攻击者可以在网络层监控受害者所有流入和流出的数据,但是这里所展示的技术本质上可以让恶意网站监控用户同时进行的网络操作。攻击可以被更多的指标增强,例如内存分配(见文[13]),DOM布局事件,磁盘写操作等。
5 结论
本文显示了边信道攻击的范围要比预期的大很多。本文提出的攻击可针对互联网上的大部分机器而不局限于某些特定的攻击场景。如此众多的系统突然间易受边信道攻击意味着防止边信道攻击的算法和系统应当被广泛使用,而不能只是在某些特定情况下。
5.1 易被攻击系统的普遍性
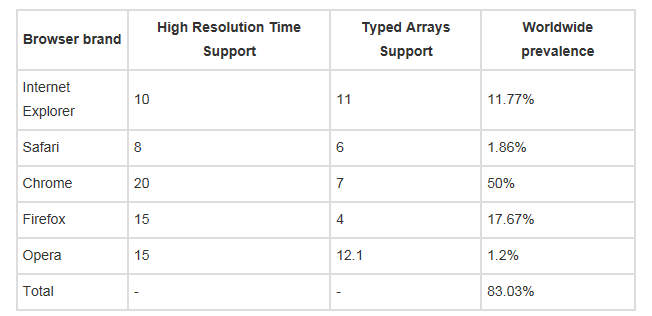
我们的攻击需要一台个人计算机,并配有Intel CPU,使用了Sandy Bridge、Ivy Bridge、Haswell或者Broadwell的微架构。据IDC的数据显示,2011年以后售出的个人计算机80%都满足这一条件。更进一步,假设用户使用的浏览器支持HTML5高精度计时器和类型数组的规范。表1列举了各个浏览器厂商支持这些API的最早的版本和易被攻击的版本占全球互联网流量的比重,统计数据来自StatCounterGlobalStatas 2015年一月份的报告。如表所示,目前市场上80%的浏览器都无法抵御此类攻击。
攻击能否取得效果取决于能不能用JavaScript高精度时间API进行精准的测量。虽然W3C对这个API规范定义了高精度时间的单位是“毫秒,并精确到千分之一”,但是它并没有给出该值的最高分辨率,实际上浏览器不同、操作系统不同这个值也会有所区别。举个例子,我们在测试过程中发现MacOS上的Safari浏览器可以精确到纳秒,而Windows上的IE浏览器只能精确到0.8微秒。另一方面,Chrome 浏览器在所有我们测试的操作系统上给出的分辨率都是1微秒。
所以图3中,单次缓存命中和缓存未命中的差别大概是50纳秒,性能分析和测量的脚本在时间分辨率力度更细的操作系统上要稍加改动。在性能分析阶段,我们没有统计单次未命中的时间,而是重复读取内存来放大时间的差别。在测量阶段,我们虽然没有办法放大每次缓存未命中的时间,但是我们可以利用来自相同页框的代码通常会让相邻的组失效这一点。只要同一个页框的64个组里有20个产生了缓存未命中,我们的攻击就可以在哪怕是毫秒级的分辨率上进行。
我们提出的这种攻击还可以很容易的运用到手机、平板等移动设备上。值得一提的是,安卓浏览器从4.4版本开始支持高精度时间API和类型数组,但在本文撰写的时候iOS Safari (8.1)还不支持高精度时间API。
5.2 反制措施
本文描述的攻击之所以可行,是因为它聚集了从微架构这一层到最终的JavaScript运行时设计和实现的的一些决定:怎么把物理内存的地址映射到组,嵌套的高速缓存区架构,JavaScript高速的内存访问和高精度计时器;最后是JavaScript的权限模型。这里的每一点上都可以采取一些缓解措施,但是都会对系统的正常使用产生影响。
在微架构这层,修改物理内存到缓存线的映射方式可以非常有效地阻止我们的攻击,即不再用地址底12比特中的6个直接选择一个组。类似的,换用非嵌套的缓存微架构而不是用嵌套的,会让我们的代码几乎不肯能精确地一级缓存中淘汰某项,使得测量更加困难。然而,这两个设计决定当初被选择正是为了让CPU的设计和高速缓存的使用更高效,改变它们会让其它很多的应用性能受到影响。再说了,修改CPU微架构可不是一件小事,因为升级已经部署的硬件是肯定不行的。
在JavaScript这层,似乎降低高精度计时器的分辨率就可以让攻击更难发动。但是,高精度计时器的建立是为了解决JavaScript开发者的实际需要的,这些应用范围可从音乐和游戏再到增强现实和远程医疗。
一个可能的权宜之计是限制应用只有在获得了用户许可后才能访问计时器(例如,通过显示一个确认窗口)或者通过第三方的认可(例如下载自可信的“appstore”)。
一种有意思的方式是使用启发式的性能分析来检测和阻止此类攻击。如Wang等人利用大量算法和按位指令的存在可以预示这密码学应用元素[21]的存在,可以注意到我们的攻击里各种测量步骤访问内存也会有一定的模式。因为现代的JavaScript的运行时,作为性能分析引导优化的机制的一部分,已经能够 详细的检查代码的运行时性能。所以JavaScript运行时应该能够在执行时发现有性能分析行为的代码并且相应的修改返回结果(例如,在高精度计时器里加上抖动,或者动态的调整数组在内存中的位置等)。
5.3 结论
在这篇论文里,我们展示了如何有效地通过可疑网页发起针对微架构的边信道攻击,这种方式已被认为是非常有效的。 与高速缓存区攻击一般被用于密码分析应用不同,本文介绍了它怎么被用来有效地跟踪用户行为。 边信道攻击的范围已被拓展,这意味着设计新的安全系统时一定要考虑到对边信道攻击的反制措施。
致谢
我们很感谢激Henry Wong对于Ivy Bridge缓存淘汰策略的研究和Burton Rosenberg对于页和页框的讲解。
论文作者和单位
- Yossef Oren (yos AT cs.columbia.edu)
- Vasileios P. Kemerlis (vpk AT cs.columbia.edu)
- Simha Sethumadhavan (simha AT cs.columbia.edu)
- Angelos D. Keromytis (angelos AT cs.columbia.edu)
原文内容:http://www.csdn.net/article/2015-05-21/2824743