HashMap
原则上,hashmap的插入和搜索,复杂度都是1,是非常快速的跟你的容量大小通常是没有直接关系的但是这是理想的情况。 这里说的理想,是在你所存储的对象的hashcode这个方法写的非常有效的情况下。根据hash的原理,存放一个对象是根据他的hashcode来计算的,如果没有哈希冲突,那么他的存储效率是最高,最完美的。 为什么哈希冲突会使得效率下降呢? 具体来分析,假设一个对象O1,他的hashcode算出来是1,另一个对象是O2,hashcode算起来也是1. 先放入O1对象,这时候速度很快,根据hashcode计算出来这个对象应该在哪个位置存放,然后直接放进去。但是到了放O2的时候,根据hashcode计算的地址存放,发现之前已经有O1了,那么显然是不能放的,因此就要采取些措施,比如,再计算一次,然后分配存放的地址(如果冲突,将继续,知道解决),一种最恶劣的情况下,很多很多的对象都存在hash冲突,那么重要就变得存储越来越慢。但是这个不是hashmap的责任,而是你的对象的hashcode方法没有定义好,使得冲突频繁 另外,哈希表为了避免这种冲突,会有一点优化。简单的说,原本可以放100个数据的空间,当放到80个的时候,根据经验,接下去冲突的可能性会更加高,就好比一个靶子上80%都是箭的时候你再射一箭出去,射中箭的可能性很大。因此就自动增加空间来减小冲突可能性。 80/100 = 0.8 这个0.8就是负载因子。 java中的hashmap的负载因子是0.75说了写理论。说这个的原因是想解释一下你的疑问“10000条的时候在搜索的时候很快,那么在多少条的时候可能导致效率下降呢”。这个答案是肯定的,就是存储的量跟存储效率没有直接的关系。 这页是hash表这个数据结构的优势所在 如果你觉得效率出现问题的时候,应该去关注一下你的存储对象的hashcode方法写的是否有问题 如果想更完美的解决效率问题,还可以手动指定hashmap的负载因子(用HashMap(int factor)这个构造方法),负载因子越低,冲突可能越小。但是牺牲的空间会相应增加
如果还是不能很好理解,可以先参看hash这个数据结构的特点,和JDK中HashMap的源代码,以及注释
学好java,数据结构是很重要的,理解原理的使用,跟生搬硬套的使用,不可同年而语 所以,去面试淘宝,腾讯,化为这种公司不会问你struts怎么用,只会问你struts怎么写。如同不会问你hashmap怎么用,而会问你hashmap的设计理念,和实现原理
1.HashMap的数据结构
数组的特点是:寻址容易,插入和删除困难;而链表的特点是:寻址困难,插入和删除容易。那么我们能不能综合两者的特性,做出一种寻址容易,插入删除也容易的数据结构?答案是肯定的,这就是我们要提起的哈希表,哈希表有多种不同的实现方法,我接下来解释的是最常用的一种方法—— 拉链法,我们可以理解为“链表的数组” ,如图:
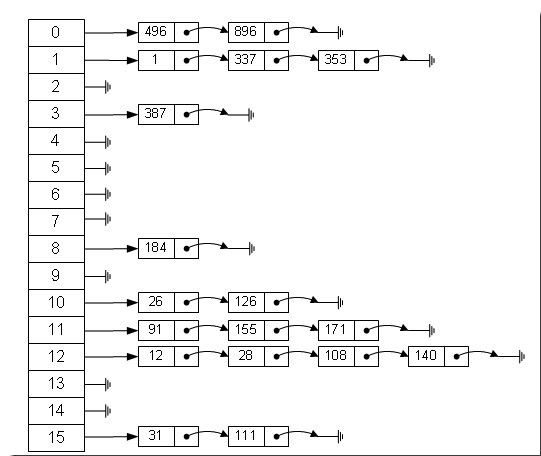
从上图我们可以发现哈希表是由数组+链表组成的,一个长度为16的数组中,每个元素存储的是一个链表的头结点。那么这些元素是按照什么样的规则 存储到数组中呢。一般情况是通过hash(key)%len获得,也就是元素的key的哈希值对数组长度取模得到。比如上述哈希表 中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都存储在数组下标为12的位置。
HashMap其实也是一个线性的数组实现的,所以可以理解为其存储数据的容器就是一个线性数组。这可能让我们很不解,一个线性的数组怎么实现按键值对来存取数据呢?这里HashMap有做一些处理。
1.首先HashMap里面实现一个静态内部类Entry,其重要的属性有 key , value, next,从属性key,value我们就能很明显的看出来Entry就是HashMap键值对实现的一个基础bean,我们上面说到HashMap的基 础就是一个线性数组,这个数组就是Entry[],Map里面的内容都保存在Entry[]里面。
2.HashMap的存取实现
既然是线性数组,为什么能随机存取?这里HashMap用了一个小算法,大致是这样实现:

//存储时: int hash = key.hashCode();// 这个hashCode方法这里不详述,只要理解每个key的hash是一个固定的int值 int index = hash % Entry[].length; Entry[index] = value; //取值时: int hash = key.hashCode(); int index = hash % Entry[].length; return Entry[index];
到这里我们轻松的理解了HashMap通过键值对实现存取的基本原理
3.疑问:如果两个key通过hash%Entry[].length得到的index相同,会不会有覆盖的危险?
这里HashMap里面用到链式数据结构的一个概念。上面我们提到过Entry类里面有一个next属性,作用是指向下一个Entry。打个比 方, 第一个键值对A进来,通过计算其key的hash得到的index=0,记做:Entry[0] = A。一会后又进来一个键值对B,通过计算其index也等于0,现在怎么办?HashMap会这样做:B.next = A,Entry[0] = B,如果又进来C,index也等于0,那么C.next = B,Entry[0] = C;这样我们发现index=0的地方其实存取了A,B,C三个键值对,他们通过next这个属性链接在一起。所以疑问不用担心。也就是说数组中存储的是最后插入的元素。到这里为止,HashMap的大致实现,我们应该已经清楚了。
当然HashMap里面也包含一些优化方面的实现,这里也说一下。比如:Entry[]的长度一定后,随着map里面数据的越来越长,这样同一 个index的链就会很长,会不会影响性能?HashMap里面设置一个因素(也称为因子),随着map的size越来越大,Entry[]会以一定的规 则加长长度。
3.解决hash冲突的办法
- 开放定址法(线性探测再散列,二次探测再散列,伪随机探测再散列)
- 再哈希法
- 链地址法
- 建立一个公共溢出区
Java中hashmap的解决办法就是采用的链地址法。
参考文献:
1、http://www.cnblogs.com/xwdreamer/archive/2012/05/14/2499339.html