FCOS 论文学习
1. 解决了什么问题?
之前的目标检测器如 RetinaNet、SSD、YOLOv3 都依赖于 anchors。基于 anchors 的检测器有如下三个缺点:
- 检测表现对于 anchors 的大小、宽高比和数量等超参数很敏感;
- 即使精心设计了 anchors,但由于大小和宽高比都是固定的,检测器很难处理形状变化很大的物体,比如小目标;
- 为了提高召回率,基于 anchor 的检测器会在输入图像上放置大量的 anchor boxes。训练时,这里面的大多数都是负样本,造成
正负样本不均衡;
- Anchor boxes 会带来复杂的计算,如计算 anchor box 和 gt box 的 IOU。
之前的基于 FCN 的框架有以下几个问题:
- 全卷积网络在语义分割、深度估计、关键点检测等任务上效果不错,唯独目标检测任务很少用全卷积、逐像素预测的架构;
- DenseBox 利用了全卷积网络的架构,但是在图像金字塔上完成检测,与 FCN 思想相悖,对于重叠目标的检测效果不好,无法分辨重叠区域内像素属于哪个边框。
2. 提出了什么方法?
将目标检测任务以逐像素预测的方式解决,提出了一个无需 anchor、无需 proposal 的检测方法。
2.1 全卷积单阶段目标检测器
主干 CNN 网络的第 i i i层特征图记做 F i ∈ R H × W × C F_i\in \mathbb{R}^{H\times W\times C} Fi∈RH×W×C, s s s是到当前层的总步长。输入图像的 ground-truth 边框记做 { B i } \lbrace B_i\rbrace {Bi},其中 B i = ( x 0 ( i ) , y 0 ( i ) , x 1 ( i ) , y 1 ( i ) , c ( i ) ) ∈ R 4 × { 1 , 2 , . . . , C } B_i=(x_0^{(i)},y_0^{(i)},x_1^{(i)},y_1^{(i)},c^{(i)})\in \mathbb{R}^4 \times \lbrace 1,2,...,C\rbrace Bi=(x0(i),y0(i),x1(i),y1(i),c(i))∈R4×{1,2,...,C}。这里 ( x 0 ( i ) , y 0 ( i ) ) (x_0^{(i)},y_0^{(i)}) (x0(i),y0(i))和 ( x 1 ( i ) , y 1 ( i ) ) (x_1^{(i)},y_1^{(i)}) (x1(i),y1(i))表示边框左上角和右下角的坐标。 c ( i ) c^{(i)} c(i)是该边框内目标的类别, C C C是类别数。
特征图 F i F_i Fi上的每个点 ( x , y ) (x,y) (x,y)可以映射回输入图像的坐标 ( ⌊ s 2 ⌋ + x s , ⌊ s 2 ⌋ + y s ) (\lfloor \frac{s}{2}\rfloor+xs,\lfloor \frac{s}{2}\rfloor+ys) (⌊2s⌋+xs,⌊2s⌋+ys),位于 ( x , y ) (x,y) (x,y)感受野的中心附近。Anchor-based 检测器将输入图像上的每个位置看作 anchor boxes 的中心点,然后根据这些 anchor boxes 回归出目标框,而 FCOS 是直接回归目标框。FCOS 将每个位置都看作为训练样本,这与语义分割里面的 FCN 一样。

如果位置 ( x , y ) (x,y) (x,y)落在任意一个 ground-truth 框内,则认为它是正样本,该位置的类别标签 c ∗ c^* c∗就是 ground-truth 框的类别。否则,该位置就是负样本,类别标签 c ∗ = 0 c^*=0 c∗=0(背景类)。此外,该位置还有一个 4D 向量 t ∗ = ( l ∗ , t ∗ , r ∗ , b ∗ ) \mathbf{t}^*=(l^*,t^*,r^*,b^*) t∗=(l∗,t∗,r∗,b∗)作为回归目标。 l ∗ , t ∗ , r ∗ , b ∗ l^*,t^*,r^*,b^* l∗,t∗,r∗,b∗分别是该位置到边框四条边的距离。如果一个位置落在多个边框内,则认为它是模糊样本。选择面积最小的边框作为回归目标。通过多层级预测,模糊样本数量能大幅降低,因此很难影响检测表现。如果一个位置 ( x , y ) (x,y) (x,y)与边框 B i B_i Bi关联,则该位置的训练回归目标写作:
l ∗ = x − x 0 ( i ) , t ∗ = y − y 0 ( i ) l^*=x-x_0^{(i)},\quad\quad t^*=y-y_0^{(i)} l∗=x−x0(i),t∗=y−y0(i)
r ∗ = x 1 ( i ) − x , b ∗ = y 1 ( i ) − y r^*=x_1^{(i)}-x,\quad\quad b^*=y_1^{(i)}-y r∗=x1(i)−x,b∗=y1(i)−y
FCOS 能利用尽可能多的前景样本来训练回归任务,而基于 anchor 的检测器只会将与 ground-truth 框 IOU 足够大的样本作为正样本。
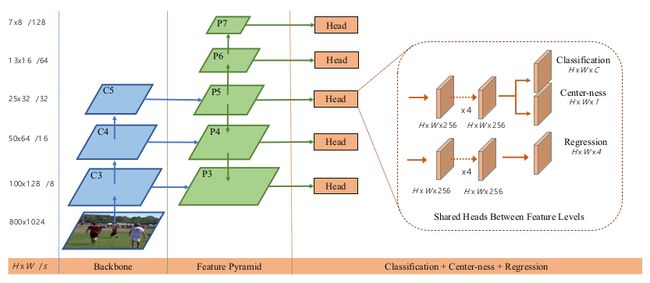
网络输出
最后一层预测一个 80 80 80维向量 p p p的分类标签,以及一个 4 4 4维的向量 t = ( l , t , r , b ) \mathbf{t}=(l,t,r,b) t=(l,t,r,b)的边框坐标。它没有训练一个多类别分类器,而是训练 C C C个两类别的分类器。在主干网络特征图后面,加了4个卷积层,分别用于类别预测和坐标回归。因为回归的目标总是正数,故而在回归分支上使用了 exp ( x ) \exp(x) exp(x)将任意实数映射到 ( 0 , ∞ ) (0,\infty) (0,∞)范围。FCOS 的输出变量要比基于 anchor 的检测器少了 9 × 9\times 9×,因为基于 anchor 的检测器一般会在每个位置使用 9 9 9个 anchor boxes。
损失函数
损失函数定义为:
L ( { p x , y } , { t x , y } ) = 1 N p o s ∑ x , y L c l s ( p x , y , c x , y ∗ ) + λ N p o s ∑ x , y I { c x , y ∗ > 0 } L r e g ( t x , y , t x , y ∗ ) L(\lbrace p_{x,y}\rbrace,\lbrace t_{x,y}\rbrace)=\frac{1}{N_{pos}}\sum_{x,y}L_{cls}(p_{x,y},c^*_{x,y})+\frac{\lambda}{N_{pos}}\sum_{x,y}\mathbb{I}_{\lbrace c^*_{x,y}>0\rbrace L_{reg}(t_{x,y},t^*_{x,y})} L({px,y},{tx,y})=Npos1x,y∑Lcls(px,y,cx,y∗)+Nposλx,y∑I{cx,y∗>0}Lreg(tx,y,tx,y∗)
L c l s L_{cls} Lcls是 focal loss, L r e g L_{reg} Lreg是 IOU 损失。 N p o s N_{pos} Npos是正样本个数, λ = 1 \lambda=1 λ=1是平衡 L r e g L_{reg} Lreg的权重。对特征图 F i F_i Fi所有的点进行计算求和。 I { c i ∗ > 0 } \mathbb{I}_{\lbrace c_i^*>0\rbrace} I{ci∗>0}是指标函数,当 c i ∗ > 0 c^*_i>0 ci∗>0则为 1 1 1,不然为 0 0 0。
推理
FCOS 推理很直接。给定输入图像,经过网络得到特征图 F i F_i Fi上每个位置的分类得分 p x , y p_{x,y} px,y和回归目标 t x , y t_{x,y} tx,y,将 p x , y > 0.05 p_{x,y}>0.05 px,y>0.05的当作正样本,进而得到预测框。
2.2 FPN 多层级预测
有两类问题可以通过 FPN 多层级预测得到解决。
- CNN 最后一层的输出特征图如果步长很大,会造成很低的召回率。对于 FCOS,看上去似乎其召回率要低于 anchor-based 方法,因为大步长可能造成有些物体无法出现在最后一层特征图上。但本文发现,FCOS 的召回率并不低。此外,有了 FPN 加持,其召回率能进一步得到提升。
- Ground-truth 边框重叠可能引起一定歧义,重叠区内的一个点应该属于哪个目标框?通过多层级预测,这类歧义可以被有效解决。
根据 FPN,我们可以在不同层级特征图上检测出不同大小的目标。可以使用的特征图有 { P 3 , P 4 , P 5 , P 6 , P 7 } \lbrace P_3,P_4,P_5,P_6,P_7\rbrace {P3,P4,P5,P6,P7}, P 3 , P 4 , P 5 P_3,P_4,P_5 P3,P4,P5是对主干网络的 C 3 , C 4 , C 5 C_3,C_4,C_5 C3,C4,C5特征图使用 1 × 1 1\times 1 1×1卷积和 top-down 连接得到。对 P 5 P_5 P5使用一个步长为 2 2 2的卷积得到 P 6 P_6 P6,再对 P 6 P_6 P6使用一个步长为 2 2 2的卷积得到 P 7 P_7 P7。因此 P 3 , P 4 , P 5 , P 6 , P 7 P_3,P_4,P_5,P_6,P_7 P3,P4,P5,P6,P7的步长分别是 8 , 16 , 32 , 64 , 128 8,16,32,64,128 8,16,32,64,128。
Anchor-based 检测器会为不同的特征层级分配不同大小的 anchor boxes,而 FCOS 直接约束每个层级的边框回归大小的范围。
- 首先计算所有的特征层级上每个位置的回归目标 l ∗ , t ∗ , r ∗ , b ∗ l^*,t^*,r^*,b^* l∗,t∗,r∗,b∗。
- 然后,如果一个位置满足 max ( l ∗ , t ∗ , r ∗ , b ∗ ) > m i \max(l^*,t^*,r^*,b^*)>m_i max(l∗,t∗,r∗,b∗)>mi或 max ( l ∗ , t ∗ , r ∗ , b ∗ ) < m i − 1 \max(l^*,t^*,r^*,b^*)
m i m_i mi是某一特征层级 i i i回归的最大距离。本文, m 2 , m 3 , m 4 , m 5 , m 6 , m 7 m_2,m_3,m_4,m_5,m_6,m_7 m2,m3,m4,m5,m6,m7分别设为 0 , 64 , 128 , 256 , 512 , ∞ 0,64,128,256,512,\infty 0,64,128,256,512,∞。这样,不同大小的物体会分到不同的特征层级上,大多数的重叠物体的尺度也不相同。如果一个位置仍然被分配到了多个 ground-truth 边框内,我们直接选择面积最小的 ground-truth 框作为目标。
不同的特征层级共享 heads,不仅可以节省了参数,也能提高表现。但是,作者发现不同特征层回归不同的大小范围,因此对不同特征层级使用相同配置的 heads 并不合理。于是,作者使用了 exp ( s i x ) \exp(s_ix) exp(six)代替了 exp ( x ) \exp(x) exp(x), s i s_i si是一个可训练的标量,自动调节 P i P_i Pi特征层级的 exp \exp exp函数,可提高检测表现。
2.3 Center-ness
仍然会出现许多的低质量预测框,这些低质量预测框的位置距离目标中心点较远。作者提出了一个简单有效的办法来抑制这些低质量预测框。增加了一个分支来预测位置的 center-ness,它只有一层,与分类分支并行。Center-ness 表示某个位置到其对应的目标中心点的归一化距离。给定某位置的回归目标 l ∗ , t ∗ , r ∗ , b ∗ l^*,t^*,r^*,b^* l∗,t∗,r∗,b∗,center-ness 目标定义为:
centerness ∗ = min ( l ∗ , r ∗ ) max ( l ∗ , r ∗ ) × min ( t ∗ , b ∗ ) max ( t ∗ , b ∗ ) \text{centerness}^*=\sqrt{\frac{\min(l^*,r^*)}{\max(l^*, r^*)}\times \frac{\min(t^*,b^*)}{\max(t^*, b^*)}} centerness∗=max(l∗,r∗)min(l∗,r∗)×max(t∗,b∗)min(t∗,b∗)
使用 \sqrt{} 来降低 center-ness 衰减的速度。Center-ness 的范围在 0 0 0到 1 1 1之间,可用 BCE 损失训练,该损失加到上面损失函数里面。测试时,将预测 center-ness 得分和相应的分类得分乘起来,得到最终得分。Center-ness 可以降低远离目标中心点的边框的得分。这样 NMS 就可过滤掉这些低质量边框,提升检测表现。

如果不用 center-ness 得分,可以将 ground-truth 边框的中间一块区域当作正样本,但这就需要一个超参数了。