【SpringBoot新手篇】SpringBoot集成JPA
【SpringBoot新手篇】SpringBoot集成JPA
- Spring Boot Jpa 介绍
-
- 首先了解 Jpa 是什么?
- Spring Data JPA
- 特征
- 整合SpringData JPA
-
- Pom
- yml
- entity
- Repository
- UserService
- UserServiceImpl
- controller
- 首页展示
- 高级查询功能
-
-
- 预先生成方法
- 自定义简单查询
- 复杂查询
-
- 分页查询
- 限制查询
-
Spring Boot Jpa 介绍
首先了解 Jpa 是什么?
Jpa (Java Persistence API)是 Sun官方提出的Java 持久化规范。它为 Java 开发人员提供了一种对象/关联映射工具来管理 Java 应用中的关系数据。它的出现主要是为了简化现有的持久化开发工作和整合 ORM 技术,结束现在Hibernate,TopLink,JDO等ORM 框架各自为营的局面。
值得注意的是,Jpa是在充分吸收了现有Hibernate,TopLink,JDO 等 ORM 框架的基础上发展而来的,具有易于使用,伸缩性强等优点。从目前的开发社区的反应上看,Jpa 受到了极大的支持和赞扬,其中就包括了 Spring 与EJB3. 0的开发团队。
注意:Jpa 是一套规范,不是一套产品,那么像 Hibernate,TopLink,JDO 他们是一套产品,如果说这些产品实现了这个 Jpa 规范,那么我们就可以叫他们为 Jpa 的实现产品。
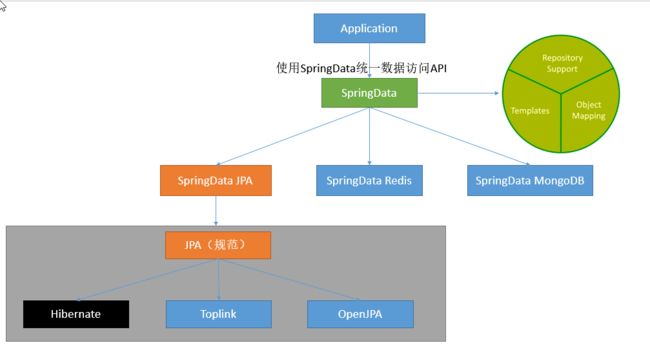
Spring Data JPA
Spring Data JPA是较大的Spring Data系列的一部分,可轻松实现基于JPA的存储库。该模块处理对基于JPA的数据访问层的增强支持。它使构建使用数据访问技术的Spring支持的应用程序变得更加容易。
实现应用程序的数据访问层已经很长一段时间了。为了执行简单查询以及执行分页和审核,必须编写太多样板代码。Spring Data JPA旨在通过将工作量减少到实际需要的数量来显着改善数据访问层的实现。作为开发人员,您将编写包括自定义finder方法在内的存储库接口,Spring会自动提供实现。
Spring Boot Jpa 让我们解脱了 DAO 层的操作,基本上所有 CRUD 都可以依赖于它来实现
特征
- 基于Spring和JPA构建存储库的先进支持
- 支持Querydsl谓词,从而支持类型安全的JPA查询
- 域类的透明审核
- 分页支持,动态查询执行,集成自定义数据访问代码的能力
@Query引导时验证带注释的查询- 支持基于XML的实体映射
- 通过引入基于JavaConfig的存储库配置
@EnableJpaRepositories。
整合SpringData JPA
Pom
<!--web start-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--web end-->
<!--thymeleaf start-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>
<!--jpa start-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
yml
spring:
datasource:
url: jdbc:mysql://localhost:3306/book_springboot?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=false
username: root
password: root
initial-size: 1
min-idle: 1
max-active: 20
test-on-borrow: true
# MySQL 8.x: com.mysql.cj.jdbc.Driver
driver-class-name: com.mysql.jdbc.Driver
jpa:
hibernate:
ddl-auto: update
# 更新或者创建数据表结构
dialect: org.hibernate.dialect.MySQL5InnoDBDialect
# 控制台显示SQL
show-sql: true
entity
@Data
@AllArgsConstructor
@NoArgsConstructor
//使用JPA注解配置映射关系
@Entity //告诉JPA这是一个实体类(和数据表映射的类)
@Table(name = "tbl_user") //@Table来指定和哪个数据表对应;如果省略默认表名就是user;
public class User {
@Id //这是一个主键
@GeneratedValue(strategy = GenerationType.IDENTITY)//自增主键
private Integer id;
@Column(name = "last_name",length = 50) //这是和数据表对应的一个列
private String lastName;
@Column //省略默认列名就是属性名
private String email;
Repository
//继承JpaRepository来完成对数据库的操作
public interface UserRepository extends JpaRepository<User,Integer> {
}
UserService
package cn.zysheep.springboot.service;
import cn.zysheep.springboot.entity.User;
import java.util.List;
public interface UserService {
List<User> getUserList();
User findUserById(long id);
void save(User user);
void edit(User user);
void delete(long id);
}
UserServiceImpl
@Service
public class UserServiceImpl implements UserService {
@Autowired
private UserRepository userRepository;
@Override
public List<User> getUserList() {
return userRepository.findAll();
}
@Override
public User findUserById(long id) {
return userRepository.findById(id);
}
@Override
public void save(User user) {
userRepository.save(user);
}
@Override
public void edit(User user) {
userRepository.save(user);
}
@Override
public void delete(long id) {
userRepository.deleteById(id);
}
}
controller
@Controller
public class IndexController {
@Resource
UserService userService;
@RequestMapping("/")
public String index() {
return "redirect:/list";
}
@RequestMapping("/list")
public String list(Model model) {
List<User> users = userService.getUserList();
model.addAttribute("users", users);
return "user/list";
}
@RequestMapping("/toAdd")
public String toAdd(Model model) {
model.addAttribute("user", new User());
return "user/userEdit";
}
@RequestMapping("/add")
public String add(User user) {
userService.save(user);
return "redirect:/list";
}
@RequestMapping("/toEdit")
public String toEdit(Model model, Long id) {
User user = userService.findUserById(id);
model.addAttribute("user", user);
return "user/userEdit";
}
@RequestMapping("/edit")
public String edit(User user) {
userService.edit(user);
return "redirect:/list";
}
@RequestMapping("/delete")
public String delete(Long id) {
userService.delete(id);
return "redirect:/list";
}
}
首页展示

高级查询功能
基本查询也分为两种,一种是 Spring Data 默认已经实现,一种是根据查询的方法来自动解析成 SQL。
预先生成方法
Spring Boot Jpa 默认预先生成了一些基本的CURD的方法,只需要继承 JpaRepository接口
public interface UserRepository extends JpaRepository<User, Long> {
}
自定义简单查询
自定义的简单查询就是根据方法名来自动生成 SQL,主要的语法是findXXBy,readAXXBy,queryXXBy,countXXBy, getXXBy后面跟属性名称:
User findByUserName(String userName);
也使用一些加一些关键字And 、 Or
User findByUserNameOrEmail(String username, String email);
修改、删除、统计也是类似语法
Long deleteById(Long id);
Long countByUserName(String userName)
基本上 SQL 体系中的关键词都可以使用,例如: LIKE 、IgnoreCase、 OrderBy。
List<User> findByEmailLike(String email);
User findByUserNameIgnoreCase(String userName);
List<User> findByUserNameOrderByEmailDesc(String email);
具体的关键字,使用方法和生产成SQL如下表所示
| Keyword | Sample | JPQL snippet |
|---|---|---|
| And | findByLastnameAndFirstname | … where x.lastname = ? and x.firstname = ? |
| Or | findByLastnameOrFirstname | … where x.lastname = ? or x.firstname = ? |
| Is,Equals | findByFirstnameIs,findByFirstnameEquals | … where x.firstname = ? |
| Between | findByStartDateBetween | … where x.startDate between ? and ? |
| LessThan | findByAgeLessThan | … where x.age < ? |
| LessThanEqual | findByAgeLessThanEqual | … where x.age ⇐ ? |
| GreaterThan | findByAgeGreaterThan | … where x.age > ? |
| GreaterThanEqual | findByAgeGreaterThanEqual | … where x.age >= ? |
| After | findByStartDateAfter | … where x.startDate > ? |
| Before | findByStartDateBefore | … where x.startDate < ? |
| IsNull | findByAgeIsNull | … where x.age is null |
| IsNotNull,NotNull | findByAge(Is)NotNull | … where x.age not null |
| Like | findByFirstnameLike | … where x.firstname like ? |
| NotLike | findByFirstnameNotLike | … where x.firstname not like ? |
| StartingWith | findByFirstnameStartingWith | … where x.firstname like ? (parameter bound with appended %) |
| EndingWith | findByFirstnameEndingWith | … where x.firstname like ? (parameter bound with prepended %) |
| Containing | findByFirstnameContaining | … where x.firstname like ? (parameter bound wrapped in %) |
| OrderBy | findByAgeOrderByLastnameDesc | … where x.age = ? order by x.lastname desc |
| Not | findByLastnameNot | … where x.lastname <> ? |
| In | findByAgeIn(Collection ages) | … where x.age in ? |
| NotIn | findByAgeNotIn(Collection age) | … where x.age not in ? |
| TRUE | findByActiveTrue() | … where x.active = true |
| FALSE | findByActiveFalse() | … where x.active = false |
| IgnoreCase | findByFirstnameIgnoreCase | … where UPPER(x.firstame) = UPPER(?) |
复杂查询
在实际的开发中我们需要用到分页、删选、连表等查询的时候就需要特殊的方法或者自定义 SQL
分页查询
分页查询在实际使用中非常普遍了,Spring Boot Jpa 已经帮我们实现了分页的功能,在查询的方法中,需要传入参数Pageable ,当查询中有多个参数的时候Pageable建议做为最后一个参数传入.
Page<User> findALL(Pageable pageable);
Page<User> findByUserName(String userName,Pageable pageable);
Pageable 是Spring 封装的分页实现类,使用的时候需要传入页数、每页条数和排序规则
@Test
public void testPageQuery() throws Exception {
int page=1,size=10;
Sort sort = new Sort(Direction.DESC, "id");
Pageable pageable = new PageRequest(page, size, sort);
userRepository.findALL(pageable);
userRepository.findByUserName("testName", pageable);
}
限制查询
有时候我们只需要查询前N个元素,或者只取前一个实体。
User findFirstByOrderByLastnameAsc();
User findTopByOrderByAgeDesc();
Page<User> queryFirst10ByLastname(String lastname, Pageable pageable);
List<User> findFirst10ByLastname(String lastname, Sort sort);
List<User> findTop10ByLastname(String lastname, Pageable pageable);