万方 protobuf 反序列化
protobuf 是一种轻便高效的结构化数据存储格式,可以用于结构化数据串行化,或者说序列化。
在网络传输方面,相比传统的json,有着更快、更小,且加密性好的特点。
在实际应用中,万方数据库官网发送的请求,就用到了这。
一般网站,比如cnki,我们检索内容,只需要拼接一个http请求,便能获取到数据。
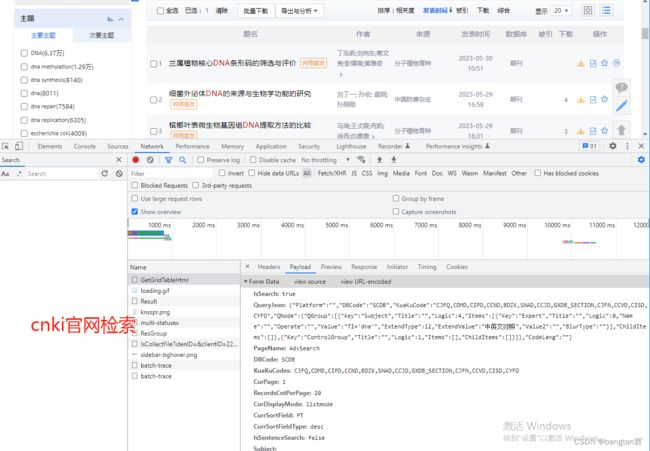
但是,万方数据库,却是这样的,看不到请求body都是一些乱码一样的数据,连返回的数据也是。
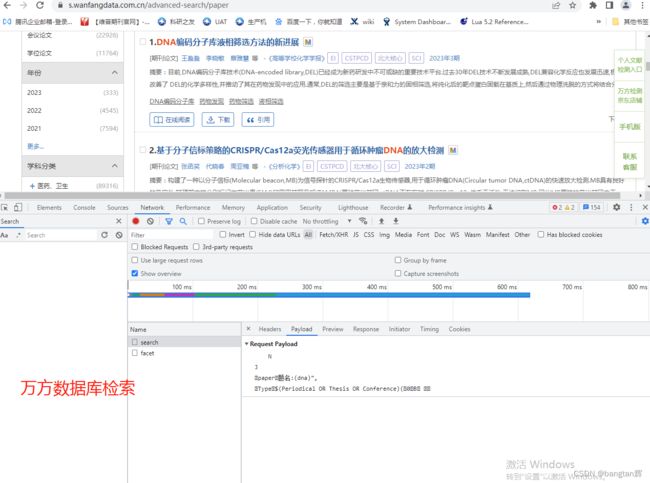
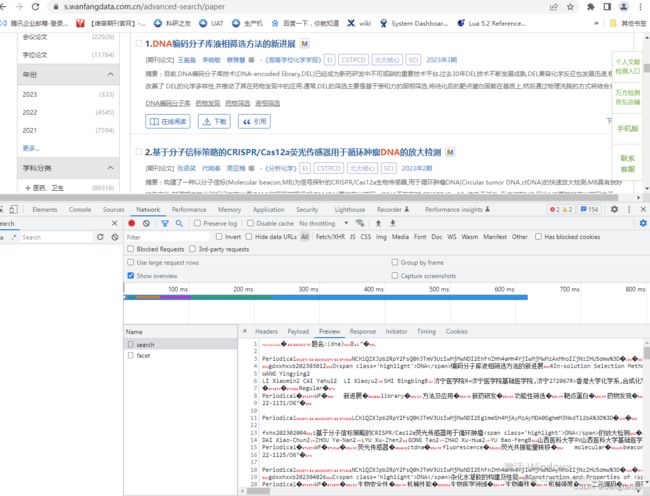
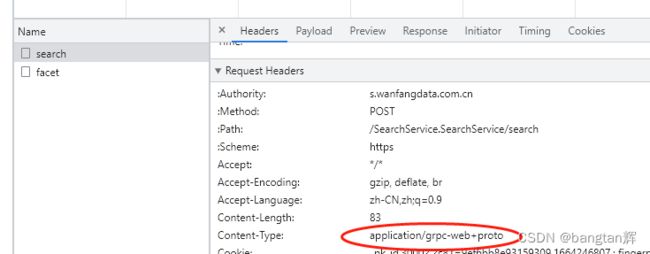
这正是由于其使用了protobuf序列化,我们通过它发送请求头中也可以看到有 “application/grpc-web+proto” 这样的字样。
其大致流程:实例化一个proto格式对象(长得类似c的结构体),将检索式塞到该对象属性中,对其进行序列化为二进制,发送请求,对接收到的数据进行反序列化。
因此我们重点就在于拿到这个proto对象的结构。
有关万方protobuf发送请求的大部分内容,可以参考大佬的文章: https://blog.csdn.net/qq_35491275/article/details/111721639
这里就只对拿到数据,将其反序列化的大致步骤,进行讲解。
本人是通过python发送请求,根据上面参考文章说的,要将数据反序列化,便需要获取到proto格式,比如有哪些变量和变量类型。
而这都需要通过在浏览器F12,打断点,一步步调试js函数才能获得。本人由于对js不了解,也不太会调试js,所以也是变相换个方法去实现。
F12------》Source------》XHR/fetch Breakpoints,将接口请求地址复制进去,这样调试的时候就会自动在相关位置断点了。
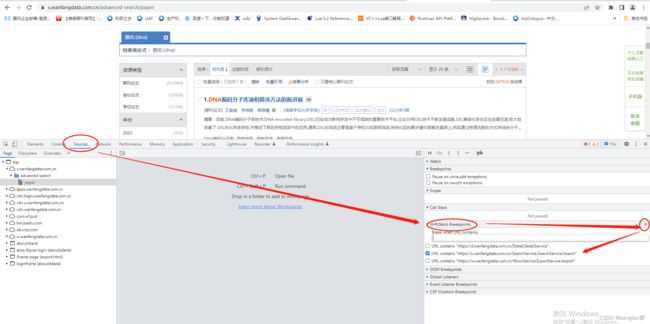
在Call Stack调用栈中,看到了SearchService字样,点击进去。
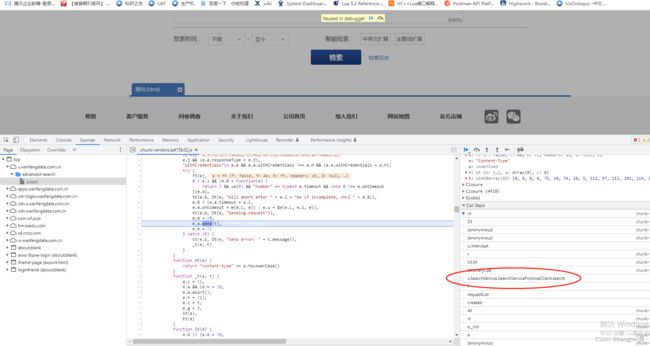
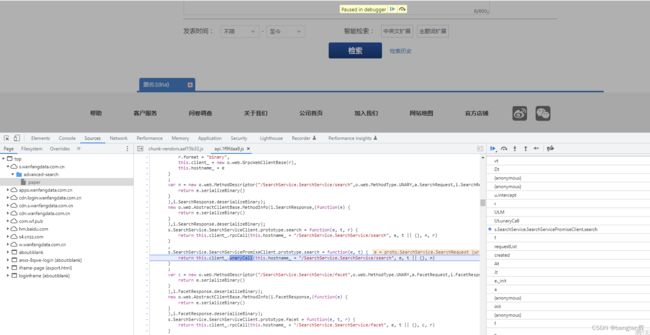
后面通过打断点,一步步调试,便能在一些方法名中找到需要的变量和类型。
本人这里就不做调试,我说说自己当时的思路。
因为整个检索流程,就主要经过了两份js,所以我直接ctrl+F,搜索SearchService字样,发现都在api.1f9fdaa9.js这一份当中。
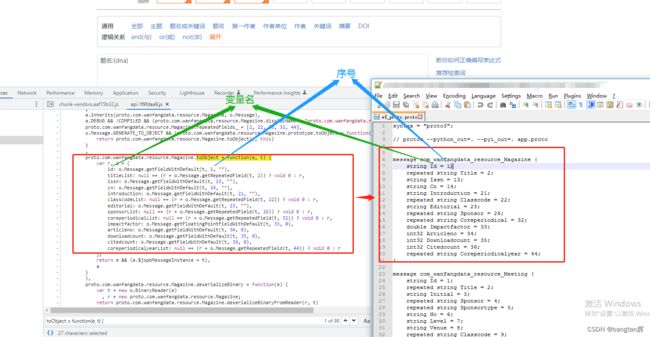
然后我再ctrl+F,搜索 “toObject = function(e, t) {” 字样,一般每个message结构对应的变量名和序号就在这个函数中,变量类型则一般在 “serializeBinaryToWriter = function(e, t) {” 函数中,大概有90多个匹配的。这一步不清楚可以看上面参考博客,便知道为什么这样找这些message结构。将他们列出来,写入一份.proto文件中。
这里变量名好像可以自己命名,主要是序号需要保持一致,但为了解析数据方便,这里变量名也尽量保持了和js中的一致,最终得到右边的proto文件。
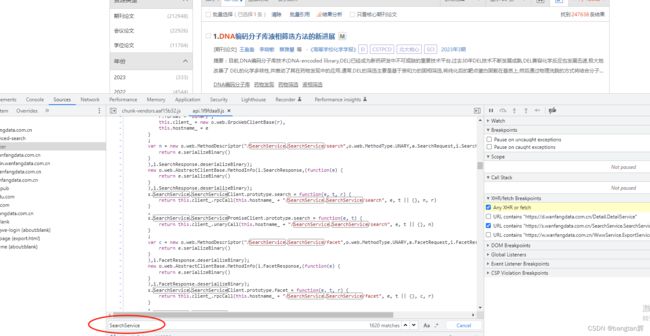

然后通过protoc.exe编译器,输入命令 protoc proto文件名 --python_out=./ 得到相关py文件。

新建一个python工程,将刚刚生成的py文件丢入工程中。便可成功反序列化出数据。
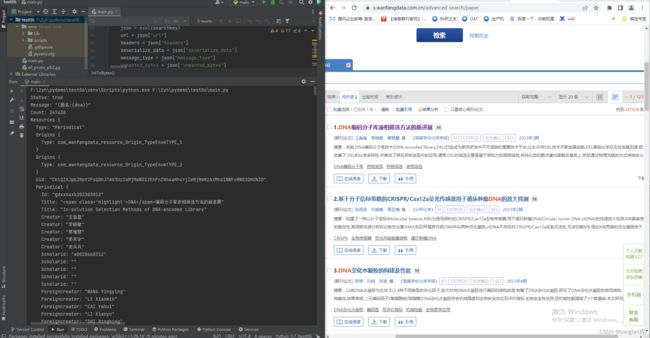
这里请求时使用了blackboxprotobuf模块,可以减少去获取请求的proto结构这一步骤。具体一些点的可以参考他人博客。
参考代码:main.py
# This is a sample Python script.
# Press Shift+F10 to execute it or replace it with your code.
# Press Double Shift to search everywhere for classes, files, tool windows, actions, and settings.
import blackboxprotobuf
import urllib
from urllib import parse
import requests
import tkinter
import asyncio
import os
import wf_proto_pb2 as wf_proto_pb2
def intToBytes(value, length):
result = []
for i in range(0, length):
result.append(value >> (i * 8) & 0xff)
result.reverse()
return result
def prowfdata(response):
# 转码
response = str(response.encode('latin1').decode('unicode-escape').encode('latin1').decode('utf-8'))
return response
def searchw(searchkey):
searchkey = urllib.parse.unquote(searchkey)
json = eval(searchkey)
url = json["url"]
headers = json["headers"]
deserialize_data = json["deserialize_data"]
message_type = json["message_type"]
unwanted_bytes = json["unwanted_bytes"]
proxies = {'http': 'http://127.0.0.1:8888', 'https': 'http://127.0.0.1:8888'}
form_data = bytes(blackboxprotobuf.encode_message(deserialize_data, message_type))
bytes_head = bytes(intToBytes(len(form_data), 5))
requests.packages.urllib3.disable_warnings()
try:
response = requests.post(url=url, headers=headers,data=bytes_head + form_data, timeout=10, verify=False)
except Exception as e:
response = requests.post(url=url, headers=headers,data=bytes_head + form_data, timeout=10, verify=False, proxies=proxies)
search_response2 = wf_proto_pb2.SearchService_SearchResponse()
search_response2.ParseFromString(response.content[5:])
return prowfdata(str(search_response2))
if __name__ == '__main__':
searchkey = '{"url":"https://s.wanfangdata.com.cn/SearchService.SearchService/search","headers":{"accept":"*/*","Referer":"https://s.wanfangdata.com.cn","User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36","Content-Type":"application/grpc-web+proto",},"deserialize_data":{"1":{"1":"paper","2":"(题名:(dna))","4":{"1":"Type","2":"(Periodical OR Thesis OR Conference)"},"5":1,"6":10,"8":"\\u0000"},"2":3},"message_type":{"1":{"type":"message","message_typedef":{"1":{"type":"bytes", "name":""}, "2":{"type":"bytes", "name":""},"4":{"type":"message","message_typedef":{"1":{"type":"bytes", "name":""},"2":{"type":"bytes", "name":""}},"name":""}, "5":{"type":"int", "name":""},"6":{"type":"int", "name":""}, "8":{"type":"bytes", "name":""}},"name":""}, "2":{"type":"int", "name":""}},"unwanted_bytes":"0"}'
print(searchw(searchkey))