什么是序列化? 如何实现(反)序列化 序列化的应用
- 1. 什么是序列化与反序列化,什么情况需要序列化
-
- 1.1 序列化
-
- 序列化是什么
- 序列化的目的
- 什么情况需要序列化
- 1.2 反序列化
-
- 反序列化是什么
- 反序列化的目的
- 2. Java中的序列化与反序列化
-
- 2.1 如何实现序列化
-
- Java序列化的规定
- 序列化的API
- 实现(反)序列化的示例
- 对象在硬盘上的存储方式
- 2.2 利用序列化,实现深拷贝
-
- 什么时候不要序列化
- Java中如何防止序列化
1. 什么是序列化与反序列化,什么情况需要序列化
1.1 序列化
序列化是什么
从百度百科中可以得知,序列化 (Serialization)是将对象的状态信息转换为可以存储或传输的形式的过程。
所以说,序列化是一种技术,Java只是以某种形式实现了序列化
序列化的目的
- 序列化最终的目的是为了对象可以跨平台存储,和进行网络传输 (也可以在分布式应用系统中传递数据)
- 也可以是将对象以二进制字节序列的方式存储在硬盘上。
当两个进程在进行远程通信时,彼此可以发送各种类型的数据。无论是何种类型的数据,都会以二进制序列的形式在网络上传送;
发送方需要把这个类型数据(对象)转换为二进制字节序列,才能在网络上传送;接收方则需要把字节序列再恢复为对象。
而我们进行跨平台存储和网络传输的方式就是IO,而我们的IO支持的数据格式就是字节数组。
什么情况需要序列化
经过上面的分析,已经很明确的知道凡是需要进行“跨平台存储”和”网络传输”的数据,都需要进行序列化。
本质上存储和网络传输 都需要经过 把一个对象状态保存成一种跨平台识别的字节格式,然后其他的平台才可以通过字节信息解析还原对象信息。
1.2 反序列化
反序列化是什么
经过上面的知识点,我们已经知道,序列化是将对象的状态信息转换为可以存储或传输的形式的过程;把对象转换为字节序列的过程称为对象的序列化。
那么把字节序列恢复为对象的过程称为对象的反序列化。
反序列化的目的
- 将字符序列方式存储的数据转换成能够识别的对象信息
2. Java中的序列化与反序列化
在Java中,一切皆对象,当我们需要实现对象的序列化时,也就需要将Java对象转换成一种对应的字节形式存储;
在Java的OutputStream类下面的子类ObjectOutputStream类就有对应的WriteObject(Object object) 方法来实现序列化,其中的参数object就要求实现了java的序列化的接口。
2.1 如何实现序列化
Java序列化的规定
Java只能将支持 java.io.Serializable 接口的对象写入流中;每个 serializable 对象的类都被编码,编码内容包括类名和类签名、对象的字段值和数组值,以及从初始对象中引用的其他所有对象的闭包
如果一个对象没有实现Serializable序列化接口,而就去使用了ObejctOutputStream去序列化对象,运行时则会报错
还有一个注意点:如果类的属性包含其他的类,那么那些类也需要实现序列化接口,否则也会报错。
序列化的API
java.io.ObjectOutputStream代表对象输出流,它的writeObject(Object obj)方法可对参数指定的obj对象进行序列化,把得到的字节序列写到一个目标输出流中。
java.io.ObjectInputStream代表对象输入流,它的readObject()方法从一个源输入流中读取字节序列,再把它们反序列化为一个对象,并将其返回。
实现(反)序列化的示例
在Java中,我们可以使用ObjectOutputStream(对象输出流)和FileOutputStream(文件输入流)搭配使用,将对象转换成字节序列后以文件的形式存储在硬盘上;这个过程也被称为Java对象的持久化;

上述序列化的规定中已有提到,如果一个类需要序列化,那么一定要实现序列化接口(Serializable),如果不实现序列化接口,那么运行时就会报错,下面是示例
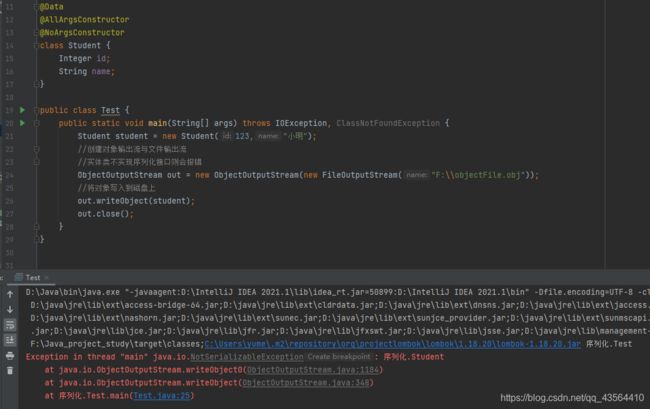
对象在硬盘上的存储方式
通过上述例子,我们可以看出,Student的一个实例化对象,被序列化后以文件的形式存储在了硬盘上
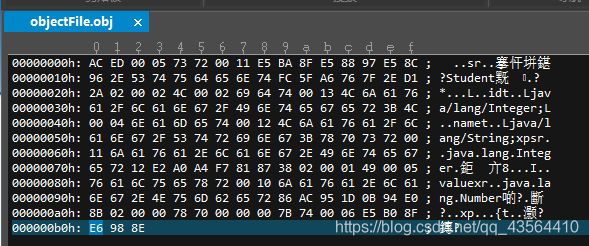
当我们以文本打开这个objectFile.obj文件,会发现里面都是乱码
![]()
这是因为对象会被转换为二进制字节序列存储在硬盘上,这个文件是以二进制的形式编写的,当用文本编辑器将它打开时,这些二进制代码与某个字符集映射之后,显示出来的东西就成了乱码。
即使输出的是一个String的对象,也是以该String对象的二进制编码的形式输出,而不是输出String对象的内容。
那我们想以二进制的形式打开这个文件,可以使用UltraEdit工具,不过该工具会自动将2进制转换为16进制进行展示
2.2 利用序列化,实现深拷贝
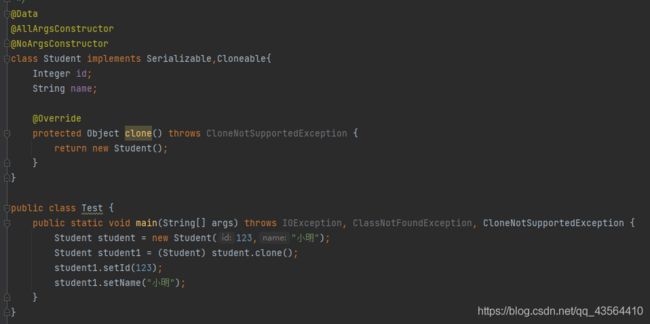
在Java中,clone()默认实现是浅拷贝,若想实现深拷贝,则需实现Cloneable接口并重写clone()方法
重写clone()方法,我们一般有两种方式去实现深拷贝。
- new对象后返回,通过get与set构造器给新创建的类属性赋值
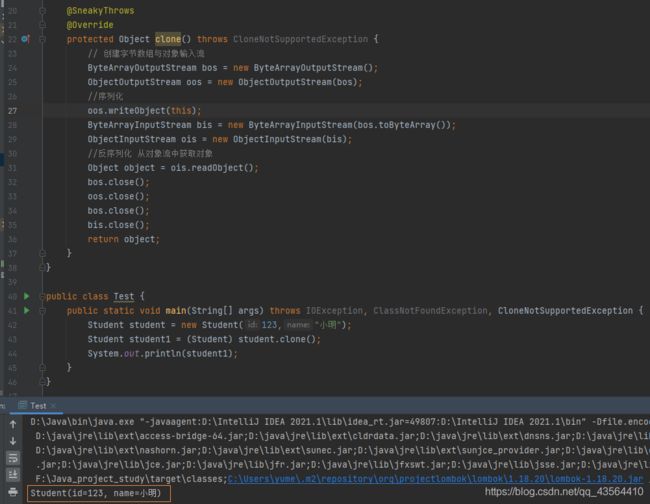
- 通过序列化,直接从硬盘上读取文件转换成新的对象返回
方式1
方式2 序列化
我们可以通过字节数组(ByteArray)输入输出流作为中间介质,来对对象进行读入和写出;
这里的字节数组,本质也就是对象序列化后在硬盘上的存储方式;
什么时候不要序列化
在Java进行应用开发的时候,用户的个人信息,包括密码、电话号码、具体住址这些隐私信息的时候,就需要防止对象被序列化,如果被序列化用于网络传输,则很有可能会造成安全问题。
Java中如何防止序列化
在Java中,声明为static和transient类型的成员数据不能被序列化。因为static代表类的状态,transient代表对象的临时数据。
所以在字段的前面,加上transient关键字,就可以防止该字段被用于序列化;
