
mini-batch
这是Spring批处理教程,它是Spring框架的一部分。 Spring Batch提供了可重用的功能,这些功能对于处理大量记录至关重要,包括日志记录/跟踪,事务管理,作业处理统计信息,作业重启,跳过和资源管理。 它还提供了更高级的技术服务和功能,这些功能和功能将通过优化和分区技术来实现极高容量和高性能的批处理作业。
在这里,您可以找到有关其主要组成部分和概念的清晰说明,以及几个工作示例。 本教程通常与Spring框架无关; 希望您熟悉诸如Spring框架的主要Struts之类的反转控制和依赖注入之类的机制。 还假定您知道如何为基本应用程序配置Spring框架上下文,并且习惯于使用基于注解和基于Spring项目的配置文件。
如果不是这种情况,那么我真的建议您在开始学习什么是Spring批处理及其工作原理之前,先转到Spring框架官方页面并学习基本教程。 这是一个很好的例子: http : //docs.spring.io/docs/Spring-MVC-step-by-step/ 。
在本教程的最后,您可以找到列出了所有示例和一些其他内容的压缩文件。
下面列出了用于编写本教程的软件:
- Java更新8版本3.1
- Apache Maven 3.2.5
- Eclipse Luna 4.4.1
- Spring Batch 3.0.3及其所有依赖项(我真的建议使用Maven或Gradle来解决所有必需的依赖项并避免麻烦)
- Spring Boot 1.2.2及其所有依赖项(我真的建议使用Maven或Gradle来解决所有必需的依赖项并避免麻烦)
- MySQL Community Server版本5.6.22
- MongoDB 2.6.8
- HSQLDB版本1.8.0.10
尽管本教程用于解决依赖关系,编译和执行所提供的示例,但本教程不会解释如何使用Maven。 在以下文章http://examples.javacodegeeks.com/enterprise-java/maven/log4j-maven-example/中可以找到更多信息。
示例中还大量使用了Spring Boot模块,有关它的更多信息,请参考官方的Spring Boot文档: http : //projects.spring.io/spring-boot/ 。
目录
-
1.简介 2.概念 3.用例 4控制流量 5.自定义作家,读者和处理器 6.平面文件示例 7. MySQL示例 8.在内存示例 9.单元测试 10.错误处理 11.并行处理 12.重复工作 13. JSR 352 14.总结 15.资源 16.下载
1.简介
Spring Batch是一个用于批处理的开源框架。 它作为Spring框架内的模块构建,并依赖于此框架(以及其他框架)。 在继续进行Spring Batch之前,我们将在这里放置批处理的定义:
“批处理是在计算机上执行一系列程序(“作业”),而无需人工干预” (摘自Wikipedia)。
因此,就我们而言,批处理应用程序执行一系列作业(迭代或并行),在这些作业中,无需任何交互即可读取,处理和写入输入数据。 我们将看到Spring Batch如何帮助我们实现这一目的。
Spring Batch提供了用于处理大量数据的机制,例如事务管理,作业处理,资源管理,日志记录,跟踪,数据转换,接口等。这些功能是现成可用的,并且可以由包含Spring Batch的应用程序重用框架。 通过使用这些多样化的技术,该框架在处理记录时会兼顾性能和可伸缩性。
通常,批处理应用程序可以分为三个主要部分:
- 读取数据(从数据库,文件系统等)
- 处理数据(过滤,分组,计算,验证...)
- 写入数据(到数据库,报告,分发…)
Spring Batch包含功能和抽象(将在本文中进行解释),这些功能和抽象用于自动化这些基本步骤,并允许应用程序程序员对其进行配置,重复,重试,停止,将它们作为单个元素执行或分组(事务管理)等
它还包含用于主要数据格式,行业标准和提供程序(例如XML,CSV,SQL,Mongo DB等)的类和接口。
在本教程的下一章中,我们将解释并提供所有这些步骤的示例以及Spring Batch提供的不同可能性。
2.概念
以下是Spring Batch框架中最重要的概念:
职位
作业是代表批处理过程的抽象,即批处理应用程序中必须执行的一系列动作或命令。
Spring批处理包含以下表示作业的接口: http : //docs.spring.io/spring-batch/apidocs/org/springframework/batch/core/Job.html 。 简单作业包含步骤列表,这些步骤顺序或并行执行。
为了配置Job,足以初始化步骤列表,这是虚拟Job的基于xml的配置示例:
工作启动器
这个介面http://docs.spring.io/spring-batch/apidocs/org/springframework/batch/core/launch/JobLauncher.html代表工作启动器。 其run()方法的实现负责为给定的作业和作业参数启动作业执行。
工作实例
这是代表给定Job的单次运行的抽象。 它是独特且可识别的。 表示此抽象的类为http://docs.spring.io/spring-batch/apidocs/org/springframework/batch/core/JobInstance.html 。
如果作业实例未成功完成并且可以重新启动作业,则可以重新启动作业实例。 否则将引发错误。
脚步
步骤主要是组成Job(和Job实例)的部分。 Step是Job的一部分,包含所有必要的信息,以执行预期在该作业阶段执行的批处理操作。 Spring Batch中的步骤由ItemReader , ItemProcessor和ItemWriter组成,根据其成员的复杂性,它们可能非常简单或极其复杂。
步骤还包含其可能使用的处理策略,提交间隔,事务处理机制或作业存储库的配置选项。 Spring Batch通常使用块处理,即一次读取所有数据,然后在一个称为提交间隔的预先配置的时间间隔内处理和写入此数据的“块”。
这是一个非常基本的基于XML的步骤配置示例,间隔为10:
下面的代码段是基于注释的版本,定义了涉及的读取器,写入器和处理器,块处理策略和10的提交间隔(这是本教程大多数示例中使用的提交间隔):
@Bean
public Step step1(StepBuilderFactory stepBuilderFactory,
ItemReader reader, ItemWriter writer,
ItemProcessor processor) {
/* it handles bunches of 10 units */
return stepBuilderFactory.get("step1")
. chunk(10).reader(reader)
.processor(processor).writer(writer).build();
}职位库
作业存储库是负责存储和更新与作业实例执行和作业上下文有关的元数据信息的抽象。 为了配置作业存储库必须实现的基本接口是http://docs.spring.io/spring-batch/apidocs/org/springframework/batch/core/repository/JobRepository.html 。
Spring将有关其执行,所获得的结果,其实例,用于执行的Jobs的参数以及运行处理的上下文的信息存储为元数据。 表名非常直观,并且类似于它们的域类名称,在此链接中有一幅图像,其中包含这些表的非常好的摘要: http : //docs.spring.io/spring-batch/reference/html/images/ meta-data-erd.png 。
有关Spring Batch元数据模式的更多信息,请访问http://docs.spring.io/spring-batch/reference/html/metaDataSchema.html 。
物品阅读器
读者是负责数据检索的抽象。 它们为批处理应用程序提供所需的输入数据。 我们将在本教程中看到如何创建自定义阅读器,并看到如何使用一些最重要的Spring Batch预定义阅读器。 这是Spring Batch提供的一些阅读器的列表:
- AmqpItemReader
- AggregateItemReader
- FlatFileItemReader
- HibernateCursorItemReader
- HibernatePagingItemReader
- IbatisPagingItemReader
- ItemReaderAdapter
- JdbcCursorItemReader
- JdbcPagingItemReader
- JmsItemReader
- JpaPagingItemReader
- ListItemReader
- MongoItemReader
- Neo4jItemReader
- RepositoryItemReader
- StoredProcedureItemReader
- StaxEventItemReader
我们可以看到Spring Batch已经为许多格式标准和数据库行业提供者提供了读者。 建议在应用程序中使用Spring Batch提供的抽象,而不是创建自己的抽象。
项目作家
编写者是负责将数据写入所需的输出数据库或系统的抽象。 我们为读者解释的内容同样适用于作家:Spring Batch已经提供了用于处理许多最常用数据库的类和接口,应该使用它们。 这是其中一些提供的作者的列表:
- AbstractItemStreamItemWriter
- AmqpItemWriter
- CompositeItemWriter
- FlatFileItemWriter
- GemfireItemWriter
- HibernateItemWriter
- IbatisBatchItemWriter
- ItemWriterAdapter
- JdbcBatchItemWriter
- JmsItemWriter
- JpaItemWriter
- MimeMessageItemWriter
- MongoItemWriter
- Neo4jItemWriter
- StaxEventItemWriter
- RepositoryItemWriter
在本文中,我们将展示如何创建自定义编写器以及如何使用列出的编写器。
项目处理器
处理器负责修改数据记录,将其从输入格式转换为所需的输出格式。 用于项目处理器配置的主要界面是http://docs.spring.io/spring-batch/trunk/apidocs/org/springframework/batch/item/ItemProcessor.html 。
在本文中,我们将看到如何创建自定义项目处理器。
下图(来自Spring批处理文档)很好地总结了所有这些概念以及基本的Spring Batch架构是如何设计的:

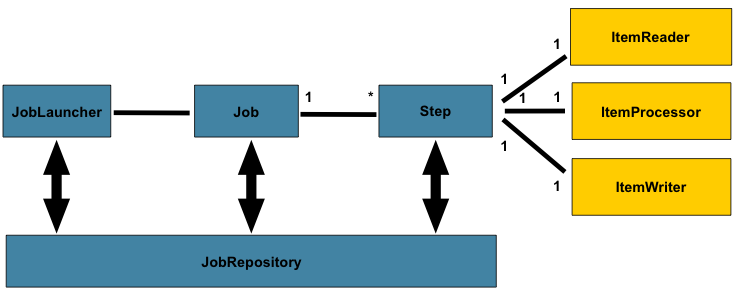
Spring Batch参考模型
3.用例
尽管很难对可以在现实世界中应用批处理的用例进行分类,但我将在本章中尝试列出最重要的用例:
- 转换应用程序:这些应用程序将输入记录转换为所需的结构或格式。 这些应用程序可用于批处理的所有阶段(读取,处理和写入)。
- 过滤或验证应用程序:这些程序旨在过滤有效记录以进行进一步处理。 通常,验证发生在批处理的第一阶段。
- 数据库提取器:这些应用程序从数据库或输入文件中读取数据,然后将所需的过滤数据写入输出文件或其他数据库。 也有一些应用程序在输入记录来自的同一数据库中更新大量数据。 作为一个真实的例子,我们可以想到一个系统,该系统分析具有不同最终用户行为的日志文件,并使用该数据生成包含有关最活跃用户,最活跃时间段等的统计信息的报告。
- 报告:这些应用程序从数据库或输入文件中读取大量数据,处理该数据并根据该数据生成格式化的文档,这些文档适合通过其他系统进行打印或发送。 会计和法律银行系统可以属于此类别:在工作日结束时,这些系统从数据库中读取信息,提取所需的数据,并将此数据写入可发送给不同机构的法律文档中。
Spring Batch提供了支持所有这些场景的机制,借助上一章中列出的元素和组件,程序员可以实现批处理应用程序以进行数据转换,过滤记录,验证,从数据库或输入文件中提取信息以及进行报告。
4.控制流量
在开始讨论特定的作业和步骤之前,我将展示Spring Batch配置类的外观。 下一个代码片段包含一个配置类,其中包含使用Spring Batch进行批处理所需的所有组件。 它包含读者,作家,处理器,工作流程,步骤以及所有其他需要的bean。
在本教程中,我们将展示如何修改此配置类,以便将不同的抽象用于不同的目的。 波纹管类粘贴后没有注释和特定的代码,有关工作类示例的信息,请转到本教程的下载部分,您可以在其中下载所有源代码:
@Configuration
@EnableBatchProcessing
public class SpringBatchTutorialConfiguration {
@Bean
public ItemReader reader() {
return new CustomItemReader();
}
@Bean
public ItemProcessor processor() {
return new CustomItemProcessor();
}
@Bean
public ItemWriter writer(DataSource dataSource) {
return new CustomItemItemWriter(dataSource);
}
@Bean
public Job job1(JobBuilderFactory jobs, Step step1) {
return jobs.get("job1").incrementer(new RunIdIncrementer())
.flow(step1).end().build();
}
@Bean
public Step step1(StepBuilderFactory stepBuilderFactory,
ItemReader reader, ItemWriter writer,
ItemProcessor processor) {
/* it handles bunches of 10 units */
return stepBuilderFactory.get("step1")
. chunk(10).reader(reader)
.processor(processor).writer(writer).build();
}
@Bean
public JdbcTemplate jdbcTemplate(DataSource dataSource) {
return new JdbcTemplate(dataSource);
}
@Bean
public DataSource mysqlDataSource() throws SQLException {
final DriverManagerDataSource dataSource = new DriverManagerDataSource();
dataSource.setDriverClassName("com.mysql.jdbc.Driver");
dataSource.setUrl("jdbc:mysql://localhost/spring_batch_annotations");
dataSource.setUsername("root");
dataSource.setPassword("root");
return dataSource;
}
...为了启动我们的spring上下文并执行所示的配置批处理,然后再使用Spring Boot。 这是一个程序示例,它负责启动我们的应用程序并使用正确的配置初始化Spring上下文。 该程序与本教程中显示的所有示例一起使用:
@SpringBootApplication
public class SpringBatchTutorialMain implements CommandLineRunner {
public static void main(String[] args) {
SpringApplication.run(SpringBatchTutorialMain.class, args);
}
@Override
public void run(String... strings) throws Exception {
System.out.println("running...");
}
}我正在使用Maven解决所有依赖关系,并使用Spring Boot启动应用程序。 这是使用的pom.xml :
4.0.0
com.danibuiza.javacodegeeks
Spring-Batch-Tutorial-Annotations
0.1.0
org.springframework.boot
spring-boot-starter-parent
1.2.1.RELEASE
org.springframework.boot
spring-boot-starter-batch
org.hsqldb
hsqldb
mysql
mysql-connector-java
org.springframework.boot
spring-boot-maven-plugin
使用的目标是:
mvn spring-boot:run现在,我们将逐步浏览上面显示的配置文件。 首先,我们将解释Jobs和Steps的执行方式以及它们遵循的规则。
在上面粘贴的示例应用程序中,我们可以看到如何配置Job和第一步。 在这里,我们提取相关的代码:
@Bean
public Job job1(JobBuilderFactory jobs, Step step1) {
return jobs.get("job1").incrementer(new RunIdIncrementer())
.flow(step1).end().build();
}
@Bean
public Step step1(StepBuilderFactory stepBuilderFactory,
ItemReader reader, ItemWriter writer,
ItemProcessor processor) {
/* it handles bunches of 10 units */
return stepBuilderFactory.get("step1")
. chunk(10).reader(reader)
.processor(processor).writer(writer).build();
}我们可以观察到仅用一个步骤如何配置名称为“ job1”的Job。 在这种情况下,称为“ step1”的步骤。 JobBuilderFactory类创建作业构建器并初始化作业存储库。 该方法flow()的类的JobBuilder创建该类的一个实例JobFlowBuilder使用所示步骤1方法。 这样,将初始化整个上下文并执行作业“ job1”。
步骤(使用处理器)以10个单位的块为单位CustomPojo读取器提供的CustomPojo记录,并使用过去的写入器进行写入。 所有依赖项都在运行时注入,Spring会进行处理,因为使用注释org.springframework.context.annotation.Configuration发生所有此类的类标记为配置类。
5.自定义作家,读者和处理器
正如我们在本教程中已经提到的那样,Spring Batch应用程序基本上包括三个步骤:读取数据,处理数据和写入数据。 我们还解释了,为了支持这3种操作,Spring Batch以接口的形式提供了3种抽象:
- ItemReader
- ItemWriter
- ItemProcessor
程序员应实现这些接口,以便在其批处理应用程序作业和步骤中读取,处理和写入数据。 在本章中,我们将解释如何为这些抽象创建自定义实现。
自定义阅读器
Spring Batch提供的用于读取数据记录的抽象是ItemReader接口。 它只有一个方法( read() ),应该执行几次; 它不需要是线程安全的,这一事实对于使用这些方法的应用程序知道是非常重要的。
接口ItemReader read()方法必须实现。 此方法不需要输入参数,应该从所需的队列中读取一条数据记录,然后将其返回。 该方法不应进行任何转换或数据处理。 如果返回null,则无需读取或分析其他数据。
public class CustomItemReader implements ItemReader {
private List pojos;
private Iterator iterator;
@Override
public CustomPojo read() throws Exception, UnexpectedInputException,
ParseException, NonTransientResourceException {
if (getIterator().hasNext()) {
return getIterator().next();
}
return null;
}
. . .上面的自定义阅读器读取pojos内部列表中的下一个元素,只有在创建自定义阅读器时初始化或注入了迭代器的情况下,才可能这样做,如果每次调用read()方法时都实例化迭代器,则作业使用该阅读器将永远不会结束并引起问题。
定制处理器
Spring Batch提供的用于数据处理的接口需要一个输入项并产生一个输出项。 两者的类型可以不同,但不必相同。 产生null意味着在串联的情况下不再需要该项目来进行进一步处理。
为了实现此接口,仅需要实现process()方法。 这是一个虚拟的示例:
public class CustomItemProcessor implements ItemProcessor {
@Override
public CustomPojo process(final CustomPojo pojo) throws Exception {
final String id = encode(pojo.getId());
final String desc = encode(pojo.getDescription());
final CustomPojo encodedPojo = new CustomPojo(id, desc);
return encodedPojo;
}
private String encode(String word) {
StringBuffer str = new StringBuffer(word);
return str.reverse().toString();
}
}上面的类在现实生活中可能没有用,但是显示了如何重写ItemProcessor接口以及如何执行process方法中需要的任何操作(在这种情况下,将输入pojo成员反转)。
定制作家
为了创建自定义编写器,程序员需要实现ItemWriter接口。 此接口仅包含一个方法write() ,该方法需要一个输入项并返回void 。 write方法可以执行所需的任何操作:在数据库中写入,在csv文件中写入,发送电子邮件,创建格式化的文档等。此接口的实现负责刷新数据并使结构保持安全状态。
这是一个自定义编写器的示例,其中输入项是在标准控制台中编写的:
public class CustomItemWriter implements ItemWriter {
@Override
public void write(List pojo) throws Exception {
System.out.println("writing Pojo " + pojo);
}
}在现实生活中也并不是很有用,仅用于学习目的。
还必须提到的是,对于几乎所有现实生活中的场景,Spring Batch已经提供了可以解决大多数问题的特定抽象。 例如,Spring Batch包含用于从MySQL数据库读取数据或将数据写入HSQLDB数据库或使用JAXB将数据从XML转换为CSV的类; 还有很多其他该代码是干净的,经过全面测试的,标准的,并且已为业界所采用,因此我可以建议使用它们。
这些类也可以在我们的应用程序中重写,以实现我们的愿望,而无需重新实现整个逻辑。 通过Spring实现提供的类对于测试,调试,记录或报告目的也可能有用。 因此,在一次又一次发现轮子之前,有必要检查一下Spring Batch文档和教程,因为我们可能会找到一种更好,更干净的方法来解决我们的特定问题。
6.平面文件示例
使用上面的示例,我们将修改读取器和写入器,以便能够从csv文件读取和写入平面文件。 下面的代码片段显示了我们应该如何配置阅读器,以提供一个从平面文件(在本例中为csv)提取数据的阅读器。 为此,Spring已经提供了FlatFileItemReader类,该类需要一个数据应来自的资源属性,以及一个行映射器,以能够解析该资源中包含的数据。 该代码非常直观:
@Bean
public ItemReader reader() {
if ("flat".equals(this.mode)) {
// flat file item reader (using an csv extractor)
FlatFileItemReader reader = new FlatFileItemReader();
//setting resource and line mapper
reader.setResource(new ClassPathResource("input.csv"));
reader.setLineMapper(new DefaultLineMapper() {
{
//default line mapper with a line tokenizer and a field mapper
setLineTokenizer(new DelimitedLineTokenizer() {
{
setNames(new String[] { "id", "description" });
}});
setFieldSetMapper(new BeanWrapperFieldSetMapper() {
{
setTargetType(CustomPojo.class);
}});
}
});
return reader;
}
else {
. . .下面的代码显示了编写器中需要的修改。 在这种情况下,我们将使用需要输出文件进行写入的FlatFileItemWriter类的编写器以及提取器机制。 提取器可以如代码片段中所示进行配置:
@Bean
public ItemWriter writer(DataSource dataSource) {
...
else if ("flat".equals(this.mode)) {
// FlatFileItemWriter writer
FlatFileItemWriter writer = new FlatFileItemWriter ();
writer.setResource(new ClassPathResource("output.csv"));
BeanWrapperFieldExtractor fieldExtractor = new CustomFieldExtractor();
fieldExtractor.setNames(new String[] { "id", "description" });
DelimitedLineAggregator delLineAgg = new CustomDelimitedAggregator();
delLineAgg.setDelimiter(",");
delLineAgg.setFieldExtractor(fieldExtractor);
writer.setLineAggregator(delLineAgg);
return writer;
}
else {
. . .
}7. MySQL示例
在本章中,我们将看到如何修改我们的编写器和数据源,以便将处理后的记录写入本地MySQL DB。
如果要从MySQL数据库读取数据,则首先需要使用所需的连接参数来修改数据源bean的配置:
@Bean
public DataSource dataSource() throws SQLException {
. . .
else if ("mysql".equals(this.mode)) {
// mysql data source
final DriverManagerDataSource dataSource = new DriverManagerDataSource();
dataSource.setDriverClassName("com.mysql.jdbc.Driver");
dataSource.setUrl("jdbc:mysql://localhost/spring_batch_annotations");
dataSource.setUsername("root");
dataSource.setPassword("root");
return dataSource;
} else {
. . .这是使用SQL语句和JdbcBatchItemWriter修改书写器的方式,该JdbcBatchItemWriter使用上面显示的数据源进行初始化:
@Bean
public ItemWriter writer(DataSource dataSource) {
...
else if ("mysql".equals(this.mode)) {
JdbcBatchItemWriter writer = new JdbcBatchItemWriter();
writer.setSql("INSERT INTO pojo (id, description) VALUES (:id, :description)");
writer.setDataSource(dataSource);
writer.setItemSqlParameterSourceProvider(
new BeanPropertyItemSqlParameterSourceProvider());
return writer;
}
.. .值得一提的是,所需的Jettison库存在问题:http://stackoverflow.com/questions/28627206/spring-batch-exception-cannot-construct-java-util-mapentry 。
8.在内存数据库(HSQLDB)示例中
作为第三个示例,我们将展示如何创建读取器和写入器以使用内存数据库,这对于测试场景非常有用。 默认情况下,如果未指定其他任何内容,Spring Batch将选择HSQLDB作为数据源。
在这种情况下,要使用的数据源与MySQL数据库相同,但具有不同的参数(包含HSQLDB配置):
@Bean
public DataSource dataSource() throws SQLException {
. . .
} else {
// hsqldb datasource
final DriverManagerDataSource dataSource = new DriverManagerDataSource();
dataSource.setDriverClassName("org.hsqldb.jdbcDriver");
dataSource.setUrl("jdbc:hsqldb:mem:test");
dataSource.setUsername("sa");
dataSource.setPassword("");
return dataSource;
}
}作者与MySQL的作者几乎没有区别:
@Bean
public ItemWriter writer(DataSource dataSource) {
if ("hsqldb".equals(this.mode)) {
// hsqldb writer using JdbcBatchItemWriter (the difference is the
// datasource)
JdbcBatchItemWriter writer = new JdbcBatchItemWriter();
writer.setItemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider());
writer.setSql("INSERT INTO pojo (id, description) VALUES (:id, :description)");
writer.setDataSource(dataSource);
return writer;
} else
. . .如果我们希望Spring负责使用数据库的初始化,我们可以创建一个名为schema-all.sql的脚本(对于所有提供程序,对于Hsqldb,为schema-hsqldb.sql,对于MySQL,为schema-mysql.sql,等)在我们项目的资源项目中:
DROP TABLE IF EXISTS POJO;
CREATE TABLE POJO (
id VARCHAR(20),
description VARCHAR(20)
);本教程末尾的下载部分中也提供了此脚本。
9.单元测试
在本章中,我们将简要介绍如何使用Spring Batch测试功能来测试Batch应用程序。 本章不解释如何测试一般的Java应用程序或特别是基于Spring的应用程序。 它仅涉及如何从端到端测试Spring Batch应用程序,仅涉及Jobs或Steps测试; 这就是为什么排除单个元素(例如项目处理器,读取器或写入器)的单元测试的原因,因为这与常规单元测试没有什么不同。
Spring Batch Test Project包含一些抽象,可以简化批处理应用程序的单元测试。
在Spring中运行单元测试(在这种情况下使用Junit)时,有两个基本注释:
- @RunWith(SpringJUnit4ClassRunner.class):Junit批注执行所有标记为测试的方法。 通过将
SpringJunit4ClassRunner类作为参数传递,我们表明该类可以使用所有的弹簧测试功能。 - @ContextConfiguration(locations = {。。。}):我们将不使用“ locations”属性,因为我们不是在使用xml配置文件,而是直接使用配置类。
http://docs.spring.io/spring-batch/trunk/apidocs/org/springframework/batch/test/JobLauncherTestUtils.html类的实例可用于启动单元测试方法中的作业和单个步骤(其中很多其他功能,其方法launchJob()执行一个Job,其方法launchStep("name")执行一个launchStep("name")的步骤。在以下示例中,您可以看到如何在实际的jUnit测试中使用这些方法:
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(classes=SpringBatchTutorialConfiguration.class, loader=AnnotationConfigContextLoader.class)
public class SpringBatchUnitTest {
@Autowired
private JobLauncherTestUtils jobLauncherTestUtils;
@Autowired
JdbcTemplate jdbcTemplate;
@Test
public void testLaunchJob() throws Exception {
// test a complete job
JobExecution jobExecution = jobLauncherTestUtils.launchJob();
assertEquals(BatchStatus.COMPLETED, jobExecution.getStatus());
}
@Test
public void testLaunchStep() {
// test a individual step
JobExecution jobExecution = jobLauncherTestUtils.launchStep("step1");
assertEquals(BatchStatus.COMPLETED, jobExecution.getStatus());
}
}您可以声明或验证测试,以检查Job执行的状态以进行完整的Jobs单元测试,也可以声明编写器的结果以进行单步测试。 在所示的示例中,我们不使用任何xml配置文件,而是使用已经提到的配置类。 为了指示要加载此配置的单元测试,使用带有属性“ classes”和“ loader”的批注ContextConfiguration :
@ContextConfiguration(classes=SpringBatchTutorialConfiguration.class,
loader=AnnotationConfigContextLoader.class)可在以下教程中找到有关Spring Batch单元测试的更多信息: http : //docs.spring.io/spring-batch/trunk/reference/html/testing.html 。
10.错误处理和重试作业
Spring提供了重试Jobs的机制,但是由于版本2.2.0不再是Spring Batch框架的一部分,而是包含在Spring Retry中: http : //docs.spring.io/spring-retry/docs/api/current/ 。 一个很好的教程可以在这里找到: http : //docs.spring.io/spring-batch/trunk/reference/html/retry.html 。
重试策略,回调和恢复机制是框架的一部分。
11.并行处理
Spring Batch支持两种可能的变体(单进程和多进程)中的并行处理,我们可以将其分为以下几类。 在本章中,我们将列出这些类别并简要说明Spring Batch如何为它们提供解决方案:
- 多线程步骤(单进程):程序员可以以线程安全的方式实现其读取器和写入器,因此可以使用多线程,并且可以在不同威胁下执行步骤处理。 Spring Batch开箱即
ItemWriter提供了几个ItemWriter和ItemReader实现。 在它们的描述中通常说明它们是否是线程安全的。 如果未提供此信息或实现清楚地指出它们不是线程安全的,则程序员始终可以将调用同步到read()方法。 这样,可以并行处理多个记录。 - 并行步骤(单个过程):如果由于应用程序模块的逻辑不会折叠而可以并行执行,则这些不同的模块可以以并行的方式在不同的步骤中执行。 这与最后一点中说明的方案不同,在最后一点中,每个步骤的执行并行处理不同的记录。 在这里,不同的步骤并行进行。Spring Batch通过元素
split支持这种情况。以下是一个示例配置,可能有助于更好地理解它:. . . - 步骤的远程分块(单个过程):在这种模式下,步骤在不同的过程中分开,这些步骤使用某种中间件系统(例如JMX)相互通信。 基本上,有一个本地运行的主组件和几个称为从属的远程进程。 主组件是正常的Spring Batch Step,它的编写者知道如何使用前面提到的中间件将项目的大块作为消息发送。 从属设备是具有处理消息能力的项目编写器和项目处理器的实现。 主组件不应成为瓶颈,实现此模式的标准方法是将昂贵的零件留在处理器和写入器中,将轻巧的零件留在读取器中。
- 对步骤进行分区(单个或多个过程): Spring Batch提供了对步骤进行分区并远程执行它们的可能性。 远程实例是“步骤”。
这些是Spring Batch提供给程序员的主要选项,允许他们以某种方式并行处理批处理应用程序。 但是一般的并行性,尤其是批处理中的并行性是一个非常深入而复杂的主题,不在本文的讨论范围之内。
12.重复工作
Spring Batch提供了以编程和可配置的方式重复作业和任务的可能性。 换句话说,可以将我们的批处理应用程序配置为重复执行作业或步骤,直到满足特定条件(或直到尚未满足特定条件)为止。 有几种抽象可用于此目的:
- 重复操作:接口RepeatOperations是Spring Batch中所有重复机制的基础。 它包含要在其中传递回调的方法。 该回调在每次迭代中执行。 看起来如下:
public interface RepeatOperations { RepeatStatus iterate(RepeatCallback callback) throws RepeatException; }RepeatCallback接口包含必须在Batch中重复的功能逻辑:
public interface RepeatCallback { RepeatStatus doInIteration(RepeatContext context) throws Exception; }所述
RepeatStatus在其返回iterate()和doInIteration()分别应RepeatStatus.CONTINUABLE万一批处理应继续迭代或RepeatStatus.FINIHSED万一批处理应该被终止。Spring已经为
RepeatCallBack接口提供了一些基本的实现。 - 重复模板: RepeatTemplate类是
RepeatOperations接口的非常有用的实现,可以用作批处理应用程序的起点。 它包含错误处理和终结机制的基本功能和默认行为。 不需要此默认行为的应用程序应实施其自定义完成策略。这是如何使用具有固定块终止策略和伪迭代方法的重复模板的示例:RepeatTemplate template = new RepeatTemplate(); template.setCompletionPolicy(new FixedChunkSizeCompletionPolicy(10)); template.iterate(new RepeatCallback() { public ExitStatus doInIteration(RepeatContext context) { int x = 10; x *= 10; x /= 10; return ExitStatus.CONTINUABLE; } });在这种情况下,批处理将在10次迭代后终止,因为iterate()方法始终返回
CONTINUABLE并将终止的责任留给完成策略。 - 重复状态: Spring包含具有可能的延续状态的枚举:
RepeatStatus .CONTINUABLERepeatStatus.FINISHED指示该处理应该继续还是结束,可以是成功或不成功)。 http://docs.spring.io/spring-batch/trunk/apidocs/org/springframework/batch/repeat/RepeatStatus.html - 重复上下文:可以在“重复上下文”中存储瞬态数据,此上下文作为参数传递给“重复回调
doInIteration()方法。 为此,Spring Batch提供了抽象RepeatContext 。调用iterate()方法后,上下文不再存在。 如果嵌套了迭代,则重复上下文具有父上下文,在这种情况下,可以使用父上下文来存储可以在不同迭代之间共享的信息,例如计数器或决策变量。 - 重复策略:重复模板终止机制由CompletionPolicy确定。 此策略还负责创建
RepeatContext并在每次迭代中将其传递给回调。 迭代完成后,模板将调用完成策略并更新其状态,该状态将存储在重复上下文中。 之后,模板要求策略检查处理是否完成。Spring包含此接口的几种实现,最简单的实现之一是SimpleCompletionPolicy ; 这提供了仅执行固定数量的迭代即可执行批处理的可能性。
13. Java平台的JSR 352批处理应用程序
从Java 7开始,批处理处理已包含在Java平台中。 JSR 352( Java平台的批处理应用程序)为批处理应用程序指定了一个模型,并为调度和执行作业指定了运行时。 在撰写本教程时,Spring Batch实现(3.0)完全实现了JSR-352的规范。
域模型和使用的词汇与Spring Batch中使用的非常相似。JSR 352:Java平台的批处理应用程序:Java平台JSR 352模型中也包含Jobs , Steps , Chunks , Items , ItemReaders , ItemWriters , ItemProcessors等。 框架和配置文件之间的细微差别几乎相同。
对于程序员和整个行业来说这都是一件好事。 因为该行业从在Java平台中创建了一个标准这一事实中获利,所以使用了像Spring Batch这样的非常好的库作为基础,该库已被广泛使用并经过了良好的测试。 程序员可以从中受益,因为如果Spring Batch停产或由于某种原因无法在其应用程序中使用(兼容性,公司策略,大小限制等),他们可以选择Java标准实现进行批处理,而无需对其系统进行太多更改。
有关Spring Batch如何成为JSR 352适配器的更多信息,请访问链接http://docs.spring.io/spring-batch/reference/html/jsr-352.html 。
14.总结
就是这样了。 我希望您喜欢它,现在可以使用Spring Batch配置和实现批处理应用程序。 我将在这里总结本文中解释的最重要的观点:
- Spring Batch是基于Spring框架构建的批处理框架。
- 主要是(简化!)它由
Steps,其中Readers,Processors和Writers进行了配置和连接以执行所需的动作。 - Spring Batch包含允许程序员与开箱即用MySQL,Mongo DB等主要提供程序以及SQL,CSV或XML等格式一起使用的机制。
- Spring Batch包含错误处理,重复
Jobs和Steps以及重试Jobs和Steps。 - 它还提供了并行处理的可能性。
- 它包含用于批处理应用程序单元测试的类和接口。
In this tutorial I used no xml file (apart from some examples) for configuring the spring context, everything was done via annotations. I did it this way for clarity reasons but I do not recommend to do this in real life applications since xml configuration files may be useful in specific scenarios. As I said, this was a tutorial about Spring Batch and not about Spring in general.
15. Resources
The following links contain a lot of information and theoretical examples where you can learn all the features of the Spring Batch module:
- http://docs.spring.io/spring-batch/reference/html/index.html
- https://jcp.org/en/jsr/detail?id=352
- https://spring.io/guides/gs/batch-processing/
- https://kb.iu.edu/d/afrx
16. Download Spring Batch Tutorial source Code
You can download the full source code of this Spring Batch Tutorial here: spring_batch_tutorial .
翻译自: https://www.javacodegeeks.com/2015/03/spring-batch-tutorial.html
mini-batch