详解EM算法
目录
- 1. 概念
- 2. 举例
-
- 2.1 例子1
-
- 2.1.2 计算
- 2.2 例子 B
- 3. 推导
- 4. 应用
1. 概念
EM算法(期望最大算法)是一种迭代算法,用于含有隐变量的概率参数模型的最大似然估计或极大后验概率估计。具体思想如下:
EM算法的核心思想非常简单,分为两步:Expection-Step和Maximization-Step。E-Step主要通过观察数据和现有模型来估计参数,然后用这个估计的参数值来计算似然函数的期望值;而M-Step是寻找似然函数最大化时对应的参数。由于算法会保证在每次迭代之后似然函数都会增加,所以函数最终会收敛。
2. 举例
通过一下两个例子来直观感受下EM算法。
2.1 例子1
假设两枚硬币A和B,他们的随机抛掷的结果如下图所示:
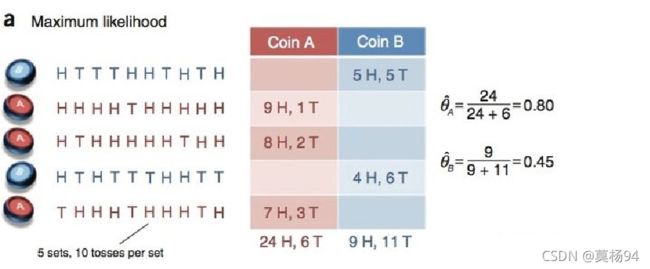 我们很容易估计出两枚硬币抛出正面的概率: θ A = 24 / 30 = 0.8 θ B = 9 / 20 = 0.45 \begin{aligned} &\theta_{A}=24 / 30=0.8 \\ &\theta_{B}=9 / 20=0.45 \end{aligned} θA=24/30=0.8θB=9/20=0.45
我们很容易估计出两枚硬币抛出正面的概率: θ A = 24 / 30 = 0.8 θ B = 9 / 20 = 0.45 \begin{aligned} &\theta_{A}=24 / 30=0.8 \\ &\theta_{B}=9 / 20=0.45 \end{aligned} θA=24/30=0.8θB=9/20=0.45
我们假如隐变量,抹去每轮投掷的硬币标记:
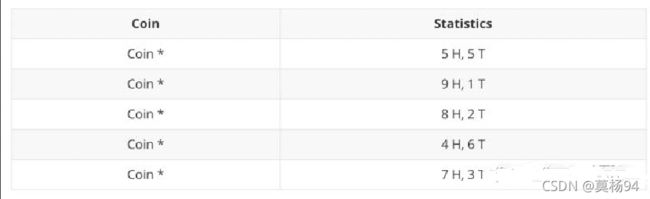
碰到这种情况,我们该如何估计 θ A \theta_{A} θA和 θ B \theta_{B} θB 的值?
我们多了一个隐变量 Z = ( z 1 , z 2 , z 3 , z 4 , z 5 ) Z=\left(z_{1}, z_{2}, z_{3}, z_{4}, z_{5}\right) Z=(z1,z2,z3,z4,z5) ,代表每一轮所使用的硬币,我们需要知道每一轮抛掷所使用的硬币这样才能估计 θ A \theta_{A} θA 和 θ B \theta_{B} θB 的值,但是估计隐变量 Z 我们又需要知道 θ A \theta_{A} θA 和 θ B \theta_{B} θB 的值,才能用极大似然估计法去估计出 Z。这就陷入了一个鸡生蛋和蛋生鸡的问题。
其解决方法就是先随机初始化 θ A \theta_{A} θA和 θ B \theta_{B} θB,然后用去估计 Z, 然后基于 Z 按照最大似然概率去估计新的 θ A \theta_{A} θA和 θ B \theta_{B} θB,循环至收敛。
2.1.2 计算
随机初始化$\theta_{A}=0.6和 θ B = 0.5 \theta_{B}=0.5 θB=0.5
对于第一轮来说,如果是硬币 A,得出的 5 正 5 反的概率为: 0. 6 5 ∗ 0. 4 5 0.6^{5} * 0.4^{5} 0.65∗0.45;如果是硬币 B,得出的 5 正 5 反的概率为: 0. 5 5 ∗ 0. 5 5 0.5^{5} * 0.5^{5} 0.55∗0.55 。我们可以算出使用是硬币 A 和硬币 B 的概率分别为:
P A = 0. 6 5 ∗ 0. 4 5 ( 0. 6 5 ∗ 0. 4 5 ) + ( 0. 5 5 ∗ 0. 5 5 ) = 0.45 P B = 0. 5 5 ∗ 0. 5 5 ( 0. 6 5 ∗ 0. 4 5 ) + ( 0. 5 5 ∗ 0. 5 5 ) = 0.55 \begin{aligned} P_{A} &=\frac{0.6^{5} * 0.4^{5}}{\left(0.6^{5} * 0.4^{5}\right)+\left(0.5^{5} * 0.5^{5}\right)}=0.45 \\ P_{B} &=\frac{0.5^{5} * 0.5^{5}}{\left(0.6^{5} * 0.4^{5}\right)+\left(0.5^{5} * 0.5^{5}\right)}=0.55 \end{aligned} PAPB=(0.65∗0.45)+(0.55∗0.55)0.65∗0.45=0.45=(0.65∗0.45)+(0.55∗0.55)0.55∗0.55=0.55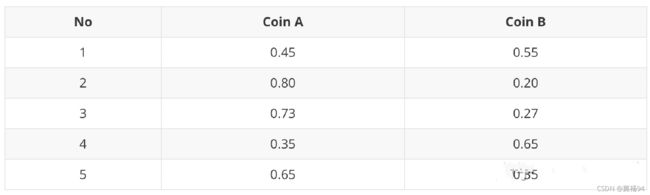
从期望的角度来看,对于第一轮抛掷,使用硬币 A 的概率是 0.45,使用硬币 B 的概率是 0.55。同理其他轮。这一步我们实际上是估计出了 Z 的概率分布,这部就是 E-Step。
结合硬币 A 的概率和上一张投掷结果,我们利用期望可以求出硬币 A 和硬币 B 的贡献。以第二轮硬币 A 为例子,计算方式为: H : 0.80 ∗ 9 = 7.2 T : 0.80 ∗ 1 = 0.8 \begin{aligned} &H: 0.80 * 9=7.2 \\ &T: 0.80 * 1=0.8 \end{aligned} H:0.80∗9=7.2T:0.80∗1=0.8于是我们可以得到:
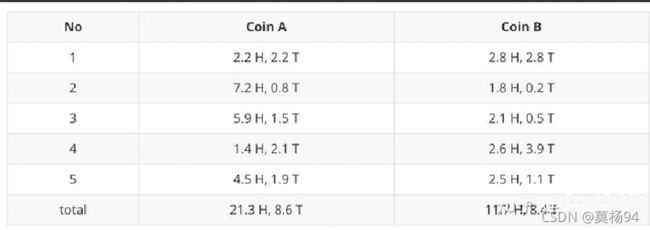
然后用极大似然估计来估计新的 θ A \theta_{A} θA和 θ B \theta_{B} θB。
这步就对应了 M-Step,重新估计出了参数值。
如此反复迭代,我们就可以算出最终的参数值。
上述讲解对应下图:

2.2 例子 B
如果说例子 A 需要计算你可能没那么直观,那就举更一个简单的例子:
现在一个班里有 50 个男生和 50 个女生,且男女生分开。我们假定男生的身高服从正态分布: N ( μ 1 , σ 1 2 ) N\left(\mu_{1}, \sigma_{1}^{2}\right) N(μ1,σ12) ,女生的身高则服从另一个正态分布: N ( μ 2 , σ 2 2 ) N\left(\mu_{2}, \sigma_{2}^{2}\right) N(μ2,σ22) 。这时候我们可以用极大似然法(MLE),分别通过这 50 个男生和 50 个女生的样本来估计这两个正态分布的参数。
但现在我们让情况复杂一点,就是这 50 个男生和 50 个女生混在一起了。我们拥有 100 个人的身高数据,却不知道这 100 个人每一个是男生还是女生。
这时候情况就有点尴尬,因为通常来说,我们只有知道了精确的男女身高的正态分布参数我们才能知道每一个人更有可能是男生还是女生。但从另一方面去考量,我们只有知道了每个人是男生还是女生才能尽可能准确地估计男女各自身高的正态分布的参数。
这个时候有人就想到我们必须从某一点开始,并用迭代的办法去解决这个问题:我们先设定男生身高和女生身高分布的几个参数(初始值),然后根据这些参数去判断每一个样本(人)是男生还是女生,之后根据标注后的样本再反过来重新估计参数。之后再多次重复这个过程,直至稳定。这个算法也就是 EM 算法。
3. 推导
给定数据集,假设样本间相互独立,我们想要拟合模型 p ( x ; θ ) p(x ; \theta) p(x;θ) 到数据的参数。根据分布我们可以得到如下似然函数: L ( θ ) = ∑ i = 1 n logp ( x i ; θ ) = ∑ i = 1 n log ∑ z p ( x i , z ; θ ) \begin{aligned} L(\theta) &=\sum_{i=1}^{n} \operatorname{logp}\left(x_{i} ; \theta\right) \\ &=\sum_{i=1}^{n} \log \sum_{z} p\left(x_{i}, z ; \theta\right) \end{aligned} L(θ)=i=1∑nlogp(xi;θ)=i=1∑nlogz∑p(xi,z;θ)
第一步是对极大似然函数取对数,第二步是对每个样本的每个可能的类别 z 求联合概率分布之和。如果这个 z 是已知的数,那么使用极大似然法会很容易。但如果 z 是隐变量,我们就需要用 EM 算法来求。
事实上,隐变量估计问题也可以通过梯度下降等优化算法,但事实由于求和项将随着隐变量的数目以指数级上升,会给梯度计算带来麻烦;而 EM 算法则可看作一种非梯度优化方法。
对于每个样本 i,我们用 Q i ( z ) Q_{i}(z) Qi(z) 表示样本 i 隐含变量 z 的某种分布,且 Q i ( z ) Q_{i}(z) Qi(z) 满足条件( ∑ z Z Q i ( z ) = 1 , Q i ( z ) ≥ 0 \sum_{z}^{Z} Q_{i}(z)=1, \quad Q_{i}(z) \geq 0 ∑zZQi(z)=1,Qi(z)≥0)。
我们将上面的式子做以下变化:
∑ i n logp ( x i ; θ ) = ∑ i n log ∑ z p ( x i , z ; θ ) = ∑ i n log ∑ z Z Q i ( z ) p ( x i , z ; θ ) Q i ( z ) ≥ ∑ i n ∑ z Z Q i ( z ) log p ( x i , z ; θ ) Q i ( z ) \begin{aligned} \sum_{i}^{n} \operatorname{logp}\left(x_{i} ; \theta\right) &=\sum_{i}^{n} \log \sum_{z} p\left(x_{i}, z ; \theta\right) \\ &=\sum_{i}^{n} \log \sum_{z}^{Z} Q_{i}(z) \frac{p\left(x_{i}, z ; \theta\right)}{Q_{i}(z)} \\ & \geq \sum_{i}^{n} \sum_{z}^{Z} Q_{i}(z) \log \frac{p\left(x_{i}, z ; \theta\right)}{Q_{i}(z)} \end{aligned} i∑nlogp(xi;θ)=i∑nlogz∑p(xi,z;θ)=i∑nlogz∑ZQi(z)Qi(z)p(xi,z;θ)≥i∑nz∑ZQi(z)logQi(z)p(xi,z;θ)
上面式子中,第一步是求和每个样本的所有可能的类别 z 的联合概率密度函数,但是这一步直接求导非常困难,所以将其分母都乘以函数 Q i ( z ) Q_{i}(z) Qi(z) ,转换到第二步。从第二步到第三步是利用 Jensen 不等式。
我们来简单证明下:
Jensen 不等式给出:如果 f f f 是凹函数,X 是随机变量,则 E [ f ( X ) ] ≤ f ( E [ X ] ) E[f(X)] \leq f(E[X]) E[f(X)]≤f(E[X]) ,当 f f f 严格是凹函数是,则 E [ f ( X ) ] < f ( E [ X ] ) E[f(X)]
我们把第一步中的 log \log log函数看成一个整体,由于 log ( x ) \log (x) log(x) 的二阶导数小于 0,所以原函数为凹函数。我们把 Q i ( z ) Q_{i}(z) Qi(z)看成一个概率 p z p_z pz ,把 p ( x i , z ; θ ) Q i ( z ) \frac{p\left(x_{i}, z ; \theta\right)}{Q_{i}(z)} Qi(z)p(xi,z;θ) 看成 z 的函数 g ( z ) g(z) g(z)。根据期望公式有:
E ( z ) = p z g ( z ) = ∑ z Z Q i ( z ) [ p ( x i , z ; θ ) Q i ( z ) ] E(z)=p_{z} g(z)=\sum_{z}^{Z} Q_{i}(z)\left[\frac{p\left(x_{i}, z ; \theta\right)}{Q_{i}(z)}\right] E(z)=pzg(z)=z∑ZQi(z)[Qi(z)p(xi,z;θ)]
根据 Jensen 不等式的性质:
f ( ∑ z Z Q i ( z ) [ p ( x i , z ; θ ) Q i ( z ) ] ) = f ( E [ z ] ) ≥ E [ f ( z ) ] = ∑ z Z Q i ( z ) f ( [ p ( x i , z ; θ ) Q i ( z ) ] ) f\left(\sum_{z}^{Z} Q_{i}(z)\left[\frac{p\left(x_{i}, z ; \theta\right)}{Q_{i}(z)}\right]\right)=f(E[z]) \geq E[f(z)]=\sum_{z}^{Z} Q_{i}(z) f\left(\left[\frac{p\left(x_{i}, z ; \theta\right)}{Q_{i}(z)}\right]\right) f(z∑ZQi(z)[Qi(z)p(xi,z;θ)])=f(E[z])≥E[f(z)]=z∑ZQi(z)f([Qi(z)p(xi,z;θ)])证明结束。
通过上面我们得到了: L ( θ ) ≥ J ( z , Q ) L(\theta) \geq J(z, Q) L(θ)≥J(z,Q) 的形式(z 为隐变量),那么我们就可以通过不断最大化 J ( z , Q ) J(z, Q) J(z,Q) 的下界来使得 L ( θ ) L(\theta) L(θ)不断提高。下图更加形象:
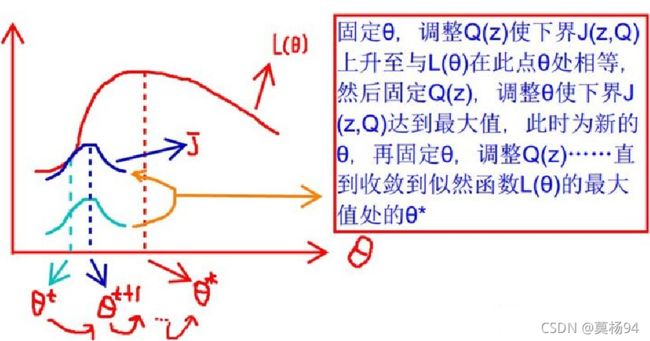
这张图的意思就是:首先我们固定 θ \theta θ,调整 Q ( z ) Q(z) Q(z) 使下界 J ( z , Q ) J(z,Q) J(z,Q) 上升至与 L ( θ ) L(\theta) L(θ)在此点 θ \theta θ 处相等(绿色曲线到蓝色曲线),然后固定 Q ( z ) Q(z) Q(z) ,调整 θ \theta θ 使下界 J ( z , Q ) J(z,Q) J(z,Q) 达到最大值( θ t \theta_t θt 到 θ t + 1 \theta_{t+1} θt+1 ),然后再固定 θ \theta θ ,调整 Q ( z ) Q(z) Q(z) ,一直到收敛到似然函数 L ( θ ) L(\theta) L(θ) 的最大值处的 θ \theta θ 。
也就是说,EM 算法通过引入隐含变量,使用 MLE(极大似然估计)进行迭代求解参数。通常引入隐含变量后会有两个参数,EM 算法首先会固定其中的第一个参数,然后使用 MLE 计算第二个变量值;接着通过固定第二个变量,再使用 MLE 估测第一个变量值,依次迭代,直至收敛到局部最优解。
但是这里有两个问题:
- 什么时候下界 J ( z , Q ) J(z,Q) J(z,Q) 与 L ( θ ) L(\theta) L(θ) 相等?
- 为什么一定会收敛?
最后第一个问题,当 X = E [ X ] X=E[X] X=E[X]时,即为常数时等式成立:
p ( x i , z ; θ ) Q i ( z ) = c \frac{p\left(x_{i}, z ; \theta\right)}{Q_{i}(z)}=c Qi(z)p(xi,z;θ)=c
做个变换:
∑ z p ( x i , z ; θ ) = ∑ z Q i ( z ) c \sum_{z} p\left(x_{i}, z ; \theta\right)=\sum_{z} Q_{i}(z) c z∑p(xi,z;θ)=z∑Qi(z)c
其中 ∑ z Q i ( z ) = 1 \sum_{z} Q_{i}(z)=1 ∑zQi(z)=1,所以可以推导出:
∑ z p ( x i , z ; θ ) = c \sum_{z} p\left(x_{i}, z ; \theta\right)=c z∑p(xi,z;θ)=c
因此得到了:
Q i ( z ) = p ( x i , z ; θ ) ∑ z p ( x i , z ; θ ) = p ( x i , z ; θ ) p ( x i ; θ ) = p ( z ∣ x i ; θ ) \begin{aligned} Q_{i}(z) &=\frac{p\left(x_{i}, z ; \theta\right)}{\sum_{z} p\left(x_{i}, z ; \theta\right)} \\ &=\frac{p\left(x_{i}, z ; \theta\right)}{p\left(x_{i} ; \theta\right)} \\ &=p\left(z \mid x_{i} ; \theta\right) \end{aligned} Qi(z)=∑zp(xi,z;θ)p(xi,z;θ)=p(xi;θ)p(xi,z;θ)=p(z∣xi;θ)
至此我们推出了在固定参数下,使下界拉升的 Q ( z ) Q(z) Q(z)的计算公式就是后验概率,同时解决了 Q ( z ) Q(z) Q(z)如何选择的问题。这就是我们刚刚说的 EM 算法中的 E-Step,目的是建立 L ( θ ) L(\theta) L(θ) 的下界。接下来得到 M-Step 目的是在给定 Q ( z ) Q(z) Q(z)后调整 θ \theta θ,从而极大化似然函数 L ( θ ) L(\theta) L(θ) 的下界 J ( z , Q ) J(z,Q) J(z,Q) 。
对于第二个问题,为什么一定会收敛?
这边简单说一下,因为每次 θ \theta θ更新时(每次迭代时),都可以得到更大的似然函数,也就是说极大似然函数时单调递增,那么我们最终就会得到极大似然估计的最大值。
但是要注意,迭代一定会收敛,但不一定会收敛到真实的参数值,因为可能会陷入局部最优。所以 EM 算法的结果很受初始值的影响。
4. 应用
EM 的应用有很多,比如、混合高斯模型、聚类、HMM 等等。其中 EM 在 K-means 中的用处,我将在介绍 K-means 中的给出。
更多请见:https://zhuanlan.zhihu.com/p/78311644