日撸java三百行day75-76
文章目录
- 说明
- 通用BP神经网络
-
- 1.通用神经网络
- 2.代码理解
-
- 2.1 FullAnn类
- 2.2 forward函数
- 2.3 backPropagation函数
- 2.4 不同激活函数的对比结果
说明
闵老师的文章链接: 日撸 Java 三百行(总述)_minfanphd的博客-CSDN博客
自己也把手敲的代码放在了github上维护:https://github.com/fulisha-ok/sampledata
通用BP神经网络
1.通用神经网络
在day71-73实现BP神经网络中,我们知道神经网络的实现中,主要是关注前向传播函数和反向传播函数,而在这两个函数的实现过程中,激活函数是必须的。所以通用神经网络我们也主要关注这几个方面。
- 通用激活函数类:
在day71-73实现BP神经网络中,是固定选择了激活函数sigmoid,但实际上在day74梳理了很多激活函数,所以为了适用性更强,专门新建了一个通用类Activator(激活函数类)可以灵活调用不同的激活函数。
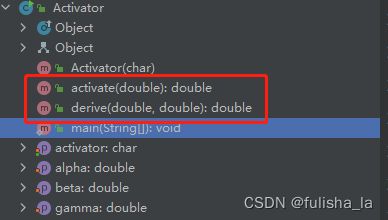
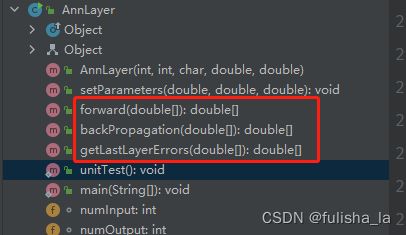
- 单层实现类
前向传播函数和反向传播函数的实现。具体的实现和day71-73一样,只不过在这里没有固定激活函数,而是灵活选择。
2.代码理解
2.1 FullAnn类
FullAnn类继承了GeneralAnn,重写了父类的forward和backPropagation函数,而且引入了单层实现类AnnLayer[] layers;
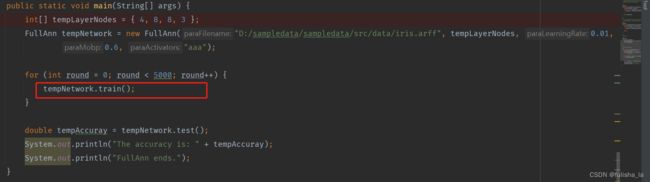
我还是从main方法开始,一步步去走一遍过程。
- FullAnn调用trian方法
train方法直接是调用父类的trian方法。而其中的forward和backPropagation是调用的FullAnn继承GeneralAnn后重新实现的方法
/**
* Train using the dataset.
*/
public void train() {
double[] tempInput = new double[dataset.numAttributes() - 1];
double[] tempTarget = new double[dataset.numClasses()];
for (int i = 0; i < dataset.numInstances(); i++) {
// Fill the data.
for (int j = 0; j < tempInput.length; j++) {
tempInput[j] = dataset.instance(i).value(j);
}
// Fill the class label.
Arrays.fill(tempTarget, 0);
tempTarget[(int) dataset.instance(i).classValue()] = 1;
// Train with this instance.
forward(tempInput);
backPropagation(tempTarget);
}
}
2.2 forward函数
forward方法就目前我们选择的激活函数是ARC_TAN(反三角函数)
resultArray = layers[i].forward(resultArray);我们是根据初始化选择的激活函数,调用Activator类的activate方法进行计算得出的输出值。(将输入数据从输入层经过各层的神经元传递至输出层的过程,每个神经元将输入值与权重相乘并求加权和,经过激活函数处理后输出给下一层的神经元。这样一层层传递,直到输出层得到最终的预测结果)
FullAnn类:
@Override
public double[] forward(double[] paraInput) {
double[] resultArray = paraInput;
for(int i = 0; i < numLayers - 1; i ++) {
resultArray = layers[i].forward(resultArray);
}
return resultArray;
}
AnnLayer类:
public double[] forward(double[] paraInput) {
//System.out.println("Ann layer forward " + Arrays.toString(paraInput));
// Copy data.
for (int i = 0; i < numInput; i++) {
input[i] = paraInput[i];
}
// Calculate the weighted sum for each output.
for (int i = 0; i < numOutput; i++) {
output[i] = weights[numInput][i];
for (int j = 0; j < numInput; j++) {
output[i] += input[j] * weights[j][i];
}
activatedOutput[i] = activator.activate(output[i]);
}
return activatedOutput;
}
Activator类:
public double activate(double paraValue) {
double resultValue = 0;
switch (activator) {
case ARC_TAN:
resultValue = Math.atan(paraValue);
break;
case ELU:
if (paraValue >= 0) {
resultValue = paraValue;
} else {
resultValue = alpha * (Math.exp(paraValue) - 1);
}
break;
// case GELU:
// resultValue = ?;
// break;
// case HARD_LOGISTIC:
// resultValue = ?;
// break;
case IDENTITY:
resultValue = paraValue;
break;
case LEAKY_RELU:
if (paraValue >= 0) {
resultValue = paraValue;
} else {
resultValue = alpha * paraValue;
}
break;
case SOFT_SIGN:
if (paraValue >= 0) {
resultValue = paraValue / (1 + paraValue);
} else {
resultValue = paraValue / (1 - paraValue);
}
break;
case SOFT_PLUS:
resultValue = Math.log(1 + Math.exp(paraValue));
break;
case RELU:
if (paraValue >= 0) {
resultValue = paraValue;
} else {
resultValue = 0;
}
break;
case SIGMOID:
resultValue = 1 / (1 + Math.exp(-paraValue));
break;
case TANH:
resultValue = 2 / (1 + Math.exp(-2 * paraValue)) - 1;
break;
// case SWISH:
// resultValue = ?;
// break;
default:
System.out.println("Unsupported activator: " + activator);
System.exit(0);
}
return resultValue;
}
2.3 backPropagation函数
backPropagation中getLastLayerErrors是计算最后一层的误差值,tempErrors = layers[i].backPropagation(tempErrors);是根据初始化选择的激活函数计算起反向传播的误差值。(根据预测结果与真实标签之间的差异,通过调整网络中的权重来减小预测误差的过程。反向传播利用梯度下降优化算法,从输出层开始,根据误差计算每个神经元的梯度,并将梯度信息传递回前一层,以调整权重) FullAnn类
FullAnn类
@Override
public void backPropagation(double[] paraTarget) {
double[] tempErrors = layers[numLayers - 2].getLastLayerErrors(paraTarget);
for (int i = numLayers - 2; i >= 0; i--) {
tempErrors = layers[i].backPropagation(tempErrors);
}
return;
}
AnnLayer类:
public double[] getLastLayerErrors(double[] paraTarget) {
double[] resultErrors = new double[numOutput];
for (int i = 0; i < numOutput; i++) {
resultErrors[i] = (paraTarget[i] - activatedOutput[i]);
}
return resultErrors;
}
public double[] backPropagation(double[] paraErrors) {
//Step 1. Adjust the errors.
for (int i = 0; i < paraErrors.length; i++) {
paraErrors[i] = activator.derive(output[i], activatedOutput[i]) * paraErrors[i];
}
//Step 2. Compute current errors.
for (int i = 0; i < numInput; i++) {
errors[i] = 0;
for (int j = 0; j < numOutput; j++) {
errors[i] += paraErrors[j] * weights[i][j];
deltaWeights[i][j] = mobp * deltaWeights[i][j]
+ learningRate * paraErrors[j] * input[i];
weights[i][j] += deltaWeights[i][j];
}
}
for (int j = 0; j < numOutput; j++) {
deltaWeights[numInput][j] = mobp * deltaWeights[numInput][j] + learningRate * paraErrors[j];
weights[numInput][j] += deltaWeights[numInput][j];
}
return errors;
}
Activator类:
public double derive(double paraValue, double paraActivatedValue) {
double resultValue = 0;
switch (activator) {
case ARC_TAN:
resultValue = 1 / (paraValue * paraValue + 1);
break;
case ELU:
if (paraValue >= 0) {
resultValue = 1;
} else {
resultValue = alpha * (Math.exp(paraValue) - 1) + alpha;
}
break;
// case GELU:
// resultValue = ?;
// break;
// case HARD_LOGISTIC:
// resultValue = ?;
// break;
case IDENTITY:
resultValue = 1;
break;
case LEAKY_RELU:
if (paraValue >= 0) {
resultValue = 1;
} else {
resultValue = alpha;
}
break;
case SOFT_SIGN:
if (paraValue >= 0) {
resultValue = 1 / (1 + paraValue) / (1 + paraValue);
} else {
resultValue = 1 / (1 - paraValue) / (1 - paraValue);
}
break;
case SOFT_PLUS:
resultValue = 1 / (1 + Math.exp(-paraValue));
break;
case RELU: // Updated
if (paraValue >= 0) {
resultValue = 1;
} else {
resultValue = 0;
}
break;
case SIGMOID: // Updated
resultValue = paraActivatedValue * (1 - paraActivatedValue);
break;
case TANH: // Updated
resultValue = 1 - paraActivatedValue * paraActivatedValue;
break;
// case SWISH:
// resultValue = ?;
// break;
default:
System.out.println("Unsupported activator: " + activator);
System.exit(0);
}
return resultValue;
}
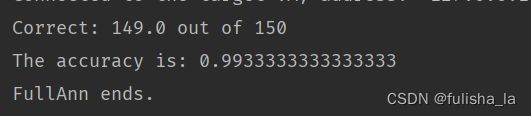
2.4 不同激活函数的对比结果
ARC_TAN:
ELU:

SOFT_SIGN:
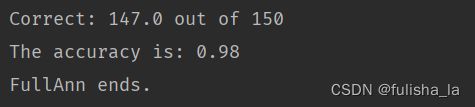
SIGMOID:

SOFT_PLUS:

从运行结果可以看出,不同的激活函数对网络的影响是不同的,有的预测结果更准确有的则效果不明显。说明不同的激活函数的使用场景也会有所区别。