【图像分割 2023 CVPR】CFNet
文章目录
- 【图像分割 2023 CVPR】CFNet
-
- 摘要
- 1. 简介
- 2. 相关工作
-
- 2.1 稠密预测的主干网设计
- 2.2 多尺度特征融合
- 3. 方法
-
- 3.1 整体架构
- 3.2 过渡块
- 3.4 结构变体
【图像分割 2023 CVPR】CFNet
论文题目:CFNet: Cascade Fusion Network for Dense Prediction
中文题目:CFNet:用于密集预测的级联融合网络
论文链接:https://arxiv.org/abs/2302.06052
论文代码:
论文团队:
发表时间:
DOI:
引用:
引用数:
摘要
多尺度特征对于对象检测、实例分割和语义分割等密集预测任务是必不可少的。 现有的最先进的方法通常首先通过分类主干提取多尺度特征,然后通过轻量级模块(如FPN中的融合模块)对这些特征进行融合。 然而,我们认为,通过这样一个范例来融合多尺度特征可能是不可取的,因为与笨重的分类主干相比,为特征融合分配的参数是有限的。 为了解决这一问题,我们提出了一种新的结构&级联融合网络(CFNET)用于密集预测。 在CFNET中,除了提取初始高分辨率特征的STEM和几个块外,我们还引入了几个级联阶段来生成多尺度特征。 每个阶段包括用于特征提取的子主干和用于特征集成的极其轻量级的过渡块。 这种设计使得整个主干的大比例参数更深入有效地融合特征成为可能。 在对象检测、实例分割和语义分割等方面进行了大量的实验,验证了所提出的CFNET的有效性。 代码将在这里提供。
1. 简介
在过去的几年里,卷积神经网络(CNNs)和基于变换器的网络在许多计算机视觉任务中取得了很好的结果,包括图像分类、对象检测、语义分割等。对于图像分类任务,最流行的细胞神经网络[1-5]和最近开发的基于变换器的网络[6-9]在架构设计中通常遵循顺序方式,即逐渐减小特征图的空间大小,并基于最粗略的特征尺度进行预测。然而,对于许多密集的预测任务,如对象检测和实例分割,需要多尺度特征来处理不同尺度的对象。获得多尺度特征并将其集成CNN[1-5]和最近开发的基于变换器的网络[6-9]通常在架构设计中遵循顺序方式,即逐渐减小特征图的空间大小,并基于最粗尺度的特征进行预测。然而,对于许多密集的预测任务,如对象检测和实例分割,需要多尺度特征来处理不同尺度的对象。获得多尺度特征并对其进行有效集成对于这些任务的成功至关重要[10-14]。
特征金字塔网络(FPN)及其变体[14-20]是目前广泛应用的多尺度特征提取和融合模型。 如图1(a)所示,这些模型通常由一个用于提取多尺度特征的重分类背骨和一个用于融合这些特征的轻量级融合模块组成。 然而,我们认为,使用这种范式可能不足以融合多尺度特征,因为与重型分类主干相比,特征融合所分配的参数是有限的。 例如,考虑一个基于骨干Convnext-S[5]构建的FPN,融合模块的参数与骨干的比值小于10%。 我们认为,在特征融合中分配较大比例的参数可以获得更好的性能。

给定固定的计算预算,如果我们想为特征融合分配更多的参数,一个直观的方法是使用较小的主干网,并扩大融合模块的规模。 然而,使用较小的主干意味着整个模型从大规模预训练(例如,ImageNet分类预训练)中受益较少,这对于训练数据有限的下游任务至关重要。 那么如何分配更多的参数来实现特征融合,同时保持一个简单的模型架构,仍然可以最大程度地受益于大规模的预训练呢?
我们先来回顾一下FPN的融合模块。为了融合多尺度特征,首先对相邻层次的特征进行元素加法,然后使用单个3×3卷积对相加后的特征进行变换。我们将这两个步骤称为特征融合和特征转换,从而构成特征融合。很明显,我们可以堆栈更多的卷积来转换集成的特征,但它引入了更多的参数,留给主干的参数更少。从另一个角度思考,我们进一步询问是否可以将特征整合操作插入到主干中,使其之后的所有参数都可以用来对整合后的特征进行转换。
在本工作中,我们试图回答上述问题。 本文提出了一种用于密集预测的级联融合网络(CFNET)。 图1(b)说明了CFNET的信息流。 它可以看作是重组不同尺度特征之间联系的结果。 图3显示了CFNET的体系结构。 基于一个茎和几个块提取的高分辨率特征,引入M级联CFNET级来生成多尺度特征。 所有阶段共享相同的结构,但它们的大小可以不同。 具体地说,每个阶段包括用于提取多尺度特征的子主干和用于集成这些特征的极其轻量级的过渡块。 这样,我们将特征集成操作插入到主干中,以便集成的特征可以在过渡块之后进行所有阶段的转换。 也就是说,过渡块之后的所有参数都可以用于特征融合。 此外,我们在图像分类任务上进行的实验表明,由于CFNET的结构简单,它仍然可以从大规模的预训练中受益。
基于所提出的CFNET,我们进行了一系列实验来验证我们的假设。 定义CFNET中用于特征融合的参数比例为第一个过渡块后各阶段的参数占整个骨干的比例。 图2中的结果表明,随着特征融合参数的增加,检测性能逐渐提高,验证了我们的假设。 更多详情请参阅第4.1节。
我们对三个流行的密集预测任务进行了广泛的实验。 在COCO VAL 2017用于对象检测和实例分割上,CFNET的性能优于其基线,即SWIN Transformer[6]和ConvNext[5],基于流行的RetinaNet[4]和Mask R-CNN[10]的Box AP和Mask AP分别为1.9-2.9和1.2-1.8。 在用于语义分割的ADE20K上,CFNET在强大的UperNet[13]的基础上比其基线性能高出0.8-2.2miou。 这些结果表明CFNET的强大性能,并鼓励社区重新思考广泛使用的密集预测任务模型设计原则。
2. 相关工作
2.1 稠密预测的主干网设计
对于密集的预测任务,现有的大多数工作都采用图像分类网络和特征融合模块相结合的策略来提取和融合多尺度特征。然而,将预先设计的分类网络直接应用于密集预测任务可能是次优的。因此,为密集预测设计任务友好型主干引起了人们的极大兴趣[21-29]。为了获得具有强语义的高分辨率特征,UNet[21]和SegNet[22]都采用了类似的具有跳跃连接的U形结构进行医学图像分割。Hourglass[23]介绍了一种卷积网络架构,该架构使用重复的自下而上和自上而下的处理来完成人体姿态估计任务。HRNet[25]在整个转发过程中保持高分辨率特征,并且所得到的表示在语义分割和人体姿态估计方面表现良好。SpineNet[26]引入了神经结构搜索(NAS)[30]来学习用于对象检测的尺度排列主干。GiraffeDet[29]采用了轻量级主干与重型融合模块相结合,以鼓励不同规模特征之间的密集信息交换。CBNet[27]通过在相邻主干之间引入复合连接来组装多个相同的主干。DetectoRS[28]直接堆叠多个FPN来增强多尺度特征。与这些方法不同的是,我们引入了几个级联阶段,在CFNet中基于提取的高分辨率特征迭代提取和集成多尺度特征。
2.2 多尺度特征融合
由于传统分类网络生成的低级特征在语义上较弱,这些多尺度特征不适合下游密集预测任务。为了解决这个问题,已经提出了许多用于多尺度特征融合的方法[14-18,31-33]。对于语义分割,DeeplabV3+[31]将低级特征与通过萎缩的空间金字塔池获得的语义强的高级特征融合在一起。ESeg[32]采用了更丰富的多尺度特征空间,并使用强大的特征融合网络来融合特征。对于对象检测,FPN[14]引入了一种自上而下的方法,将高级特征与低级特征依次组合。PANet[15]进一步增加了另一种自下而上的途径,以缩短低级特征和最高级特征之间的信息途径。NAS-FPN[16]通过NAS[30]搜索的重复融合阶段融合多尺度特征。EfficientDet[17]采用具有复合缩放规则的加权双向特征金字塔网络来实现简单快速的多尺度特征融合。A2-FPN[18]通过注意力引导的特征聚合改进了多尺度特征学习。所有上述方法都依赖于重分类主干来提取多尺度特征,然后用轻量级融合模块融合这些特征。然而,与分类主干相比,融合模块的参数是有限的。相反,我们提出了一个非常轻量级的转换块,并将其插入到主干中。这样,过渡块之后的所有阶段都可以用于融合集成的多尺度特征。
3. 方法
3.1 整体架构
CFNet体系结构的概述如图3所示。将空间大小为H×W的输入RGB图像馈送到一个干和N个连续块中,以提取空间大小为H4×W4的高分辨率特征。茎由两个3×3的卷积组成,步长为2,每个卷积后面都有一个LayerNorm[34]层和一个GELU[35]单元。CFNet中的块可以是先前工作中提出的任何设计,例如ResNet瓶颈[4]、ConvNeXt块[5]、Swin Transformer块[6]等。
在被送入M级联级之前,提取的高分辨率特征通过步幅为2的2×2卷积进行下采样。 所有阶段共享相同的结构,但可能具有不同的大小,即不同的块数。 具体来说,每个阶段都由子主干和极其轻量级的过渡块组成,用于提取和集成不同尺度的特征。 在这里,我们将每个阶段的块组定义为用于转换相同尺度特征的块的并集。 N1I、N2I和N3I分别表示第I级的三个块组中包括的块的数量。 在每个阶段的最后一个块组中,应用焦点块。 关于过渡块和焦点块的更多细节分别在3.2节和3.3节中介绍。 值得注意的是,每级输出特征P3、P4、P5,步幅为8、16、32,但只有P3被馈入后期。 最后,将最后一阶段输出的融合特征P3、P4和P5用于密集预测任务。
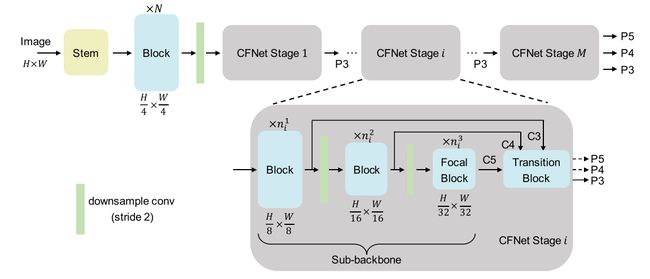
图3。CFNet的体系结构。首先将空间大小为H×W的输入图像馈送到一个干和N个连续块中,以提取空间大小为H4×W4的高分辨率特征。然后,将这些特征馈送到M个级联级中以提取多尺度特征。每个阶段输出具有步幅8、16、32的融合特征P3、P4、P5,但只有P3被馈送到后面的阶段。请注意,只有主干和“下采样对流”会减小特征的空间大小。×nki(k=1,2,3)表示应用了nki个连续块。
3.2 过渡块
引入过渡块,在每个阶段整合不同尺度的特征。为了避免引入过多的额外计算成本,我们提出了三个简单的设计,如图4所示。“添加”融合首先减少了特征C4和C5的频道数,以对齐C3与1×1卷积的频道数。在执行元素加法之前,双线性插值操作用于对齐特征的空间大小。“Concat”融合直接对C4和C5特征进行采样,以对齐C3的空间大小,然后将这些特征连接起来,然后进行1×1卷积以减少通道数量。“顺序添加”融合了样本,并将不同尺度的特征顺序地组合在一起。这个设计类似于FPN中的融合模块,除了没有额外的卷积来转换求和的特征。以上三种设计在实验中均表现良好(对比见4.5节表8),其中“顺序添加”融合的效果最好。我们在CFNet变体中默认采用这种设计(见章节3.4)。
对于密集预测任务,处理各种尺度的对象一直是一大挑战。 一种广泛使用的解决方案是生成不同分辨率的特征。 例如,通常生成步幅为8、16、32、64、128的特征,以在一级检测器中检测相应比例的对象[11、12、36、37]。 用于产生步幅较大的特征的神经元通常具有较大的感受野。 在CFNET的每个阶段中,有三个块组来提取特征,步幅分别为8、16、32。 理想情况下,我们可以提取另外两个分辨率特征来集成更多的特征尺度,如FPN变体[15-17]。 但是,它会引入更多的参数,因为随着特征空间尺寸的缩小,后续组的通道数逐渐增加。 因此,我们提出局灶阻滞扩大每一阶段最后一个阻滞组神经元的感受野作为替代方式。
图5给出了焦块的两种设计。 在ConvNext模块和SWIN变压器模块中都引入了扩展的深度卷积和两个跳过连接。 因此,Focal Block可以同时包含细粒度的局部交互和粗粒度的全局交互(Focal Block的名称来自这里)。 利用全局注意力[38,39]或大卷积核[5,40]来扩大感受野是近年来研究的热点。 虽然取得了很好的效果,但由于输入图像大小较大,将这些操作应用于密集预测任务时,通常会引入大量的计算开销和内存开销。 相比之下,拟议的重点区块引入了边际额外费用(见第4.5节表9进行比较)。

3.4 结构变体
我们构建了三种CFNet变体,即CFNet-T(Swin)、CFNet-T和CFNet-S(NeXt)。T和S分别是单词tiny和small的缩写,表示模型的大小。第一个使用Swin Transformer块和焦点Swin块。另外两个使用ConvNeXt块和焦点NeXt组块。每个CFNet变体的详细配置如表1所示。CFNet-T和CFNet-S的级数分别设置为3和4。尽管具有不同配置的不同阶段可能会获得更好的性能,但为了简单起见,我们为所有阶段设置了相同的配置。并且所有焦块中的膨胀率r默认设置为3。由于计算资源的限制,我们在本文中没有考虑更大的CFNet变体。
