ImVoxelNet 论文学习
论文链接:ImVoxelNet: Image to Voxels Projection for Monocular and Multi-View General-Purpose 3D Object Detection
1. 解决了什么问题?
RGB 图像成本低、数据源丰富,可以提供场景和物体的视觉信息,但不包括场景几何结构的直接信息。因此,从 RGB 图像检测 3D 物体本身就是不适当的。给定一张单目图像,基于深度学习的 3D 检测方法只能推断数据的尺度。有些区域是看不到的,我们无法从 RGB 图像中清楚地推断出场景的几何结构。但是通过多个位姿的图像就能获取到比单目图像更丰富的场景信息。
现有的方法基本是独立地预测每张单目 RGB 图像,然后融合预测的结果。而本文方法在训练和测试时可接受任意数量的视角输入,效果更优。
2. 提出了什么方法?
将多视角基于 RGB 3D 目标检测方法看作为端到端的优化问题,提出了 ImVoxelNet。为了融合不同输入的信息,作者构建了一个 3D 空间的体素表征,然后从该 3D 特征图做最终的预测,类似于点云检测的方式。
2.1 方法
本文方法可以接受任意数量的、带相机位姿的 RGB 输入。首先使用一个 2D 卷积主干网络提取特征,然后将图像特征投影到 3D 体素空间。通过简单地逐元素求均值,聚合多张图像的投影特征,得到每个体素的特征。然后将这个体素 volume 输入进 neck(一个 3D 卷积网络)。Neck 的输出再输入进检测 head(一些卷积层),预测每个 anchor 的边框特征。最终的边框预测结果表示为 ( x , y , z , w , h , l , θ ) (x,y,z,w,h,l,\theta) (x,y,z,w,h,l,θ),其中 ( x , y , z ) (x,y,z) (x,y,z)是中心点的坐标, w , h , l w,h,l w,h,l是宽度、高度、长度, θ \theta θ是 z z z轴的旋转角度。整体架构如下图所示。
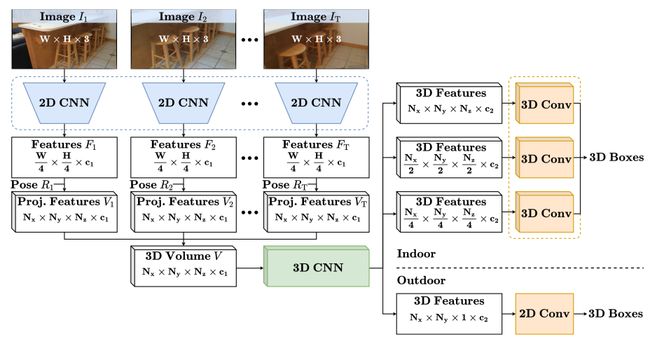
2.1.1 3D Volume Construction
用 I t ∈ R W × H × 3 I_t\in\mathbb{R}^{W\times H\times 3} It∈RW×H×3表示集合里的第 t t t帧图像,该集合共有 T T T张图像,对于多视角输入, T > 1 T>1 T>1;对于单视角输入, T = 1 T=1 T=1。使用一个预训练 2D 主干网络提取输入图像的 2D 特征,输出四个特征图,形状分别是 W 4 × H 4 × c 0 , W 8 × H 8 × 2 c 0 , W 16 × H 16 × 4 c 0 , W 32 × H 32 × 8 c 0 \frac{W}{4}\times \frac{H}{4}\times c_0,\frac{W}{8}\times \frac{H}{8}\times 2c_0,\frac{W}{16}\times \frac{H}{16}\times 4c_0,\frac{W}{32}\times \frac{H}{32}\times 8c_0 4W×4H×c0,8W×8H×2c0,16W×16H×4c0,32W×32H×8c0。通过一个 FPN 聚合这些特征图,输出一个形状是 W 4 × H 4 × c 1 \frac{W}{4}\times \frac{H}{4}\times c_1 4W×4H×c1的张量 F t F_t Ft, c 0 , c 1 c_0,c_1 c0,c1值与具体主干网络有关。
然后将第 t t t个输入的 2D 特征 F t F_t Ft投影到 3D 体素 volume V t ∈ R N x × N y × N z × c 1 V_t\in \mathbb{R}^{N_x\times N_y\times N_z\times c_1} Vt∈RNx×Ny×Nz×c1里面。设定 z z z轴垂直于地面, x x x轴指向前方, y y y轴正交于 x x x轴和 z z z轴。这三个轴都有各自的限制范围,记做 x m i n , x m a x , y m i n , y m a x , z m i n , z m a x x_{min}, x_{max}, y_{min}, y_{max}, z_{min}, z_{max} xmin,xmax,ymin,ymax,zmin,zmax。对于一个固定的体素大小 s s s,空间约束可以表示为 N x s = x m a x − x m i n , N y s = y m a x − y m i n , N z s = z m a x − z m i n N_xs=x_{max}-x_{min}, N_ys=y_{max}-y_{min}, N_zs=z_{max}-z_{min} Nxs=xmax−xmin,Nys=ymax−ymin,Nzs=zmax−zmin。使用小孔成像模型来判断特征图 F t F_t Ft上的 2D 坐标 ( u , v ) (u,v) (u,v)和 volume V t V_t Vt的 3D 坐标 ( x , y , z ) (x,y,z) (x,y,z)之间的对应关系:
[ u v ] = Π [ 1 4 0 0 0 1 4 0 0 0 1 ] K R t [ x y z 1 ] \left[\begin{array}{c} u \\ v \end{array}\right]=\Pi \left[\begin{array}{c} \frac{1}{4} & 0 & 0\\ 0 & \frac{1}{4} & 0\\ 0 & 0 & 1 \end{array}\right]KR_t \left[\begin{array}{c} x\\ y\\ z\\ 1 \end{array}\right] [uv]=Π 41000410001 KRt xyz1
其中 K K K和 R t R_t Rt是内参和外参矩阵, Π \Pi Π是透视映射。将 2D 特征投影后,某条相机射线上的所有体素都会被填充上相同的特征。定义一个形状与 V t V_t Vt相同的二值 mask M t M_t Mt,表示每个体素是否在相机视锥内。因此,对于每张图像 I t I_t It, M t M_t Mt定义如下:
M t ( x , y , z ) = { 1 , if 0 ≤ u < W 4 and 0 ≤ v < H 4 0 , otherwise M_t(x,y,z)=\left\{ \begin{aligned} 1,& \quad\text{if} &0\leq u<\frac{W}{4} \text{and} 0\leq v<\frac{H}{4} \\ 0,& & \text{otherwise} \end{aligned} \right. Mt(x,y,z)=⎩ ⎨ ⎧1,0,if0≤u<4Wand0≤v<4Hotherwise
然后将 F t F_t Ft投影到 V t V_t Vt中每个有效的体素:
V t ( x , y , z ) = { F t ( u , v ) , if M t ( x , y , z ) = 1 0 , otherwise V_t(x,y,z)=\left\{ \begin{aligned} F_t(u,v),&\quad \text{if} &M_t(x,y,z)=1 \\ 0,& & \text{otherwise} \end{aligned} \right. Vt(x,y,z)={Ft(u,v),0,ifMt(x,y,z)=1otherwise
将 M 1 , . . . , M t M_1,...,M_t M1,...,Mt融合,得到二值 mask M M M:
M ( x , y , z ) = { ∑ t M t ( x , y , z ) , if ∑ t M t ( x , y , z ) > 0 1 , otherwise M(x,y,z)=\left\{ \begin{aligned} \sum_tM_t(x,y,z),&\quad \text{if} &\sum_tM_t(x,y,z)>0 \\ 1,& & \text{otherwise} \end{aligned} \right. M(x,y,z)=⎩ ⎨ ⎧t∑Mt(x,y,z),1,ift∑Mt(x,y,z)>0otherwise
最后,将 V 1 , . . . , V t V_1,...,V_t V1,...,Vt的特征求平均得到 3D volume V V V:
V = 1 M ∑ t M t V t V=\frac{1}{M}\sum_t M_tV_t V=M1t∑MtVt
2.2 3D 特征提取
室内
将体素 volume V V V输入一个 3D 卷积 encoder-decoder 网络,优化特征。对于室内场景,作者简化了网络,减少耗时的 3D 卷积层。简化后的 encoder 只有三个下采样残差模块,每个有三个 3D 卷积层。简化后的 decoder 包括三个上采样模块,每个模块由一个步长为 2 2 2的转置 3D 卷积层和一个 3D 卷积层组成。Decoder 分支输出三个特征图,形状如下: N x 4 × N y 4 × N z 4 × c 2 \frac{N_x}{4}\times \frac{N_y}{4}\times \frac{N_z}{4}\times c_2 4Nx×4Ny×4Nz×c2, N x 2 × N y 2 × N z 2 × c 2 \frac{N_x}{2}\times \frac{N_y}{2}\times \frac{N_z}{2}\times c_2 2Nx×2Ny×2Nz×c2,和 N x × N y × N z × c 2 N_x\times N_y\times N_z\times c_2 Nx×Ny×Nz×c2。
室外
将 3D 空间的 3D 目标检测降低为 BEV 平面的 2D 检测问题。Necks 和 heads 都由 2D 卷积层组成。Head 的输入是一个 2D 特征图,所以我们应该从 3D 体素 volume 中获取一个 2D 表征。形状是 N x × N y × N z × c 1 N_x\times N_y\times N_z\times c_1 Nx×Ny×Nz×c1的体素 volume V V V经过由多个 3D 卷积和下采样操作组成的 encoder 后,就映射成一个形状是 N x × N y × c 2 N_x\times N_y\times c_2 Nx×Ny×c2的张量。
2.3 Detection Heads
ImVoxelNet 构建一个 3D 体素表征。因此,它能利用激光点云 3D 检测方法的 heads。
2.3.1 室外 Head
将室外 3D 检测看作为 BEV 平面的 2D 目标检测。作者使用了 2D anchor head,它在 KITTI 和 nuScenes 上都很高效率。因为室外 3D 检测方法是在车辆上做评价,所以目标的尺度都相似,而且属于同一个类别。对于单尺度、单类别检测,head 包括两个平行的 2D 卷积层。一层估计类别概率,另一层回归边框的七个参数。
输入
输入是形状为 N x × N y × c 2 N_x\times N_y\times c_2 Nx×Ny×c2的张量。
输出
对于每个 2D BEV anchor,head 返回一个类别概率 p p p和一个七元组的 3D 框:
Δ x = x g t − x a d a , Δ y = y g t − y a d a , Δ z = z g t − z a d a \Delta{x}=\frac{x^{gt}-x^a}{d^a},\Delta{y}=\frac{y^{gt}-y^a}{d^a},\Delta{z}=\frac{z^{gt}-z^a}{d^a} Δx=daxgt−xa,Δy=daygt−ya,Δz=dazgt−za
Δ w = log w g t w a , Δ l = log l g t l a , Δ h = log h g t h a \Delta{w}=\log\frac{w^{gt}}{w^a},\Delta{l}=\log{\frac{l^{gt}}{{l^a}}},\Delta{h}=\log\frac{h^{gt}}{h^a} Δw=logwawgt,Δl=loglalgt,Δh=loghahgt
Δ θ = sin ( θ g t − θ a ) \Delta{\theta}=\sin(\theta^{gt}-\theta^a) Δθ=sin(θgt−θa)
这里 ⋅ g t \cdot^{gt} ⋅gt和 ⋅ a \cdot^{a} ⋅a是 ground-truth 和 anchor boxes。边框对角线长度是 d a = ( w a ) 2 + ( l a ) 2 d^a=\sqrt{(w^a)^2+(l^a)^2} da=(wa)2+(la)2。 z a z^a za对于所有的 anchors 都是常量,因为是定位在 BEV 平面的。
Loss
使用了与 SECOND 算法一样的损失函数。损失包括多个损失项,定位损失 L l o c L_{loc} Lloc使用平滑平均绝对值损失,分类损失 L c l s L_{cls} Lcls用的是 focal loss,方向损失 L d i r L_{dir} Ldir用的是交叉熵损失。
L o u t d o o r = 1 n p o s ( λ l o c L l o c + λ c l s L c l s + λ d i r L d i r ) L_{outdoor}=\frac{1}{n_{pos}}(\lambda_{loc}L_{loc}+\lambda_{cls}L_{cls}+\lambda_{dir}L_{dir}) Loutdoor=npos1(λlocLloc+λclsLcls+λdirLdir)
其中 n p o s n_{pos} npos是正样本 anchor 的个数, λ l o c = 2 , λ c l s = 1 , λ d i r = 0.2 \lambda_{loc}=2,\lambda_{cls}=1,\lambda_{dir}=0.2 λloc=2,λcls=1,λdir=0.2。
2.3.2 室内 Head
目前所有的室内 3D 检测算法都对稀疏的点云表征使用深度 Hough voting。而本文使用的是密集的体素表征,于是作者受到 FCOS 启发,构建了一个 head 可以完成多尺度的 3D 目标检测。
FCOS head 的输入是 FPN 的 2D 特征,然后通过 2D 卷积层预测 2D 框。这里,作者将 2D 卷积替换为了 3D 卷积,处理 3D 输入。作者使用了中心采样来选取候选目标的像素位置。在 2D 检测,对于每个 ground-truth,候选样本个数是 3 × 3 = 9 3\times 3=9 3×3=9个,而在 3D 空间,候选样本个数就是 3 × 3 × 3 = 27 3\times 3\times 3=27 3×3×3=27。Head 包括三个 3D 卷积层,分别用于分类、定位、centerness,对所有的尺度都共享权重。
输入
多尺度输入包括三个张量,形状是 N x 4 × N y 4 × N z 4 × c 2 \frac{N_x}{4}\times \frac{N_y}{4}\times \frac{N_z}{4}\times c_2 4Nx×4Ny×4Nz×c2, N x 2 × N y 2 × N z 2 × c 2 \frac{N_x}{2}\times \frac{N_y}{2}\times \frac{N_z}{2}\times c_2 2Nx×2Ny×2Nz×c2, N x × N y × N z × c 2 N_x\times N_y\times N_z\times c_2 Nx×Ny×Nz×c2。
输出
对于每个 3D 坐标 ( x a , y a , z a ) (x^a,y^a,z^a) (xa,ya,za)和每种尺度,head 预测类别概率 p p p、centerness c c c、七元组的 3D 框:
Δ x m i n = x m i n g t − x a , Δ x m a x = x m a x g t − x a \Delta{x}_{min}=x_{min}^{gt}-x^a,\Delta{x}_{max}=x_{max}^{gt}-x^a Δxmin=xmingt−xa,Δxmax=xmaxgt−xa
Δ y m i n = y m i n g t − y a , Δ y m a x = y m a x g t − y a \Delta{y}_{min}=y_{min}^{gt}-y^a,\Delta{y}_{max}=y_{max}^{gt}-y^a Δymin=ymingt−ya,Δymax=ymaxgt−ya
Δ z m i n = z m i n g t − z a , Δ z m a x = z m a x g t − z a , θ . \Delta{z}_{min}=z_{min}^{gt}-z^a,\Delta{z}_{max}=z_{max}^{gt}-z^a,\theta. Δzmin=zmingt−za,Δzmax=zmaxgt−za,θ.
这里 x m i n g t , x m a x g t , y m i n g t , y m a x g t , z m i n g t , z m a x g t x_{min}^{gt},x_{max}^{gt},y_{min}^{gt},y_{max}^{gt},z_{min}^{gt},z_{max}^{gt} xmingt,xmaxgt,ymingt,ymaxgt,zmingt,zmaxgt表示 ground-truth 框三条轴对应的最小和最大的坐标值。
Loss
分类损失 L c l s L_{cls} Lcls是 focal loss,centerness 损失 L c n t r L_{cntr} Lcntr是交叉熵损失,定位损失 L l o c L_{loc} Lloc是 IoU 损失。作者将 2D IoU loss 替换为了旋转 3D IoU Loss。此外,用第三个维度更新了 ground-truth centerness 的值。
L i n d o o r = 1 n p o s ( L l o c + L c l s + L c n t r ) L_{indoor}=\frac{1}{n_{pos}}(L_{loc}+L_{cls}+L_{cntr}) Lindoor=npos1(Lloc+Lcls+Lcntr)
n p o s n_{pos} npos是正样本 3D 位置的个数。
2.4 Extra 2D Head
在一些室内场景基准上,3D 目标检测任务被看作是场景理解的一个子任务。因此,评测就不只是解决 3D 框估计的问题,而包括了各种场景理解任务。作者增加了一个简单的 head,预测 R t R_t Rt和 3D 布局。这个 head 包括两个平行分支:两个全连接层输出房间布局,另外两个全连接层预测相机旋转角度。
输入
输入是一个形状是 8 c 0 8c_0 8c0的张量,主干网络输出后经过全局平均池化得到。
输出
Head 输出相机的姿态(包括 pitch 角 β \beta β和 roll 角 γ \gamma γ),以及七元组的 3D 布局框 ( x , y , z , w , l , h , θ ) (x,y,z,w,l,h,\theta) (x,y,z,w,l,h,θ)。固定住 yaw 角,将其转为 0 0 0。
损失
布局损失 L l a y o u t L_{layout} Llayout定义为预测布局框和 ground-truth 框之间的旋转 3D IoU 损失。相机旋转角度预测使用的是 L p o s = ∣ sin ( β g t − β ) ∣ + ∣ sin ( γ g t − γ ) ∣ L_{pos}=|\sin(\beta^{gt}-\beta)|+|\sin(\gamma^{gt}-\gamma)| Lpos=∣sin(βgt−β)∣+∣sin(γgt−γ)∣。
整体损失如下:
L e x t r a = λ l a y o u t L l a y o u t + λ p o s e L p o s e L_{extra}=\lambda_{layout}L_{layout}+\lambda_{pose}L_{pose} Lextra=λlayoutLlayout+λposeLpose
λ l a y o u t = 0.1 , λ p o s e = 1.0 \lambda_{layout}=0.1, \lambda_{pose}=1.0 λlayout=0.1,λpose=1.0。