面向轻量化文图检索的 Dual-Encoder 模型蒸馏算法 ConaCLIP
近日,阿里云机器学习平台PAI与华南理工大学金连文教授团队合作在自然语言处理顶级会议ACL 2023上发表面向轻量化文图检索的dual-encoder模型蒸馏算法ConaCLIP( fully-Connected knowledge interaction graph for CLIP)。ConaCLIP针对轻量化的图文检索任务进行设计,是一种通过全连接的知识交互图学习方式将知识从dual-encoder大模型中蒸馏到dual-encoder小模型的算法。
论文:
Jiapeng Wang, Chengyu Wang, Xiaodan Wang, Jun Huang, Lianwen Jin. ConaCLIP: Exploring Distillation of Fully-Connected Knowledge Interaction Graph for Lightweight Text-Image Retrieval. ACL 2023 (Industry Track)
背景
文本-图像检索(Text-Image Retrieval)的目的是在给出一个特定的文本查询时,从一个大型的图像集合中检索出一个最相关的图像列表。随着信息交互和社交场景的快速发展,该任务一直被认为是跨模态应用的一个关键组成部分,并被各种现实世界的场景所需求,如电子商业平台,网站等。
现有的文图检索模型通常可以根据模型架构分为两类:跨流编码器(cross-encoder)和双流编码器(dual-encoder)。跨流编码器通常会添加额外的Transformer层来建模图像和文本特征之间的深度交互关系。这种架构通常可以提高检索性能,然而缺点是当该类模型应用于整个图像集合时,会导致检索速度非常缓慢。因为每当给出一个新的文本查询时,每个图像样本都需要进行跨模态的计算成本。相比之下,双流编码器是以一种完全解耦的方式分别编码视觉和文本输入。该类架构允许图像表示独立于文本查询,而进行预先的计算和重复使用。双流编码器还可以在运行时与快速近似最近邻(Approximate Nearest Neighbors)搜索相结合。
尽管双流编码器通常是现实应用中的首选,但现有的相关模型如CLIP在计算资源有限的边缘设备或动态索引场景如私人照片/消息集合上仍然不太实用。为了解决这个问题,我们的目标是从大规模的预训练双流编码器模型出发,专注于小模型预训练阶段的蒸馏过程,以获得一系列更小、更快、更有效的相应的轻量化模型。知识蒸馏(Knowledge Distillation)最先被提出利用soft targets将知识从教师转移给学生。MoTIS方法简单地重复在文本和图像领域分别进行模态内蒸馏的过程。然而,这些方法都只涉及了模态内的师生知识交互学习。
算法概述
与现有的工作不同,我们的方法引入了全连接知识交互图(fully-Connected knowledge interaction graph)用于预训练阶段的蒸馏。除了模态内教师-学生交互学习之外,我们的方法还包括模态内学生-学生交互学习、模态间教师-学生交互学习和模态间学生-学生交互学习,如下图所示。

这种为学生网络建立的全连接图可以看做是多视角和多任务的学习方案的集成,以此可以加强预训练模型所需要的稳健性和有效性。同时我们建议,每种类型的学习过程都应该详细地测试各种不同监督策略的效果。因此,我们将在下一节中提出并验证各种监督策略对模型表现的影响。
监督策略方案
这里我们提出了以下这些有效的监督策略:
InfoNCE loss是一种对比损失函数,如下式所示。MoTIS方法已经成功将其应用于预训练蒸馏之中。

Feature-wise distance (FD) loss旨在直接最小化特征向量之间的距离。这里我们使用平方的L2范数作为度量:
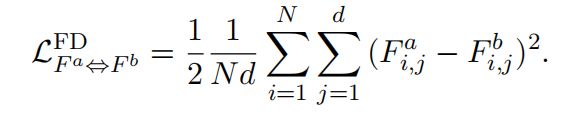
Similarity-wise distance (SD) loss期望减少相似矩阵之间的距离度量:

KL-Div loss使用Kullback–Leibler散度来度量预测概率分布和目标概率分布之间的差异,并期望最小化以下这个目标函数:

值得注意的是,SD loss和KL-Div loss中通常使用两个教师网络的输出作为两个学生网络学习的目标。而我们这里额外尝试了使用如Figure 1中同色成对箭头作为相互学习的目标,我们称之为symmetric(Sym)版本。例如,通常的KL-Div loss实现的模态间师生交互学习可以表示为:

而我们提出的相应的Sym版本可以表示为:
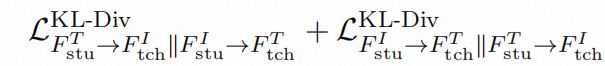
这种方式加深了在优化过程中四个编码器之间的交互作用。
监督策略选择
我们旨在通过实验验证各种学习类型和监督策略的结合是否可以带来进一步的性能提升。实验的结果如下表所示:
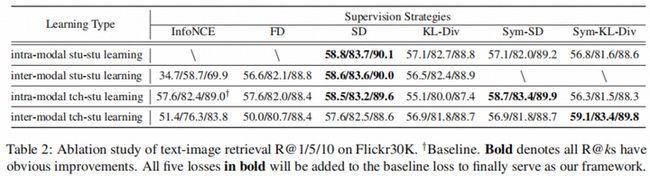
我们可以观察到: 1) 通过适当地选择具体的监督策略,每种学习类型都可以在基线的基础上进一步带来明显的改进。2) 每种学习类型的效果都很大程度上受到所实现的损失函数的影响。这也表明,我们应仔细探讨预训练蒸馏过程的监督策略。3)我们提出的Sym版本损失(Sym-SD和Sym-KL-Div)在师生交互学习中通常具有优于标准版本的性能。在基线的基础之上,我们最终的方法将所有有效的结合都进一步进行了集成。
算法精度评测
为了评测ConaCLIP算法的精度,我们在一些常用的文图检索数据集上进行了实验,结果如下:

结果可以证明,在所有评估指标下,ConaCLIP相比现有的方法和基准模型都有显著的改善。这充分证明了我们方法的有效性。同时我们将所提出的技术应用于阿里巴巴电子商务平台的某个端到端跨模态检索场景。本方法取得的性能指标、模型大小和加速比率如下表所示:

可以发现我们的方法在基本保证模型性能的同时显著的降低了模型的存储空间并增加了模型的计算效率。为了更好地服务开源社区,ConaCLIP方法即将贡献在自然语言处理算法框架EasyNLP中,欢迎NLP从业人员和研究者使用。
EasyNLP开源框架:https://github.com/alibaba/EasyNLP
参考文献
- Chengyu Wang, Minghui Qiu, Taolin Zhang, Tingting Liu, Lei Li, Jianing Wang, Ming Wang, Jun Huang, Wei Lin. EasyNLP: A Comprehensive and Easy-to-use Toolkit for Natural Language Processing. EMNLP 2022
- Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever. Learning Transferable Visual Models From Natural Language Supervision. ICML 2021
- Geoffrey E. Hinton, Oriol Vinyals, Jeffrey Dean. Distilling the Knowledge in a Neural Network. NeurIPS 2014 Deep Learning Workshop
- Siyu Ren, Kenny Zhu. Leaner and Faster: Two-stage Model Compression for Lightweight Text-image Retrieval. NAACL-HLT 2022
论文信息
论文标题:ConaCLIP: Exploring Distillation of Fully-Connected Knowledge Interaction Graph for Lightweight Text-Image Retrieval
论文作者:汪嘉鹏、汪诚愚、王小丹、黄俊、金连文
论文PDF链接:https://aclanthology.org/2023.acl-industry.8.pdf
点击立即免费试用云产品 开启云上实践之旅!
原文链接
本文为阿里云原创内容,未经允许不得转载。