LinkNet分割模型搭建
原论文:LinkNet: Exploiting Encoder Representations for Efficient Semantic Segmentation
直接步入正题~~~
一、LinkNet
1.decoder模块
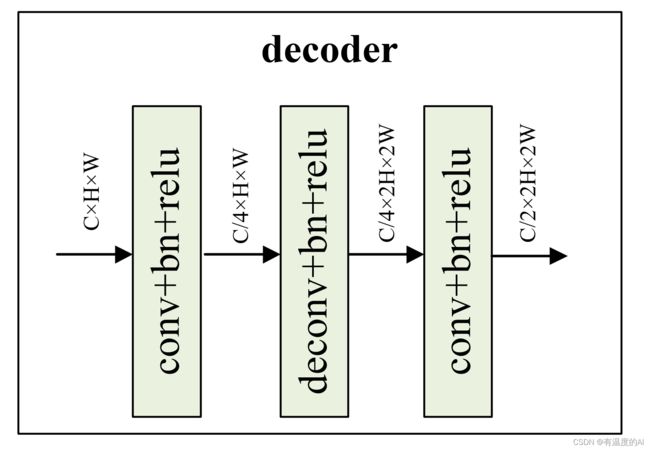
class DecoderBlock(nn.Module):
def __init__(self, in_channels, n_filters): #512, 256
super(DecoderBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, in_channels // 4, 1)
self.norm1 = nn.BatchNorm2d(in_channels // 4)
self.relu1 = nonlinearity
self.deconv2 = nn.ConvTranspose2d(in_channels // 4, in_channels // 4, 3, stride=2, padding=1, output_padding=1)
self.norm2 = nn.BatchNorm2d(in_channels // 4)
self.relu2 = nonlinearity
self.conv3 = nn.Conv2d(in_channels // 4, n_filters, 1)
self.norm3 = nn.BatchNorm2d(n_filters)
self.relu3 = nonlinearity
def forward(self, x):
x = self.conv1(x)
x = self.norm1(x)
x = self.relu1(x)
x = self.deconv2(x)
x = self.norm2(x)
x = self.relu2(x)
x = self.conv3(x)
x = self.norm3(x)
x = self.relu3(x)
return x2.整体网络结构

class LinkNet34(nn.Module):
def __init__(self, num_classes=1):
super(LinkNet34, self).__init__()
filters = [64, 128, 256, 512]
resnet = models.resnet34(pretrained=False)
self.firstconv = resnet.conv1
self.firstbn = resnet.bn1
self.firstrelu = resnet.relu
self.firstmaxpool = resnet.maxpool
self.encoder1 = resnet.layer1
self.encoder2 = resnet.layer2
self.encoder3 = resnet.layer3
self.encoder4 = resnet.layer4
self.decoder4 = DecoderBlock(filters[3], filters[2])
self.decoder3 = DecoderBlock(filters[2], filters[1])
self.decoder2 = DecoderBlock(filters[1], filters[0])
self.decoder1 = DecoderBlock(filters[0], filters[0])
self.finaldeconv1 = nn.ConvTranspose2d(filters[0], 32, 3, stride=2)
self.finalrelu1 = nonlinearity
self.finalconv2 = nn.Conv2d(32, 32, 3)
self.finalrelu2 = nonlinearity
self.finalconv3 = nn.Conv2d(32, num_classes, 2, padding=1)
def forward(self, x):
# Encoder
x = self.firstconv(x) #[1, 64, 128, 128]
#print(f'x0:{x.shape}')
x = self.firstbn(x)
x = self.firstrelu(x)
x = self.firstmaxpool(x) #[1, 64, 64, 64]
e1 = self.encoder1(x) #[1, 64, 64, 64]
e2 = self.encoder2(e1) #[1, 128, 32, 32]
e3 = self.encoder3(e2) #[1, 256, 16, 16]
e4 = self.encoder4(e3) #[1, 512, 8, 8]
# Decoder
d4 = self.decoder4(e4) + e3 #[1, 256, 16, 16]
d3 = self.decoder3(d4) + e2
d2 = self.decoder2(d3) + e1
d1 = self.decoder1(d2) #[1, 64, 128, 128]
out = self.finaldeconv1(d1) #[1, 32, 257, 257]
out = self.finalrelu1(out)
out = self.finalconv2(out) #[1, 32, 255, 255]
out = self.finalrelu2(out)
out = self.finalconv3(out) #[1, 4, 256, 256]
return F.sigmoid(out)
if __name__ == '__main__':
input_tensor = torch.randn((1, 3, 256, 256))
model = LinkNet34(num_classes=4)
out1 = model(input_tensor)
print(out1.shape)二、D-LinkNet
原论文:D-LinkNet: LinkNet with Pretrained Encoder and Dilated Convolution for High Resolution Satellite Imagery Road Extraction
1.decoder模块
class DecoderBlock(nn.Module):
def __init__(self, in_channels, n_filters):
super(DecoderBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, in_channels // 4, 1)
self.norm1 = nn.BatchNorm2d(in_channels // 4)
self.relu1 = nonlinearity
self.deconv2 = nn.ConvTranspose2d(in_channels // 4, in_channels // 4, 3, stride=2, padding=1, output_padding=1)
self.norm2 = nn.BatchNorm2d(in_channels // 4)
self.relu2 = nonlinearity
self.conv3 = nn.Conv2d(in_channels // 4, n_filters, 1)
self.norm3 = nn.BatchNorm2d(n_filters)
self.relu3 = nonlinearity
def forward(self, x):
x = self.conv1(x)
x = self.norm1(x)
x = self.relu1(x)
x = self.deconv2(x)
x = self.norm2(x)
x = self.relu2(x)
x = self.conv3(x)
x = self.norm3(x)
x = self.relu3(x)
return x2.dblock模块

class Dblock_more_dilate(nn.Module):
def __init__(self, channel):
super(Dblock_more_dilate, self).__init__()
self.dilate1 = nn.Conv2d(channel, channel, kernel_size=3, dilation=1, padding=1)
self.dilate2 = nn.Conv2d(channel, channel, kernel_size=3, dilation=2, padding=2)
self.dilate3 = nn.Conv2d(channel, channel, kernel_size=3, dilation=4, padding=4)
self.dilate4 = nn.Conv2d(channel, channel, kernel_size=3, dilation=8, padding=8)
self.dilate5 = nn.Conv2d(channel, channel, kernel_size=3, dilation=16, padding=16)
for m in self.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.ConvTranspose2d):
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x):
dilate1_out = nonlinearity(self.dilate1(x))
dilate2_out = nonlinearity(self.dilate2(dilate1_out))
dilate3_out = nonlinearity(self.dilate3(dilate2_out))
dilate4_out = nonlinearity(self.dilate4(dilate3_out))
dilate5_out = nonlinearity(self.dilate5(dilate4_out))
out = x + dilate1_out + dilate2_out + dilate3_out + dilate4_out + dilate5_out
return out3.整体网络结构

class DinkNet34(nn.Module):
def __init__(self, num_classes=1):
super(DinkNet34, self).__init__()
filters = [64, 128, 256, 512]
resnet = models.resnet34(pretrained=True)
self.firstconv = resnet.conv1
self.firstbn = resnet.bn1
self.firstrelu = resnet.relu
self.firstmaxpool = resnet.maxpool
self.encoder1 = resnet.layer1
self.encoder2 = resnet.layer2
self.encoder3 = resnet.layer3
self.encoder4 = resnet.layer4
self.dblock = Dblock(512)
self.decoder4 = DecoderBlock(filters[3], filters[2])
self.decoder3 = DecoderBlock(filters[2], filters[1])
self.decoder2 = DecoderBlock(filters[1], filters[0])
self.decoder1 = DecoderBlock(filters[0], filters[0])
self.finaldeconv1 = nn.ConvTranspose2d(filters[0], 32, 4, 2, 1)
self.finalrelu1 = nonlinearity
self.finalconv2 = nn.Conv2d(32, 32, 3, padding=1)
self.finalrelu2 = nonlinearity
self.finalconv3 = nn.Conv2d(32, num_classes, 3, padding=1)
def forward(self, x):
# Encoder
x = self.firstconv(x) #[1, 64, 128, 128]
x = self.firstbn(x)
x = self.firstrelu(x)
x = self.firstmaxpool(x) #[1, 64, 64, 64]
e1 = self.encoder1(x) #[1, 64, 64, 64]
e2 = self.encoder2(e1) #[1, 128, 32, 32]
e3 = self.encoder3(e2) #[1, 256, 16, 16]
e4 = self.encoder4(e3) #[1, 512, 8, 8]
# Center
e4 = self.dblock(e4) #[1, 512, 8, 8]
# Decoder
d4 = self.decoder4(e4) + e3
d3 = self.decoder3(d4) + e2
d2 = self.decoder2(d3) + e1
d1 = self.decoder1(d2)
out = self.finaldeconv1(d1)
out = self.finalrelu1(out)
out = self.finalconv2(out)
out = self.finalrelu2(out)
out = self.finalconv3(out)
return F.sigmoid(out)
if __name__ == '__main__':
input_tensor = torch.randn((1, 3, 256, 256))
model = DinkNet34_less_pool(num_classes=4)
out = model(input_tensor)
print(out.shape)此处还可以将主干网络换为resnet50/resnet101
三、NL-LinkNet
原论文:NL-LinkNet: Toward Lighter but More Accurate Road Extraction with Non-Local Operations
1.decoder模块
class DecoderBlock(nn.Module):
def __init__(self, in_channels, n_filters):
super(DecoderBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, in_channels // 4, 1)
self.norm1 = nn.BatchNorm2d(in_channels // 4)
self.relu1 = nonlinearity
self.deconv2 = nn.ConvTranspose2d(in_channels // 4, in_channels // 4, 3, stride=2, padding=1, output_padding=1)
self.norm2 = nn.BatchNorm2d(in_channels // 4)
self.relu2 = nonlinearity
self.conv3 = nn.Conv2d(in_channels // 4, n_filters, 1)
self.norm3 = nn.BatchNorm2d(n_filters)
self.relu3 = nonlinearity
def forward(self, x):
x = self.conv1(x)
x = self.norm1(x)
x = self.relu1(x)
x = self.deconv2(x)
x = self.norm2(x)
x = self.relu2(x)
x = self.conv3(x)
x = self.norm3(x)
x = self.relu3(x)
return x2.NONLocalBlock2D_EGaussian模块
这个模块在http://t.csdn.cn/wQGan这篇文章中用到过!!!
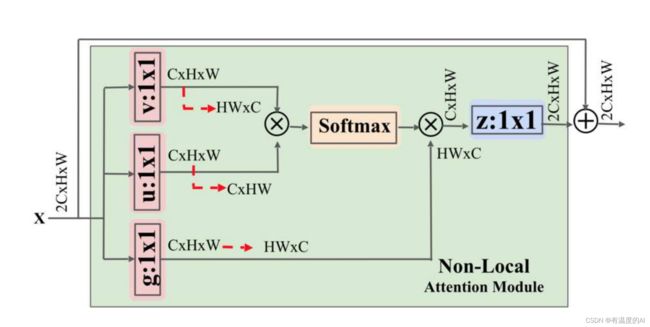
class _NonLocalBlock2D_EGaussian(nn.Module):
def __init__(self, in_channels, inter_channels=None, dimension=3, sub_sample=True, bn_layer=True):
super(_NonLocalBlock2D_EGaussian, self).__init__()
assert dimension in (1, 2, 3)
self.dimension = dimension
self.sub_sample = sub_sample
self.in_channels = in_channels
self.inter_channels = inter_channels
if self.inter_channels is None:
self.inter_channels = in_channels // 2
if self.inter_channels == 0:
self.inter_channels = 1
conv_nd = nn.Conv2d
max_pool_layer = nn.MaxPool2d(kernel_size=(2, 2))
bn = nn.BatchNorm2d
self.g = conv_nd(in_channels=self.in_channels, out_channels=self.inter_channels,
kernel_size=1, stride=1, padding=0)
if bn_layer:
self.W = nn.Sequential(
conv_nd(in_channels=self.inter_channels, out_channels=self.in_channels,
kernel_size=1, stride=1, padding=0),
bn(self.in_channels)
)
nn.init.constant_(self.W[1].weight, 0)
nn.init.constant_(self.W[1].bias, 0)
else:
self.W = conv_nd(in_channels=self.inter_channels, out_channels=self.in_channels,
kernel_size=1, stride=1, padding=0)
nn.init.constant_(self.W.weight, 0)
nn.init.constant_(self.W.bias, 0)
self.theta = conv_nd(in_channels=self.in_channels, out_channels=self.inter_channels,
kernel_size=1, stride=1, padding=0)
self.phi = conv_nd(in_channels=self.in_channels, out_channels=self.inter_channels,
kernel_size=1, stride=1, padding=0)
if sub_sample:
self.g = nn.Sequential(self.g, max_pool_layer)
self.phi = nn.Sequential(self.phi, max_pool_layer)
def forward(self, x): #例: 1, 128, 32, 32
batch_size = x.size(0) #1
# 128, 32, 32--64, 32, 32--64, 16, 16--1, 64, 16*16
g_x = self.g(x).view(batch_size, self.inter_channels, -1)
g_x = g_x.permute(0, 2, 1) #1, 16*16, 64
# print(f'g_x:{g_x.shape}')
# 128, 32, 32--64, 32, 32--1, 64, 32*32
theta_x = self.theta(x).view(batch_size, self.inter_channels, -1)
theta_x = theta_x.permute(0, 2, 1) #1, 32*32, 64
# print(f'theta_x:{theta_x.shape}')
# 128, 32, 32--64, 32, 32--64, 16, 16--1, 64, 16*16
phi_x = self.phi(x).view(batch_size, self.inter_channels, -1)
f = torch.matmul(theta_x, phi_x) #1, 32*32, 16*16
# print(f'f:{f.shape}')
f_div_C = F.softmax(f, dim=-1)
y = torch.matmul(f_div_C, g_x) #1, 32*32, 64
y = y.permute(0, 2, 1).contiguous() #1, 64, 32*32
y = y.view(batch_size, self.inter_channels, *x.size()[2:]) #1, 64, 32, 32
# print(f'y:{y.shape}')
W_y = self.W(y) #1, 128, 32, 32
z = W_y + x #1, 128, 32, 32
return z3.整体网络结构

class NONLocalBlock2D_EGaussian(_NonLocalBlock2D_EGaussian):
def __init__(self, in_channels, inter_channels=None, sub_sample=True, bn_layer=True):
super(NONLocalBlock2D_EGaussian, self).__init__(in_channels,
inter_channels=inter_channels,
dimension=2, sub_sample=sub_sample,
bn_layer=bn_layer)
class NL34_LinkNet(nn.Module):
def __init__(self, num_classes=1):
super(NL34_LinkNet, self).__init__()
filters = (64, 128, 256, 512)
resnet = models.resnet34(pretrained=True)
self.firstconv = resnet.conv1
self.firstbn = resnet.bn1
self.firstrelu = resnet.relu
self.firstmaxpool = resnet.maxpool
self.encoder1 = resnet.layer1
self.encoder2 = resnet.layer2
self.nonlocal3 = NONLocalBlock2D_EGaussian(128)
self.encoder3 = resnet.layer3
self.nonlocal4 = NONLocalBlock2D_EGaussian(256)
self.encoder4 = resnet.layer4
self.decoder4 = DecoderBlock(filters[3], filters[2])
self.decoder3 = DecoderBlock(filters[2], filters[1])
self.decoder2 = DecoderBlock(filters[1], filters[0])
self.decoder1 = DecoderBlock(filters[0], filters[0])
self.finaldeconv1 = nn.ConvTranspose2d(filters[0], 32, 4, 2, 1)
self.finalrelu1 = nonlinearity
self.finalconv2 = nn.Conv2d(32, 32, 3, padding=1)
self.finalrelu2 = nonlinearity
self.finalconv3 = nn.Conv2d(32, num_classes, 3, padding=1)
def forward(self, x):
# Encoder
x = self.firstconv(x) #[1, 64, 128, 128]
x = self.firstbn(x)
x = self.firstrelu(x)
x = self.firstmaxpool(x)
e1 = self.encoder1(x) #[1, 64, 64, 64]
e2 = self.encoder2(e1) #[1, 128, 32, 32]
e3 = self.nonlocal3(e2) #[1, 128, 32, 32]
e3 = self.encoder3(e3) #[1, 256, 16, 16]
e4 = self.nonlocal4(e3) #[1, 256, 16, 16]
e4 = self.encoder4(e4) #[1, 512, 8, 8]
# Decoder
d4 = self.decoder4(e4) + e3
d3 = self.decoder3(d4) + e2
d2 = self.decoder2(d3) + e1
d1 = self.decoder1(d2)
out = self.finaldeconv1(d1)
out = self.finalrelu1(out)
out = self.finalconv2(out)
out = self.finalrelu2(out)
out = self.finalconv3(out)
return F.sigmoid(out)
if __name__ == '__main__':
input_tensor = torch.randn((1, 4, 256, 256))
model = NL34_LinkNet(num_classes=4)
out = model(input_tensor)
print(out.shape) https://github.com/zstar1003/Road-Extraction
https://github.com/zstar1003/Road-Extraction