Oracle分区表-大数据量表存储
Oracle分区表
- 使用场景
- 分区类型
- 分区方法
-
- Range 按取值范围分区
- List 按键值分区
- Hash 散列哈希分区
- 二级分区
- 普通表转为分区表
- 分区表常用操作
- 分区表常用查询
使用场景
当一个表的数据过大,如记录数超千万乃至过亿,或表数据大小超过2G时,对该表的操作性能就会严重降低。尤其在某些复杂SQL在特殊情况下触发全表扫描,更是慢的令人发指。对于这种超大数据量的表,可以通过分区来提高性能。
分区表将数据根据分区列放到不同的分区里,从物理上分离开。查询时,可以只查询相应分区的数据,避免了全表扫描。而且数据库分区对于应用是完全透明的。
分区后,由于数据分布在不同的物理空间,当某个分区故障并不影响其他分区的使用,提高了可用性。同时可以把不同的分区映射到不同的磁盘,均衡IO,提升系统性能。
分区类型
- 水平分区
按记录分区,根据分区列的取值划分,将记录放到不同的分区。例如一些操作日志表,可以按操作时间划分,每一年或每个月的记录存放在一个分区。 - 垂直分区
按列分区,可以将某些列单独分区。例如操作日志表里可以存放系统交互报文,报文使用CLOB存放,这里的报文并不经常使用,可以将报文单独分区存储。
分区方法
以下分区方法以此表结构为例:
CREATE TABLE
TB1
(
ID NUMBER(10),
LVL VARCHAR2(5),
DT DATE,
PRIMARY KEY (ID)
);
--表中数据
INSERT INTO TB1 (ID, LVL, DT) VALUES (1, 'A', TIMESTAMP '2018-12-01 03:21:16');
INSERT INTO TB1 (ID, LVL, DT) VALUES (2, 'B', TIMESTAMP '2017-12-01 03:21:16');
INSERT INTO TB1 (ID, LVL, DT) VALUES (3, 'C', TIMESTAMP '2019-12-11 03:21:16');
INSERT INTO TB1 (ID, LVL, DT) VALUES (4, 'A', TIMESTAMP '2020-10-01 03:21:16');
INSERT INTO TB1 (ID, LVL, DT) VALUES (6, 'D', TIMESTAMP '2020-05-01 03:21:16');
INSERT INTO TB1 (ID, LVL, DT) VALUES (5, 'B', TIMESTAMP '2021-08-01 03:21:16');
Range 按取值范围分区
按某一列的取值范围进行分区,以日期范围为例。
DROP TABLE TB1;
CREATE TABLE
TB1
(
ID NUMBER(10),
LVL VARCHAR2(5),
DT DATE,
PRIMARY KEY (ID)
)
partition by range (DT)
(
partition P2018 values less than (to_date('20190101', 'YYYYMMDD')) TABLESPACE USERS,
partition P2019 values less than (to_date('20200101', 'YYYYMMDD')) TABLESPACE USERS,
partition P2020 values less than (to_date('20210101', 'YYYYMMDD')) TABLESPACE USERS,
partition P2021 values less than (to_date('20220101', 'YYYYMMDD')) TABLESPACE USERS
);
取值测试:

这里除了DATE类型,也可以按其他类型字段范围取值。
对DATE类型使用Range分区时,当时间范围超过已有分区的最大值时,就会新增失败。例如上例中,当新增的数据时间超过2022年时,新增会报错:ORA-14400: 插入的分区关键字未映射到任何分区。
这时候可以编写存储过程新增分区并定时执行,也可以使用INTERVAL关键字使其根据新增的数据,自动新增分区。
使用INTERVAL关键字按年分区:
DROP TABLE TB1;
CREATE TABLE
TB1
(
ID NUMBER(10),
LVL VARCHAR2(5),
DT DATE,
PRIMARY KEY (ID)
)
partition by range (DT) interval (numtoyminterval(1, 'year'))
(
partition P2018 values less than (to_date('20190101', 'YYYYMMDD')),
partition P2019 values less than (to_date('20200101', 'YYYYMMDD')),
partition P2020 values less than (to_date('20210101', 'YYYYMMDD')),
partition P2021 values less than (to_date('20220101', 'YYYYMMDD'))
);
这里通过以下SQL查看分区:
SELECT * FROM USER_TAB_PARTITIONS WHERE TABLE_NAME='TB1';
执行后,看到分区数量是4个:

新增数据:
INSERT INTO TB1 SELECT 7, 'D', SYSDATE + INTERVAL '1' YEAR FROM DUAL;
INSERT INTO TB1 SELECT 8, 'A', SYSDATE + INTERVAL '2' YEAR FROM DUAL;
新增后查看分区数,可以看出已自动新增分区:

这里INTERVAL使用了日期函数numtoyminterval,numtoyminterval除了支持年,还支持月month。
日需要使用函数numtodsinterval,numtodsinterval支持的单位有’day’,‘hour’,‘minute’,‘second’。
这两个函数的单位不区分大小写。
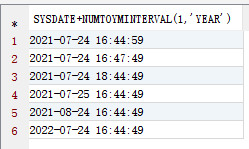
测试SQL:
SELECT SYSDATE + NUMTOYMINTERVAL (1, 'YEAR') FROM DUAL
UNION
SELECT SYSDATE + NUMTOYMINTERVAL (1, 'MONTH') FROM DUAL
UNION
SELECT SYSDATE + NUMTODSINTERVAL (1, 'DAY') FROM DUAL
UNION
SELECT SYSDATE + NUMTODSINTERVAL (2, 'HOUR') FROM DUAL
UNION
SELECT SYSDATE + NUMTODSINTERVAL (3, 'MINUTE') FROM DUAL
UNION
SELECT SYSDATE + NUMTODSINTERVAL (10, 'SECOND') FROM DUAL;
执行结果
List 按键值分区
按有一列的键值进行分区,适用于一列取值固定的情况。
DROP TABLE TB1;
CREATE TABLE
TB1
(
ID NUMBER(10),
LVL VARCHAR2(5),
DT DATE,
PRIMARY KEY (ID)
)
partition by list (LVL)
(
partition P1 values ('A', 'B'),
partition P2 values ('C', 'D')
);
取值测试:
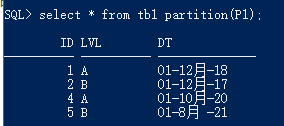
Hash 散列哈希分区
在无特定规则的情况下,可以按某一列或某几列的哈希值分区。当数据量大时哈希分区可以相对平均地将数据存储到指定个数的分区中。
DROP TABLE TB1;
CREATE TABLE
TB1
(
ID NUMBER(10),
LVL VARCHAR2(5),
DT DATE,
PRIMARY KEY (ID)
)
partition by hash (ID)
(
partition P1,
partition P2,
partition P3
);
取值测试
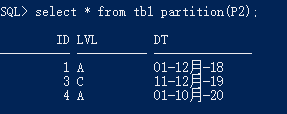
二级分区
以上两种分区组合得到二级分区。即先以某一种方法进行分区,再对分区后的数据以某一种分区方法进行分区得到子分区。两种分区方法可以相同,也可以不同。
例如:Range-List,可以先以时间范围分区,每个时间分区内再以List键值分区。
DROP TABLE TB1;
CREATE TABLE
TB1
(
ID NUMBER(10),
LVL VARCHAR2(5),
DT DATE,
PRIMARY KEY (ID)
)
partition by range (DT) subpartition by list (LVL)
(
partition P2018 values less than (to_date('20190101', 'YYYYMMDD'))
(
subpartition P2018_1 values ('A', 'B'),
subpartition P2018_2 values ('C', 'D')
),
partition P2019 values less than (to_date('20200101', 'YYYYMMDD'))
(
subpartition P2019_1 values ('A', 'B'),
subpartition P2019_2 values ('C', 'D')
),
partition P2020 values less than (to_date('20210101', 'YYYYMMDD'))
(
subpartition P2020_1 values ('A', 'B'),
subpartition P2020_2 values ('C', 'D')
),
partition P2999 values less than (to_date('30000101', 'YYYYMMDD'))
(
subpartition P2999_1 values ('A', 'B'),
subpartition P2999_2 values ('C', 'D')
)
);
取值测试:

二级分区的组合可以有多种,可以根据应用场景自行选择。
普通表转为分区表
需要使用sysdba权限。
使用oracle或管理员账户执行sqlplus / as sysdba进入sqlplus命令行模式。
- 建原表
这里使用本例中的TB1。 - 检查原表是否可重定义
检查是否有主键,如果无主键需新增主键才可转换。
SQL> EXEC DBMS_REDEFINITION.CAN_REDEF_TABLE('SCOTT','TB1',DBMS_REDEFINITION.CONS_USE_PK);
BEGIN DBMS_REDEFINITION.CAN_REDEF_TABLE('SCOTT','TB1',DBMS_REDEFINITION.CONS_USE_PK); END;
*
第 1 行出现错误:
ORA-12089: 不能联机重新定义无主键的表 "SCOTT"."TB1"
ORA-06512: 在 "SYS.DBMS_REDEFINITION", line 139
ORA-06512: 在 "SYS.DBMS_REDEFINITION", line 1782
ORA-06512: 在 line 1
SQL> alter table scott.tb1 add primary key(id);
表已更改。
SQL> EXEC DBMS_REDEFINITION.CAN_REDEF_TABLE('SCOTT','TB1',DBMS_REDEFINITION.CONS_USE_PK);
PL/SQL 过程已成功完成。
SQL>
- 建中间表
中间表表结构必须与原表完全相同。
CREATE TABLE
TB1_TMP
(
ID NUMBER(10),
LVL VARCHAR2(5),
DT DATE,
PRIMARY KEY (ID)
)
partition by range (DT) interval (numtoyminterval(1, 'year'))
(
partition P2018 values less than (to_date('20190101', 'YYYYMMDD')),
partition P2019 values less than (to_date('20200101', 'YYYYMMDD')),
partition P2020 values less than (to_date('20210101', 'YYYYMMDD')),
partition P2021 values less than (to_date('20220101', 'YYYYMMDD'))
);
- 执行重定义
SQL> EXEC DBMS_REDEFINITION.START_REDEF_TABLE('SCOTT', 'TB1', 'TB1_TMP');
PL/SQL 过程已成功完成。
- 新增数据同步
对于大数据量的表,重定义时间较长。在同步过程中,如果TB1有新增的数据,可以通过以下命令同步:
SQL> EXECUTE DBMS_REDEFINITION.SYNC_INTERIM_TABLE('SCOTT','TB1','TB1_TMP');
PL/SQL 过程已成功完成。
- 结束定义
SQL> EXEC DBMS_REDEFINITION.FINISH_REDEF_TABLE('SCOTT','TB1','TB1_TMP');
PL/SQL 过程已成功完成。
- 检查数据,删除中间表
--检查数据
SELECT COUNT(1) FROM TB1;
SELECT COUNT(1) FROM TB1_TMP;
--删除中间表
DROP TABLE TB1_TMP;
--查看原表分区信息
SELECT * FROM USER_TAB_PARTITIONS WHERE TABLE_NAME='TB1';
以上操作中,如果START_REDEF_TABLE和FINISH_REDEF_TABLE期间如果出现异常,还可以执行以下命令来终止转换:
SQL> DBMS_REDEFINITION.ABORT_REDEF_TABLE(‘SCOTT’, 'TB1','TB1_TMP');
分区表常用操作
- 添加分区
ALTER TABLE TB1 ADD partition P2022 values less than (to_date('20230101', 'YYYYMMDD'));
ALTER TABLE TB1 MODIFY PARTITION P2020 ADD SUBPARTITION P2020_3 VALUES('E', 'F');
- 删除分区
ALTER TABLE TB1 DROP PARTITION P2018;
ALTER TABLE TB1 DROP SUBPARTITION P2020_3;
注意:如果删除的分区是表中唯一的分区,那么此分区将不能被删除,要想删除此分区,必须删除表。
- 清空分区
ALTER TABLE TB1 TRUNCATE PARTITION P2018;
ALTER TABLE TB1 TRUNCATE SUBPARTITION P2020_1;
- 合并分区
ALTER TABLE TB1 MERGE PARTITIONS P2018,P2019 INTO PARTITION P2019;
- 拆分分区
拆分分区将一个分区拆分两个新分区,拆分后原来分区不再存在。注意不能对HASH类型的分区进行拆分。
ALTER TABLE TB1 SPLIT PARTITION P2100 AT(TO_DATE('20230101','YYYYMMDD')) INTO (PARTITION P2022,PARTITION P2100);
- 重命名表分区
ALTER TABLE TB1 RENAME PARTITION P21 TO P2;
- 索引重建
对分区表的分区操作之后,需要对分区表的索引进行重建。
ALTER INDEX TB1_IDX1 REBUILD ONLINE;
分区表常用查询
- 查询表分区
SELECT * FROM USER_TAB_PARTITIONS WHERE TABLE_NAME='TB1';
- –查询表子分区:
select * from USER_TAB_SUBPARTITIONS WHERE TABLE_NAME='TB1';
- –查询表分区列:
select * from USER_PART_KEY_COLUMNS WHERE NAME='TB1'
- –查询表子分区列:
select * from USER_SUBPART_KEY_COLUMNS WHERE NAME='TB1';
- –查询所有的分区表
select * from user_tables a where a.partitioned='YES'
以上。
参考博文:
- oracle 分表分区
- oracle表分区实现及查询
- oracle的 分表 详解 -----表分区: